
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于IAMCS路由器的NoC延迟上界分析
[任向隆 , 高德远, 樊晓桠, 安建峰]
, 高德远, 樊晓桠, 安建峰]
, 高德远, 樊晓桠, 安建峰]
|
|


任向隆(1982),男,博士研究生.研究方向:计算机系统结构.E-mail:xianglong.ren@gmail.com
针对使用改进非对称多通道(IAMCS)路由器的片上网络(NoC)的最坏延迟上界问题,提出了一种基于网络演算的分析方法。通过对IAMCS路由器中流控阻塞、交换阻塞和通道阻塞进行分析,建立了与之对应的等价服务模型。将路由器服务模型扩展到对整个网络的分析,建立了前向等价服务分析网络。借助冲突树演算模型,推导了网络提供给流量的端到端等价服务曲线,进而得到了延迟上界模型。实验结果表明:该延迟上界模型可以界定仿真的最大延迟,且上界是紧致的。
Based on network calculus, a technique was proposed for analyzing communication delay bounds for individual flows in Networks on Chip (NoC) using Improved Asymmetric Multi-channel Structure (IAMCS) of router. The flow control blocking, switch blocking and channel blocking of IAMCS router were analyzed. Then, corresponding equivalent service models of them were constructed. By extending the router service model to the analysis of the entire network, the forward equivalent service analysis network was established. Furthermore, using the contention tree model, the equivalent service curves were computed for individual flows in the equivalent service analysis network, and then their delay bounds were derived. Experimental results show that the delay bound model can restrict the maximum delay of simulation, and the bounds is compact.
半导体技术的发展使得设计者可在一块芯片上集成数百个核,庞大的计算资源给通讯系统造成了巨大的压力。特征尺寸快速缩小,使互连系统的延时和优化成为制约系统性能的关键因素之一。另外,传统的总线及点对点互连结构受可扩展性、通信效率、功耗等方面的限制,使通信成为制约系统发展的瓶颈。NoC被认为是解决上述问题的一个可行方案[ 1]。
多媒体、HDTV、机顶盒和游戏盒等许多应用,都需要严格限制通信延迟上界。可预知通信系统中,即便是在最坏的情况下,延迟上界也必须保证[ 2]。而NoC资源共享且使用报文通信,会产生冲突,并由此带来性能的不可预测性。因而,NoC自诞生之日起就一直是一个引人关注的问题[ 3]。Lu等[ 4]提出了一种片上实时流调度的延迟上界模型,采用冲突树来刻画消息的直接和间接冲突。Shi等[ 5]完善了Lu的模型,提出一种使用虫孔交换和固定优先级调度的实时片上通信的分析方法。Qian等[ 2]针对使用信用流控的虫孔网络,提出一种基于网络演算的流量延迟上届分析方法。
另外,单通道路由器中队列头(HoL)阻塞时有发生,是制约NoC性能的一个重要问题。文献[ 6]提出了一种非对称多通道路由器结构,用于降低路由器输入端口的HoL阻塞。但在特定输出方向上,该结构仍为单通道,不能显著降低该方向上的HoL阻塞。为此,本文作者提出了一种改进的非对称多通道结构(IAMCS)[ 7],进一步提高了系统的性能。本文在文献[2,8]的基础上,针对文献[7]提出的IAMCS结构,构建相应的延迟上界分析模型,以便为使用IAMCS路由器的NoC系统提供快速、有效的QoS分析能力。
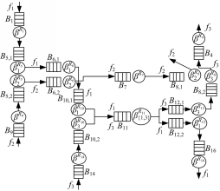
文献[ 7]提出的IAMCS结构如图1所示。其每个输入端口具有Dn个通道组(CG),每组对应一个独立的输出方向,且组内包含多条通道。以2D Mesh为例,每个输入端口具有5个CG,对应的输出方向分别为东、南、西、北和本地。输入报文根据其流出方向进入合适的通道组,然后路由器以轮询的方式为其分配组内的一条通道。该结构进一步减少了特定输出方向上的HoL阻塞,有效降低了报文平均延时、提高了饱和吞吐率和系统的性能。为了简化IAMCS的分析模型,假定每组具有相同的通道数量 m。
