


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
指纹识别中未匹配细节点信息的挖掘与利用
[李天平1  , 李亚硕
, 李亚硕2 , 王帅强3 , 张擎2 , 尹义龙2 , 任春晓2 ]
, 李亚硕, 尹义龙|
|


李天平(1965),男,研究员.研究方向:图像处理与模式识别.E-mail:sdsdltp@163.com
针对基于细节点的指纹匹配中未匹配细节点,定义和提取了细节点比例、紧互对原型对距离、网格集合距离以及Hausdorff距离四个方面的特征,并将其作为辅助特征进行利用,通过在得分级上与一种已有的基于细节点的匹配方法进行融合,实现指纹识别。实验结果表明,融合未匹配细节点中的区分性信息后,指纹识别系统的性能得到了明显的提升,从而也证实了未匹配细节点中的确包含可以利用的区分性信息。
Defines and extracts minutiae ratio, tight pair-wise prototype distance, grid set distance, and Housdorff distance from minutiae as four auxiliary features. Fingerprint recognition is realized by fusing with an existed minutiae based matching method at the score level. Experiment results on databases of FVC2000, FVC2002 and FVC2004 for international fingerprint verification competition indicate that fused with the discriminating information of the unmatched minutiae, the performance of the fingerprint system is noticeably promoted. The results also verify that unmatched minutiae truly contain discriminating information.
指纹识别的核心步骤指纹匹配主要有四种方法:①基于细节点的匹配方法[ 1, 2, 3, 4, 5, 6, 7];②基于纹线的匹配方法[ 8, 9];③基于纹理的匹配方法[ 10, 11];④基于人工神经网络的匹配方法[ 12, 13]。其中基于细节点的指纹匹配方法,由于所使用的特征相对稳定、可靠,一直是指纹识别中最为基础、最为主流的匹配方法。但是,现有基于细节点的指纹匹配中,匹配结果只由成功配对的细节点数量来决定。未能形成匹配的细节点都被视为无用信息,没有加以利用。而实际上,未能形成匹配的细节点中,包含着较多的区分性信息,也应该用于提高指纹识别系统的性能。
基于上述思路,本文对未能形成匹配的细节点中包含的区分性信息进行了挖掘和利用,将其作为辅助特征,与一种已有的基于细节点的指纹匹配方法进行得分级融合,实现指纹识别,从而有效提高了识别性能。
(1)同源指纹与异源指纹:采集自同一手指的指纹图像,称为同源指纹;采集自不同手指的指纹图像,称为异源指纹。
(2)同源匹配与异源匹配:如果模板指纹和输入指纹是同源的,则称它们之间的匹配为同源匹配;如果模板指纹和输入指纹是异源的,则称它们之间的匹配为异源匹配。
(3)匹配区域:指一对模板指纹和输入指纹(实际上是特征提取后得到的一对平面细节点集合)在完成配准、进行匹配(同源匹配或异源匹配)后,所有成功配对的细节点所围成的最大区域。本质上,匹配区域是可用于相似程度度量的、模板指纹和输入指纹的有效重叠区域。
(4)未匹配细节点:虽位于匹配区域内、但却没有形成配对的细节点。
