


{kind=link}
{kind=link}
{kind=link}
基于LRU淘汰机制的自适应大流检测算法
[任高明 , 夏靖波, 乔向东, 杨仝]
, 夏靖波, 乔向东, 杨仝]
, 夏靖波, 乔向东, 杨仝]
|
|


作者简介:任高明(1986-),男,博士生研究生.研究方向:互联网测量.E-mail:gaomingren_928@126.com
针对现有大流检测算法自适应能力差和难以满足工程应用需求的问题,提出一种新的基于“最近最久未用”淘汰机制的自适应大流检测算法。该算法设置流归并和LRU两级缓存,数据分组到达时,首先进入流归并缓存,按照“流关键字”通过哈希算法实现数据分组到流的匹配,并对流大小进行估计;同时根据上一时刻被LRU淘汰流的大小实时调整LRU缓存之前的过滤门限;然后比较流估计值和门限大小,估计值大于门限的流所含数据分组进入LRU缓存进一步筛选,否则丢弃。为保证实时性和过滤效果,分析并提出了门限时长的设置方法。理论推导和实验结果表明:该算法既保证了准确性又提高了自适应性,更适合工程应用。
The adaptivity of the existing methods of elephant flow identification is poor and can not meet the needs of engineering application. In order to solve this problem, a novel algorithm based on Least Recently Used (LRU) replacement was developed. The algorithm has two caches, flow merge cache and LRU cache. First, the packet goes into flow merge cache and is matched to flow records according to flow keywords, and the length of flow is estimated. In the meantime, the threshold is changed with the previous length of the flow estimated by LRU cache in real time. Then the estimation of the flow is compared with the threshold; if the estimated length of the flow is longer than threshold, the packet belongs to the flow can go into LRU cache and be further filtered, otherwise the packet is abandoned. To guarantee the filtering effect and real-time performance, a method of setting up the threshold of time span was proposed. Theoretical analysis and experiment results illustrate that the algorithm can guarantee the accuracy, improve the adaptivity, and is more suitable for engineering application.
网络流量测量是掌握网络信息,理解和认识网络行为规律,优化、重新规划网络结构的基础[ 1]。随着网络规模的不断扩大和链路速率的迅速提高,数据分组到达的频率越来越高[ 2],网络流量测量硬件的处理速度难以满足需要。这种情况下,传统的全流量测量方法已不再适用[ 3]。如何在有限的硬件资源条件下,完成高速链路下的流量测量成为当前亟待解决的问题。
通常,网络流量测量以流为单位进行。研究发现互联网中流大小服从重尾分布[ 4],即大流占据了大部分流量,而其余的流量由大量小流组成。在实际应用中,大部分情况下,掌握少数的大流信息就可以满足需要[ 5]。因此,研究包含大量信息的小部分大流是网络流量测量的重要分支,对于网络计费、带宽规划和检测Dos攻击等网络管理应用意义重大[ 6, 7]。Cristian等[ 8]第一次明确提出了在网络流量测量中采取“抓大放小”的策略,以放弃小流量对象信息为代价换取存储空间和处理速度上的优势。此后,大流检测成为网络测量的研究热点之一[ 9, 10]。