 | 图1 IAMCS路由器结构Fig.1 Structure of IAMCS router |
IAMCS路由器使用四级流水:路由计算(RC)、通道分配(CA)、交换机分配(SA)和交换机通过(ST)[ 8]。IAMCS路由器采用信用流控,当无可用信用时,将出现流控阻塞;在CA流水级,若多个报文争用相同CG的同一通道,将出现通道阻塞;在SA流水级,多个切片争用同一输出链路,将出现交换阻塞。接着,基于文献[ 2, 8]的工作并针对IAMCS路由器结构,对每种阻塞展开分析,构建该路由器的分析模型。
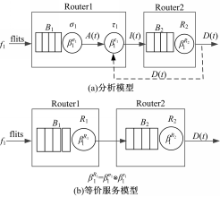
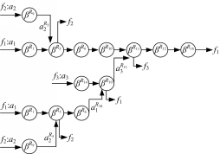
考虑到图2中流量 f1穿越相邻的两个IAMCS路由器的情形。由于切片传递和信用生成之间存在依赖关系,故不能直接使用网络演算的结论。为此,文献[ 2]将流控功能抽象成一个网络元素——流量控制器。然而,文献[ 2]的分析仅针对单通道路由器,每个输入端口仅有一条通道,且每个输出端口来自下游节点的流控反馈也只有一条;而IAMCS路由器为多通道路由器,每个输入端口具有多个CG,每个输出端口来自下游节点的流控反馈亦有多条,每条对应输入端口中的一个CG。因此,文献[ 2]的流控阻塞模型不能直接用于IAMCS路由器。
分析发现,在一条流量通过路由器的过程中,根据其输出方向,进入一个特定CG,切片输出过程受控于该CG对应的流控反馈;因此,针对一条流量路径,可借鉴文献[ 2]的流控阻塞模型,构建其流控反馈模型,如图2(a)所示。
 | 图2 流控阻塞模型Fig.2 Model for flow control blocking |
图2中,B1为f1流经路由器R1中通道的缓冲区大小;σ1代表R1的交换机;τ1代表R1的流量控制器。当f1通过R1和R2时,由σ1、τ1和R2组成的节点串为其提供服务, 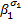
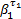
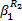
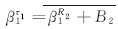 | (1) |
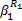 = =  | (2) |
消除流控反馈后,流控阻塞等价服务模型变为开环模型,如图2(b)所示。
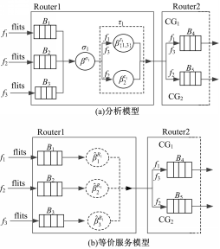
单通道路由器中,交换阻塞仅在不同输入端口争用同一输出端口时发生,且下游节点的流控反馈仅有一条;而在IAMCS中,某个输入端口的同一CG的多条通道间、不同输入端口的具有相同编号CG的多条通道间,均可能争用同一输出端口而发生交换阻塞,来自下游节点的流控反馈为多条。因此,文献[ 8]的交换阻塞模型同样需要扩展后才能用于IAMCS路由器。
不失一般性,考虑北输入端口的东CG中的两条流量f1、f2和西输入端口的东CG中的流量f3因争用东输出端口而竞争交换机的情况,其中f1、f3在下游节点的输出方向相同,进入同一个CG,共用一个流控反馈,而f2进入另一个CG,使用另外的流控反馈。将路由器抽象成交换机σ和流量控制器τ的组合,可构建交换阻塞分析模型,如图3(a)所示。
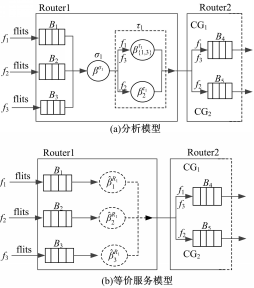 | 图3 交换阻塞模型Fig.3 Model for switch blocking |
在不同输入端口具有相同编号的CGs间,以及同一CG中的不同通道间,交换机均采用加权轮询策略为流量服务。交换机根据为流量fi配置的权重φi为其提供服务。假定权重分配确保在每次轮询中报文可以完全传送,不同报文的切片在传输过程中不会交错。
每次轮询时,若当前CG中轮到的通道缓存非空,交换机将为其服务φi个时钟周期后,再服务下一个CG的通道缓存。故一次轮询的最长时间为 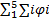
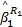 = = 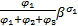 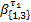 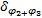 | (3) |
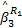 = = 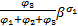 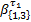 | (4) |