在同源匹配中,未匹配细节点的成因主要有三个方面:①由于图像本身存在形变、图像预处理技术不够完善等因素的影响,使得部分细节点定位存在较大偏差;②匹配过程中,匹配算法对成功匹配的条件要求比较高,使得部分本应形成匹配的细节点对难以实现匹配;③个别伪细节点的存在。
对于异源匹配而言,由于模板指纹和输入指纹来自不同的手指,匹配的结果只是找到模板指纹和输入指纹相似性最大的局部区域作为匹配区域。显然,异源指纹的匹配本质上是一种“伪匹配”,但是,当图像质量比较差、面积比较大、提取的伪细节点数量很多、分布比较密集时,也有可能在局部重叠区域(匹配区域)产生足够多的、满足匹配条件的细节点对,这也是指纹识别中产生误识的最主要原因。异源匹配中,未匹配细节点的产生,本质上只是一个随机性质的问题。
宏观上看,同源匹配和异源匹配,匹配区域内未匹配细节点信息是有明显差异的:①对同源匹配而言,一般来说,匹配区域内未匹配细节点的数量会很少;而对异源匹配来说,匹配区域内未匹配细节点的数量往往会比较多;②对同源匹配而言,本应形成匹配、但未能成功匹配的点对,在位置上仍存在着很强的对应关系(尽管有一定的定位偏差);③对同源匹配而言,匹配区域内的未匹配细节点在分布上存在着较高的一致性和规律性;而对异源匹配而言,匹配区域内的未匹配细节点在分布上几乎没有任何一致性和规律性。
所以,从成因和特点来看,同源匹配和异源匹配中未匹配细节点是包含了一定的区分性信息的。如果能有效挖掘其中的区分性信息并加以利用,可以提高指纹识别系统的性能。
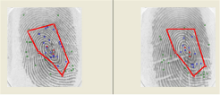
一般来说,同源匹配和异源匹配中匹配区域内的未匹配细节点数量会有一定差异。如在图1和图2中,红色点表示匹配细节点,蓝色点表示匹配区域内未匹配细节点,红色框框出匹配区域。两幅图中,虽然匹配细节点对数量都为10,但同源匹配(图1)中未匹配细节点数量明显少于异源匹配(图2)中未匹配细节点数量。
 | 图1 两幅同源指纹的匹配结果Fig.1 Matching result of two homologous fingerprints |
 | 图2 两幅异源指纹的匹配结果Fig.2 Matching result of two heterologous fingerprints |
本文用未匹配细节点与匹配细节点的比例来刻画未匹配细节点数量上的特点,此比例可以在一定程度上分辨同源匹配和异源匹配,是可以利用的区分性信息。将此比例记为R,计算式如下:
R=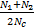 | (1) |
式中:N1为模板指纹匹配区域内未匹配细节点个数;N2为输入指纹匹配区域内未匹配细节点个数;N c为两副指纹匹配成功的细节点对数。
R越小,两副指纹的匹配得分越高,因此,用公式(2)中的归一化方法将R归一化到[0,1]之间,给出匹配得分S a。
S a=( maxR-R)/( maxR- minR) (2)
式中:max R和min R分别代表R的最大值和最小值。
对同源匹配而言,本应形成匹配、但未能成功匹配的点对,在位置上仍存在着很强的对应关系(尽管有一定的定位偏差)。但异源匹配中,由于未匹配细节点的产生在本质上是随机的,因此,未匹配成功细节点在位置上不存在任何对应规律。本文定义了紧互对原型对,并用其描述两个未匹配细节点在位置上的对应关系。
定义1 对A和B两幅指纹进行匹配,若在A和B匹配区域内的两个未匹配细节点pi和qi满足式(3),则称细节点对(pi,qi)为紧互对原型对:
d(pi,qi)= 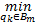

用函数d(·)计算两点间的欧式距离;A m为指纹A中匹配区域内未匹配细节点的集合;B m为指纹B中匹配区域内未匹配细节点的集合。
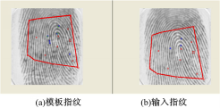
