




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
云存储系统聚合带宽测试技术
[贺秦禄1  , 李战怀
, 李战怀1 , 王乐晓1 , 王瑞2 ]
, 李战怀|
|


作者简介:贺秦禄(1982-),男,博士研究生.研究方向:海量存储,云存储,重复数据删除. E-mail:luluhe8848@hotmail.com
提出了测试云存储文件系统聚合带宽的方法,设计并实现了测试并行文件系统聚合带宽的测试软件FSPoly。本文对FSPoly测试结果的有效性进行了充分验证,并通过使用FSPoly,实现了对内存文件系统、网络文件系统及并行文件系统的聚合带宽进行了评测。
A testing method for aggregate bandwidth of cloud storage file system is proposed, and a parallel file system aggregate bandwidth test software, called FSPoly, is developed. The testing results are analyzed in depth to verify FSPoly. Then FSPoly is used for the evaluations of the aggregate bandwidth of memory file system, network file system and parallel file system.
随着互联网技术的飞速发展,数据呈现出爆炸式增长的趋势。美国南加州大学的希伯特和洛佩斯估计,全球计算机储存容量每18个月就提高一倍[ 1, 2, 3, 4, 5, 6]。思科发布的全球云指数(2010~2015年)报告[ 2]指出,数据中心的总体流量将由2011年的1.5 ZB增长到2015年的4.8 ZB,是原来的三倍之多。随着网络与计算机技术的快速发展,当今需要存储的数据量也呈现出爆炸性增长的趋势,随之而来的问题就是如何能够有效、合理地存储这些数据,而这些数据可能会是某个领域或者某个单位、企业的命脉。为了解决这个问题,各个存储厂商都在努力开发高可用性、高可靠性的云存储系统,一时间面对如此繁多的存储产品,存储数据中心使用者迫切需要一个能够显示各个存储产品性能、功能差别的标准,从而为他们提供一个可参考的指标[ 3, 4, 5, 6, 7, 8, 9]。由于存储产品的数目繁多,各个厂家都以自己的标准去评测自己的产品,这样最终可能会导致存储厂商提供给消费者的标准没有可比性。而现在国际上对云存储系统的评测技术与标准还相对滞后,这与云存储系统本身的复杂性不无关系[ 4, 5, 6, 7]。
云存储系统最基本的目标就是向外提供超大容量文件存储功能,而聚合带宽[ 5]作为整个存储系统文件数据吞吐率的指标,其对存储系统各种上层应用的性能起着至关重要的作用。本文在开发聚合带宽测试工具的基础上,实现对云存储系统聚合带宽的测试技术研究。
FSPoly基于客户端/服务器结构,根据物理位置的不同,整体上分为总控端与测试端两大部分;其目标则是可以并行测试文件系统的聚合带宽、并发连接数等性能指标。按照松耦合设计的原因,以物理分布及扮演的角色的不同,FSPoly整个软件的设计分为7个模块。图1显示了FSPoly各个模块所处的层次。
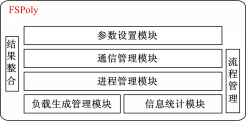 | 图1 FSPoly模块层次图Fig.1 FSPoly module hierarchy chart |
FSPoly中只有负载生成模块与被测试文件有直接的联系,此模块将采用文件提供的标准API,且此API符合POSIX标准,来实现其对目标文件系统的文件级的测试。在生成负载的同时,信息统计模块将实现对整个负载生成情况的统计。而进程管理模块将控制负载生成模块的行为,同时,其还会向信息统计模块索取统计信息,最终进程管理模块会将得到的统计结果通过通信模块传送到结果整合模块,由结果整合模块进行整合,最终将结果存入结果文件并显示给测试发起者。
