

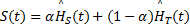
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
视频显著性计算模型及其在广告插入中的应用
[赵世杰 , 韩军伟, 贺胜, 程塨, 郭雷]
, 韩军伟, 贺胜, 程塨, 郭雷]
, 韩军伟, 贺胜, 程塨, 郭雷]
|
|


赵世杰(1987),男,博士研究生.研究方向:图像处理,机器学习.E-mail:857367398@qq.com
提出了一种新的基于频域分析的视频显著性计算模型。该模型具有计算量小、速度快的优点。首先将原始视频处理成一系列视频场景图片;然后根据频域分析方法分别计算视频的空域显著图和时域显著图,并用Renyi熵度量显著图的显著性;最后,融合时域和空域显著性结果,得到视频的显著性曲线。将本文模型应用于视频广告插入系统中并与现有方法比较,结果证明了其有效性。
This paper proposes a novel video saliency computational model based on frequency domain analysis, which is simple and efficient. First, the original video is parsed to a series of consecutive video scene images. Then, the space domain saliency and time domain saliency of the video scene images are computed, respectively. In each domain, the saliency of each frame is estimated by using Renyi entropy. Finally, both space domain and time domain results are fused to obtain the overall saliency. Application results in video advertising system and comparison with state-of-the-art approach demonstrate the effectiveness of the proposed model.
针对视频显著性分析问题,许多研究者提出了不同的计算模型。根据计算显著性是否需要提取视频或物体的特定特征,视频显著性研究主要分为两个阶段。第一阶段,Itti等[ 1]提出了一个自底向上数据驱动的数学计算模型,建立了NVT工具箱。之后Walther等[ 2]扩展了这个模型,并建立了STB工具箱。Liu等[ 3]将动态和静态显著性信息,以及时空域内在联系等信息在条件随机场中融合起来检测视频显著性。这些计算模型能够很好地计算视频的显著性信息,但是计算前需要首先提取视频的特定特征信息,计算复杂度高,参数设置繁琐,结果往往与参数设置有很大关系。第二阶段,Hou等[ 4]在2007年提出一种基于傅立叶变换的残留谱显著性检测方法。Guo等[ 5]在2008年提出一种基于傅立叶变换相位谱信息的显著性检测方法。这些计算模型不需要依赖参数和计算视频或图像的某一方面特征,运算速度快,给视频显著性计算带来了新的思路和方向。但是Hou的模型[ 4]只考虑了静态图像,只使用了傅立叶变换中的相位谱信息;Guo的方法[ 5]只采用了傅立叶变换中相位谱信息进行视频显著性的计算。考虑到傅立叶变换的幅度谱和相位谱都含有丰富的显著性信息,本文提出一种结合幅度频域和相位频域,以频带为基本处理单元的视频显著性计算模型。首先将视频处理为空域和时域输入所需的视频场景序列;然后对时域和空域的视频场景序列进行傅立叶变换,将得到的幅度频谱均匀切分成子频带,利用每个子频带幅度谱与全部的相位频谱进行傅里叶反变换,得到图片序列的空域显著性和时域显著性,并用Renyi熵量化显著性值;最后,融合时域和空域显著性结果,得到视频的显著性曲线。将该方法用于视频广告系统中,可以有效获得合适的广告插入点,改善了视频广告的效果。
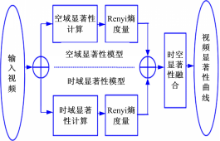
本文提出的视频显著性计算模型如图1所示,首先将原始视频处理成一系列视频场景图片;然后根据频域分析方法分别计算视频的空域显著图和时域显著图,并用Renyi熵量化显著图得到显著性值;最后,融合空域和时域显著性结果,得到视频的显著性曲线。