图3中的模板指纹和输入指纹是同源指纹。红色点代表匹配成功的细节点,蓝色点代表匹配区域内未匹配成功的细节点。模板指纹中绿色点代表输入指纹匹配区域内未匹配细节点在模板指纹中的位置。可以看到,有几个绿色细节点与蓝色细节点距离很近,根据定义1,这些细节点对为紧互对原型对。
 | 图3 两幅指纹中的紧互对原型对Fig.3 Tight pair-wise prototypes in two fingerprints |
根据上文分析,在同源匹配中,可能存在较多数量的紧互对原型对,并且紧互对原型对中两细节点间的距离相对较近。而异源匹配中有可能无法提取出紧互对原型对,在提取出的紧互对原型对中两个细节点的距离也相对较远。由此,紧互对原型对中两细节点的距离信息应该是具有区分性的信息。统计两副指纹中所有紧互对原型对,并用式(4)计算平均距离 Davg作为衡量指纹相似度的指标,平均距离越小,两副指纹的匹配得分越高。
D avg=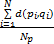 | (4) |
式中:N p为紧互对原型对的个数;d(pi,qi)为第i个紧互对原型对中两细节点的欧式距离。
在计算过程中若未匹配细节点个数为0,则置D avg为0,若未匹配细节点个数不为0,但紧互对原型对个数为0,则置D avg为较大值。最后,采用与2.1节中相同的归一化方法将D avg归一化到[0,1]之间,给出匹配得分S b。
利用网格集合距离来对未匹配细节点的分布一致性进行衡量。将一幅指纹图像划分成M×N个大小相同的网格,计算每个网格内未匹配细节点的个数,其中只计算匹配区域内的未匹配细节点,设与匹配区域没有交集的网格中未匹配细节点个数为0。将两副待匹配指纹中第i(i=1,2,…,M×N)个网格中的未匹配细节点集合分别记为Ai和Bi,则两副指纹的网格距离G由公式(5)给出:
G=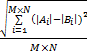 | (5) |
式中:|Ai|和|Bi|分别代表集合Ai、Bi中的元素个数。网格距离G越小,认为两幅指纹中未匹配细节点在分布上越一致(相似),从而,两副指纹的匹配得分越高。最后,采用与2.1节中相同的归一化方法将G归一化到[0,1]之间,给出匹配得分S c。
从另外一个角度,如果把匹配区域内的未匹配细节点集看作一个集合,则可以直接通过计算两个集合的相似度来衡量两幅指纹中未匹配细节点在分布上的一致性。本文用Hausdorff距离[ 14]来衡量两个未匹配细节点集合的相似度。
对于集合A=(a1,a2,…,am)与集合B=(b1,b2,…,bn),Hausdorff距离的计算公式为:
H(A,B)= max(h(A,B),h(B,A)) (6)
h(A,B)= 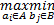
h(B,A)= 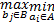
在计算两个未匹配细节点集合的Hausdorff距离时,用公式(9)(10)中的欧式距离代替公式(7)(8)中两元素的差运算:
h(A,B)=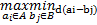 | (9) |
h(B,A)= | (10) |
具体过程如下:设集合A=(a1,a2,…,am)和集合B=(b1,b2,…,bn)分别为模板指纹和输入指纹匹配区域内的未匹配细节点集合。首先针对A中每个细节点,计算其到B中所有细节点距离中的最小距离,然后取集合A中得到的所有该最小距离中的最大值作为集合A到集合B的距离,记为h(A,B)。同理,算得集合B到集合A的距离,记为h(B,A)。最后,取h(A,B)与h(B,A)中较大的值作为集合A和集合B的Hausdorff距离。但上述过程极易受到伪细节点的影响。例如一个集合中的某伪细节点与其他细节点距离都较远,则用上述方法得到的Hausdorff距离将是一个较大的噪声值。