FSPoly作为文件系统测试工具,其主要目的是测试目标文件系统的聚合带宽,其测试结果的有效性需要进一步验证。FSPoly在测试过程中,每个进程首先会创建一个指定大小的文件,然后对此文件进行读、写操作以实现对文件系统的测试。通过与iozone做对比试验,通过测试结果的分析对比证明FSPoly的正确性和有效性。
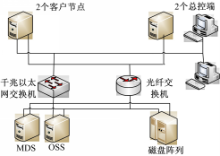
测试环境拓扑图如图2所示,PnFS文件系统使用1个总控节点,2个客户节点,1个MDS服务器和1个OSS服务器。
测试过程中使用测试工具FSPoly和iozone;FSPoly的总控端运行在安装有Windows XP系统的PC机上。2个测试工具的测试端运行在安装有RedHat Enterprise Linux 5.3系统,内核为2.6.18-128.el5xen的节点上。
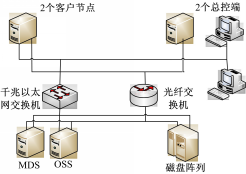 | 图2 测试环境拓扑结构Fig.2 Test environment topology |
使用FSPoly模拟iozone混和模式。两台控制端各控制一台客户端,两台客户端同时对文件系统进行读写,其中一台进行顺序写操作、一台进行顺序读操作。对iozone测试时分为:非DIRETCIO+非MMAP()即iozone正常读写、dirtectio+非map()、非directio+mmap()几种方式分别测试出iozone对文件系统的顺序读、顺序写、随机读、随机写,并使用这些数据与FSpoly测试结果进行对比。最后使用iozone的混合模式进行测试。
2.3.1 顺序读写测试
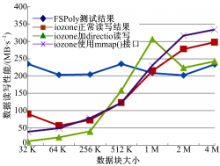
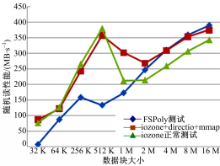
从图3可以看出,iozone在使用mmap接口进行写文件时,性能会比直接写文件高,这个函数mmap实现把一个文件映射到一个内存区域,从而可以像读写内存一样读写文件,比单纯调用read/write也要快很多,但是使用directio读写文件并不会提高iozone写性能。
 | 图3 iozone和FSPoly顺序读写结果对比Fig.3 iozone and FSPoly order to read and write results |
当读写块较小时FSPoly测试结果优于iozone,而当读写块增大时FSPoly测试结果就比iozone差。主要原因如下:①iozone写文件时是对一个不存在的文件进行写,所以当写文件的同时还要写元数据信息,这对性能就有一定影响。但是随着读写块的增加,需要写的元数据信息就会变少,性能就会提高;②FSPoly写使用fwrite函数,而iozone使用write函数。fwrite在写文件时可以使用系统缓存单,而write不能,所以FSPoly写性能应该优于iozone的写文件性能,但是当数据块增大时,从图3可以看出iozone写性能要比FSPoly优的主要原因是:fwrite会先将数据缓存在文件系统的page cache中,等到cache存满后才会调用write刷下去,所以,当读写块增大时,缓存的影响就会减弱。而由于fwrite在底层调用了write函数,则iozone写性能就会超过FSPoly。
2.3.2 顺序读测试
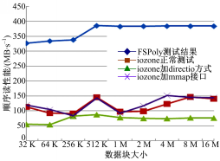
由图4可以看出FSPoly测试结果远大于iozone测试结果,主要原因是FSPoly在读文件时使用了fread函数,而iozone使用了read函数,由于fread在读文件时可以利用系统缓存,所以结果正确。
