
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于极值外推的高速列车齿轮传动装置载荷谱编制
[宫海彬1, 2  , 苏建
, 苏建1 , 王兴宇3 , 徐观1 , 张益瑞1 ]
, 苏建, 王兴宇|
|


作者简介:宫海彬(1987-),男,博士研究生.研究方向:车辆智能化检测与诊断.E-mail:gonghaibin126@aliyun.com
针对传统传动系载荷谱编制时计数及统计方法的局限性及高速列车齿轮传动装置载荷测量的特殊性,构建了基于电机有功功率的高速列车齿轮传动装置扭矩间接测量方案,统计了传动系扭矩转数历程,提出了一种基于极值理论及非参数密度估计相结合的载荷数据统计方法,从而获得了总体载荷样本概率密度分布函数,并据此建立了高速列车齿轮传动装置程序载荷谱,实现了载荷极值外推和载荷谱压缩。最后,基于实测车辆网端功率转数历程完成了一个高速列车齿轮传动装置载荷谱编制算例。
For the limitations of traditional counting and statistic methods in drawing up load spectrum and the particularity of high-speed train gear drive load measurement, an indirect measurement scheme of torque of high-speed train drive system is proposed based on motor active power. Statistic calculation of the torque-revolution history of the gear drive system is carried out. Synthesizing extreme value theory and non-parametric probability density estimation, a load data statistical method is introduced. The probability density function of the overall load samples is obtained, and load extreme extrapolation and load spectrum compression are realized. Accordingly, high-speed train gear transmission unit's load spectrum is established. A case study based on measured network end power of rolling stock is presented to verify the proposed scheme.
车辆在轨道上行驶时,高速列车齿轮传动装置处于高速重载的运行工况,校核其疲劳强度是否满足机车运用要求,对提高机车车辆的可靠性有重大意义。载荷谱的编制是进行疲劳寿命分析和疲劳可靠性试验的关键[ 1]。根据实测或仿真获得的载荷时间历程编制传动系载荷谱时,往往采用能够较好反雨流计数法进行统计分析。如Xu等[ 2]采用较好雨流计数法对装载机传动系载荷数据进行计数,基于非参数法进行统计外推,从而编制载荷谱。Kim等[ 3]根据变速器输入轴的扭矩历程,采用雨流循环计数方法统计载荷循环分布并据此建立农用拖拉机传动系载荷谱。张英爽等[ 4, 5]采用雨流计数法对传动系载荷历程进行统计处理,获得载荷均值和幅值的二维联合分布概率密度函数,并据此建立二维载荷谱。