因此,本文使用Hausdorff距离的改进算法:用集合A中每个细节点到集合B中所有细节点距离的平均值代替最小值,取集合A中所有细节点得到的平均值中的最大值作为集合A到集合B的距离。同理,计算集合B到集合A的距离。最后,取二者的最大值作为集合A和集合B的Hausdorff距离。两个集合的Hausdorff距离越小,两幅指纹中未匹配细节点分布一致性越高,从而,两副指纹的匹配得分越高。将Hausdorff距离用与2.1节中相同的归一化方法归一化到[0,1]之间,给出匹配得分 Sd。
本文通过得分级融合方法,将上述从未匹配细节点中提取的四方面特征的匹配得分与一种已有的细节点方法[ 15]的匹配得分进行融合,实现指纹识别。文献[ 15]提出了一种多模板融合的指纹识别方法,将指纹模板视为空间中的点,利用同一手指的两两模板之间的距离建立空间多面体,通过计算输入模板与空间多面体中心的距离得到匹配得分。该方法在竞赛数据库FVC2000及FVC2002上得到了较好的识别效果。拟通过此融合策略达到两个目的:①验证未匹配细节点中的确存在可利用的区分性信息;②证明将从未匹配细节点中提取的区分性信息作为辅助特征用于指纹识别能够提高指纹识别系统的性能。
在识别阶段,将输入指纹逐一与每个用户的模板指纹进行匹配。采用线性加权的得分级融合方法将基于四个辅助特征的匹配得分( Sa、 Sb、 Sc和 Sd)与已有匹配算法的匹配得分( So)进行融合,得到最终匹配得分 Sf。计算公式如下:
S f=k1×S o+k2×S a+k3×S b+k4×S c+k5×S d (11)
其中,权值满足 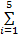
(1)依据具体数据特性设置权值。不同应用背景下的数据特点并不相同,存在指纹质量等因素的差异,融合方法(1)对不同的数据库设置不同的权值。原始匹配得分包含较多信息,仍作为主要的衡量标准,因此,设置权重 k1为稍大于0 .5的值,然后在每个数据库上,根据多次实验的经验值确定较高识别精度时 k2 ~k5的组合。
(2)依据匹配得分设置权值。匹配得分本身可以在一定程度上反映其对应特征的重要程度。此方法考虑了不同指纹对匹配时的个性化特点。 k i( i=1,…,5)的计算公式如下:
k i =S i / 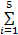
这里为了方便表达,分别用 S1~ S5替代 So~ Sd。
得到最终的匹配得分 Sf后,设置阈值τ,如果 Sf大于τ,则认为输入指纹和模板指纹是同源指纹,将模板指纹对应的用户ID返回;如果 Sf小于等于τ,则认为输入指纹和模板指纹为异源指纹,用相同方法将输入指纹与模板库中其他用户的模板指纹进行匹配,直到遇到同源指纹,返回相应用户ID。如果输入指纹与模板库中所有用户的指纹都被认为是异源指纹,则返回错误或报警信息。
实验中选择文献[ 15]的方法为对比方法。该方法属于典型的基于细节点的指纹匹配方法,其识别性能优于当前同类方法。通过实验将本文提出的融合方法(1)和融合方法(2)的识别性能与文献[ 15]的方法进行了对比。
实验使用国际指纹识别竞赛的三个数据库FVC2000、FVC2002和FVC2004,每个数据库均包含4个子库,分别称为DB1、DB2、DB3和DB4。其中的每个子库中都包含采集自100个手指的指纹,每个手指均采集8幅指纹图像,即每个子库包含800幅指纹图像。FVC2000、FVC2002和FVC2004每个数据库包含3200幅指纹图像,三个数据库共包含1200个不同手指的9600幅指纹图像。
对每个手指,取数据库中该手指的前3幅指纹图像作为模板指纹,剩余的5幅指纹图像作为测试指纹。分别用等错误率(EER)和ROC曲线两个指标对识别性能进行评价。
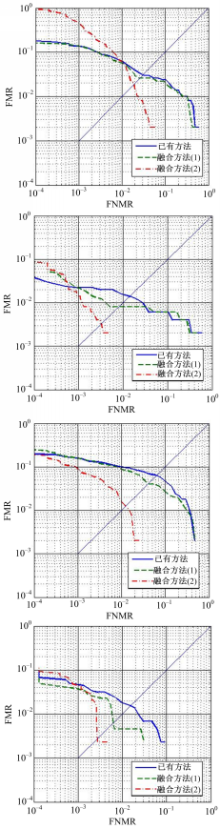