提供给f2的等价服务曲线为:
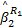 = = 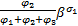 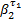 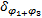 | (5) |
式中: 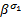
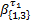
图3(b)给出了路由器R1提供给fi(i=1,2,3)的等价服务模型。
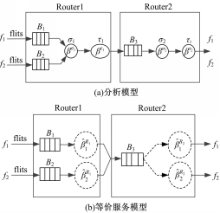
考虑图4(a)给出的情形:在路由器R1及R2中具有相同的输出方向的流量f1和f2,在R1的RC流水级被路由到相同的输出端口,进入CA流水级,f1和f2又因在R2中具有相同输出方向被分配到同一CG,并竞争该CG中的同一通道。通道分配竞争失败的流量将被阻塞,即通道阻塞。接着在SA流水级,通道分配成功的流量将独占输出链路,分配失败的流量将发生交换阻塞。
 | 图4 通道阻塞模型Fig.4 Model for ohannel blocking |
由于通道分配以报文为单位进行,且不同报文的切片在穿过路由器的过程中不能交错[ 8],路由器按照分配给流量fi的权重(ρi个报文)提供服务。使用1.2节交换阻塞的分析方法,可得R1提供给f1的等价服务曲线为:
= 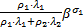 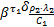 | (6) |
式中:λi为流量fi的报文长度,单位为切片; 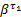
类似地,可得到R1提供给f2的等价服务曲线
如图4(a)所示,f1和f2的报文A和B在R2中占用同一通道,共享其缓存B3,且因争用同一输出端口而会再次出现交换阻塞,这与文献[8]通道阻塞的情形是不同的。然而,可将f1、f2放在一起看成一条聚集流,其切片缓存在B3中,该聚集流经交换机σ2后流向输出端口,其切片传输受下游节点流控反馈控制,其服务曲线记为 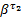
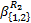 = = 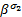 | (7) |
R2提供给fi的等价服务曲线依赖于它的冲突流在缓冲区入口处的到达曲线。路由器R2为流量f1提供的等价服务曲线为[ 2]:
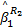
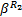
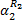
式中:
类似地,可得到为f2提供的等价服务曲线 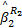
图5所示的NoC平台中同时存在f1、f2和f3三条流量,每条流量的路径也在图中标出。令f1为目标流,f2和f3为冲突流。假设到达服从仿射曲线,服务服从延迟-速率服务曲线和确定性路由算法,基于文献[ 2, 8]的方法推导目标流f1的切片延迟上界。
 | 图5 4*4网格结构的NoCFig.5 4*4 mesh NoC |
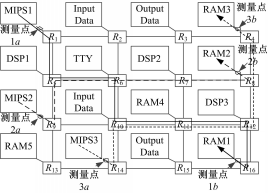
步骤1 构建等价服务分析网络。在路由器R5中,流量f1和f2发生交换阻塞;在路由器R10中,流量f1和f3发生交换阻塞;在路由器R11中,流量f1和f3发生通道阻塞。利用网络元素构建闭环分析网络,并将其简化成前向等价服务分析网络,如图6所示。图6中所有网络元素的服务曲线公式为:
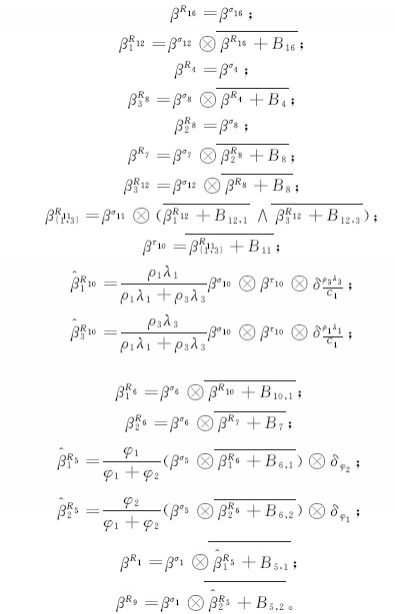
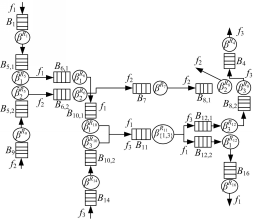 | 图6 等价服务分析网络Fig.6 Analysis network for equivalent service |
步骤2 构建冲突树。图6描绘了流量如何穿越串联的路由器,竞争共享缓冲区资源。对于这样的冲突关系,构建目标流量f1的冲突树,如图7所示。
 | 图7 目标流量 f1的冲突树Fig.7 Contention tree of target flow f1 |
步骤3 计算冲突树中流的输出曲线。采用深度优先策略遍历图7中的冲突树。首先计算流量f2流经树枝{R9}后,对于{R1→R16}的输出到达曲线为:
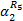 =α2Ø =α2Ø 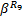 | (9) |
流量f2流经树枝{R9}后,对于{R1→R6}的输出到达曲线与式(9)相同。然后,使用文献[2]中的嵌套冲突模型,可得f1流经{R1→R6}后的输出曲线(也即对于分支{R14→R10}的到达曲线)为:
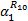
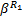
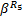
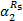
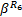
再次使用嵌套冲突模型,可得对于分支{ R1→ R16}, f3流经{ R14→ R10}后的输出到达曲线为:
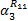
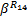

得到所有树枝流注入树干的到达曲线后,流量 f1的树干服务曲线可表示为:
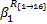 = = 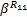 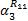 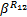 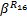 | (12) |
步骤4 计算延迟上界。目标流量 f1的延迟上界可由式(13)计算得到:
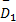
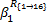
式中:H(·,·)为到达曲线与服务曲线最大水平距离的计算函数[ 2]。
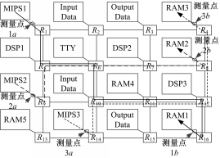
使用SoCLib[ 9]构建基于IAMCS路由器见图5的NoC平台。为该平台分配以下嵌入式应用:在MIPS1上分配一个MP3音频解码器,处理5 kB/s的音频流;在MIPS2上分配一个JPEG解码器,处理250×160的图像;在MIPS3上分配一个MPEG2视频解码器,处理176×144的视频帧。上述应用共生成三条多媒体流量(f1、f2和f3)。并在平台上设置三对测量点用于测量流量f1、f2和f3的通信延迟。同时运行这3个应用,采集各测量点的踪迹文件,得到它们的端到端最大延迟;分析3个多媒体流量的踪迹文件,推导它们的仿射到达曲线,并使用前面的分析模型对端到端延迟上界进行分析。
假定一个CG的所有通道的Buffer总数为60切片,在实验平台上对不同的配置进行了多次仿真;并分别设定f1、f2和f3为目标流,由分析模型推导它们的延迟上界,针对不同配置进行计算。
表1和表2列出了当报文长度分别为15和20切片,各目标流在CG所含通道数目m不同时,切片延迟的模拟和分析结果。仿真所得的最大延迟记为D max,分析得到的延迟上界记为 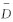
(1)IAMCS网络中,报文长度及缓存大小固定时,为通道组选择合适的通道数目可降低端到端延迟。这是因为:当通道组CG的缓存总量不变,CG中的通道数量m适当增加时,会降低HoL阻塞,而m超过合适的值后,造成通道中的缓存过小,流控反馈增加。本实验平台中,每CG中通道数目 m=2时延迟最小,与最大的通道需求为2相吻合。
| 表1 报文长度为15切片时延迟的模拟和分析结果 Table 1 Simulation and analysis results when the packet is 15 flits |
| 表2 报文长度为20切片时延迟的模拟和分析结果 Table 2 Simulation and analysis results when the packet is 20 flits |
(2)对所有设置均有D max<
| 表3 延迟上界紧致度 Table 3 Tightness of delay bound |
通过对IAMCS路由器信用阻塞、交换阻塞和通道阻塞进行详细分析,推导了其提供给流量的等价服务曲线,分别建立了对应的分析模型,进而得出一种使用IAMCS路由器NoC的端到端延迟上界分析模型。实验结果表明:该延迟上界模型可以界定仿真的最大延迟,且上界是紧致的。对采用IAMCS或非对称多通道路由器的NoC,该模型可有效地计算每条流量的最坏延迟上界,对设计进行指导和优化。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|