由于直接测试轮齿载荷较困难,传动系载荷测量时往往仅测量传动轴的扭矩,将载荷时间历程和相邻等值数据压缩,提取峰、谷值,然后采用雨流计数法提取循环数,然而该方法将无法反映载荷历程中相邻等值及幅值波动小的载荷对基于轮齿啮合传递扭矩的齿轮传动装置疲劳寿命的影响。同时,实测载荷数据有限,难以暴露全寿命周期可能发生对部件寿命影响较大的极值载荷。
针对高速列车载荷谱编制问题,本文提出一种基于能量转换法的高速列车传动系统扭矩测量的间接测量方法,根据获得的扭矩-转数分布构建一种基于极值理论与非参数密度估计相结合的高速列车齿轮传动装置载荷数据统计方法,以获得总体载荷样本概率密度分布函数,并实现载荷极值外推,据此完成高速列车传动系统载荷谱的编制。
传动系统扭矩测量往往采用无线遥测的方法,高速列车传动系统布置十分紧凑,因此只能将应变片粘贴在联轴器表面,遥测系统发射机固定在联轴器上。但由于联轴器紧靠牵引电机,遥测系统必须解决牵引电机引起的电磁干扰问题,同时,高速列车传动系设计寿命十分长,线路试验所需测量里程相应较长,对测量系统的可靠性提出了很高的要求。
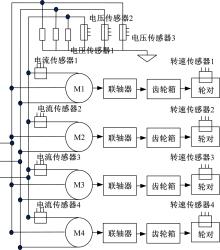
本文基于能量转换法提出适用于高速列车传动系统扭矩测量的间接测量方法,即采用电压传感器分别测量动车变流器输出三相电压,采用电流传感器测量各牵引电机单相输入电流计算得到的电机有效功率,以计算牵引电机输出扭矩。同时,将转速传感器安装在车轴轴箱盖上测量车轴转速。为测量每节动车4台电机的有功功率,构建的测量系统传感器布置如图1所示。电机每相有功功率为:
牵引电机
牵引电机输出扭矩为:
式中:
 | 图1 电机有功功率测量传感器布置图Fig.1 Measuring sensor placement for traction motor’s active power measurement |
