



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于空域和频域的图像显著区域检测
[纪超 , 刘慧英, 孙景峰, 贺胜, 黄民主]
, 刘慧英, 孙景峰, 贺胜, 黄民主]
, 刘慧英, 孙景峰, 贺胜, 黄民主]
|
|


纪超(1987),男,博士研究生.研究方向:图像处理与机器视觉.E-mail:dachao9898@163.com
根据人眼视觉注意机制,提出将图像在空域中采用局部复杂密度对比和全局颜色分布估计,在频域中通过有效频段分割的方法分别提取显著特征,再仿照细胞调节原理进行特征组合。局部复杂密度对比是模仿万有引力定律,通过稀疏基建模的方式计算视觉注意力的大小;提出在频域内采用有效频段分割,结合幅度信息提取显著特征后加权合成。仿真实验证明本文算法能高效地检测出场景中的显著区域。最后将本文算法应用于虚拟与现实交互中检测真实场景中的有效区,效果良好。
According to the human visual attention mechanism, an image salient region detection method is proposed. The salient features of image are extracted in spatial domain using local clutter density contrast and global color distribution estimation, and extracted in frequency domain using the efficient band divided method. Then, referring to the principle that cells respond to stimuli, such features are combined using the theory of feature combination. Local clutter density contrast imitates the law of universal gravitation, computing the visual attention on sparse matrix model. The efficient band divided method is used in combining information of amplitude for salient feature detection in frequency domain, later utilizes all features with weight. Experiment results show that the algorithm can effectively extract salient regions. The visual attention model is effectively applied to virtual and reality interaction to detect the effective region in real scene.
视觉注意机制是灵长类动物在漫长的生物进化中的产物。人眼视觉系统总能迅速把注视点集中到自己感兴趣的目标上,这种能力是建立在复杂的生理结构基础上,涉及心理学、神经学和生物仿生学等多个领域。运用视觉选择注意策略及人眼主动感应能力解决复杂问题是近年来计算机视觉研究的热点,可应用于感兴趣物体目标识别、图像分割、自适应压缩、内容感知、图像编辑和图像检索等方面。
国内外在图像显著区检测研究中,具有代表性的有Itti等[ 1]提出经典的视觉注意模型,简称Itti模型;Seoand等[ 2]提出残留谱显著性检测方法(SR),出发点是基于图像的信息量编码原理,利用自然背景的傅里叶频谱统计特性,通过频谱残差的傅里叶逆变换得到显著图,但该算法倾向于检测目标区域的边缘,计算量较大;GBVS算法[ 3]是基于图的显著区域提取方法,在图上建立马尔科夫链,链的平衡状态反映了随机游走者在每个节点上所花时间的积累,这种积累程度与视觉显著性等价;Achanta等[ 4]提出频率协调技术(FT),指出显著区域往往分布在高频部分,但实际中很多噪声也分布在高频中,因此无法从根本上界定高频的截止频率;Goferman等[ 5]提出的CA算法是根据图像中新颖的特征具有高显著度,通过模仿视觉组织的工作原理建模来突出显著特征;2011年,Chen等[ 6]提出HC算法是依据像素之间的色彩对比差异来分配像素的显著值,并以此产生高分辨率的显著特征图。对于复杂的图像结构,很难用底层的特征描述和表示,研究中发现大脑皮层对图像的理解存在稀疏结构,研究成果证明通过ICA训练的基是对应于V1细胞的响应,因此任意图像都可以用一组相对小的描述子(通常称为字典)来表示和编码[ 7];并且稀疏结构是基于图像统计学分析,具有高阶统计特征;采用稀疏基的最大优点在于图像中的小块在稀疏基上的响应是独立的,有利于通过联合概率分布计算信息熵,从而高效地检测图像的显著特征。
