{kind=link}
{kind=link}
{kind=link}
考虑层数信息的XML文档聚类方法
[刘兆军1, 2  , 赵浩宇
, 赵浩宇3 , 王婧1, 2 , 李雄飞1, 2 , 李巍1, 2 ]
, 赵浩宇, 李巍|
|


刘兆军(1973),男,讲师,博士研究生.研究方向:数据挖掘,信息融合技术.E-mail:zhaojun@jlu.edu.cn
提出了一种层数敏感的XML文档数据集聚类方法CXLI。首先提出结构表概念,消除XML文档的重复和嵌套结构。然后提出考虑层数信息的XML文档基本编辑操作约束。进一步给出考虑层数信息的XML文档间相似性度量方法。最后使用凝聚型层次聚类方法对XML文档数据集进行聚类。在ACM SIGMOD数据集和人工生成的数据集上进行了实验验证,结果表明:在计算时间基本相同的情况下,CXLI方法具有更好的精确度。
方法
方法
A layer-sensitive XML document collection clustering method CXLI is proposed in this paper. First, a concept of structural table is put forward to clear up the duplication structures in XML documents. Second, the constraints of editing operations are established. Third, a testing method of the similarity between XML documents is presented. Finally, the XML documents are clustered using agglomerative hierarchical clustering method. ACM SIMOD data set and synthetic data set are used to test the proposed method. Results show that the proposed CXLI has better precision under similar time cost.
随着互联网的发展,半结构化数据(如HTML文档、XML文档、Email Message等)被广泛应用于互联网信息存储与信息交换领域,另外,一些非互联网的应用也使用半结构化数据格式存储信息(如Microsoft Office文档使用OpenXML格式存储、OpenOffice文档使用OpenDocument格式存储)。半结构化数据使用的编码方式与结构化数据(如关系型数据库中的数据、Excel数据等)不同,所以传统的结构化数据处理技术并不适用于半结构化数据[ 1, 2]。
目前,关于XML文档数据集聚类的方法大多忽略XML层数特性,认为不同层数操作是等费用的。本文提出一种考虑层数信息的XML文档聚类方法CXLI(Clustering XML with Layer Information),并进行了实验验证。
XML文档聚类的核心问题是XML文档相似性度量问题。Selkow[ 3]、Zhang等[ 4]和Chawathe等[ 5, 6]分别提出几种经典的树模型相似性度量方法。这些方法已经成为XML数据相似性度量和聚类任务的研究基础,但由于这些方法提出较早,所以其中一些操作并不完全适合于XML数据。一些学者在树模型相似性计算方法的基础上,针对XML数据特性进行改进,使其更适合XML数据特性。
Nierman等[ 7]提出两个含根有序标签树间编辑距离的计算方法,用于在文档类型定义DTD未知的情况下,提取XML文档集合的DTD。Nierman等[ 7]使用动态规划方法,除了插入叶子操作、删除叶子操作、更新操作,还支持插入子树操作与删除子树操作,但是对插入子树操作与删除子树操作做了一些限制。此外,Nierman的方法[ 7]还考虑到属性对结构的影响,使得操作更加符合XML数据的特性。Dalamagas等[ 8]提出一种根据结构进行XML文档聚类的工作框架,并提出一种消除XML文档重复元素和重复嵌套元素的方法。Dalamagas等[ 8]将消除重复元素与重复嵌套元素后的XML结构称为“结构概要(Structural summary)”。结构概要也是一种树形结构,可以使用递归方法计算相似度。同时,Dalamagas等[ 8]还给出使用结构概要以及相似性度量方法进行XML文档聚类的方法。Dalamagas的方法不满足无结构丢失特性。Flesca等[ 9]将XML文档重新编码成时间序列的形式,然后使用离散傅里叶变换计算XML文档间的相似度,该方法的时间复杂度为 O( Nlog N)。Flesca的方法不是基于树编辑距离的,其方法的精炼级别是元素。Tekli等[ 10]对XML相似性度量方法进行了总结,概述了基于编辑距离的XML相似性度量方法、基于信息检索的相似性度量方法以及基于其他结构(如边匹配、路径相似度)的XML相似性度量方法。
除此之外,在动态XML文档数据集和带语义的XML文档数据集方面,学者们也取得了一些成果。Li等[ 11, 12]提出了一种基于频繁变化结构FCS和加权余弦定理的动态XML文档数据集聚类方法,将XML文档聚类问题延伸到动态XML文档领域。Tagarelli等[ 13]充分考虑语义信息在XML文档数据集中的重要意义,提出一种带有语义度量的XML文档数据集聚类方法。Algergawy等[ 14]对XML文档聚类问题和聚类方法进行了总结,并提出XML文档数据集聚类问题的研究方向。