由于测量高速列车传动系载荷时间历程进行的线路试验成本较高,而采用能量转换法在车辆实际线路运行时即可方便地进行试验测量,为获得传动系载荷时间历程提供了一个有效可靠的手段。
载荷数据统计是通过对实测载荷数据进行数据处理、概率统计,以获得代表全寿命周期载荷分布的概率密度函数,是载荷谱编制的关键。然而线路实测只能进行一定时间内的载荷时间历程的测量,不能够反映全寿命周期载荷分布,同时实测载荷包含大量不产生疲劳损伤的小载荷循环。
实测载荷数据统计包括无效载荷截除、载荷谱外推、载荷样本概率密度估计、极大值载荷截止等内容。其统计处理过程如下:①载荷数据预处理,获得齿轮传动装置的扭矩-转数分布图。②确定无效载荷门槛值,删除无效小载荷循环。③选取阈值,对大于阈值的载荷数据进行极值外推,以估计全寿命周期内可能发生的极大载荷数据,同时估计小于阈值的载荷数据的概率密度分布。④获得总体样本概率密度分布,确定载荷极值。
载荷数据中包括大量不产生疲劳损伤的小载荷循环,为提高试验效率,必须删除小载荷循环,其中无效载荷门槛值的确定是关键。
高速列车齿轮传动装置具有较高的可靠性,通常其全寿命周期内载荷循环次数大于109次,齿轮的疲劳破坏往往属于高周疲劳,疲劳极限对应的载荷循环次数为107~108。故选择累积频次为108作为截至级,所对应的载荷值作为无效载荷门槛值 Xth。对于实测载荷信号,令
载荷谱外推是依据样本推断全寿命周期内总体分布的未知部分。载荷历程中的极值载荷对部件损伤影响最大,而实测载荷仅能反映短期内的载荷历程,难以暴露全寿命周期可能发生的极值载荷。基于实测载荷数据的极值统计为准确估计极值载荷概率密度分布提供了一种有效方法。
为充分利用测量数据中包含的极值信息,可基于超出某阈值的载荷数据建立近似极值模型,即服从广义Pareto分布的超阈值载荷的概率密度分布。
