{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于遗传算法优化的BP神经网络的材料疲劳寿命预测
[闫楚良 , 郝云霄, 刘克格]
, 郝云霄, 刘克格]
, 郝云霄, 刘克格]
|
|


作者简介:闫楚良(1947-),男,研究员,博士生导师.研究方向:飞机结构寿命与可靠性.E-mail:yancl@sina.cn
针对传统的材料疲劳寿命计算方法(概率统计法)误差较大的问题,在对材料疲劳寿命数据进行分类的基础上,采用基于遗传算法优化的BP神经网络方法,建立了应力集中系数、应力均值、应力幅值和材料的中值寿命之间的关系模型,针对具有有限寿命的数据进行寿命预测。实例验证结果表明,利用本文方法获得的预测结果与试验数据的相对误差均在5%以下,优于传统算法的预测精度,可以作为获取材料疲劳寿命数据的一种更为有效的手段。
The error of traditional fatigue life algorithms of materials is big. To overcome this problem, a model of the relationship among stress concentration factor (
材料的P-S-N曲线是结构件进行寿命分析和疲劳可靠性设计的重要依据[ 1, 2, 3, 4, 5]。获得P-S-N曲线的常规方法主要是基于传统的概率统计方法,近年来一些学者对此方法进行了相关的研究和改进,如建立广义S-N曲面[ 6]、采用加权最小二乘法估计[ 7]、使用Monte Carlo方法修正[ 8]等。随着模拟仿真技术的发展,人工神经网络等技术被引入这方面研究中[ 9, 10, 11],其中BP神经网络是目前应用最为广泛的一种误差逆传播神经网络[ 12],可以为材料疲劳寿命估计提供一种新的方法。但该网络的初始权值和阈值是随机获取的,容易导致网络训练陷入局部最优以及延长收敛时间,通常采用遗传算法(GA)对其进行优化[ 13, 14, 15, 16]。
本文采用BP神经网络方法预测材料的疲劳寿命,并引入遗传算法对其进行优化,建立预测模型;利用一个算例对此模型进行训练和检验。通过比较网络的训练效果,选择适当的网络参数,并将预测值与使用传统方法得到的计算值进行对比来验证此模型预测材料疲劳寿命的优势。
由于构件在各种工况下受到随机循环载荷的作用,所以构件的疲劳寿命实际上是由循环应力幅值 Sa和循环应力均值 Sm共同控制的。循环最大应力 Smax与疲劳寿命 N的关系可用三参数 S-N曲线方程表示为:
式中:三参数 S0、 m、 C与材料、集合形状和应力比有关。其中 S0为“理论疲劳极限”,即当 N→ ¥时的应力。
在给定应力均值
将式(2)代入式(1)得:
引入等寿命曲线方程,本文采用对于塑性材料较为适用的Gerber方程:
式中: σb为抗拉强度; σ-1为对称循环疲劳强度。
将式(3)和 Sm =
将式(5)代入式(4),可得Gerber型广义 S-N曲面方程为:
式中: σb、
对于航空领域常用材料LC4高强度铝合金板材,根据疲劳寿命试验数据[ 17],求得其在不同应力集中系数 Kt和给定应力均值
| 表1 LC4高强度铝合金板材的部分寿命试验值与计算值比较 Table 1 Comparison between the patial experimental data and computed data of fatigue life about LC4 |
通常将材料的寿命分为长、中、短三个寿命区,中、长寿命区的分界线一般为107次,若寿命超过107次,可视为无限寿命,反之则视为有限寿命。无限寿命可不进行数值预测,有限寿命利用神经网络进行预测。设计两种BP神经网络模型分别实现分类和数值预测的功能。构件的寿命与多种因素有关,其中材料本身的性质、应力集中系数以及应力水平是主要影响因素,因此以应力集中系数 kt、应力均值 Sm、应力幅值 Sa作为输入变量来描述材料的中值寿命 N50。
BP神经网络是一种单向传播的多层前向网络,包括输入层、隐含层和输出层,采用的算法是误差反向传播算法,即BP算法[ 9]。该算法依次计算隐含层输出 Hj=g(
式中: j=1,2,…, l,其中 l为隐含层节点数; k=1,2,…, m,其中 m为输出层节点数; n为输入层节点数; g为隐含层和输出层神经元之间的传递函数; wij和 aj分别为隐含层的权值和阈值; wjk和 bk分别为输出层的权值和阈值; η为网络学习速率。
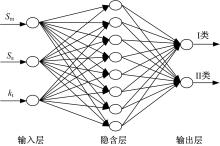
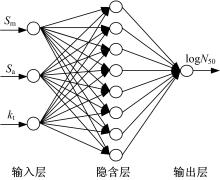
选取模型的输入层均为 kt、 Sm、 Sa三个单元,分类网络输出层为有限寿命所属的Ⅰ类和无限寿命所属的Ⅱ类两个节点单元;预测网络的输出层为log N50一个节点单元;隐含层节点数 l根据公式 l=
 | 图1 分类功能的BP神经网络结构图Fig.1 BP neural network with classification |
