
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于时空关系的复杂交互行为识别
引用本文
王生生, 杨锋, 刘依婷, 王伟烈, 李洋. 基于时空关系的复杂交互行为识别. 2014, 44(2): 421-426[WANG Sheng-sheng, YANG Feng, LIU Yi-ting, WANG Wei-lie, LI Yang. Complex interactive activity recognition with spatial-temporal relationship. 吉林大学学报(工学版), 2014, 44(2): 421-426] 
Permissions
Copyright©2014, 吉林大学学报编辑部
版权所有.吉林大学学报编辑部
基于时空关系的复杂交互行为识别
王生生(1974),男,教授,博士生导师.研究方向:时空推理,机器视觉.E-mail:wss@jlu.edu.cn
摘要
提出了一种基于时空关系和多观察值的三层隐马尔科夫扩展模型识别复杂交互活动的方法。根据多目标交互活动具有分层的性质和目标之间的时空关系,给出了提取3个粒度(整体,双人,单人)行为特征的方法。同时提出与之对应的多观测值三层隐马尔科夫扩展模型。实验结果表明:将新的特征提取方法和新的模型应用于复杂交互行为识别能得到较高的识别准确率和较好的鲁棒性。
关键词:
人工智能; 时空关系; 交互行为; 三层多观察隐马尔科夫模型; 三层特征
中图分类号:TP18
文献标志码:A
文章编号:1671-5497(2014)2-421-6
Complex interactive activity recognition with spatial-temporal relationship
Abstract
A complex interactive activity recognition approach with spatial-temporal relation and an extended Hidden Markov Model with multi-observations and multi-layers is presented here. Interactive activities involving multi-objects are naturally hierarchical and related with spatial-temporal relationship. The multi-granularity features (group, two persons and single person) are used. A new model, Multi-observations Three-Layers Hidden Markov Model (MTHMM), corresponding to these features is put forward. The experiments show that the new feature extraction method and the new model have a good performance and a fair robustness in complex interactive activity recognition.
Keyword:
artificial intelligence; spatial-temporal relation; interactive activity; hidden Markov model with multi-observations and three-layers; features with three layers
0 引 言
交互行为识别在视频监控等领域有着广泛的应用前景[
本文研究复杂场景中多目标之间的交互行为活动,提出一种提取3个粒度的行为特征(顶层特征,中间层特征,底层特征)的方法。在顶层特征上场景中所有目标的行为将被提取为整体特征因子 φ;在中间层特征中场景中目标两两之间的定量时空关系QSTR(Quantitative spatial-temporal relationship)反映了两个目标之间的行为关系;在底层特征中描述了场景中目标自身的特性。行为识别采用三层的行为特征:顶层特征(group),中间层特征(intermediate)和底层特征(bottom),提出基于时空关系特征和隐马尔科夫扩展模型的交互行为识别框架,在该框架下提出了一种多观测值的三层的隐马尔科夫扩展模型(Multi-observations three-layers hidden Markov model,MTHMM)。
1 定量时空关系特征提取
以往的大多数研究只集中底层特征的研究,仅有少量工作是放在中间层特征和顶层特征,更少将这几层的定量时空关系特征联合起来分析。表1中顶层特征、覆盖的矩形块大小、重叠等组合成的特征因子表示了整个大的场景之间所有目标之间的关系;两两目标之间的定量时空关系(QSTR)则表明在交互过程中两两目标之间的在时间和空间上变化关系及相互之间的影响;目标的轮廓大小,速度位置的变化反映出目标在底层的特征。三个层次的特征从整体到局部再到个体,鲜明的层次结构体现了交互行为活动的层次性。
| 表1 交互行为特征表 Table 1 Features of interactive activities |
1.1 底层特征提取
定义1 在任何自然活动中,运动目标随着时间移动所形成的轨迹称为运动轨迹,一条轨迹就是有一定时间长度 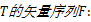

式中:向量 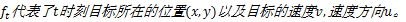
在提取底层特征时,运动目标用矩形框圈出来, 
1.2 中间层时空特征提取
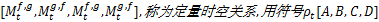
在以往很多的交互行为研究中,两两目标之间的关系往往简单地使用两目标之间的距离表示,而忽略了目标之间在时间和空间的相对变化关系,文献[11]提出使用定量时空关系QTC(Qualitative trajectory calculus)研究多目标的运动。本文提出提取基于定量时空关系的中间层特征的方法,更加准确地描述两两目标之间的关系。
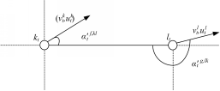
关于两个运动目标之间的时空关系,本文应用了方向、距离、时间3个维度来表示目标之间的时空关系。对于任意两个目标对象之间的时空关系如图1所示:
 | 图1 两个目标对象之间的时空关系图Fig.1 Spatial-temporal relationship of two objects |
定义2 从时刻 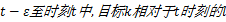
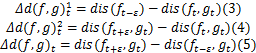
式中: 
定义3 定义 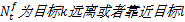
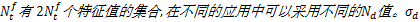
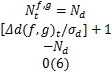
当 