本文通过在空域和频域中分别提取同幅图像的显著特征,最后采用特征组合的方法得到显著区域。
首先在空域中通过局部复杂密度对比和全局颜色分布估计[ 8]的方法分别提取同幅图像的显著特征。
在显著区域检测中,本文提出仿照万有引力定律来计算显著点。首先将一幅图像中的各像素点看做是有质量的物体,由于各像素点的纹理、颜色、梯度等特征信息不同即代表各点的密度不同,所以各像素点的质量也不同。如果把人眼也看做一个有质量的质点,那么在眼睛与像素点之间会产生类似于万有引力的一种力,可称为视觉注意力,计算式如式(1)所示。由于眼睛质量 m e固定,视觉注意力 F s的大小就取决于像素点的质量 m i与眼睛与像素点之间的距离 l i。由于像素点的大小一样,所以 m i和像素点的密度成正比,即像素点的复杂度越大,该像素点质量越大,视觉显著力越大,该点越显著;某区域的复杂密度越大,则该区域就越显著。
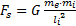 | (1) |
Bruce等[ 8]提出图像区域内所包含的信息量能反映该区域的复杂程度。本文引入局部特征信息量的多少来衡量图像局部的复杂密度大小。文献[ 9]提到图像的特征信息就是各部分对应熵的集,所以本文通过在稀疏基上建模来计算图像信息量。
稀疏表达原理认为:视觉系统中简单细胞的感受野能够被某些基函数所刻画,这些基函数被认为是神经元的响应。因此一个图像块 A可以表示成一组基的线性组合,如式(2)所示:
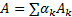 | (2) |
式中: Ak和 a k分别表示第 k个基和对应的响应系数; F k= A k-1是第 k个滤波函数; a k通过式(3)计算得到:
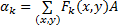 | (3) |
本文是从18个人的眼动数据库中抽取93 312个注意块,采用FastICA方法来学习基函数,基函数的大小 N为:6×6×3=108。图1显示了从注意点上学习得到的基。
 | 图1 学习训练的基Fig.1 Eye-fixation patches learned |
首先通过式(4)计算特征信息的复杂密度 SL、再通过式(5)计算平均值 SL。
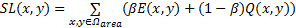 | (4) |
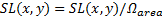 | (5) |
式(4)中:参数 β是平衡图像复杂度中熵和能量的因子,本文实验中选取 β值为0.3; E( x, y)和 Q( x, y)表示熵和能量,计算方法如式(6)(7)所示。
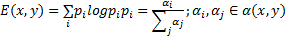 | (6) |
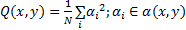 | (7) |
由于视觉注意力 F注意力的大小还和眼睛与像素点之间的距离 l有关,假设眼睛与图像的中心像素刚好为平视关系,那么此时的 li最小,其他像素与眼睛之间的距离 li可通过该像素到中心位置来确定位置权重PW,计算方法如式(8)所示。其中( Cx, Cy)表示图像的中心位置,而( W, H)表示图像的宽和高。
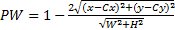 | (8) |
局部对比特征是一个反映图像显著信息的重要因素。本文采用“中心-周围”领域加权算子计算,能很好地提取显著物体的整体信息,还具有平滑边缘的功能。方法如式(9)(10)所示。
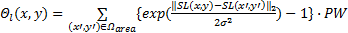 | (9) |
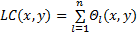 | (10) |
式中: Θl ( x, y)表示“中心-周围”算子; Ωarea是( x, y)的邻域。本文实验中 Ωarea的大小是4×4,尺度大小为5。叠加各尺度特征得到 LC( x, y)后再增加一个运算:对其中的每个元素值进行放大,在综合考虑计算时间和实验效果的前提下选择对每个像素值进行平方,此操作可以扩大显著图中像素值的大小对比,使得显著像素点更加明显,同时减少冗余信息,得到显著区域 S r。
一幅图像中某种颜色在整个空间上分布越广泛,那么它对于显著性的贡献就越小;分布越集中的颜色在整个颜色空间中所占的显著性权重越大[ 10]。图像显著区域颜色相对于背景颜色变化范围更广,而背景颜色较单一,所占的区域较多。本文首先通过颜色空间平滑操作来大大减少计算量和随机性给计算显著值造成的影响,再通过估计图像中的颜色空间分布,最后去除背景,得到显著区域。
首先将所有颜色量化为颜色直方图,颜色的总数为 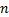
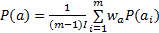 | (11) |
式中: 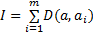