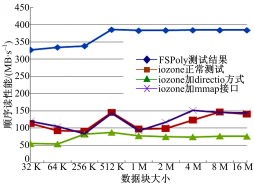 | 图4 iozone和FSPoly顺序读结果对比Fig.4 iozone and FSPoly sequence read result contrast |
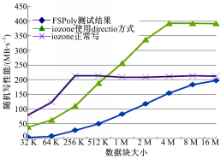
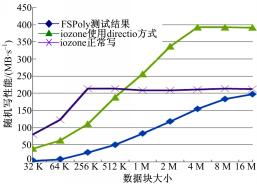 | 图5 iozone和FSPoly随机写结果对比Fig.5 iozone and FSPoly random write results |
2.3.3 随机写测试
由图5可知,FSPoly在随机写时性能比iozone差。主要是因为FSpoly使用了fopen系列函数,而iozone使用了open系列的函数。由于open和fopen最主要的区别在于fopen在用户态下就有了缓存,在进行read和write时,减少了用户态与内核态的切换,而open则每次都需要进行内核态与用户态的切换,所以随机访问文件,open系列函数要比fopen系列函数快。
2.3.4 随机读测试
由图6可知,FSPoly在随机读时性能比iozone差。主要是因为FSPoly使用了fopen系列函数,而iozone使用了open系列的函数。由于open和fopen最主要的区别在于fopen在用户态下就有了缓存,在进行read和write时,减少了用户态与内核态的切换,而open则每次都需要进行内核态与用户态的切换,所以随机访问文件,open系列函数要比fopen系列函数快。
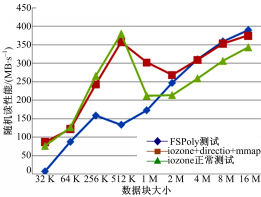 | 图6 iozone和FSPoly随机读结果对比Fig.6 iozone and FSPoly random read results |
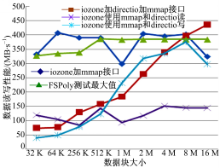
2.3.5 混合模式测试
由图7可以看出:首先,FSPoly测试时的最大值即顺序读时的测试结果,最大不到390 Mb/s,而iozone使用混合模式(即在测试文件系统性能时一半进程读文件,一半进程写文件)时测试的最大结果为430 Mb/s,iozone结果比FSPoly测试结果高出10%。其次,iozone在单独读写文件时数据读写速率也都比混合模式小。
 | 图7 iozone和FSPoly混合模式下读写性能对比Fig.7 iozone and read/write performance comparison FSPoly mixed mode |
通过分析测试环境和两款工具源代码,得出iozone在混合模式测试时优于FSPoly的原因:①iozone测试时使用了mmap()函数,mmap函数实现了把一个文件映射到一个内存区域,从而可以像读写内存一样读写文件,比单纯调用read/write要快很多;②iozone测试使用混合模式(即50%的进程进行读操作,50%的进程进行写操作),FC卡如果是全双工,当使用混合模式测试时,读、写两个方向都有数据流,这也提高了测试带宽。
为了减少外部设备IO,诸多操作系统提供有内存文件系统,用户可以将经常使用的文件放置在内存文件系统之上,以快速进行访问。本节将实现对内存文件系统的测试,使用FSPoly测得其聚合带宽性能指标。
使用测试工具FSPoly,其总控端运行在安装有Windows XP系统的PC机上,测试端运行在安装有RedHat Enterprise Linux 5.3系统、内核为2.6.18-128.el5xen的节点上。
硬件包括型号为D-Link DGS-1024T的千兆以太网交换机和型号为Inspur AS300N的存储服务器,如图8所示。
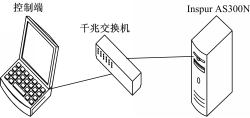 | 图8 内存文件系统测试拓扑Fig.8 Memory file system test topology |
