Journal of Jilin University(Engineering and Technology Edition) ›› 2025, Vol. 55 ›› Issue (1): 339-346.doi: 10.13229/j.cnki.jdxbgxb.20230284
Temporal and motion enhancement for video action recognition
Hao WANG1,2,3,4( ),Bin ZHAO5,Guo-hua LIU1,2,3,4()
),Bin ZHAO5,Guo-hua LIU1,2,3,4()
- 1.College of Electronic Information Technology and Optical Engineering,Nankai University,Tianjin 300350,China
2.Tianjin Key Laboratory of Optoelectronic Sensor and Sensing Network Technology,Tianjin 300350,China
3.General Terminal IC Interdisciplinary Science Center,Nankai University,Tianjin 300350,China
4.Engineering Research Center of Thin Film Optoelectronics Technology,Ministry of Education,Nankai University,Tianjin 300350,China
5.School of Artificial Intelligence,Guilin University of Electronic Technology,Guilin 541004,China
CLC Number:
- TP391
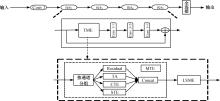
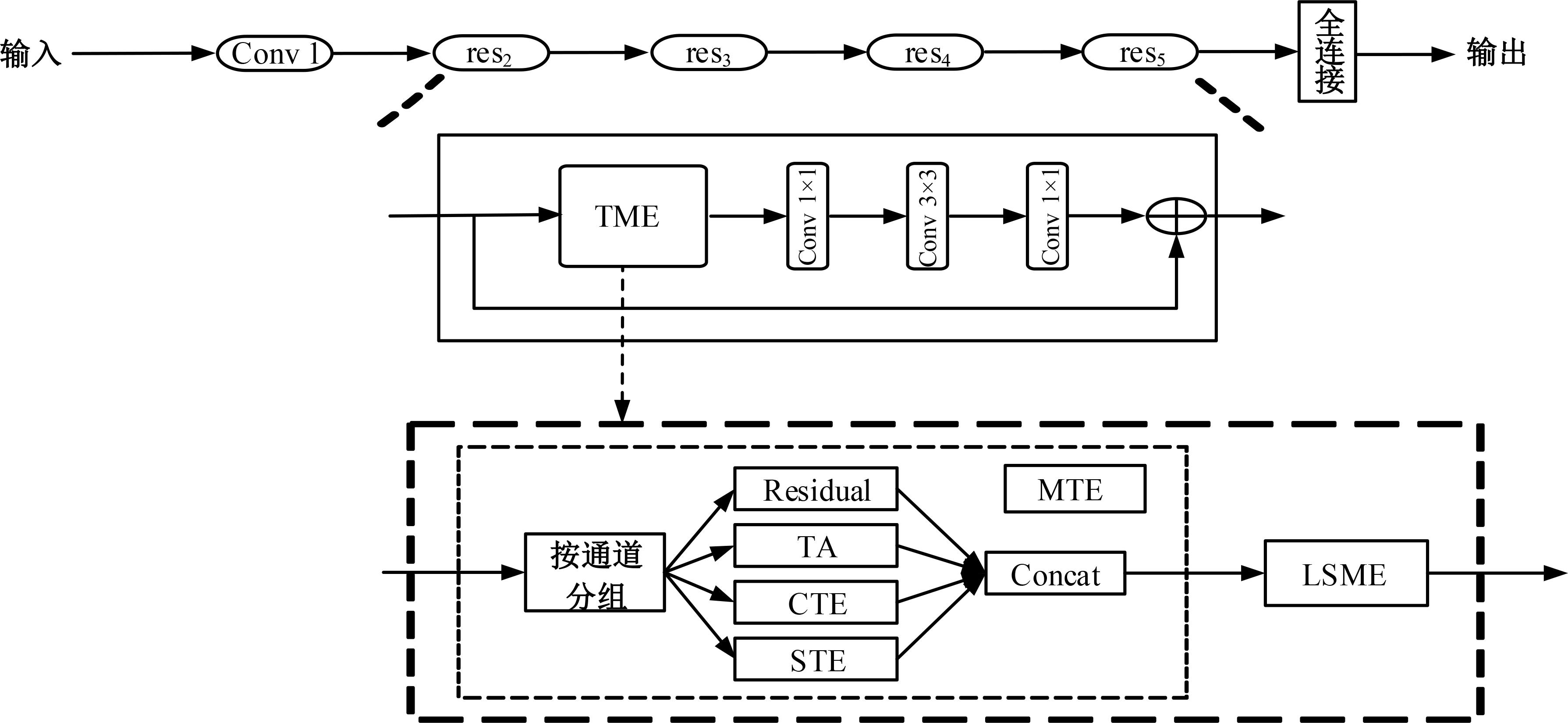
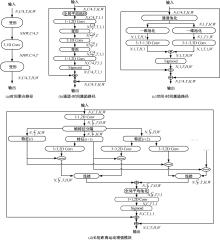
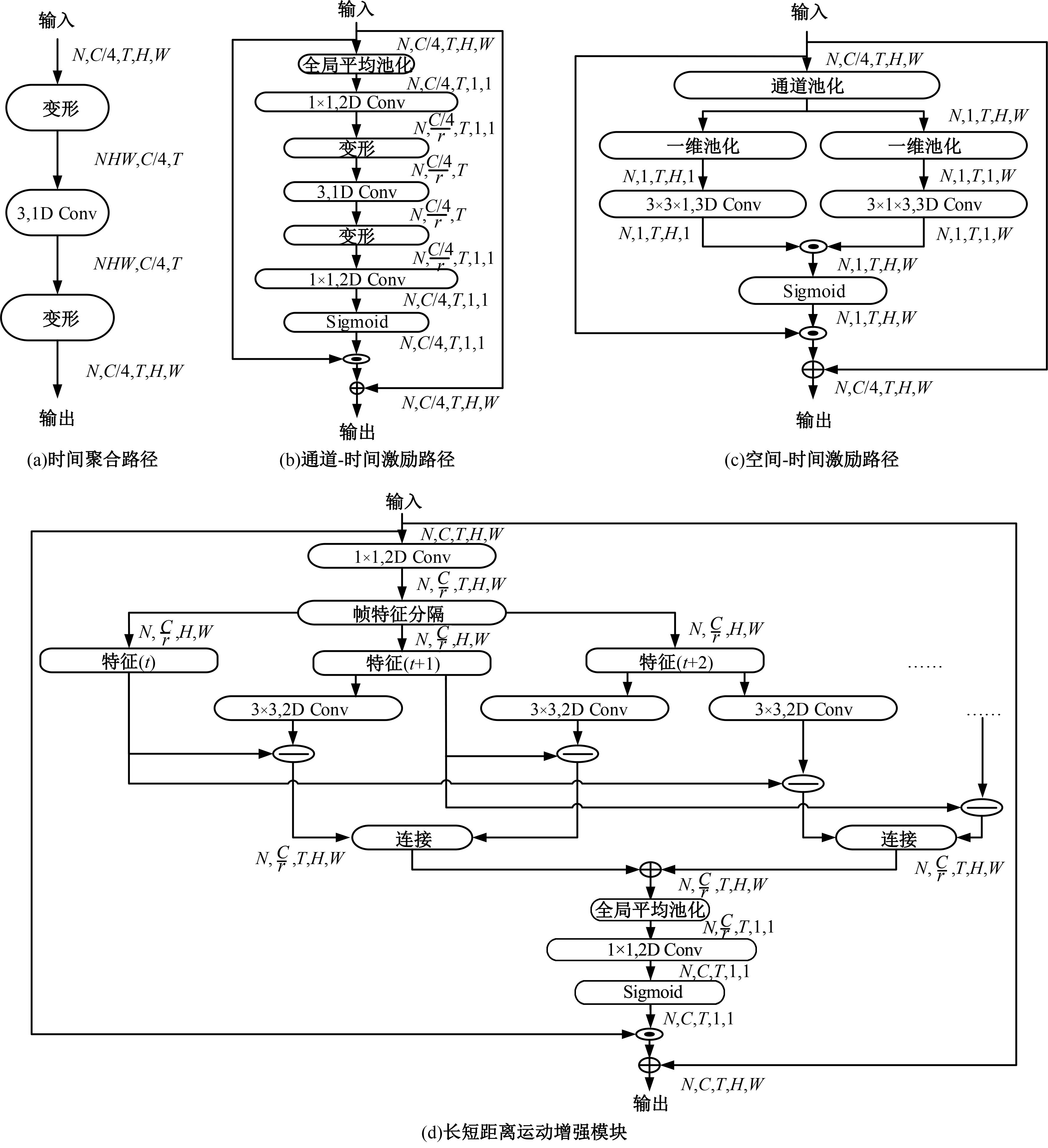
| 1 | Diba A, Fayyaz M, Sharma V, et al. Temporal 3D convnets: new architecture and transfer learning for video classification[DB/OL]. [2023-01-29]. . |
| 2 | Simonyan K, Zisserman A. Two-stream co-nvolutional networks for action recognition in videos[DB/OL]. [2023-01-29]. . |
| 3 | Wang L, Xiong Y, Wang Z, et al. Temporal segment networks:towards good practices for deep action recognition[C]∥Proceedings of the European Conference on Computer Vision, Amsterdam, Netherlands,2016: 20-36. |
| 4 | Girdhar R, Ramanan D, Gupta A, et al. Action- vlad: Learning spatio-temporal aggregation for action classification[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, USA, 2017: 971-980. |
| 5 | Zhu Y, Lan Z, Newsam S, et al. Hidden two-stream convolutional networks for action recognition[C]//Proceedings of the Asian Conference on Computer Vision, Perth, Australia,2018: 363-378. |
| 6 | Tran D, Bourdev L, Fergus R, et al. Learning spatiotemporal features with 3d convolutional networks[C]//Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 4489-4497. |
| 7 | Feichtenhofer C, Fan H, Malik J, et al. Slowfast networks for video recognition[C]∥Proceedings of the IEEE International Conference on Computer Vision, Seoul, South Korea, 2019: 6202-6211. |