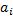
然后采用高斯混合模型(GMM)来估计特定颜色的空间分布。首先,用 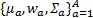
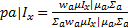 | (12) |
每个颜色成分 a空间位置的水平方差 V h ( a)如式(13)(14)所示:其中 x h是像素 x的 x轴坐标,| X| a= Σ x p( a| I x),垂直方差 V v ( a)可用类似的方法定义。
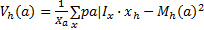 | (13) |
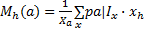 | (14) |
成分 a的空间方差可表示为 V( a)= V h( a)+ Vv ( a),再通过归一化因式( V( a)←( V( a)- min a V( a))/( max a V( a)- min a V( a)))将{ V( a)} a规范到范围[0,1]。最后,颜色空间分布特征 F a ( x, I)由式(15)表示为加权和的形式:
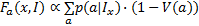 | (15) |
由于真实场景存在人为和环境因素的影响,那么图像拐角或边界的颜色空间方差会受影响。为了减少引入的误差,本文采用中心加权的空间方差特征进行修正,定义为式(16):
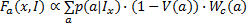 | (16) |
式中: 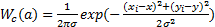
由于目前对幅度频域的认识还不够深入,本文在频域分析中提出有效频段分割算法(Efficient band divided,EBD)来提取显著特征。EBD算法的出发点为:每个物体或者有意义的区域都含有丰富的纹理特征;显著物体的纹理特征相对于非显著物体的走向更为相似和一致;显著物体或者区域所占据的频段既不是高频也不是低频[ 12]。由于Lab颜色空间更接近人类视觉,所以本文在Lab颜色空间中进行计算。
首先根据二维Log-Gabor函数式在特定朝向下具有带通滤波器的性质,在频域中对原图 I( x, y)进行滤波,如式(17)所示:
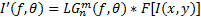 | (17) |
在极坐标下建立二维Log-Gabor滤波函数 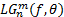
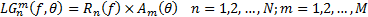 | (18) |
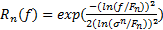 | (19) |
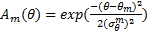 | (20) |
式中: F n为中心频率,是以像素点的个数为单位,根据空域中滤波器的波长 λ,通过 Fn=( λn)-1求得; θm为滤波器的朝向,取{0,π/4,π/2,3π/4}; 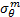
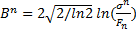 | (21) |
然后将幅度频谱分成均匀的频段,利用每个频段与全部的相位频谱进行傅里叶反变换,最后加权合成。具体计算方法如式(22)(23)所示:
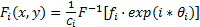 | (22) |
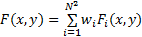 | (23) |
式中: F和 F-1是傅里叶变换和反变换; Fi(x,y)表示第 i个频段构造的显著图; C i是幅度频谱特征的归一化因子; w i是每个频段的权值; N2表示频段的个数;F(x,y)表示最终的显著特征集合。由于显著物体的有效区大部分在中频段,而边缘和噪声多为高频段,所以根据实验效果对比得出最优权值分配如下:低频段权重定为0.2,中频段权重定为0.5,高频段权重定为0.3。最后对所有加权后的频谱信息求和得到显著图 S f。
算法中参数 N决定频域被分成频段的个数,影响显著图的特征效果。图2为不同的 N对显著图特征的影响。
 | 图2 不同 N值下的显著图的效果Fig.2 Saliency detection by different N |
从实验结果得出: N越大,越能突出物体的内部信息,但边缘信息越模糊; N越小,越能突出边缘信息,但内部信息丢失越多。本文从实验效果和时间综合权衡, N取固定值40。
文献[13][ 14]指出没有任何神经网络结构和相关领域研究能证明特征之间完全是线性组合,传统的特征组合方法一般不会考虑特征之间相互作用问题,权值指定大都依赖经验值或机器学习。本文提出采用特征独立和联合作用的组合方式进行特征融合:其中一部分为特征的独立线性组合,另一部分为特征的联合作用部分。假设特征集合 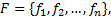