XML文档结构可以根据DTD约束进行改变。XML文档结构本质是对存储实际数据的逻辑关系进行描述,XML文档中不同层次的元素数据重要程度不同,表示的逻辑关系也不同。如果对XML结构进行修改,插入或删除的结构应该在其相关的层数上,这样更符合XML数据本身的特性。
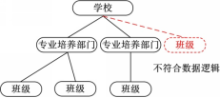
图1是某学校信息的XML文档例子,学校设有若干专业培养部门,每个专业培养部门下设若干班级。现在需要增加一个新的班级节点,如果将该班级节点插入学校节点下方,则违背了数据所表示的意义,出现一个没有专业的班级。其原因是在学校节点下方插入班级节点破坏了班级节点和专业培养部门节点的层次性,导致数据逻辑混乱。这种操作在树模型中是允许的,但在XML数据模型中是不适合的。如果在XML操作时不考虑XML层次性是不符合XML特性的。
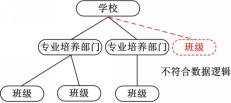 | 图1 层次敏感例子Fig.1 Instance of lay-sensitive |
目前,在XML文档聚类研究中,未见考虑XML文档结构层数信息的研究,在XML文档相似性度量时,大多忽略了XML文档子结构的层数,导致聚类结果不精确。因此,本文提出一种带有层数信息的XML文档聚类算法CXLI。
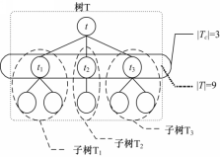
根据XML数据模型,一篇XML文档可以建模为一颗有序标签树结构。为方便描述算法,本文使用符号T代表一个树形结构,使用符号|T|代表树的节点总数,使用符号t代表树T的根节点,使用符号| T C |代表 t的直接孩子数量,即 t的出度,使用符号 t1, t2,…, 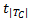
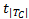
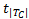
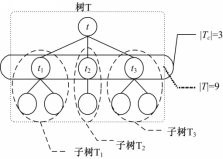 | 图2 树表示Fig.2 Tree representation |
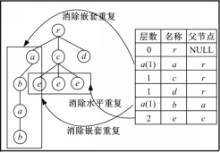
为了方便记录层数信息,消除XML数据中的水平重复与嵌套重复和加快层数查找速度,本文提出结构表方法。在相似度计算之前,对XML数据模型进行解析,将解析结果存入结构表中,这个过程需要层次遍历XML数据模型一次。结构表包括层数、名称和父节点三个字段。
结构表构造过程如下:
步骤1 增加结构表条目,层数字段为0、名称字段为根节点名、父节点为NULL。
步骤2 层次遍历含根有序标签树,如果已经全部遍历,算法结束;否则设遍历到节点为Node,Node所在层数为 L,执行步骤3。
步骤3 在结构表中查找层数为 L的条目,如果存在与Node节点名称相同且父节点相同的条目,返回步骤2。
步骤4 在结构表中Node的所有祖先节点中查找与Node节点名相同的节点,如果不存在同名祖先节点,执行步骤5,否则执行步骤6。
步骤5 增加结构表条目,将Node节点的层数、名称和父节点信息保存在结构表中,返回步骤2。
步骤6 设在Node节点的祖先节点中,与Node名称相同的节点所在层数为 l,对结构表进行修改,将从第 l层的Node节点开始到Node父节点结束这条路径上所有节点的层数修改为Node( l),返回步骤2。
在结构表构造过程中,第3步消除水平重复节点,第6步消除嵌套重复节点。
图3是结构表例子。结构表保存含根有序标签树节点层数信息,并消除重复节点信息,将层数信息的查找过程由树遍历转换为表遍历。结构表只记录相似性度量过程所必要的信息,构造完成后,结构表不参加树编辑操作,不会在表中插入或删除条目,没有额外的时间开销。
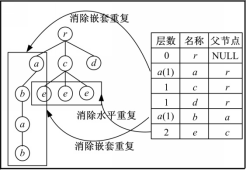 | 图3 结构表Fig.3 Structural table |
在考虑XML数据层数属性的情况下,一些树编辑操作就不再适合于XML数据。为了更好地适合XML数据本身特点,提高XML相似性度量的准确度,本文对XML数据模型的操作定义约束策略,设需要度量的两个含根有序标签树为Ts与Td,待插入或删除的子树为T':
约束规则1:节点插入约束。禁止非叶子节点插入操作,这种操作不符合XML特性。
约束规则2:子树插入约束。对插入子树操作进行约束。设操作为将子树T'插入源树Ts中且作为Ts的第 L层子树。T'能够被插入,当且仅当在源树Ts结构表中层数为 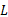
约束规则3:节点删除约束。禁止非叶子节点删除操作,这种操作破坏了源XML数据的层次关系。
约束规则4:子树删除约束。对删除子树操作进行约束:设子树T'为要删除的子树,T'所在层数为 L,T'能够被删除,当且仅当在目标树Td结构表中层数为 L的条目中,存在与T'相同的子树。如果删除子树操作不满足以上约束,则需要将删除子树操作转化成若干次删除叶子操作。这样就保证了删除的子树与目标树中相同子树在相同的层次。
约束1和约束3防止在含根有序标签树内部插入与删除操作破环数据层次关系,导致数据逻辑混乱。约束2和约束4通过结构表查找,在子树插入与删除操作时进行层数约束,保证子树操作不破坏层次性。