| 8 | Qiu Z, Yao T, Mei T. Learning spatio-temporal representation with pseudo-3D residual networks[C]∥Proceedings of the IEEE International Conference on Computer Vision, Venice,Italy, 2017: 5533-5541. |
| 9 | Tran D, Wang H, Torresani L, et al. A closer look at spatiotemporal convolutions for action recognition[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA,2018: 6450⁃6459. |
| 10 | Xie S, Sun C, Huang J, et al. Rethinking spatiotemporal feature learning: speed-accuracy trade-offs in video classification[C]∥Proceedings of the European Conference on Computer Vision, Munich, Germany,2018: 305-321. |
| 11 | Carreira J, Zisserman A.Quo vadis, action recognition? a new model and the kinetics dataset[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA,2017:6299-6308. |
| 12 | Lin J, Gan C, Han S. TSM: temporal shift module for efficient video understanding[C]∥Proceedings of the IEEE International Conference on Computer Vision, Seoul, South Korea, 2019: 7083-7093. |
| 13 | Li Y, Ji B, Shi X, et al. Tea: temporal excitation and aggregation for action recognition[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Online, 2020: 909-918. |
| 14 | Jiang B, Wang M, Gan W, et al. Stm: spatiotemporal and motion encoding for action recognition[C]∥Proceedings of the IEEE International Conference on Computer Vision, Online, 2019: 2000-2009. |
| 15 | Liu Z, Luo D, Wang Y, et al. Teinet: towards an efficient architecture for video recognition[C]//Proceedings of the AAAI Conference on Artificial Intelligence, New York, USA, 2020(34): 11669-11676. |
| 16 | Liu Z, Wang L, Wu W, et al. Tam: temporal adaptive module for video recognition[DB/OL].[2021-08-18]. . |
| 17 | Zhou B, Andonian A, Oliva A, et al. Temporal relational reasoning in videos[C]∥Proceedings of the European Conference on Computer Vision, Munich, Germany,2018: 803-818. |
| 18 | Lee M, Lee S, Son S, et al. Motion feature network: fixed motion filter for action recognition[C]∥Proceedings of the European Conference on Computer Vision, Munich,Germany,2018: 387-403. |
| 19 | He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770-778. |