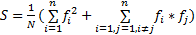 | (24) |
本文在得到图像空域和频域特征的基础上,通过特征独立和联合作用的方式将 S r、 S g和 S f组合形成最终的显著图 S。具体计算公式如下:
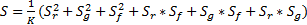 | (25) |
式中: K是 S归一化因子。
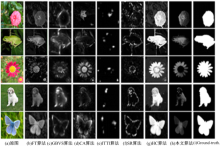
为了验证算法的有效性,本文分别对图像进行显著区域检测的准确度和复杂度对比实验。实验硬件为Intel 酷睿i5处理器,主频3 GHz,内存2 GHz的配置,软件为Matlab 2010a。实验结果如图3所示,可看出:本文算法比ITTI算法和GBVS算法、CA算法能更好地突出显著物体的内部信息;比SR算法、HC算法能得到更完整清晰的显著物体边缘区域;比FT算法更能区别显著区域与背景的对比度。
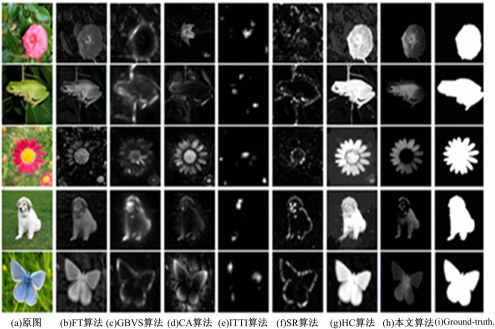 | 图3 通过不同算法提取显著区域Fig.3 Saliency detection by different algorithms |
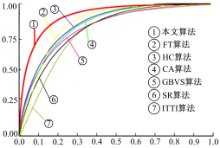
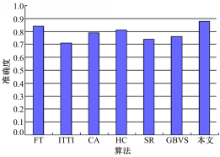
算法准确度对比也可以用ROC曲线来衡量,图4和图5显示了不同算法的ROC曲线和对应的曲线面积图。易知,本文算法能更好地获取显著区域。
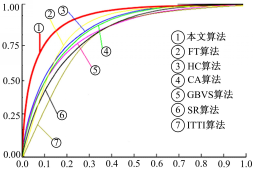 | 图4 不同方法的ROC曲线Fig.4 ROC curves of saliency detection by different algorith |
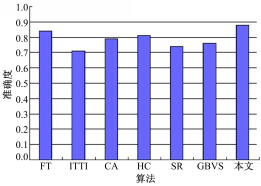 | 图5 不同算法在ROC曲线下的面积Fig.5 Area under ROC curves of different algorithms |
复杂度对比实验是从MSRA图库中选取500幅大小为400×300的图像,均分成5组进行处理,分别计算出每组处理方法所用的平均时间。实验结果如下:CA算法耗时9.7 s,ITTI算法耗时6.3 s,GBVS算法耗时21.2 s,SR算法耗时9.5 s,FT算法耗时8.6 s,HC算法耗时8.9 s,本文算法耗时4.7 s;其中ITTI算法和FT算法采用C++编程,其他算法均采用Matlab。
虚拟与现实交互技术是一门新兴的综合技术体系,用户借助必要的设备以自然的方式与虚拟环境中的对象进行交互。其中虚拟与现实场景的合成是虚拟与现实交互中最关键的部分。比如在电视节目中一些美轮美奂,惊心动魄的场景和特技,大都是通过软件制作出的虚拟场景与拍摄的真实前景进行合成所得,目前合成方式是检测前景中每一个像素点,例如在演播室拍摄的图6(a),
 | 图6 合成效果图Fig.6 Result of virtual and reality interaction |
如果像素值是蓝色就换成对应虚拟场景的像素值,但此方法会把前景中的虚景区(如图6(a)左上方的污区)当成有效区保留下,结果如图6(b)所示。
本文提出并验证采用本文算法能完整检测出前景中的有效区,图7(a)为经本文算法提取的显著图,图7(b)为经过本文算法处理后的真实前景与虚拟背景合成的效果图,可以看出污区已经被剔除。
 | 图7 本文算法合成效果图Fig.7 Result of virtual and reality interaction by proposed method |
根据灵长类动物视觉系统所感觉到物体不仅和自身形状有关,还受周围环境的影响,并结合对图像的高级视觉关注特性,本文提出分别在空域和频域对图像进行显著特征提取,再经过特征组合理论合成为显著图。实验证明该算法能较准确地检测图像的显著区域,提高算法的运算效率,与其他方法相比,本文的算法具有以下几个优点:①模仿万有引力定律,通过视觉注意力的大小来计算像素信息量的多少,能更真实准确地反映图像的显著区域;②空域中结合局部与全局信息能更好地提取显著物体的整体信息并确定其边界,而不只是一个模糊的范围;③将频段作为幅度频域和相位频域处理的基本单元可得到更精确的检测效果;④将此算法用在虚拟与现实交互中可以更方便、更高质量地提取图像的有效区,是有广泛的应用场合和可观的经济效益。由于本文算法和目前视觉显著性算法大都采用下意识的、由数据驱动的纯外部刺激的显著性提取方法,这类方法要求图像的前景与背景要有较强的对比,并不适应于一般图像。因此在以后的研究中应加入更多的目标驱动或依赖具体任务的显著性提取方法,以便适用于更多类型的图像。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|