2.2.1 超阈值载荷数据概率密度
如果
则称
采用矩法、概率权矩法或极大似然估计法对Pareto分布参数
2.2.2 阈值的选取
为正确估计广义Pareto分布
基于广义Pareto分布的平均超出量函数为:
式中:
定义点集
实测载荷时间历程中阈值以内载荷数据概率密度分布形式是未知的,为掌握其密度分布,本文采用核密度函数估计法对其进行估计。
对于样本
相应地,任意区间
根据选取的阈值,将实测载荷时间历程获得的载荷数据分为超过阈值的载荷样本和阈值以内的载荷样本两部分,其在总体载荷样本中的比例分别为
式中: Xmax为载荷极大值。
已有研究和实践资料认为,106个载荷循环对于很少发生的最严重情况在内的全部载荷具有足够的代表性。根据截除无效载荷后的载荷数据样本分布,选取106个载荷循环累积频次为1的载荷作为载荷极大值 Xmax,即:
程序载荷谱应在具有一定的精度的同时,保证试验简单便于实施,由于高速列车齿轮传动装置结构载荷或应力变化相对不太剧烈,其载荷谱可采用程序载荷谱描述。
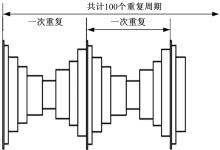
结构平均使用寿命大于20个以上的程序块谱,能够较大地减少加载顺序对疲劳寿命的影响。考虑各程序块谱所需的加载时间,选择程序块循环次数为100,从而确定各程序块谱等效载荷频次为106。将总体载荷样本的累积概率分布函数外推106倍,即得载荷累积频次分布。本文选择8级程序载荷谱模拟传动系统工作载荷谱。
根据载荷极大值和无效载荷门槛值之间的载荷范围Δ X=Xmax- Xmin,常用的分级比例系数
式中:
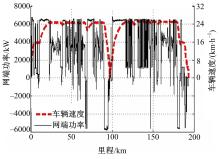
由于试验条件有限,目前尚未进行车辆运行时各牵引电机有功功率实测试验,本文基于如图2所示的某动车组型式试验时在某先导段进行典型运行图检查及能量消耗试验时测得的网端功率及车速历程两组实测数据编制载荷谱。将试验中上行和下行共运行193 km的两组数据作为一完整试验进行分析。