首先创建一个10 GB大小的RAM盘,用EXT3文件系统对其进行格式化。然后通过设置不同的测试规则与进程数,发起对建立在此RAM盘上的EXT3文件系统的聚合带宽测试。在所有测试过程中,每个进程创建文件的大小为45 MB。
图9显示了对于不同文件的存取方式,内存文件系统的聚合带宽测试结果,可得出如下结论:
(1)对于顺序存取与随机存取,聚合带宽结果并无变化。原因是内存的寻址并不需要像硬盘那样机械寻道,而是通过电信号的改变即可实现寻址过程。
(2)对于顺序读与随机读存取方式,其聚合带宽最大可以达到近10 000 MB/s;对于顺序写与随机写存取方式,其聚合带宽最大可以达到近3000 MB/s。内存理论带宽值为1333 M(内存频率)*64b(数据宽度)=85 312 Mbit/s=10 664 MB/s。由此可知对于读操作,其聚合带宽值几乎可以达到存储介质(内存)的理论带宽值;而对于写操作,此值只能达到其理论值的30%,这可能是因为在写操作时会有元数据、日志数据的写入,其占用了内存周期,大大降低了聚合带宽性能指标。
(3)过多的连接数则会严重影响聚合带宽值。
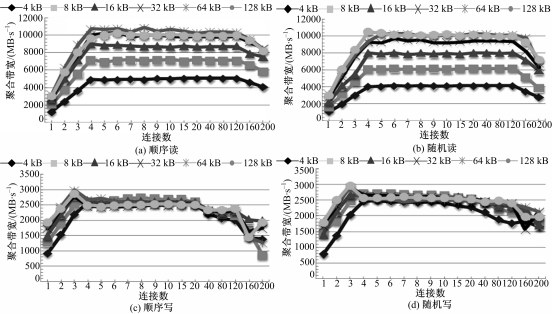 | 图9 内存文件系统测试结果Fig.9 Memory file system test results |
对应用非常广泛的Lustre并行文件系统进行测试,此文件系统广泛用于存储系统中,支持PB级的存储容量。其最新版本已支持IB网络环境。本节对Lustre的测试也是基于IB网络环境的。
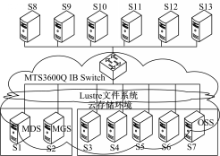
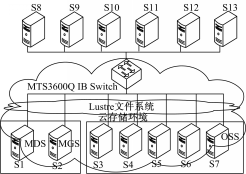
硬件配置如图10所示:S1至S7上安装有Lustre-1.8.2。其中S1为元数据服务器,其后端存储为4个硬盘组成的RAID0;S2为元数据管理服务器,其后端存储为3个硬盘组成的RAID0;S3至S7为对象存储服务器,其后端存储为7个硬盘组成的RAID5。
整个测试使用测试工具FSPoly。FSPoly总控端运行在安装有Windows XP系统的PC机上。图10未给出此节点;FSPoly测试端运行在S8至S13节点上。各节点安装有RedHat Enterprise Linux 5.3系统,内核为2.6.18-128.el5xen;并由OFED-1.5.1 IB驱动。
本节的目的是为了测得在当前环境下,Lustre并行文件系统的聚合带宽最大值。存取方式选择顺序读与顺序写两种,从4个方面(Lustre自身条带大小、读写块大小、并发连接数与客户端个数)逐步测得Lustre并行文件系统的聚合带宽最优值。
(1)使用单个客户端节点,设置不同的Lustre条带大小,测得使聚合带宽达到最优值时的Lustre条带宽大小。
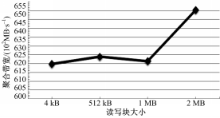
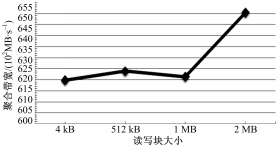
(2)设定上一步中得到的使聚合带宽达到最优值时的相关参数,逐步改过读写块大小,测得使聚合带宽最优的读写块大小。
(3)设定以上几步中测得的最优值参数点,逐步增加并发连接数,测得使聚合带宽性能最优的并发连接数参数指标。
(4)以上几步都是在单个客户端的基础上进行的。本步依次增加Lustre客户端的个数,测得使聚合带宽指标达到最优时的客户端个数,并最终得到本环境下Lustre并行文件系统的聚合带宽最优值。
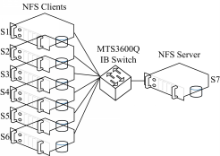
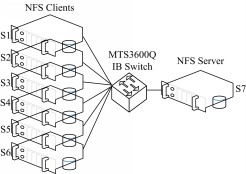
硬件配置(见图12)如下:型号为Mellanox MTS3600Q、端口单向速率为40 GB/s的InfiniBand交换机一台。S1至S7为Inspur AS300N存储服务器,每台服务器上安装有型号为MHQH19-XTC的Mellanox ConnectX 4X QDR InfiniBand HCA卡一个,单向速率为40 GB/s;服务器与交换机之间使用的IB连接线型号为MCD4Q26C-007,其单向速率为40 GB/s。S7节点为NFS服务端,其存储使用的是3个硬盘(转速为15.7 kr·min-1、速率为3.0 GB/s SAS接口的300 GB Cheetah硬盘)组成的RAID0。
