{kind=link}
{kind=link}
{kind=link}
{kind=link}
制的容错节能调度算法
[张忆文1, 2  , 郭锐锋
, 郭锐锋1 ]
, 郭锐锋]
|
|


作者简介:张忆文(1988-),男,博士研究生.研究方向:低功耗调度.E-mail:zywsy2010@126.com
综合考虑了实时系统的容错和节能,针对处理器提供离散的频率和电压,提出了基于检查点机制的容错节能调度算法(CPFTES)。该算法利用动态电压缩放技术节能,通过确定优化的检查点且使用检查点机制实现容错。当任务发生错误时,恢复任务从已保存的检查点重新启动以最大的处理器速度运行,确保任务不错过截止期限。提出了H_SPEED和A_SPEED两种速度选择策略。仿真实验表明:在PXA250处理器上,CPFTES_A_SPEED比CPFTES_NODVS平均节约66.18%的能耗,CPFTES_A_SPEED比 CPFTES_H_SPEED节约0~19.41%的能耗。
A Fault-tolerant Energy-saving Scheduling Algorithm base on Checkpoint Scheme (CPFTES) is proposed. The algorithm considers fault tolerance and power management in real-time system that the discrete frequency and voltage are provided by processors. The fault tolerance is achieved via optimal checkpoint scheme and the power management is carried out using dynamic voltage scaling. The optimal checkpoints can help the task to guarantee the timing constraints and reliability. If a task fails, it can restart from a saved checkpoint and execute at the maximum speed to ensure the deadlines are met. Two speed selection strategies, named H_SPEED and A_SPEED, of the algorithm are proposed. Simulation results show that CPFTES_A_SPEED can save about 66.18% energy compared to CPFTES_NODVS and save about 0~19.41% energy compared to CPFTES_H_SPEED under PXA250 processors.
实时系统是指能够响应外部随机事件,并能够在规定的时间完成对事件处理的计算机系统,确切地说:实时系统的正确性不仅取决于计算的逻辑结果,而且也取决于产生结果的时间。可靠性和实时性是实时系统的重要特征。近年来随着制造工艺的日益精密,集成电路规模的飞速发展,系统能耗问题日益凸现,能耗已成为实时系统设计的瓶颈。
容错可以通过在线检测错误、插入检查点和回卷恢复机制实现。每个检查点都保存系统的状态,当发生错误时,任务从最近的检查点恢复执行。文献[1]分析了检查点机制容错调度算法的可调度性。文献[2]介绍了基于检查点机制的容错调度算法。
DVS是一种有效的低功耗和低能耗的优化技术。文献[3-4]提出了针对周期任务的节能调度算法,将DVS技术和实时调度算法结合起来,有效地降低了系统能耗。最近的研究[ 5, 6, 7, 8]结合了容错和节能,文献[5]假设处理器提供连续的频率和电压,提出了两种检查点策略,一种是考虑检查点间距相等,另一种是考虑检查点间距不相等,但这两种策略都只能够容忍一个错误。文献[6]提出了容忍 k个错误的固定优先级容错节能调度算法。文献[7]提出了针对非周期任务的容错节能调度算法。文献[8]提出可适应性检查点机制的方法。上述算法只考虑处理器的动态功耗,忽略了处理器的静态功耗。文献[9]考虑了处理器的动态功耗和静态功耗,但不是使用检查点机制来实现容错。本文综合考虑了实时系统的容错和节能,同时考虑处理器的动态功耗和静态功耗,针对处理器提供离散的频率和电压,提出了能容忍 k个错误的CPFTES算法。该算法针对周期任务,利用DVS技术节能,通过检查点机制实现容错。优化的检查点机制确保任务集的可靠性和实时性;当任务发生错误,恢复任务从已保存的检查点重新启动以最大的处理器速度运行。
