

{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于网格单元的DBSCAN算法
[刘淑芬 , 孟冬雪, 王晓燕]
, 孟冬雪, 王晓燕]
, 孟冬雪, 王晓燕]
|
|


作者简介:刘淑芬(1950-),女,教授,博士生导师.研究方向:计算机网络协同工作技术,软件编程新方法. E-mail:liusf@mail.jlu.edu.cn
针对DBSCAN算法时间开销大的缺点,提出了基于网格单元的DBSCAN算法,通过对数据空间进行网格单元划分来优化DBSCAN算法中最耗时的区域查询过程,省去了大量不必要的查询操作,并分析了网格单元的划分方式对本文算法的影响,通过选取最优划分方式,提高整个算法的运行效率。通过仿真实验,验证了基于网格单元的DBSCAN算法具有较高的准确率和较低的时间复杂度。
To overcome the time overhead shortcoming of Density Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm, a modified DBSCAN algorithm based on grid cell is proposed. Using this algorithm the data space is divided into grid cells and large number of unnecessary operations is eliminated, thus the region query process, which is the most time-consuming in DBSCAN algorithm, is optimized. The effects of different grid division methods are analyzed to select the optimal division method, thus improving the total operation efficiency of the algorithm. Simulation results verify that the modified DBSCAN algorithm based on grid cell has higher accuracy and lower time complexity.
数据挖掘是从大量数据中“挖掘”隐含的、有潜在应用价值的信息的过程[ 1, 2]。聚类技术是数据挖掘的一个主要研究方向,它将要分析的数据集合根据每个数据的特点进行分组,并把特征相似的数据归为一类(簇)。目前提出的聚类算法可以分为划分、层次、基于密度和基于网格几种[ 3, 4, 5]。其中基于密度的聚类算法应用广泛,基本思想是:只要邻近区域的密度超过某个阈值就继续聚类[ 6],不需要对簇的数量进行预先设定,因此适合对未知内容的数据集进行聚类[ 7]。
DBSCAN(Density-based spatial clustering of applications with noise)算法是一种简单、有效的基于密度的聚类算法,具有代表性。但该算法的时间开销很大,时间复杂度为 O( n2)[ 8]。因此对DBSCAN算法进行优化,减少运行开销,提高准确度,具有重要意义。本文在DBSCAN算法的基础上,提出一种基于网格单元的聚类新方法,利用网格划分的方法,减少数据点的搜索范围,大大提高了DBSCAN算法的效率。
DBSCAN聚类算法能够发现任意大小和任意形状的聚类,能有效识别离群点[ 9],并且对输入对象的顺序不敏感,这些优点使其在许多领域得到了广泛的应用。
定义1 数据点 p的 Eps邻域:是以数据集合 D中的点 p为圆心,以 Eps为半径的圆区域。区域中包含的点集合记作 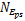
定义2 数据点 p的密度:是数据集合 D中数据点 p的 Eps邻域中数据点的个数。
定义3 核心点:如果数据点 p的密度大于或等于Min Pts则称其为核心点,其中Min Pts是由用户指定的一个阈值。
定义4 边界点:是指数据点 q本身不是核心点,但它包含在另外一个核心点 p的 Eps邻域内,则称 q为边界点。
定义5 噪声点:数据集合中既不是核心点也不是边界点的其他点称为噪声点。
定义6 直接密度可达:设数据点 q是核心点,只要满足数据点 p属于数据点 q的 Eps邻域,则说数据点 p从数据点 q直接密度可达,记作:
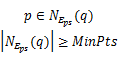
定义7 密度可达:如果存在数据点链 p1, p2,…, pn,其中 p1 =p, pn=q, pi∈ D,1≤ i≤ n,而且有 pi从 pi+1直接密度可达,则称数据点 p从数据点 q密度可达。
定义8 密度相连:数据集合 D中,对于给定的 Eps和Min Pts,如果存在点 o,使得数据点 p和数据点 q都从数据点 o密度可达,则称数据点 p和数据点 q关于 Eps和Min Pts密度相连。
在DBSCAN算法发现聚类的过程中,先从数据集合 D中找到任一数据点 p,考察点 p,如果 p是核心点,即 p的邻域中点的数目大于等于 MinPts,那么 p的 Eps邻域中的数据点在接下来的过程中作为种子点,进行进一步考察。具体就是:不断对种子点进行区域查询,如果当前种子点也是核心点,则将它的 Eps邻域中的点也加入种子集合中。通过这种方式,不断扩展当前数据点所在的类(簇),直到找到一个完整的类(簇)为止,这样就确定了一个关于 Eps和 MinPts的聚类。如果 p是一个边界点,即 p的邻域中点的数目小于 MinPts,则DBSCAN算法选取数据集 D中的下一个点进行处理。而数据集合中最终剩下的没有被划分到任意类(簇)中的数据点就被标记为噪声点。
点 p邻域中数据点的数目是通过不断执行区域查询和判断来获取的[ 9],以二维数据为例,网格上的区域查询如图1所示。
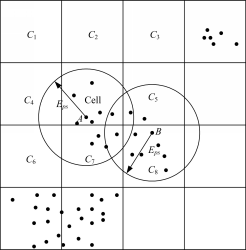 | 图1 网格单元上的区域查询Fig.1 Region query on grid cell |
每次查询判断返回区域中的所有对象,DBSCAN算法的时间复杂度为 O( n2),可见算法的时间开销很大。另外,算法运行时,所有数据都应该存放在内存中,当数据量增大时,要求较大的内存支持,I/O消耗也很大[ 10]。针对以上两点,本文提出一种网格单元划分方法,优化区域查询操作以减少时间开销。
算法使用宽度优先搜索来联接多个网格区域,并使用贪婪算法的生长模式来形成聚类。
定义9 网格单元:用户设定一个划分参数 ε,根据这个参数可以将数据空间在每一维上划分为 π个相同长度(即 ε)的区间,每个维度上做相同的划分,从而将整个数据空间划分成边长为 ε的网格。记作网格单元 Cell={ c1, c2,…, cn}, ci={[ lij, hij)},1≤ i≤ n,其中 hij— lij=ε, i表示维度, j表示空间序数,这是一个左闭右开区间。在网格单元划分的过程中,最后一个网格单元的边长可能不足 ε,可以将该边长看作 ε,这样既不会影响计算的准确性,又可保证计算的一致性。
定义10 k-邻接网格集合:网格单元 Cell的 k-邻接网格集合定义为沿网格 Cell的上下左右4个方向各延伸 k个网格边长(即 k×ε的距离)后所构成的矩形区域所包含的网格集合,记作 Ncell。
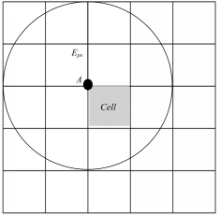
定义11 Eps矩形域:以二维网格 Cell的4个顶点为圆心,画4个半径为 Eps的圆。网格单元 Cell的 Eps矩形域定义为能够覆盖这4个圆区域的 k-邻接网格集合所构成的区域。
为了便于计算网格单元 Cell的 Eps矩形域,取网格单元的边长 Lpg=Eps/γ。显然,当 γ≥1时,网格单元 Cell的 Eps矩形域为 Cell的 γ-邻接网格集合所构成的区域,边长为(2 γ+1) ×Lpg;当 γ<1时, Cell的 Eps矩形域为 Cell的1-邻接网格集合所构成的区域,边长为3× Lpg。
图2所示为当 γ=2时,网格单元 Cell的 Eps矩形域。由图2可以看出,当网格单元 Cell的 Eps矩形域内的点的数目不足 MinPts时, Cell内任意一点都不可能是核心点,而当网格单元 Cell的 Eps矩形域内的点的数目大于等于Min Pts时,种子点仅需计算与 Eps矩形域内的点的距离,以判断该点是否是核心点,从而可以在很大程度上减少点与点之间距离的计算。
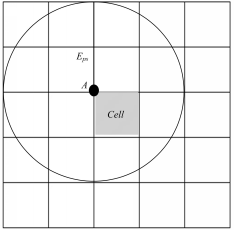 | 图2 网格单元 Cell的 Eps矩形域Fig.2 Eps rectangular area of grid unit Cell |
基于网格单元的DBSCAN算法首先获取数据集合所在的大区域,然后通过网格划分的方法减少每个点的邻居对象的搜索范围,利用宽度优先搜索,忽略掉低密度的单元,用高密度的区域生成聚类。基于网格单元的DBSCAN算法可以分为以下几个步骤:①将数据空间划分为多个网格单元;②建立数据点到网格单元的映射;③利用宽度优先搜索生成聚类。