| 20 | Karpathy A, Toderici G, Shetty S, et al. Large-scale video classification with convolutional neural networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA,2014: 1725-1732. |
| 21 | Zolfaghari M, Singh K, Brox T. Eco: efficient convolutional net- work for online video understanding[C]∥Proceedings of the European Conference on Computer Vision, Munich, Germany, 2018: 695-712. |
| 22 | Wang Z, She Q, Smolic A.Action-net: multipath excitation for action recognition[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 2021: 13214-13223. |
| 23 | Goyal R, Ebrahimi Kahou S, Michalski V, et al. The “something-something” video database for learning and evaluating visual common sense[C]∥Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 2017: 5842-5850. |
| 24 | Kuehne H, Jhuang H, Garrote E,et al. Hmdb: a large video database for human motion recognition[C]∥Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 2011:2556-2563. |
| 25 | Soomro K, Zamir A R, Shah M. Ucf101: a dataset of 101 human actions classes from videos in the wild[J/OL]. [2012-12-03]. . |
| 26 | Wang X, Girshick R, Gupta A, et al. Non-local neural networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, 2018:7794-7803. |
| 27 | Contributors M.OpenMMLab's Next Generation Video Understanding Toolbox and Benchmark[DB/OL].[2020-12-26]. . |
| [1] | Xiao-ran GUO,Tie-jun WANG,Yue YAN. Entity relationship extraction method based on local attention and local remote supervision [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(1): 307-315. |
| [2] | Yuan-ning LIU,Zi-nan ZANG,Hao ZHANG,Zhen LIU. Deep learning-based method for ribonucleic acid secondary structure prediction [J]. Journal of Jilin University(Engineering and Technology Edition), 2025, 55(1): 297-306. |
| [3] | Lu Li,Jun-qi Song,Ming Zhu,He-qun Tan,Yu-fan Zhou,Chao-qi Sun,Cheng-yu Zhou. Object extraction of yellow catfish based on RGHS image enhancement and improved YOLOv5 network [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(9): 2638-2645. |
| [4] | Hong-wei ZHAO,Hong WU,Ke MA,Hai LI. Image classification framework based on knowledge distillation [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(8): 2307-2312. |