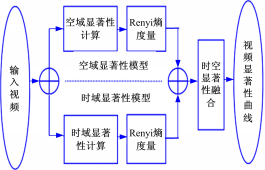 | 图1 本文的视频显著性计算模型Fig.1 Computational video saliency model1. |
对视频进行显著性分析前,首先对输入视频进行预处理。将输入视频分解为视频场景序列,每一个场景由一个关键帧表示,关键帧由文献[ 6]中的算法提取得到。
视频空域显著性是指根据视频场景灰度图像计算出的显著性,它的输入为视频场景灰度图像。空域显著性计算模型首先对输入的视频场景灰度图像进行频域分析,提取空域显著图,然后利用Renyi熵量化空域显著图得到显著性值。
假定第 t张视频场景图像为 F( t),t∈{1,2,…, N}, N为视频场景的总数。 F( t)的灰度区间为[ a1, a2],则通过下式进行灰度调整,得到视频场景灰度图像 F g( t)的灰度值:
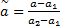 | (1) |
式中: a和 
通过对 F g( t)进行频域分析,可得到 F( t)的空域显著图,具体过程如下:
(1)对 F g( t)进行二维傅立叶变换,得到视频场景图像的幅度谱和相位谱信息:
Ag(t)=amplitude(F[Fg(t)]) (2)
Pg(t)=angle(F[Fg(t)]) (3)
(2)将幅度谱 A g( t)划分为多个子频带,对每一子频带的幅度谱和全局的相位谱进行傅立叶反变换,得到该子频带的显著图:
 | (4) |
在上述公式中: F和 F-1分别表示二维傅里叶变换和逆变换; Agi(t)表示幅度谱中第 i个子频带; Sgi(t)表示该频带显著图;Ci是该子频带显著图的归一化因子,用以保证 Sgi(t)的值在[0,1]范围。
(3)由下式计算整个视频场景的空域显著图:
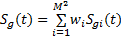 | (5) |
式中: M2是均匀划分子带的个数;wi是第 i个子频带显著图的权重。在本文中将权重设为统一值(单位值1); Sg(t)为计算得到的视频场景 F( t)的空域显著图。
得到空域显著图 Sg(t)后,按照1.4节所述的Renyi熵量化过程得到场景 F( t)的时域显著性数值 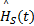
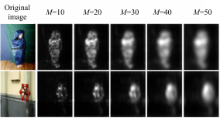
不同的频带个数 M2对结果有较大影响,本文分别测试 M为10、20、30、40和50的情况,显著图结果如图2所示。实验结果显示,不同的分辨率数目产生了不同的显著图:一定范围内,子带数目越小,视频显著图的显著性区域轮廓越好,计算量也越小。通过实验,选用 M=10。
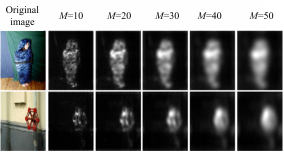 | 图2 不同的 M值对应的显著图结果Fig.2 Saliency maps with different M |
视频时域显著性的计算过程与空域显著性计算过程相似。首先对输入的视频场景序列进行频域分析,提取时域显著图,然后利用Renyi熵量化显著图的显著性值。两者不同的是,时域显著性计算的输入是视频场景的运动信息特征图序列。计算视频场景运动信息特征图的方法有很多,本文采用文献[ 5]的方法计算视频场景运动信息特征图。具体地:假定第 t张视频场景图像为F(t),r(t)、g(t)、b(t)分别是F(t)的RGB三个颜色通道,利用下式计算视频场景F(t)的运动信息特征图Fm(t):
Fm(t)=| I(t)- I(t-τ)| (6)
式中:I(t)=(r(t)+g(t)+b(t));τ是系数,通常设定为τ=3;Fm(t)表示第 t个视频场景的运动信息特征图。
通过对 F m (t)进行频域分析,可得到F(t)的时域显著图,具体过程如下:
(1)对 F m( t)进行傅立叶变换,得到运动信息特征图的幅度谱和相位谱信息:
Am(t)=amplitude(F[Fm(t)]) (7)
Pm(t)=angle(F[Fm(t)]) (8)
(2)将幅度谱Am(t)划分为多个子频带,对每一子频带的幅度谱和全局的相位谱进行傅立叶反变换,得到该子频带的显著图:
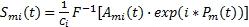 | (9) |
在上述公式中:Ami(t)表示幅度谱中第 i个子频带;Smi(t)表示该频带显著图;Ci是该子频带显著图的归一化因子,用以保证Smi(t)的值在[0,1]内。
(3)整个视频场景的时域显著图计算式为
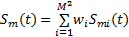 | (10) |