点 p邻居对象搜索范围的缩小是在步骤③中体现的,具体步骤如下:
(1)将第一个(下一个)标记为未读的数据点作为种子点送入队列,若所有点都已读,则结束。
(2)如果队列不为空,取队列首部的点进行 Eps矩形域上的区域查询,并将其标记为已读,如果队列为空,执行第(1)步。
(3)如果 Eps矩形域内点的个数大于等于Min Pts,则在 Eps矩形域内检测与种子点之间距离小于等于 Eps的点的个数是否大于等于Min Pts,如果是,则该点是核心点,将它的 Eps邻域中的点作为种子点送入队列,如果不是,则将其还原为未读。如果 Eps矩形域内点的个数小于Min Pts,则直接将该点还原为未读。
(4)循环执行第(2)(3)步。
对于核心点的判断方法,上文已经详细说明,值得一提的是,本算法采用欧氏距离公式计算两个 t维空间点的距离,公式如下:
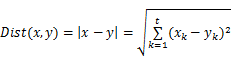
本文所用数据均为二维数据,算法共分为三大步:第一步网格的划分需要计算数据空间上每一维的最大、最小值,时间复杂度为 O( n);第二步进行数据点到网格单元的映射,需要遍历 n组数据,时间复杂度也是 O( n);第三步聚类的生成利用了宽度优先搜索算法,对种子点的考察穿插在宽度优先搜索的过程中,时间复杂度为 O( n+me), m为扩展的种子点的个数, e为当网格单元的边长 Lpg=Eps/γ时,计算(2 k+1)2个网格内的点数 s并施行相应操作所用的时间,为 O( k2),其中:若 γ≥1, k=γ;若 γ<1, k=1。故整个算法的时间复杂度为 O( n+mk2),可见 m和 k的值越小,时间复杂度越低。
对于数据集合明显呈现一个或多个簇的情况,当 γ<1时, k=1,虽然 k足够小,但是由于网格明显增大, Eps矩形域内点的个数也将明显增多,显然时间复杂度高于 γ=1的情况。当 γ≥1时, k=γ,此时随着 k值的增大, Eps矩形域缩小,但是 k2的值会明显增大,具体哪一方面的作用明显,要视簇所呈现的状态而定,一般情况下 k2的增大作用更明显。
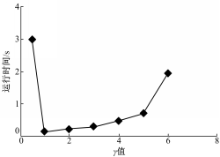
图3是多次对数据量为10 000的数据集合进行聚类时,不同 γ值情况下,运行时间的平均值。
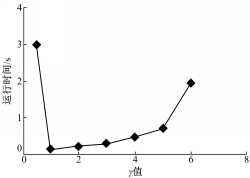 | 图3 γ值对运行时间的影响Fig.3 Effect of γ value on running time |
根据2.3节的分析和图3所示的实验数据,本文算法选取 γ=1。采用二维仿真数据集合,分别用原始DBSCAN算法和基于网格单元的DBSCAN算法进行聚类分析。算法用Visual Studio 2010实现,实验在一台PC(Intel Core i7 3.4 GHz处理器,8 G内存,500 G硬盘)上完成。参数 Eps=10,Min Pts=3。
两个算法分别针对同一数据集运行5次并取得运行时间的平均值,在数据量分别为2000、4000、6000的情况下,得到运行时间和准确率如表1所示。
由表1可知,基于网格单元的DBSCAN算法具有较高的准确率和较低的运行时间。
| 表1 两种算法运行时间和准确率对比 Table 1 Comparison of two algorithms on running time and accuracy |
在数据量分别为2000,4000,…,20 000的情况下,两个算法分别针对同一数据集运行10次并取得运行时间的平均值得到的实验结果如图4所示。由图4可直观看出,对相同规模的数据集,本文算法运行时间明显降低。
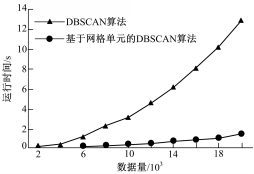 | 图4 两种算法运行时间对比Fig.4 Comparison of two algorithms on running time |
本文在分析了原始的DBSCAN算法优缺点的基础上,提出了基于网格单元的DBSCAN算法,该算法继承了原始DBSCAN算法的优点,并利用网格技术,避免了原始DBSCAN算法中大量不必要的距离计算,提高了算法的运行效率。实验证明,改进的基于网格单元的DBSCAN算法取得了令人满意的结果。今后的工作主要是将算法扩展到多维度,以满足更复杂的数据聚类分析需求。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|