式中: 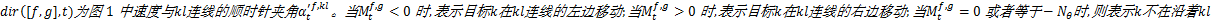
定义4 定义两个目标之间的中间层特征向量为四维向量
1.3 顶层特征提取
顶层特征提取采用最小边界矩形MBR表示,矩形的大小表示目标的大小,矩形块之间的距离则表示场景中目标之间的距离,当场景中的目标相互靠近遮挡时,两个目标就会被圈成一个更大的矩形块。本文提出针对多目标场景中所有目标的顶层行为特征算子,该算子用 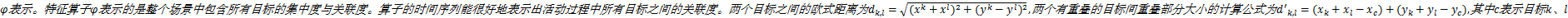
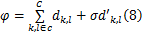
式中: 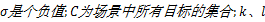
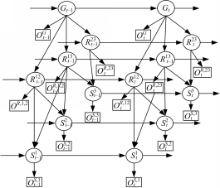
2 MTHMM模型:定义,学习
MTHMM模型可以用五元组表示为 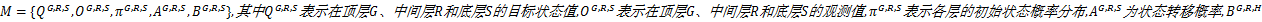

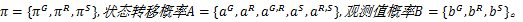

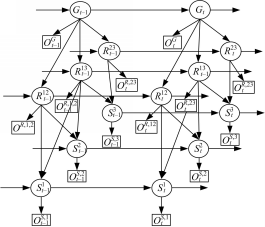 | 图2 HTHMM拓扑结构图Fig.2 Topological structure of HTHMM |
Baum-Welch算法HMM中标准参数重估算法需要计算 

3 实验结果和分析
根据不同场景选用不同的MTHMM模型对多目标行为进行分析。MTHMM是一个三层模型,当场景中人数超过一定数量时可以根据场景中目标之间的距离等做一些限制,以减少中间层的维度,从而减少计算复杂度。在本实验中,应用本文模型对两人行为和三人行为进行识别。模型中的观测数据 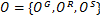
 | 图3 交互行为Double-inter5的关键帧视图Fig.3 Key frame of the Double-interactive activity 5 |
3.1 双人行为识别及效果
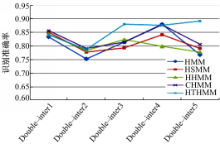
双人视频数据集包含:①Double-inter1,两个目标穿过场景,其中一个目标跟着另一个目标,一直保持一段距离;②Double-inter2,两个目标分别进入场景,而后展开搏斗,搏斗过后分别离开场景;③Double-inter3,两个目标进入场景,相遇,然后并行离开场景;④Double-inter4,两个目标先后进入场景,后进入场景的目标赶上并超过先进入场景的目标;⑤Double-inter5,两个目标穿过场景,第一个运动目标往前走,另一个运动目标跟在后面,然后后面的运动目标加速追上前面的目标,最后并排离开。实验中的视频时长主要分布在12~15 s,约250~350帧。图3是Double-inter5交互视频中几个关键帧的展示,以及各个时间段中目标运动状态的变化说明。对于两个目标的交互行为识别,MTHMM模型中顶层的特征因子由式(8)计算出,其中需要计算每个关键帧中目标之间的距离,顶层特征算子为正,若目标有重叠(如并排行走),则因为式(8)中参数 
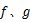
为了进一步确认对于双人行为识别的准确率,在相同的数据集上,本文选择HMM、HSMM、HHMM和CHMM这几个模型作为比较,对于HMM、HSMM,选择底层特征(( x, y)中心位置, 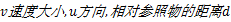
 | 图4 五个两目标交互行为识别准确率折线图Fig.4 Line chart of the accuracy rate of double- interactive activities recognition |
从图中可以看出,基于时空关系的HTHMM模型识别效果在多数情况下优于其他几个模型。
3.2 三人交互行为识别效果
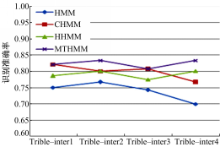
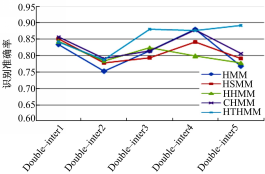
三个目标的交互行为的复杂场景中,实验数据包括以下3种行为:①Triple-inter1,三个目标并行进入场景,而后分开,分别离开场景;②Triple-inter2,三个目标从不同方向进入场景,相遇后一同离开场景;③Triple-inter3,两个目标进入场景,第3个目标迎面进入场景相遇,停留片刻分开;④Triple-inter4,第1个目标拿着包进入场景,后面尾随第2个目标,前面迎面走来第三个目标,第2和第3个目标配合抢走第1个目标的包。该视频数据集类似于两目标的数据集,由作者自行采集,视频长度也为12~15 s。当场景中的目标数量为 
 | 图5 多目标事件的识别准确率折线图Fig.5 Line chart of the accuracy rate of double-interactive activities recognition |
本文基于时空关系的三层MHTMM模型效果稍优于其他模型。
4 结束语
提出了提取交互行为活动的时空特征的新方法,并提出一个与之对应的新模型用于复杂交互行为的识别。实验结果表明,基于时空关系特性的新模型具有很好的识别结果。
The authors have declared that no competing interests exist.
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|