式中:M2是划分子频带的个数,M=10;wi是第 i个子频带显著图的权重;在本文中将权重设为统一值(单位值1);Sm(t)为计算得到的视频场景F(t)的时域显著图。
得到时域显著图Sm(t)后,按照1.4节所述的Renyi熵量化过程得到场景F(t)时域显著性数值 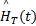
得到一个视频场景的显著图后,还需估计一个视频场景整体的显著值。之前的研究工作[ 7, 8]主要是通过线性组合显著图中的每个点的灰度值来得到整个视频场景的显著值,效果不是很理想。对于一幅图像,显著物体越分散,需要投放在这张图像上的注意力越多,这张图像越显著。因此,假设一幅图像显著点越分散,整幅图片的显著值越高。Renyi熵主要计算空间分布的离散程度,空间分布越分散,则对应的熵越大。因此,本文提出利用Renyi熵度量显著图中显著点的空间分布,将熵值作为整个视频场景显著值。受文献[ 9]的启发,用高斯分布来近似计算特征图中的像素分布。显著图中所有的位置都用等权值的高斯分布来计算:
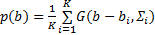 | (11) |
Renyi熵可以用下式计算得到:
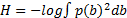 | (12) |
在混合高斯模型中,Renyi熵可以表示为
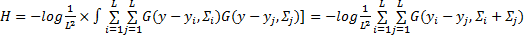 | (13) |
更进一步,可以由下式近似:
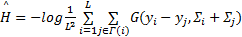 | (14) |
式中:yi表示显著图中的显著点 i的坐标;yi表示显著图中的显著点 i的八邻域内任一其他显著点的坐标; L表示显著图中显著点的总数;G(yi-yj,Σi+Σj)表示图像中显著点 i到显著点 j的混合高斯分布; 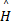
根据Renyi熵的定义,场景F(t)的空域显著性值 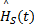
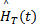
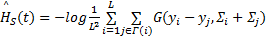 | (15) |
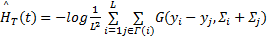 | (16) |
图3(a)(b)为两幅原始输入图像,图3(c)(d)为根据红绿对比特征得到的显著图。根据Renyi熵的计算原理,图3(a)的Renyi熵值 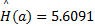
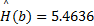
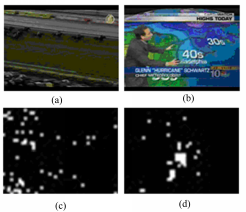 | 图3 不同图像的Renyi熵比较Fig.3 Comparison of Renyi entropy in different images |
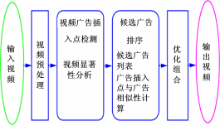
视频广告插入点的选取是视频广告智能插入技术的核心问题之一,本文提出的视频显著性分析方法可以帮助解决广告插入点的问题。通过视频显著性分析,选择视频显著性小的地方作为广告插入点,可以有效降低广告对用户的侵扰性,改善广告效果。为了验证本文方法的有效性,本文根据文献[ 11]实现了一个视频广告智能插入系统,其系统的框架如图4所示。
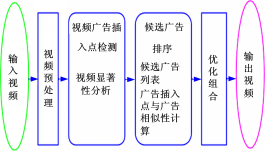 | 图4 基于视频显著性分析的视频广告系统框架图Fig.4 Framework of video advertising system based on video saliency analysis |
该系统由4个模块组成:视频预处理模块,视频广告插入点检测模块,候选广告排序模块和优化组合模块。在视频的预处理模块中,输入视频被分解为场景,每一个场景由一个关键帧来表示。广告插入点检测模块确定广告插入原始视频的时间点。广告插入点检测主要通过本文提出的视频显著性计算方法得到。候选广告排序模块确定了一个视频相关的广告列表和每个候选广告插入点与侯选广告的相关性。候选广告列表生成主要通过候选广告和视频的文本相关性得到。广告插入点和广告的相关性则通过计算广告插入点和候选广告的文本相似性和视觉相似性共同得到。优化组合模块确定了输入视频最终选定的广告插入点和广告组合。