整个测试使用测试工具FSPoly。FSPoly总控端运行在安装有Windows XP系统的PC机上,图12未给出此节点;FSPoly测试端运行在S1至S6节点上。各节点安装有RedHat Enterprise Linux 5.3系统,内核为2.6.18-128.el5xen;并由OFED-1.5.1 IB驱动。
每个测试的预热时间为2 min,每个测试项测试时间为5 min,每个测试项重复测试3次,取其平均值。每个连接创建一个大小为客户端内存两倍(32 GB)的文件进行顺序读与顺序写测试。
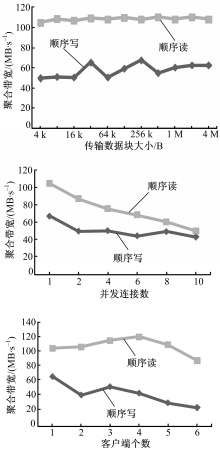
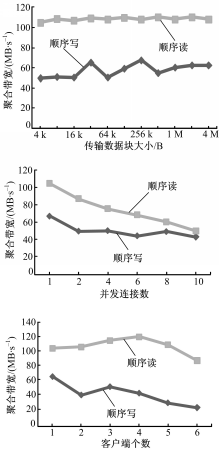
图13为IB网络环境下,NFS的聚合带宽测试结果。从图13可以看出:
(1)顺序读的聚合带宽比顺序写的聚合带宽要大,这一点与前面的测试结果一致。
(2)传输数据块在4 kB时,顺序读存取规则下的聚合带宽值即可基本达到最大值。而对于顺序写,最大值的传输数据块大小为256 kB。
(3)当并发连接数为1时,顺序读与顺序写的聚合带宽值达到了其最大值。
(4)当NFS客户端个数为4时,顺序读的聚合带宽值可以达到其最大值,约为120 MB/s;顺序写的聚合带宽值达到最大(约为70 MB/s)时,NFS客户端个数为1。
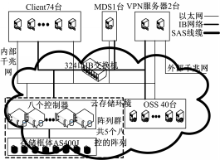
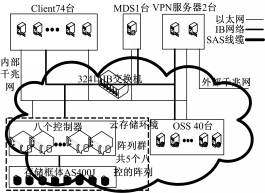
图14为被测云存储系统的内部拓扑结构图。图14中使用的后端存储由多控制器的IB磁盘阵列提供,每个IB阵列相关配置为:磁盘阵列内部控制器与各个磁盘框体间使用双口4通道SAS卡(速率:3.0 GB/s)互联;阵列中使用硬盘全部为2 TB大小的SATA口硬盘,其转速为7200 r/min,五个阵列共配置有496块硬盘;使用由12个硬盘组成RAID0进行配置,并做为后端存储提供给各个OSS及MDS;各服务器与阵列间使用IB网络进行互联与挂接。图14中所使用的IB交换机有324口,其单端口单向速率为40 GB/s。图14中各服务器全部为浪潮AS3000存储服务器, 其中74个客户端内存大小全部为1 GB,其他各个服务器内存大小全部为32 GB。各服务器其他相关配置为:两个CPU,每个CPU四核,共有8个CPU核心;型号为MHQH19-XTC的HCA卡一个,其单向速率为40 GB/s,用于IB网络互联。各服务器所使用的操作系统为CentOS5.4,内核为2.6.18-164。整个存储系统使用最新研制的CFS并行文件系统。
首先介绍了最新开发的聚合带宽测试软件FSPoly,在验证FSPoly测试结果有效性的基础上,依次实现了对内存文件系统、网络文件系统和并行文件系统的测试。在分析结果的合理性的基础上,验证了依次设定各个参数寻找聚合带宽最优值的测试方法的合理性。最终实现了对最新研制的云存储环境下文件系统聚合带宽的评测。由于聚合带宽是新近才提出的一个全新的概念,而对云存储系统的聚合带宽的研究也还未成熟,相应的基准与规范也没有详细的说明。所以这个性能指标在以后可能会进一步完善或者重定义。随着应用的需求标准越来越高,人们对云存储系统的依赖越来越强。高性能、高可扩展性、高容量、高可靠性的要求,迫使存储厂商对云存储系统的架构不得不进行革新。对软件、硬件性能的要求更加苛刻,这又导致了新技术的不断催生。因此,对云存储系统中各个环节的优化与完善也显得非常重要。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|