考虑有 n个周期任务的实时任务集 T={ T1, T2,…, Tn},一个任务的参数为 Ti=( Pi, Ci, Di, ki), Pi是任务 Ti的周期,且相对于截止期限等于其周期, Ci是任务在最大处理器速度和任务没有出错情况下的执行时间, Di是任务的截止期限, ki代表能够容忍错误的数量。 Tij是任务 Ti的第 j次调用。任务是相互独立且在时刻0同时就绪;因此任务 Tij的就绪时间 rij=( j-1) *Pi,它的截止期限 dij=j*Pi。
不失一般性,假设任务的周期满足 P1≤ P2≤…≤ Pn, Utot是在最大速度下,任务总的利用率, Utot = 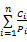
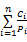
使用文献[9,10]的功耗模型。系统的功耗为:

式中: Ps代表静态功耗,当关闭整个系统时 Ps =0。静态功耗包括(但不限于)基本电路的功耗、维持时钟运行以及主存和I/O设备在睡眠状态的功耗。 Pind和 Pdep分别代表正在运行的任务 Ti与频率无关的功耗和与频率相关的功耗。与频率无关的组件的功耗是不受CPU频率或者电压变化影响的。任务 Ti使用的主存和I/O设备等功耗都包含在 Pind里面。 Pdep包括CPU的动态功耗和系统中与频率和电压相关的功耗。 Cef为有效的负载电容。 m为动态指数(2≤ m≤3)。 Si为任务 Ti的当前速度。 h代表系统的状态,当系统处于动态模式时, h=1;当系统处于睡眠或者关闭模式时 h=0。由于关闭和打开设备的开销比较大,因此对于实时系统而言,任务在执行过程中将某些组件设置为低功耗的状态,而不是关闭它。
降低CPU的速度可以降低处理器的动态功耗,但处理器速度的降低会延长任务的执行时间,这时系统的静态功耗会增加。文献[9]定义了关键速度 Scrit,关键速度是系统能耗最低的速度。关键速度可以由式(2)求出:
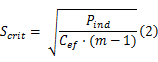
当任务的速度不等于关键速度时,系统的能耗会增加,为了保证系统的实时性,假设任务运行的最低速度应该大于等于 Scrit。
CPU提供离散的频率和电压,即[ f1, f2,…, fmax]和[ v1, v2,…, vmax],能够提供的速度也是离散的,对频率进行归一化处理, Smin = 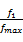
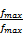
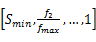
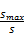
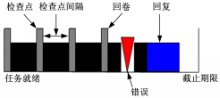
任务执行期间发生错误的原因很多,例如硬件错误、软件错误、宇宙射线的影响等。本文考虑瞬时错误,因为研究表明发生瞬时错误的概率比永久错误的概率大。假设一个任务在执行期间最多发生 k次错误;当错误发生时使用检查点机制对错误进行恢复,检测错误的开销记录在建立检查点的开销里面,任务在回卷和恢复的过程中不会再发生错误。从图1可以看出,任务有4个等间距的检查点,把任务分成4个部分。当发生错误时,任务回卷到上一个检查点,继续执行。恢复任务的主要作用就是预留时间在任务发生错误时,任务有足够的时间重新执行。
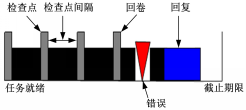 | 图1 检查点和回卷恢复Fig.1 Checkpoint and rollback recovery |
考虑单个任务,任务的优化的检查点就是确保任务在最坏情况下的执行时间最低,这样就有更多的空闲时间用于节能。任务最坏情况下的执行时间是指任务在执行过程中发生了 k个错误。任务 Ti的最坏情况的执行时间可以表示为:
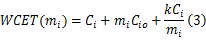
式中: mi为检查点的数量; Cio为任务 Ti建立检查点的开销。
本文的目标就是找到恰当的 mi,在保证任务时限和可靠性的前提下,使得任务 Ti的空闲时间最大(任务最坏情况下的执行时间最小),利用DVS技术节约更多的能耗。
对方程(3)求导,令求导后的方程值为0,求出 m的非负解,可得使空闲时间最大的 m值为:
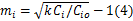
定义 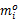
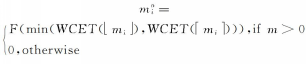
任务 Ti的空闲时间 Slack=Di-WCET( 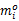
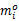