 | 图2 网端功率及车速历程Fig.2 Power of network end and vehicle speed history |
3.2.1 预处理
考虑车辆运行前、后车载电器消耗功率大致相同,可得牵引电机消耗(产生)的功率
将牵引传动系统各部件功率因数、效率视为不随运行工况变化的常数,对各电机传递至传动系统的平均功率做近似估计,电机驱动状态时:
电机配合摩擦制动动力制动时:
式中: Pw为实测网端功率; Pw0为未运行时初始网端功率; Pm为电机输出功率; ηtr=0.94,为牵引变压器效率; ηconv=0.975,为脉冲整流器效率; ηinv=0.985,为逆变器效率; pm=0.87,为电机功率因数; ηm=0.94,为电机效率。
电机传递至传动系统的扭矩为:
式中:
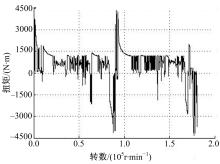
统计每转对应的电机输出扭矩,从而获得牵引电机输出扭矩-转数历程,如图3所示。保守考虑,将车辆制动时电机输出的负扭矩变成正扭矩。样本载荷最大值为 Tmax=4467 N·m,根据截至级计算公式得 Nth=16 080,从而得无效载荷门槛值 Tth=1840.1 N·m。
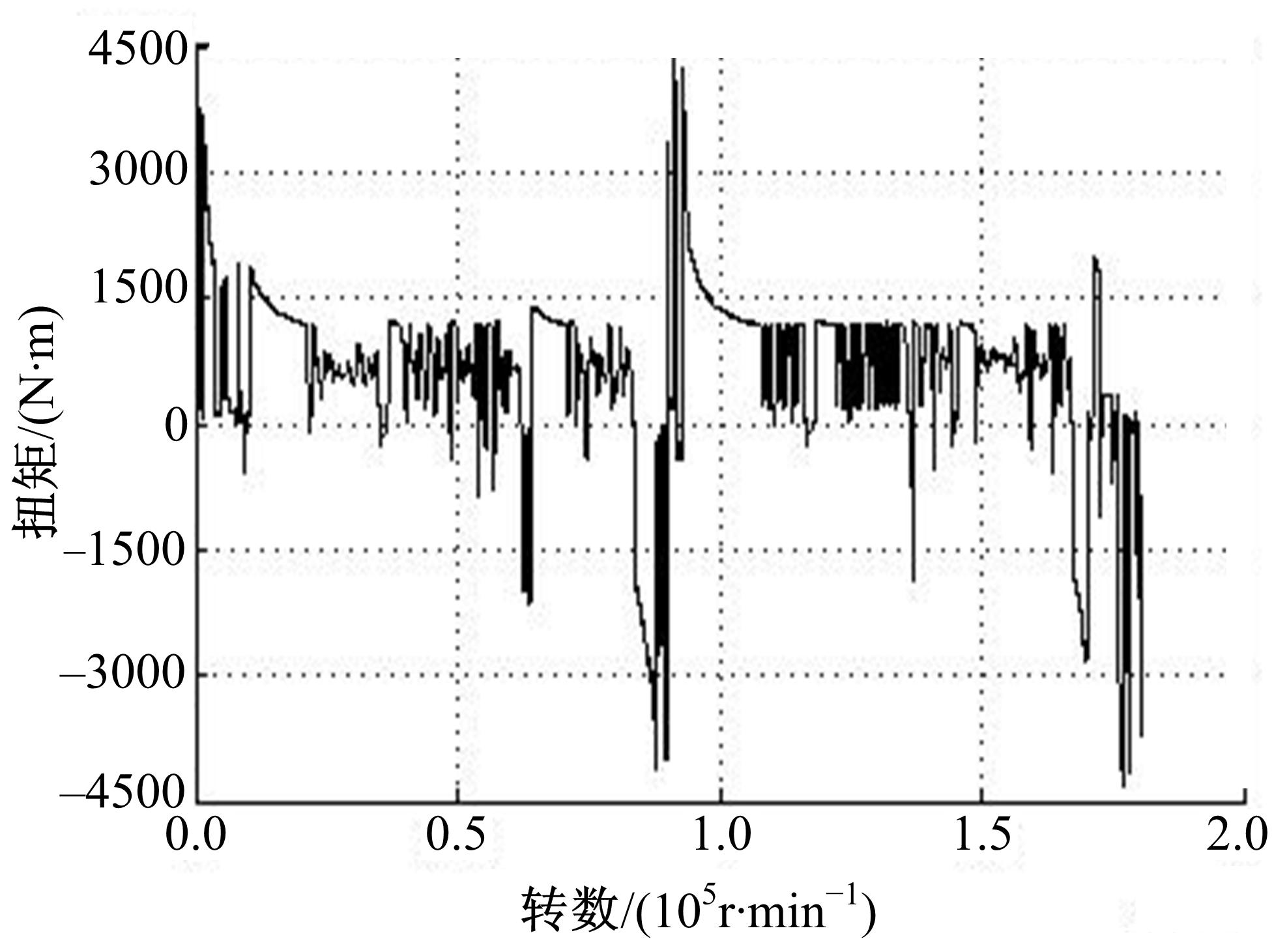 | 图3 牵引电机输出扭矩-转数历程Fig.3 Motor output torque-revolution history |
3.2.2 载荷数据统计分析及载荷谱编制
截除小于无效载荷门槛值的载荷,对剩余样本进行统计分析。根据前文所述方法计算样本超出量函数,并考虑超过阈值的样本个数,选取 u=4100,超过阈值的数据共528个,具体计算过程不在此赘述。样本参数进行极大似然估计