在进行XML编辑距离计算时,经常使用动态规划方法。本文相似性度量算法首先对源树Ts与目标树Td进行解析,分别生成源树Ts与目标树Td的结构表,然后插入目标树中存在而源树中缺失的结构。之后删除源树中存在而目标树缺失的结构,生成目标树Td,最后使用动态规划方法找到最优解。
设符合约束条件的插入操作费用计算函数为InsertCost(Tree T),符合约束条件的删除操作费用计算函数为DeleteCost(Tree T),相似性度量算法(CXLI_SIM)描述如下:
输入:源树Ts,目标树Td
输出:编辑距离
{
1.定义相似度矩阵dist=int[| 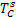
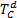
2.记录每棵子树插入操作费用
for(int j=1;j≤| 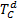
dist[0][j]=dist[0][j-1]+InsertCost( 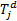
3.记录每棵子树删除操作费用
for(int i=1;i≤M;i++)
dist[i][0]=dist[i-1][0]+DeleteCost( 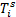
4.获取最小编辑距离
dist[i][j]=min{
( 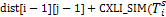
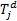
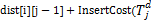
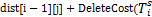
};
5.返回编辑距离dist[M][N];
}
聚类过程采用凝聚型层次聚类算法CXLI:
输入:XML数据集D,最小簇数t
输出:聚类结果
{
1.定义相似度矩阵M;
2.for ( Xi∈D,Xj∈D ) //创建相似度矩阵
Mij=CXLI_SIM(Xi,Xj);
3.在M中查找具有最大相似度的两个XML文档Xa和Xb;
4.if 簇数 > t
合并Xa和Xb;
else
执行步骤3;
5.返回当前分簇;
}
实验所用计算机硬件为Intel Core2 Quad Q9550 2.83 GHz(4核)处理器、2048 MB RAM、500 G硬盘,采用Windows 7操作系统。所有的算法都使用C++语言实现,使用标准库STL进行树遍历,使用微软MSXML库处理XML数据。
实验数据包括ACM SIGMOD Record XML数据集[ 15]以及人工生成的数据集。ACM SIGMOD Record XML数据集包括1999年发布的数据、2002年更新数据和2005年更新数据,人工生成的数据集使用人工编写的DTD文档并由IBM XML Generator生成。实验生成5个人工数据集,分别包含一些与层次相关的结构。人工数据集记为D1…D5,每个数据集中包含XML文件10 000个,文件名按顺序排列,从0.xml到9999.xml。为了测试各种方法的执行时间,实验中人工生成XML文档5000、7500、10 000、12 500、15 000、17 500、20 000个,分别使用各种相似性度量方法对这些XML文档进行相似度计算。
在相似性度量过程中,所有允许的编辑操作费用都设为1。
使用Nierman[ 7]、Dalamagas[ 8]、Flesca[ 9]方法作为XML文档相似性度量进行聚类,然后使用CXLI方法进行对比,聚类结果正确率见表1。
从表1可以看出,在考虑层数属性后,CXLI聚类正确率最优,说明在计算相似度时考虑层数属性能够提高正确率。对于ACM SIGMOD Record数据集,CXLI与Nierman的方法[ 7]具有相同的正确率,而Dalamagas方法[ 8]因为计算结构概要时修剪太过拟合,所以导致正确率有所下降。在有层数信息的实验数据中,如D1~D5数据集,CXLI具有更好的正确率。Flesca方法经过时间序列编码和傅里叶变换计算相似度,其复杂度为 O( Nlog N),所以其优势在于高效的相似度计算过程,这是一种牺牲精确度而换取时间的策略。
| 表1 聚类结果正确率 Table 1 Precision of clustering result % |
使用Nierman[ 7]、Dalamagas[ 8]、Flesca[ 9]和CXLI方法对5000到20 000个XML文档进行相似性度量,相似度计算时间消耗如表2所示。
| 表2 时间消耗 Table 2 Time cost ms |
根据表2可知,Flesca方法[ 9]计算相似性速度最快,CXLI与Nierman[ 7]以及Dalamagas[ 8]方法耗时基本相同,且都呈线性增长,算法具有良好的可扩展性。说明在聚类过程中考虑层数信息,不会增加额外的时间消耗。
在进行XML相似性度量时,XML数据层次性是影响XML相似度的因素,应该禁止在不同层次上的子树插入与删除操作。CXLI方法可以用于XML相似性度量的所有应用领域。在计算时间基本相同的情况下,CXLI方法精确度更高。另外,本文理论可用在XML动态特征识别领域。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|