表1~表3列出了在FVC2000、FVC2002和FVC2004所有数据库中本文提出的融合方法和已有方法获得的EER。可以看出,本文方法的EER全部低于已有匹配方法。虽然在不同指纹库中,本文方法对系统识别性能提高的效果不同,但总体性能都有显著提高。其中,第(2)种融合方法性能提高幅度最大。融合方法(2)优于融合方法(1)的主要原因是其对权重的设置考虑了每次两幅指纹匹配时的具体情况。
| 表1 FVC2000数据库上各方法的EER(%) Table 1 EER(%) of different methods on FVC2000 |
| 表2 FVC2002数据库上各方法的EER(%) Table 2 EER(%) of different methods on FVC2002 |
| 表3 FVC2004数据库上各方法的EER(%) Table 3 EER(%) of different methods on FVC2004 |
图4~图6分别展示了本文方法和已有方法在FVC2000、FVC2002和FVC2004中所有数据上的ROC曲线。ROC曲线更加直观和全面地展示本文提出方法在识别性能方面的优越性。在FVC所有数据库上的实验结果可以充分说明以下两点:(1)未匹配细节点中的确含有能够有效分辨同源指纹和异源指纹的区分性信息。(2)本文定义和提取的4种辅助特征可以有效挖掘未匹配细节点的区分性信息,融合4个辅助特征的匹配方法可以大幅度提升系统性能。
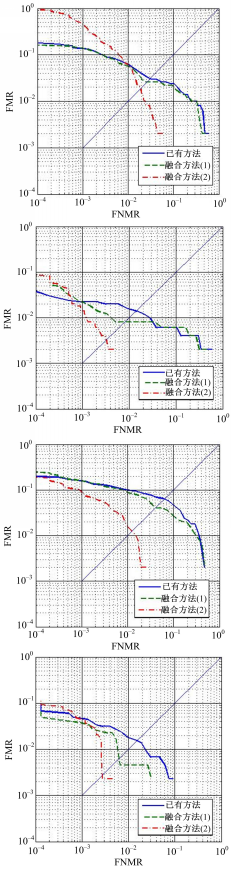 | 图4 FVC2000数据库上各方法的ROC曲线Fig.4 ROC curves of different methods on FVC2000 |
 | 图5 FVC2002数据库上各方法的ROC曲线Fig.5 ROC curves of different methods on FVC2002 |
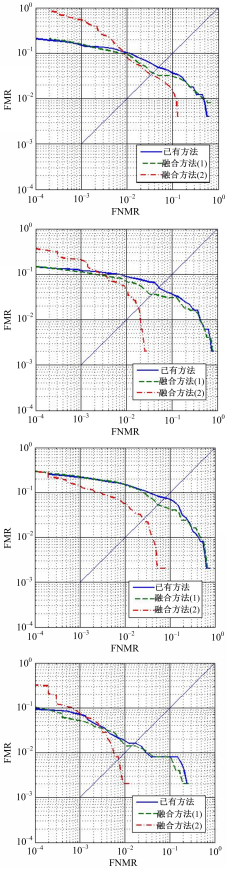 | 图6 FVC2004数据库上各方法的ROC曲线Fig.6 ROC curves of different methods on FVC2004 |
需要特别说明的是:①本文实验主要是为了验证所挖掘的未匹配细节点特征信息的区分性以及将其与已有的细节点指纹匹配方法进行融合,是否可以有效提升指纹识别系统的性能。理论上,已有的各种基于细节点的指纹匹配方法,都可以作为被融合方法。所以,本文实验中选择的对比方法(文献[ 15]的方法)本身是否为当前性能最优的方法、融合后的性能是否为当前算法中最优的与本文的贡献并无直接关系。②本文方法造成系统性能提升的根本原因在于两点,一是利用了在已有方法中被忽视的未匹配细节信息,对区分性信息的利用更加充分;二是未匹配细节点信息与成功匹配的细节点信息之间存在一定的互补性。例如在2.1节的图1和图2中,虽然匹配细节点对数量都为10,但是未匹配细节点的数量成为了有效的补充,为区分同源匹配和异源匹配提供了证据。显然,这种得分级融合策略,与具体融合哪种已有的基于细节点指纹匹配方法并没有直接关系。可以预见,将所挖掘的未匹配细节点信息和各种已有的细节点匹配方法融合,可以在不同程度上提升识别的性能。
(1)突破了指纹识别中未匹配细节点属于无用信息的思维定势,提出了挖掘和利用未匹配细节点中所包含的区分性信息,从而提高指纹识别系统性能的新思路。
(2)基于同源指纹匹配和异源指纹匹配中未匹配细节点的成因和特点不同,定义和提取了4个方面的特征,实现了对未匹配细节点中区分性信息的有效挖掘。
(3)将在未匹配细节点中提取的区分性信息作为辅助特征,通过在得分级上与一种已有的基于细节点的匹配算法进行融合,有效提升了指纹识别系统的性能,验证了未匹配细节点中确实存在可以利用的区分性信息。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|