目前,大多数的大流检测算法主要集中在理论研究方面,普遍使用的面向工程的流量测量工具是采用系统抽样的Netflow[ 11],其主要缺点在于:准确性欠佳、自适应能力差;系统抽样的周期性可能会使被测对象陷入同步状态。而现有的理论算法或者实现难度大,或者准确性较差,且大多数需要人为设置相关参数,均难以应用于工程实际中。
在实际网络链路中,流量复杂多变,参数的人为设置难以适应网络流量的变化,且极大地限制了方法的扩展性。因此,作者根据网络流量实时情况,提出了一种自适应地调整相关参数的大流检测算法。
Estan在文献[8]中提出了Sample and Hold和Multi-stage Filters两种算法。Sample and Hold的基本思想是用概率 p对每个字节进行抽样,则大小为 s的数据分组被抽样的概率为 ps=1 -( -p) s,可以发现,包含字节数多的大流被抽取的概率更大;当某个流所属数据分组被抽样后,属于该流的后续数据分组到来时,流的信息均会被更新,因此保证了测量的准确性,该方法较易实现,所需缓存小,但由于需要对每个字节进行处理,开销较大。Multi-stage Filters的基本思想是:Bloom Filter中每一向量位关联一个计数器;根据关键字将数据分组映射到Bloom Filter的向量位中,并将数据分组的大小积累到对应计数器上。由于同一个流 F所含数据分组会映射到同一个向量中,当流 F对应的计数器值达到或者超过阈值 T时,即将流 F识别为大流。考虑到哈希碰撞会引起误判,Multi-stage Filters采用多级Bloom Filter,每级使用独立的哈希函数,只有各级相应向量位的计数器值都大于阈值的流才会被识别为大流,从而大大减少了假阳性误判。但是由于哈希算法会将不同的流映射到相同的向量位上,导致高估大流的实际流量;硬件实现复杂,算法启动较慢,初期会丢失采样数据分组,难以应用于实时测量。
文献[12]将计算机中的页面置换算法——最近最久未用(Least recently used,LRU),应用于大流检测。LRU算法的基本思想是:设置一个用于保存流记录的固定大小的缓存;保持最新到达的数据分组所属流记录位于缓存最顶部,则最久未到达数据分组所属流的记录位于缓存的最底部;当有新流到达而缓存已满时,把缓存最底部的流替换出去为新流腾出空间。大流持续时间长且分组到达速率高,使得其总能排在缓存的上部,从而以较大的概率留在LRU缓存中。但该方法的缺点在于当有大量小流突发到达时,会造成某些大流被替换出LRU缓存,从而造成漏检[ 13]。文献[12]的实验结果中有10%到20%的大流被漏检。
针对上述问题,本文提出一种基于LRU淘汰机制的自适应大流检测算法,称之为LRU_Based算法,该算法在保证检测准确性的同时,提高了算法的自适应性,使得其更适合工程应用。
算法的基本思想:根据LRU缓存上一时刻淘汰流的大小调整过滤门限,对即将进入LRU缓存的数据分组提前进行判断;只有所属流的估计值大于该门限值的数据分组才能进入LRU缓存进行进一步筛选,否则丢弃。
算法处理流程如图1所示,流归并缓存和LRU缓存长度均固定。在流归并缓存中,当数据分组到达时,按照“流关键字”通过哈希实现数据分组到流记录的匹配。缓存中使用哈希双向链表组织流记录,归并时对每个流设定一个计数器 c进行计数,将 c值作为数据分组所属流的估计值;每隔 t时间,对流计数器清零,重新计数。
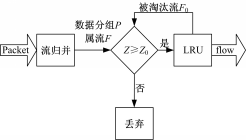 | 图1 处理流程图Fig.1 Processing flow chart |
1.初始化门限值 Z0=0;
2.数据分组 P到达;
3.if 存在 P所属流的记录;
4.更新相应流计数器: c=c+P包含字节数;
5.else;
6.在链表尾部创建新流记录,并置相应计数器为 c=P包含字节数;
7.记 p所属流的估计值 Z=c;
8.if Z≥ Z0;
9.数据分组 P进入LRU缓存
10.if LRU缓存已满;
11.丢弃LRU底部的流 F0,根据规则调整过滤门限 Z0;
12.if P属于LRU中流 F;
13.流 F的字节数 =流 F的字节数 +P包含字节数;
14.将流 F的记录置于LRU的队列顶部;
15.else;