前面已经确定了任务的优化的检查点,这一部分主要是确定使总能耗最低的任务的运行速度。假设系统的所有任务都以相同的速度 S运行。在不发生错误的情况下,任务 Ti插入 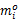
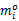
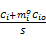
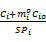
在发生 k个错误后,为了正确执行任务,在每个时间间隔 P1预留 k 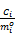
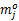
引理1 对于任务集 T={ T1, T2,…, Tn},假如 Utot≤1 - 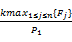
证明 考虑一个修改的任务集,其任务 Ti被任务 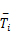
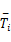
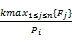
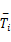
系统在无错情况下的运行速度为 S,当出现错误时,恢复任务以最高处理器速度运行,因此插入检查点后系统的利用率为:
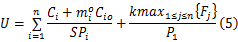
为了充分利用系统的空闲时间,设置系统的利用率为1,求出速度:
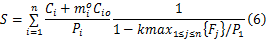
假如由式(6)求出的速度 S小于关键速度 Scrit,这时 S=Scrit。
由于处理器提供的频率和电压是离散的,为了确保任务不错过截止期限,本文提出两种速度选择策略,第一种策略(H_SPEED)每个任务选择的速度都大于或等于速度 S。第二种策略(A_SPEED)[ 12]是任务以相邻的速度运行,任务的执行时间划分为两部分。通过速度 S确定第一部分的速度和第二部分的速度,并且利用速度 S下的执行时间计算出第一部分的执行时间。待第一部分执行完成,根据剩余执行时间完成第二部分。
H_SPEED
{ select speed from 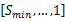
Return the first speed greater than or equal S;}
定义速度 SL、 SH且满足 Scrit≤ SL<S≤ SH。在速度 SL、 SH下相应的频率和电压分别为 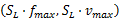
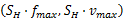
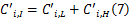
为了保持任务的运行时间,于是有关系式:
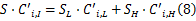
由式(7)(8)可以计算出:
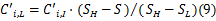
A_SPEED
{ //任务 Ti在无错和最高处理器速度的执行时间为 Ci+ 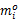
对于任务 Ti,1≤ i≤ n;
根据 S选择 SL和 SH;
选择速度 SL执行任务;
//计算任务在 SL下的执行时间
ttrig =t+( Di-t)( SH-S) /( SH-SL)
SetTimer( ttrig);//给任务的执行设一个计时器
SetTimer( t)
Set Timer to be triggered at t;
On Trigger()
Ri=Ri-SL( t-l)// l代表先前时刻 t
If( Ri>0)
Then 速度 SH执行。}
为了保证系统的可靠性、实时性,同时尽可能降低系统的功耗,提出了基于检查点机制的容错节能调度算法(CPFTES)。该算法使用EDF调度策略,在任务调度前,插入检查点到任务中,当错误发生时,任务回卷到最近的检查点,重新执行任务。利用DVS技术调节任务的运行速度,降低系统的能耗。
CPFTES Algorithm
1.For each Ti in T, do {
1.1 Calculate 
1.2 Calculate Slack;
1.3 if Slack0;
Return exist equidistant checkpoint;
1.4 Calculate Fi;}
2 Calculate speed S;
3 Select speed policy
(H_SPEED OR A_SPEED).