| [5] | Yun-zuo ZHANG,Yu-xin ZHENG,Cun-yu WU,Tian ZHANG. Accurate lane detection of complex environment based on double feature extraction network [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(7): 1894-1902. |
| [6] | Ming-hui SUN,Hao XUE,Yu-bo JIN,Wei-dong QU,Gui-he QIN. Video saliency prediction with collective spatio-temporal attention [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(6): 1767-1776. |
| [7] | Yan-feng LI,Ming-yang LIU,Jia-ming HU,Hua-dong SUN,Jie-yu MENG,Ao-ying WANG,Han-yue ZHANG,Hua-min YANG,Kai-xu HAN. Infrared and visible image fusion based on gradient transfer and auto-encoder [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(6): 1777-1787. |
| [8] | Li-ping ZHANG,Bin-yu LIU,Song LI,Zhong-xiao HAO. Trajectory k nearest neighbor query method based on sparse multi-head attention [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(6): 1756-1766. |
| [9] | Li-ming LIANG,Long-song ZHOU,Jiang YIN,Xiao-qi SHENG. Fusion multi-scale Transformer skin lesion segmentation algorithm [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(4): 1086-1098. |
| [10] | Yun-zuo ZHANG,Wei GUO,Wen-bo LI. Omnidirectional accurate detection algorithm for dense small objects in remote sensing images [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(4): 1105-1113. |
| [11] | Dondrub LHAKPA,Duoji ZHAXI,Jie ZHU. Tibetan text normalization method [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(12): 3577-3588. |
| [12] | Feng-feng ZHOU,Tao YU,Yu-si FAN. Generative adversarial autoencoder integrated voting algorithm based on mass spectral data [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(10): 2969-2977. |
| [13] | Jin-peng TIAN,Bao-jun HOU. Compressive sensing image reconstruction based on deep unfolding self-attention network [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(10): 3018-3026. |
| [14] | Na CHE,Yi-ming ZHU,Jian ZHAO,Lei SUN,Li-juan SHI,Xian-wei ZENG. Connectionism based audio-visual speech recognition method [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(10): 2984-2993. |
| [15] | Fa-sheng WANG,Bing HE,Fu-ming SUN,Hui ZHOU. Adaptive content aware spatially-regularized correlation filter for object tracking [J]. Journal of Jilin University(Engineering and Technology Edition), 2024, 54(10): 3037-3049. |
|
||