分位数 xp的估计为:
可得载荷样本上端点
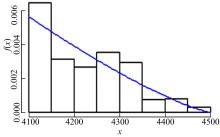
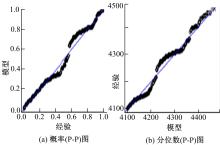
采用P-P图、Q-Q图对GPD模型拟合的载荷分布进行诊断,如图4所示,由于载荷数据不是完全独立同分布的随机变量,数据拟合效果并不是太好,但样本基本为一条直线,图5所示超阈值载荷的概率密度与直方图基本吻合,因此诊断图基本能支持所拟合的GPD模型。
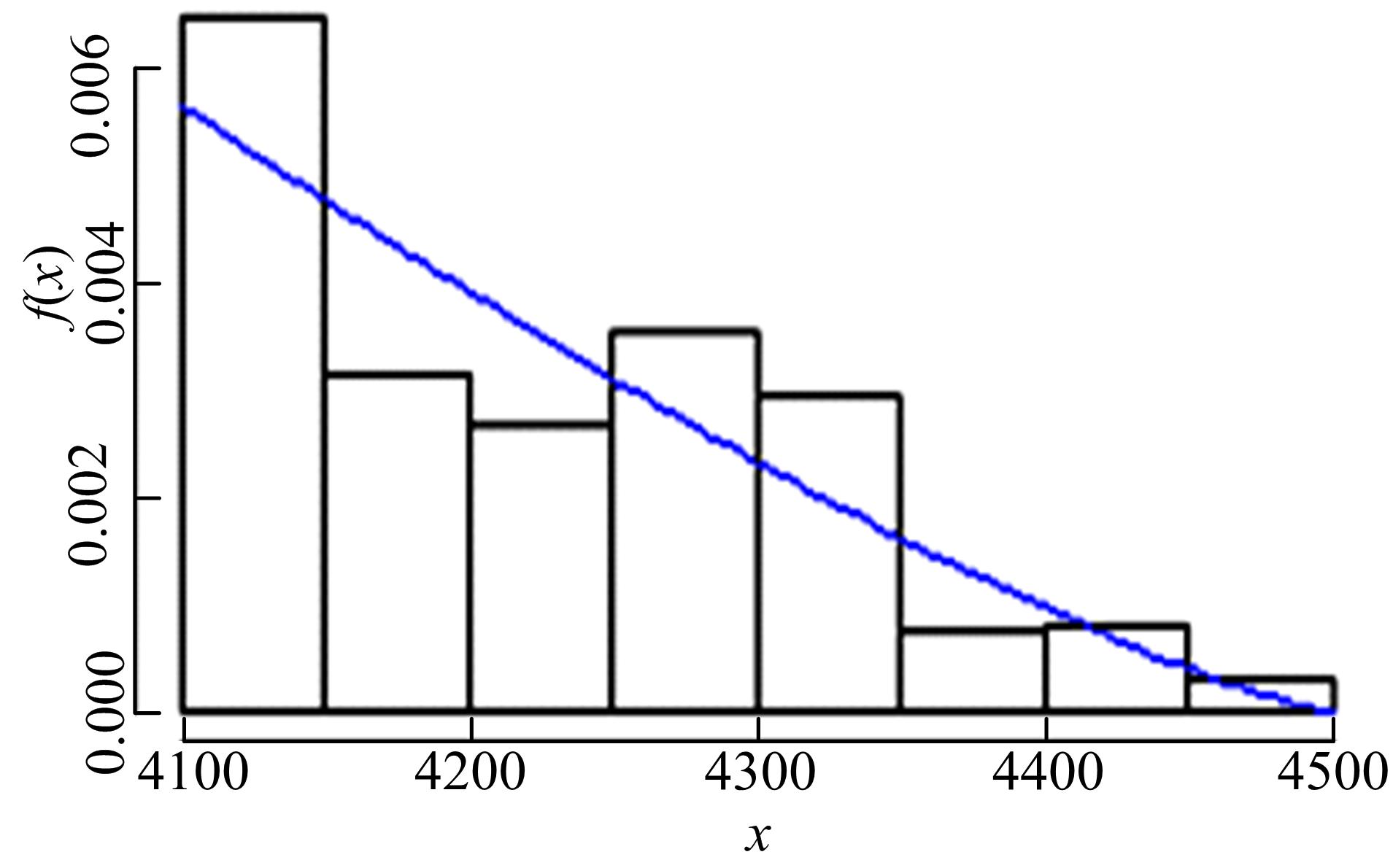 | 图4 超阈值样本概率密度函数Fig.4 Probability density function of over-threshold sample |
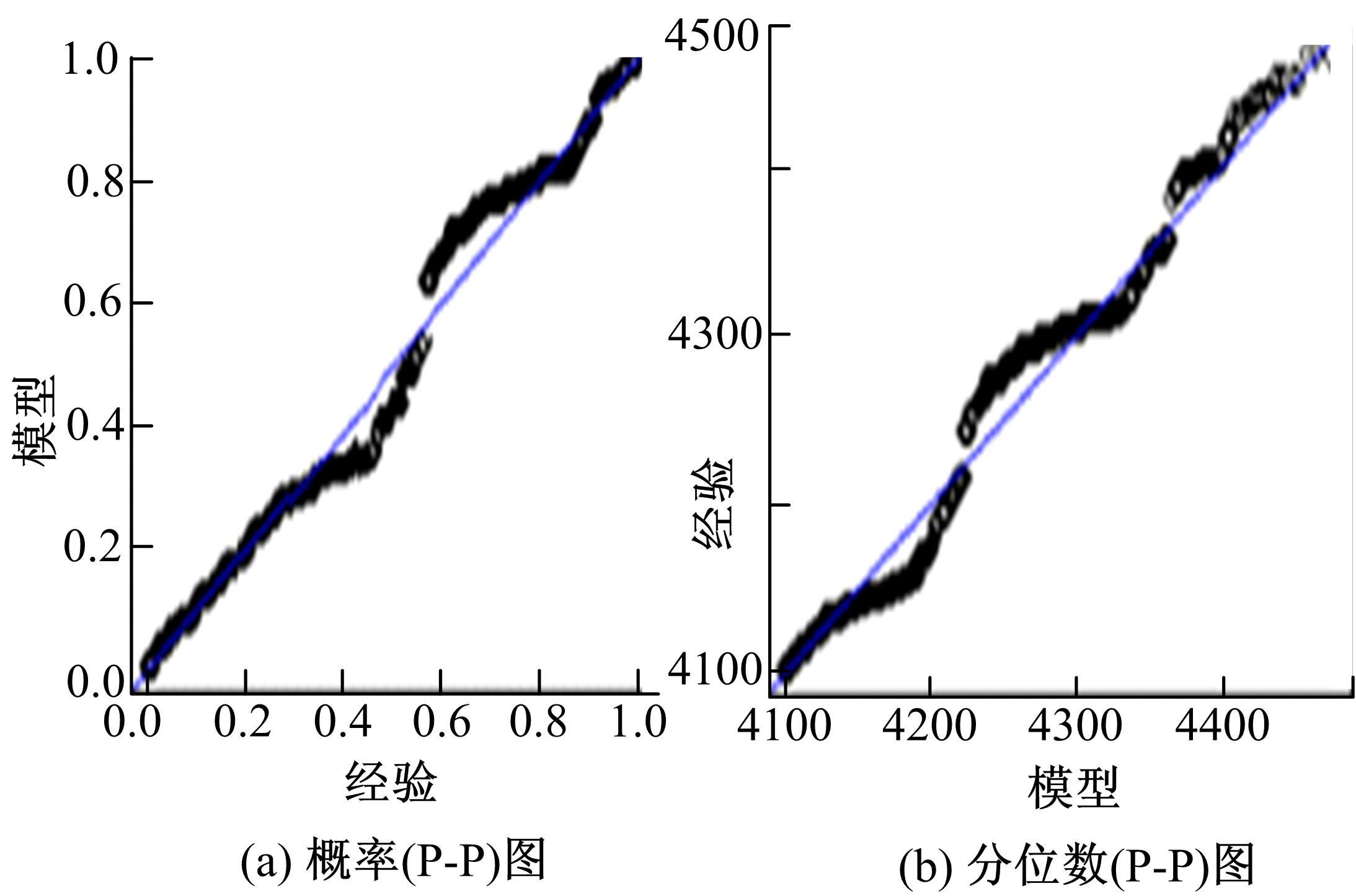 | 图5 GPD拟合诊断图Fig.5 Diagnostic diagram of GPD |
采用核密度函数法估计低于阈值的15 552个样本数据分布,从而得到总体样本概率密度函数
相应地,总体样本的累积概率分布函数
式中:
将总体样本的累积概率曲线外推106倍得到相应的累积频次分布,采用8个块载荷按一定顺序排列组成一个块载荷程序,由100个重复的块载荷程序组成代表全寿命周期载荷历程的高速列车齿轮传动装置载荷谱。表1给出了一个块载荷程序中的块载荷水平及相应的循环次数,累积频次分布及相应的块载荷分布如图6所示。基于高速列车齿轮传动装置载荷历程分布特点确定高-低-高载荷排列顺序,制定的载荷谱见图7,至此完成了高速列车齿轮传动装置载荷谱编制算例。
| 表1 块载荷程序统计 Table 1 Statistics of block load |