在得到候选广告和候选广告插入点的相关性后,基于输出视频的整体侵扰性最小、视频与广告的相关性最大、广告均匀分布的原则进行优化组合,得到最终广告插入点和广告组合,并将相应广告加入原始视频。
目前视频显著性分析研究中还没有一个被广泛接受的客观测试标准,本文采用普遍使用的主观测试方法对显著性分析的结果进行评价分析。在目前的视频显著性研究中,效果比较好的模型是Itti等[ 10]提出的Surprise模型,因此本文主要与Surprise模型进行比较。
本文采用的测试数据是2011年4月12日美国NBA湖人和马刺比赛的视频,WMV格式,585 MB大小,整段视频持续的时间是1小时28分26秒,提取关键帧后得到10 614幅顺序排列的视频场景图片为480×320像素。实验采用的软件是Windows XP系统下的MATLAB R2011b,硬件是酷睿双核E7500,主频2.93 GHz,2 GB内存的计算机。
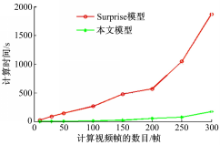
分别用Surprise模型和本文方法计算了8组不同数量视频帧的视频显著性,所用时间如图5所示。从结果可以看出,本文方法由于无需在提取图像特征上花费大量计算时间, 总体计算量大大减小,计算速度明显优于Surprise模型。
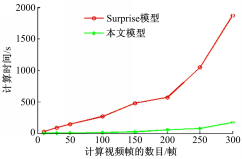 | 图5 不同方法的运算时间对比Fig.5 Computational time using different methods |
本文选取了实验提取的前50幅视频场景作为素材,分别用Surprise模型和本文方法进行视频显著性曲线提取。图6为视频11~30帧原始场景缩略图。
 | 图6 原始视频场景部分缩略图(11~30帧)Fig.6 Video frame samples(11~30th frames) |
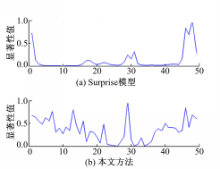
用本文算法得到的视频显著性曲线和用Surprise模型得到的视频显著性曲线如图7所示。
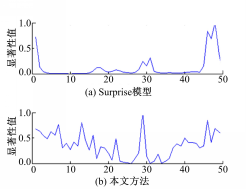 | 图7 用不同模型得到的视频显著性曲线Fig.7 Video saliency curves using different models |
以11~30帧的视频显著值为研究对象,对两种算法的结果进行分析。从图7中可以看出,本文算法优于Surprise模型计算得到的视频显著性曲线,主要表现在两个方面:①本文方法的显著性曲线将不同场景间显著性的差异明显地表现了出来,而Surprise模型计算出的结果中,视频显著性曲线的不同帧之间的显著值差异表现不明显,差距很小;②本文计算出的视频显著性曲线的走势与我们观察到的原始场景图片得到的趋势比较一致,例如16到17帧之间,原始场景有了较大转换,本文得到的视频显著性曲线的显著值有比较明显的提升过程,之后场景的显著区域比较集中,显著值减小,曲线也有对应的下降部分,比较符合我们的主观感知,而用Surprise模型计算出的视频显著性曲线的走势和观察的结果有较大的出入。
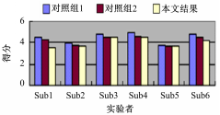
在本文中,邀请了6位实验者来整体评价实验结果。他们的年龄为20~25岁、均为计算机相关专业的学生,在测试之前均未看过原始视频。实验中设置了2个对照组与本文结果对比:对照组1:不相关广告,在固定时间点加入;对照组2:相关广告,在固定时间点加入;本文结果:相关广告,根据视频内容加入。
实验者根据自己的判断进行打分,相应的指标与实际越符合,分数越高,打分区间为1~5分。实验结果如图8所示。
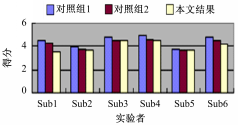 | 图8 广告侵扰性测试结果Fig.8 Intrusiveness test of video advertising |
从图8可以看出,采用本文视频显著性分析指导下得到的广告插入点对用户有较小的侵扰性,这也间接说明本文算法能够正确模拟人类视觉机制,找到视频中显著的点和区域,并生成正确的视频场景显著值。
提出了一种新的视频显著性计算模型并在视频广告插入系统中进行了验证。首先将原始视频处理成一系列视频场景图片;然后根据频域分析方法分别计算视频的空域显著性和时域显著性,并用Renyi熵量化显著性值;最后,融合空域和时域显著性结果,得到视频的显著性曲线。实验结果证明了本文方法的有效性。此方法还可应用到视频检索、视频摘要、视频跟踪、视频监控等领域。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|