16.建立新流,放置于缓存顶部,相应计数器计为 P0;
17.else; 丢弃 P;
LRU_based算法最初的目的在于:当有大量小流短期到达时,必然会导致大流被LRU缓存丢弃的情况发生,一旦发生,迅速提高过滤门限,有效地过滤掉包含数据分组较少的小流。该算法是以牺牲少量常态准确率换取大量小流短期出现时的准确率。首先给出两个定义。
定义1:门限时长是指根据淘汰流的大小设置的门限值应该保持的时间。
定义2:门限超时是指门限值的实际保持时间超过了门限时长。
门限时长 T应随着淘汰流 M变大而增大,即 T( M)为增函数,即 T(1) <T(2) <… <T( n) <T( n+1) <…。为方便计算,此处设定 T和 M成正比例关系,即满足 T=KM( K为常系数),则 T( n) =nT(1)。
类似地,门限值与淘汰流之间的关系也为增函数,同样设置为正比例关系,即门限值 Q=LM( L为常系数)。设置门限后,如果下一时刻丢弃的流更大,说明当前门限值还不够大,应该提高门限;如果丢弃的流变小,证明设置门限有效,属正常情况,则维持当前门限不变,等待当前门限时长结束。实现流程如图2所示,其中 T0为根据门限值 Z0设置的门限时长。
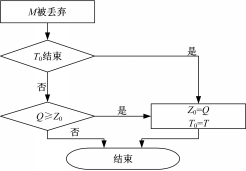 | 图2 时长设置流程图Fig.2 Flow chart of duration setup |
数据分组进入流归并缓存和LRU缓存时,首先查找相应的流记录,本文均采用Hash方案,其计算复杂度均为 O(1)。随后的操作包括LRU缓存中流记录在双向链表中的移动,流记录的移动是有限常数次指针操作,其计算复杂度为 O(1),因此,LRU_based算法处理一个数据分组的时间复杂度为 O(1)。
流归并缓存部分,假设 b为分组平均大小; R为链路速率, n为每流平均分组数,则在时间 t内到达流测速缓存的流个数,也即流归并缓存的空间为:

LRU缓存部分,由于每个大流所占链路总容量的比例为 P,所以最多会有1 /P个大流,故LRU缓存的空间复杂度为 O(1 /P)。
处理一个数据分组需要访问存储器的次数是衡量一个算法效率的关键因素之一。在LRU方法中,表项采用双向链表结构组织,当有新的数据分组到达时,首先查找LRU缓存中是否有相应的流记录,分两种情况:①不存在相应的流记录,新建流记录;②存在流记录,对其更新,分别需要访问内存4次(如果新建流记录后,LRU缓存已满,则将最后一个表项丢弃,需访问内存1次,此时共需访问5次)和6次。LRU算法访问存储器次数如下:首先,在LRU缓存中查找流记录分两种情况,若 F属LRU:查找记录(1次);修改流目录(4次);修改指针(1次),共6次;若 F不属LRU:查找记录(1次);创建流目录(1次);修改第一个指针(2次),共4次。
本文方法和LRU方法相比,在内存访问次数上,增加了流归并缓存中的处理过程。
在流归并环节,由于采用单向链表结构。数据分组访问内存的次数最少的情况为:数据分组进入流归并缓存,查找相应流记录;找到并修改流记录;当该数据分组所属流小于当前门限值时,被丢弃,这种情况下,处理该数据分组需要访问内存2次。
当数据分组进入流归并缓存,查找;没有找到相应的流记录,此时需创建新的流记录;修改指针,共需要访问内存3次。即在流归并阶段,最多需访问内存3次,最少2次。
结合上述LRU缓存访问次数的分析,LRU_based方法处理一个数据分组最多需访问存储器(3+6)次,最少为2次。
表1为LRU_based算法与Sample and Hold算法、Multistage Filters算法[ 8]和LRU算法访问存储器的次数比较。
根据以上分析,算法最多需要9次访问内存操作。根据当前的硬件性能,SRAM访问速度可以达到2~5 ns,假设使用3 ns的SRAM,则最坏情况下,算法需要27 ns处理一个数据分组。当有大流被淘汰时,门限值提高,使得大量属于小流的数据分组不能进入LRU缓存,进一步降低了平均内存访问次数,提高了算法的处理速率。互联网中封装TCP协议的IP分组最小长度为40字节,10 GB链路中,满负荷状态下每个分组的处理时间为32 ns。因此,算法的处理速度理论上完全可以满足10 Gbit/s链路的要求。
| 表1 不同算法访问存储器次数比较表 Table 1 Number of different algorithms access memory table |