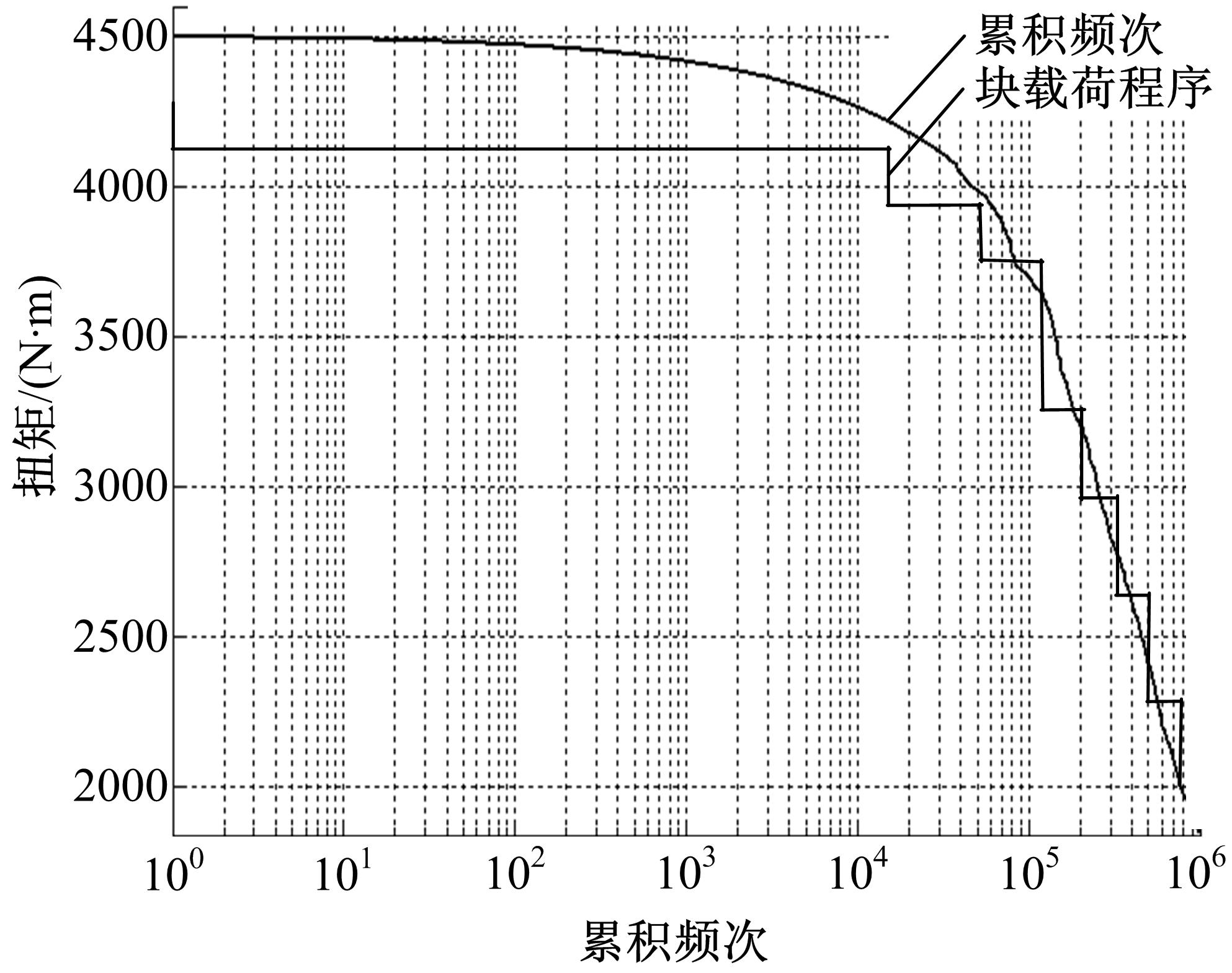 | 图6 累积频次及块载荷分布图Fig.6 Cumulative frequency and block load distribution |
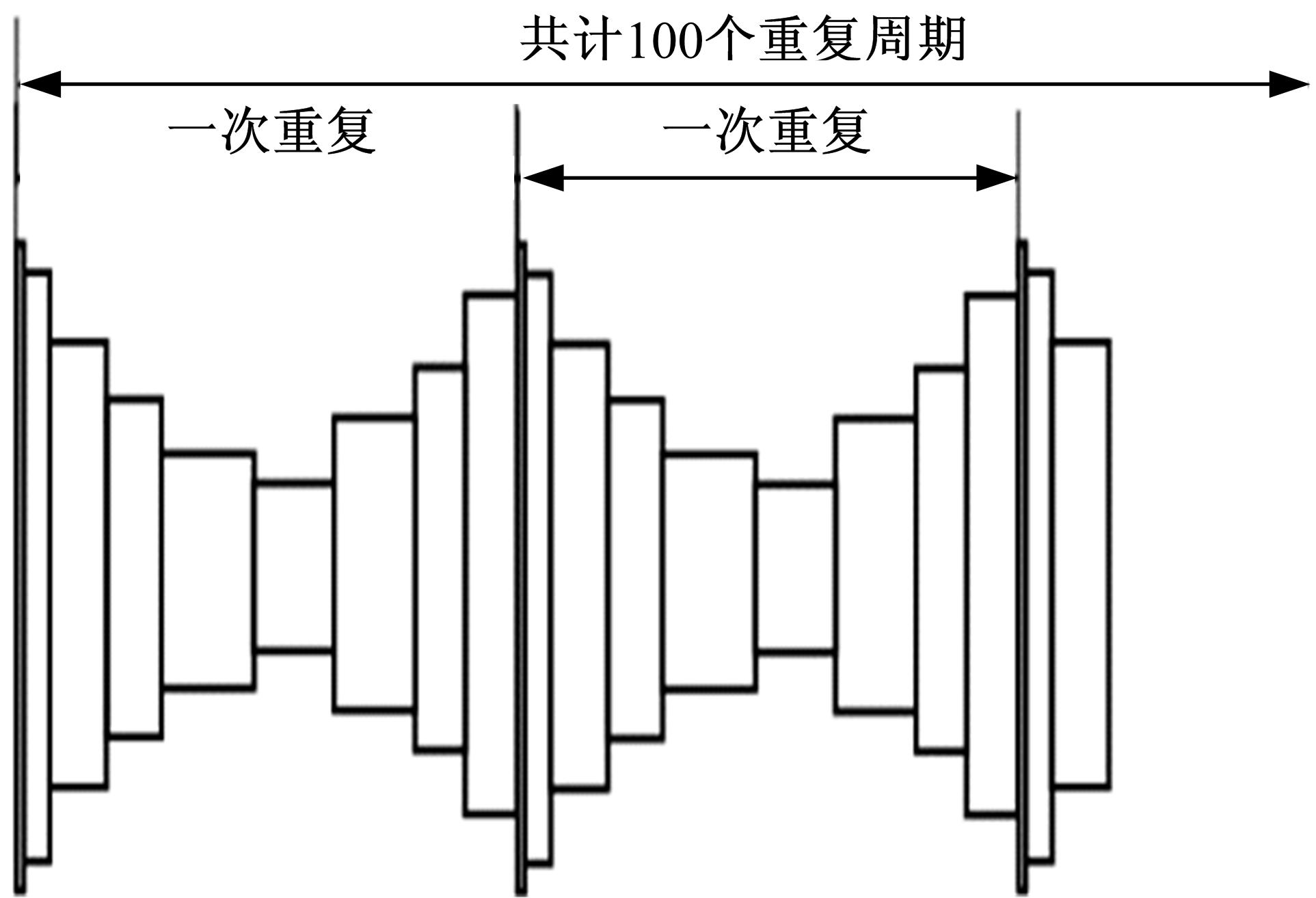 | 图7 高速列车齿轮传动装置载荷谱Fig.7 Load spetrum of high-speed train gear drive |
通过数据处理和统计分析,截除了对部件损伤影响较小的载荷样本,载荷极大值由4467 N·m外推至4502.4 N·m,实现载荷极大值外推,同时验证了超阈值样本服从ParetoⅢ型分布,样本具有确定的极大值,符合实际车辆扭矩载荷状况。最后,根据实际车辆起动-加速-平稳运动-制动减速时齿轮传动装置扭矩载荷特点编制了高-低-高顺序的8级程序块载荷谱。该载荷谱能够较好地反映全寿命历程的高速列车齿轮传动装置载荷分布规律。然而由于采用基于车辆网端功率获得的传动系载荷历程与实际各电机输出扭矩尚存在一定区别,且试验样本较少,该载荷谱尚不能直接用于试验和设计。
针对高速列车齿轮传动装置载荷谱编制问题的特殊性,提出了具体的实施方案:①分析了高速列车齿轮传动装置扭矩测量的特点,构建了一种基于电机有功功率的高速列车齿轮传动装置扭矩间接测量方案。②提出了一种基于极值理论与非参数密度估计相结合的载荷数据统计方法,获得了总体载荷样本概率密度分布函数,实现了载荷外推,避免了测量周期载荷不包括全寿命周期中较少发生的极值载荷的问题。③根据总体载荷样本概率密度分布编制高速列车齿轮传动装置程序载荷谱,并基于实测车辆网端功率时间历程完成了一个高速列车齿轮传动装置载荷谱编制算例。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|