1.1~1.3计算每个任务优化的检查点的数量,同时判断是否存在优化的检查点。1.4计算每个任务的恢复时间间隔。第2步计算任务的运行速度。第3歩选择速度策略,确定任务最终的运行速度。CPFTES算法的计算时间主要消耗在确定优化的检查点上,因此时间复杂度为 O( n)。
仿真实验环境是Pentium(R) Dual-core CPU 2.20 GHz、2 GB RAM的个人计算机,实验的代码用C语言编写。将每个任务集的能耗归一化,也就是将每个任务集的能耗除以任务集最大的能耗(最大频率下运行的能耗),所以归一化的能耗的值在 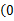
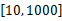
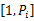
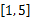
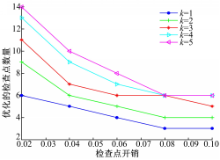
从图2可以看出,在错误数量一定时,检查点开销增加,优化的检查点的数量降低。检查点的开销越大任务的执行时间就越长,这时可以降低检查点的数量。因为添加过多的检查点,任务就有可能错过截止期限。错误的数量增加,优化的检查点数量随之增加。增加检查点,减少了检查点之间的间距,有利于错误的恢复。
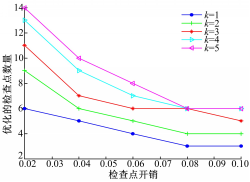 | 图2 检查点开销对优化的检查点数量的影响Fig.2 Overheads of checkpoint vs number of optimal checkpoint |
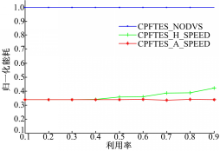
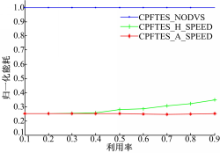
仿真实验比较了CPFTES算法的3种策略,第一种策略(CPFTES_NODVS)没有采用DVS技术,任务始终以最大的处理器速度运行;第二种策(CPFTES_H_SPEED)任务的运行速度大于或等于连续频率计算出来的速度 S;第三种策略(CPFTES_A_SPEED)任务以相邻的速度运行。图3和图4分别是CPFTES算法在PXA250处理器和TM5800处理器上的仿真结果。
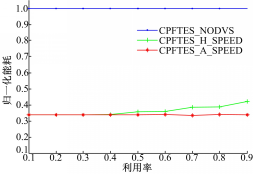 | 图3 PXA250处理器运行结果Fig.3 Running results of PXA250 processor |
 | 图4 TM580处理器运行结果Fig.4 Running results of TM580 processor |
从图3和图4都可以看出,CPFTES_A_SPEED的能耗始终低于CPFTES_H_SPEED的能耗。随着任务集利用率的增加,CPFTES_A_SPEED和CPFTES_H_SPEED的能耗随之增加。图3中任务集所消耗的能耗比图4任务集消耗的能耗大,这主要是因为TM5800处理器比PXA处理器提供的速度多;任务集在TM5800运行时,实际的运行速度更接近计算出来的理想速度 S。在任务集的利用率小于0.3时,CPFTES_A_SPEED和CPFTES_H_SPEED的能耗几乎相同,这是因为任务集的利用率低时,所计算出的理想速度 S小于关键速度 Scrit,两种策略的运行速度都设定为关键速度 Scrit。从图3可以看出,CPFTES_A_SPEED比CPFTES_H_SPEED节约0~19.41%的能耗,CPFTES_A_SPEED比CPFTES_NODVS平均节约66.18%的能耗。从图4可以看出CPFTES_A_SPEED比CPFTES_H_SPEED节约0~28.15%的能耗,CPFTES_A_SPEED比CPFTES_NODVS平均节约74.95%的能耗。仿真实验表明CPFTES_A_SPEED始终比CPFTES_H_SPEED节能;任务集在TM5800上运行的能耗低于在PXA250上运行的能耗。
针对处理器提供的离散频率和电压,在保证任务集的可靠性和实时性的基础上,提出了针对周期任务的CPFTES算法。该算法的容错是通过检查点机制实现的,利用DVS技术节能,考虑了处理器的动态功耗和静态功耗,并使用了关键速度,以达到能耗最低。通过分析CPFTES算法的两种速度选择策略,可知CPFTES_A_SPEED的节能效果优于CPFTES_H_SPEED。仿真实验表明,在PXA250处理器上CPFTES_A_SPEED比CPFTES_NODVS平均节约66.18%的能耗。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|