设流归并缓存大小为 L0,LRU缓存大小为 L1,每隔 t时间对归并缓存的计数器进行清零处理。单位时间段内通过链路的流个数平均为 S,则在 t时间段内进入流归并缓存的流数量可近似为 tS,则所需流归并缓存的大小为 L0 =tS。即所需流缓存的大小和时间 t成正比,因此, t越小越好;另一方面, t又不能太小,以至于失去流归并的功能。经过试验验证,此处取 t=1 s最合适。
本文选取LRU算法、Multistage Filters和Sample and Hold三种算法作为参照,与本文算法进行比较。为公平起见,为各种算法分配相同的内存2000 kB,即10 000个流表项。对本文算法,流归并缓存部分和LRU缓存部分分别分配2000和8000流表项;对Multistage Filters算法,设置为4级过滤器;对于Sample and Hold算法,选取抽样率为0.000 04;对于LRU算法,则将流表项设置为10 000。
实验数据为oc48-mfn;时间为2011.01.15;链路速率为2.5 G;单位时间内流量为3373;单位时间内分组数为59 193;单位时间内数据量为38.67。来自互联网数据分析合作协会(CAIDA)所提供的300 s的实际互联网数据。实验平台为配有2.69 GHz CPU和2 GB内存的Ubuntu主机,实验代码采用C语言编写,编译器为GCC4:4.5.2-1 ubuntu3。
本文以5元组作为流的定义,大流门限为链路容量的0.01%。
为使各种算法测量效果的展示更为直观,首先对oc48-mfn的前5 s数据,采用不同的算法进行大流检测,将检测出的大流从大到小排序,如图3所示。
在前5 s时间内,oc48-mfn测试数据流的总数为45 382个,大流的数量为104,如图3(a)所示;对于LRU算法,检测得到的大流数为91;如图3(b)所示,丢掉了数值较大的几个大流点;对于MF算法,计算得到的大流数目为107,如图3(c)所示;MF算法检测出的大流数量多于实际大流数目,原因是MF使用Hash函数存在将多条流映射到同一个入口,多条小流相加检测为大流的情况;对于SAH算法,设置抽样率为0.000 04,计算得到的大流数目为82;对于本文算法,反馈函数采用正比例函数,经过多次试验,发现当取 L=0 .3、 K=2时效果较好,计算得到的大流数目为101。
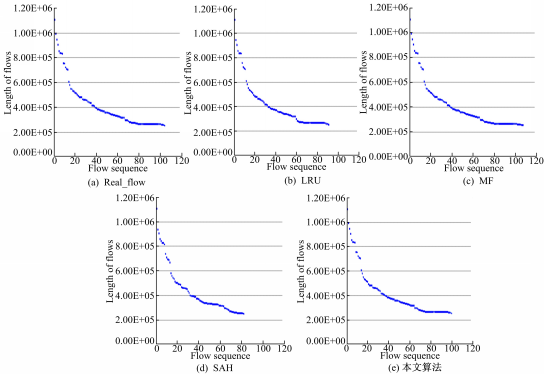 | 图3 大流检测算法效果比较Fig.3 Algorithms comparison |
将总的测量时间300 s分为 J段,每5 s为一测量时间段,假设第 j个测量时间段内共有大流 Mj个,其中大小分别为 Ni字节,使用本文算法检测的相应的流大小为 Ti( i≤ Mj),漏检的大流个数为 Oj,误检的大流个数为 Qj,采用3个尺度衡量算法的准确性:
平均假阴性误判率(AFNR):
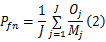
平均假阳性误判率(AFPR):
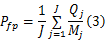
第 j个时间段相对误差率:
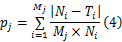
故整个测量时间平均相对误差率(ARER):
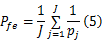
经过试验比较,得到的结果如表2所示。
| 表2 算法准确性比较 Table 2 Comparison of algorithm accuracy % |
Sample and Hold算法由于只需访问一次存储器,效率较高且容易实现,但假阴性误判率较高,很多大流不能被检测到;Multistage Filters算法不存在假阴性误判,但假阳性误判率较高,处理速度慢、实现难度大;本文算法相对于Sample and Hold算法更准确;相对于Multistage Filters算法速度更快。因此,本文算法满足工程应用所需的实现简单、处理速度高、准确性较高的要求。
本文针对现有算法自适应能力差和难以适应工程应用的问题,在LRU算法的基础上,提出一种采用反馈策略的自适应大流检测算法,尽管复杂度较高,但该算法实现简单,准确性较高,能满足高速网络流量测量需要,自适应性强,更适合工程应用。在本文中,为计算方便,限时长设置函数和门限值设置函数均选择简单的正比例函数,达到很好的检测效果。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|