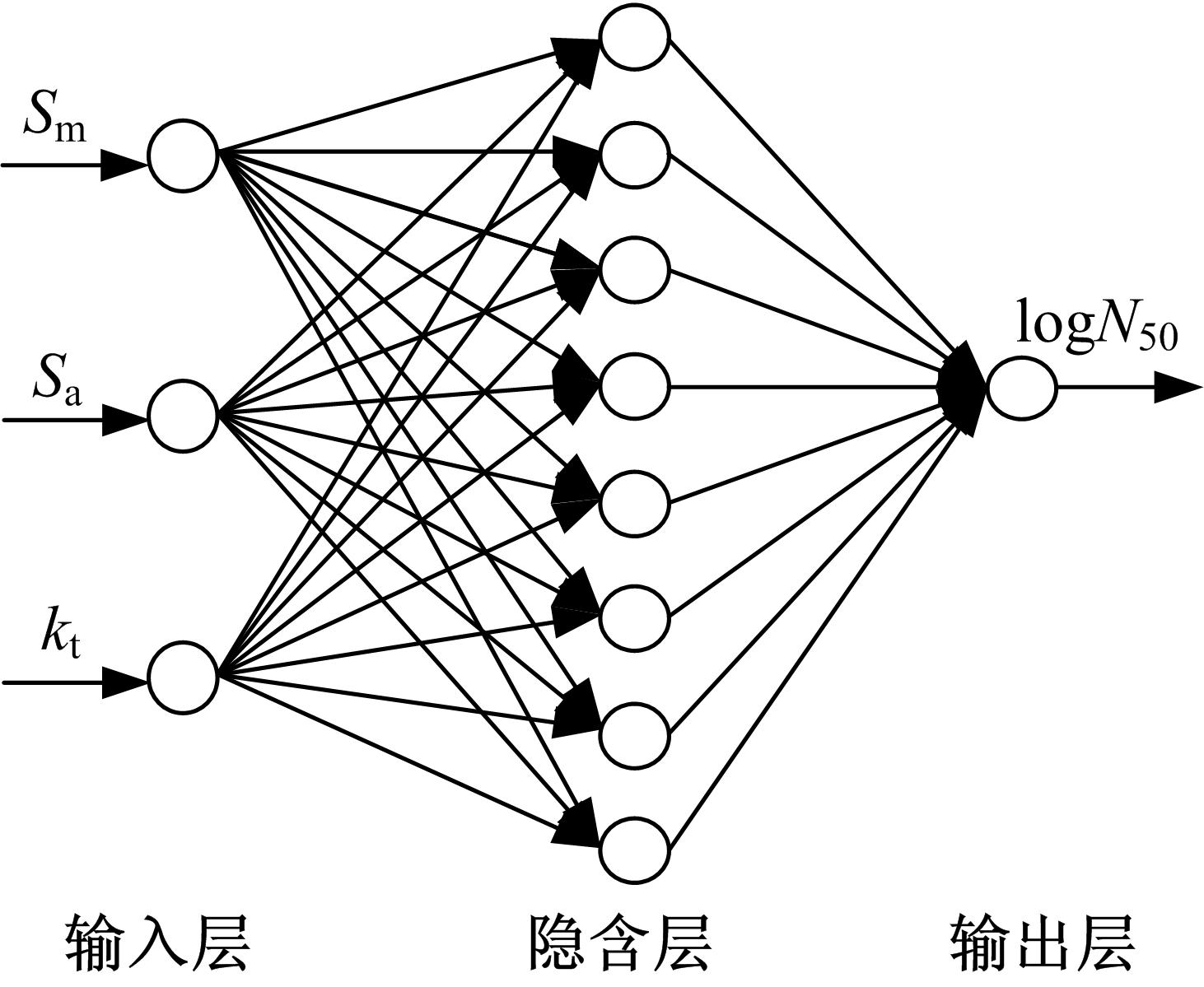 | 图2 预测功能的BP神经网络结构图Fig.2 BP neural network with prediction |
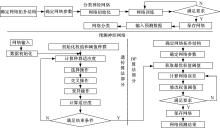
GA算法的基本思想是用个体代表网络的初始权值和阈值,用个体值初始化的BP神经网络交叉、变异操作寻找最优个体,即最优的BP神经网络权值和阈值。本文通过在MATLAB软件中编程实现GA算法,主要包括以下步骤:
(1)使用浮点数编码方式实现种群初始化。个体编码长度为网络所有权值个数( n×m+l×m)和阈值个数( l+m)之和。
(2)把BP网络的预测输出值和真实值之间的误差平方和作为个体适应度,计算表达式为: F=c
(3)选择操作采用最优保存策略,每一代群体中的最优个体直接进入下一代,余下个体采用轮盘赌法选择,每个个体被选择到下一代参加遗传操作的概率为 pi=fi/
(4)交叉操作采用实数交叉法,第 k个染色体 ak和第 l个染色体 al在 j位的交叉操作方法如下:
式中: b是[0,1]间的随机数。
(5)变异操作方法如下:
式中: amax为 aij的上界; amin为 aij的下界; f( g) =r2
整个算法流程如 图3所示。
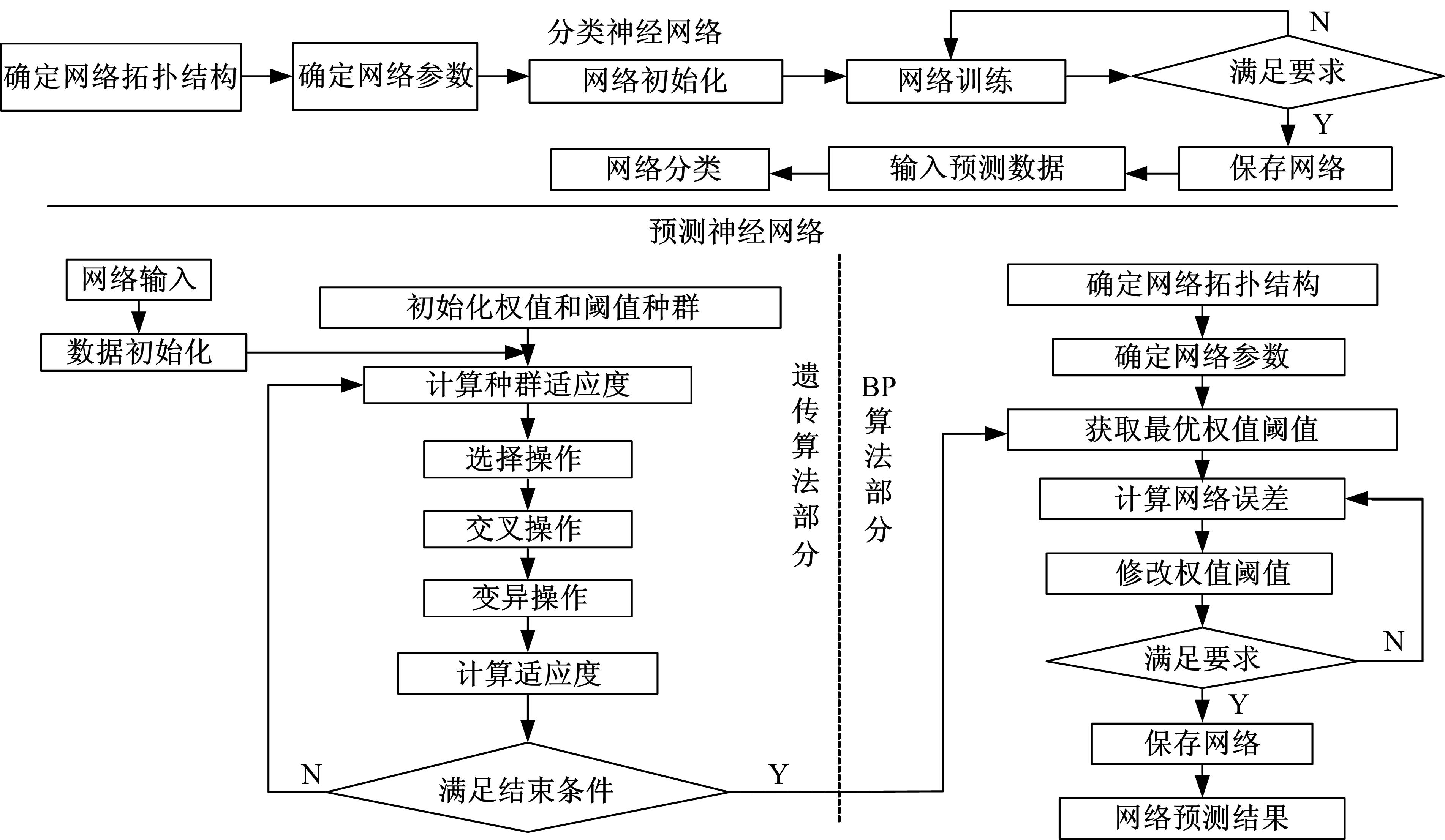 | 图3 算法流程图Fig.3 Flow diagram of BP neural network with genetic algorithm |
选用LC4高强度铝合金板材的疲劳寿命试验数据作为神经网络的样本[ 17]。样本共有78对数据,其中66对属于Ⅰ类(有限寿命),12对属于Ⅱ类(无限寿命)。进行分类时,Ⅱ类的样本较少,会导致神经网络的泛化性降低,因此利用插值法将Ⅱ类数据扩展为36对。从中随机抽取Ⅰ类数据中的34对、Ⅱ类数据中的24对作为训练样本,余下数据作为测试样本。
由于 kt、 Sm、 Sa和 N50的数值分布范围较广且较分散,为保证网络在训练过程中收敛,避免因为输入输出数据数量级差别较大而造成网络预测误差较大。在训练之前,首先对其进行归一化处理,使输入和输出变量的值处于[-1,1]之间。训练结束后,再将数据进行反归一化,还原成实际值。数据归一化方法采用最大最小法。函数形式如下:
式中: xmin为数据序列中的最小值; xmax为数据序列中的最大值。
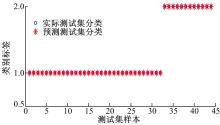
分类结果如 图4所示,从图中可以看出,分类结果完全正确。
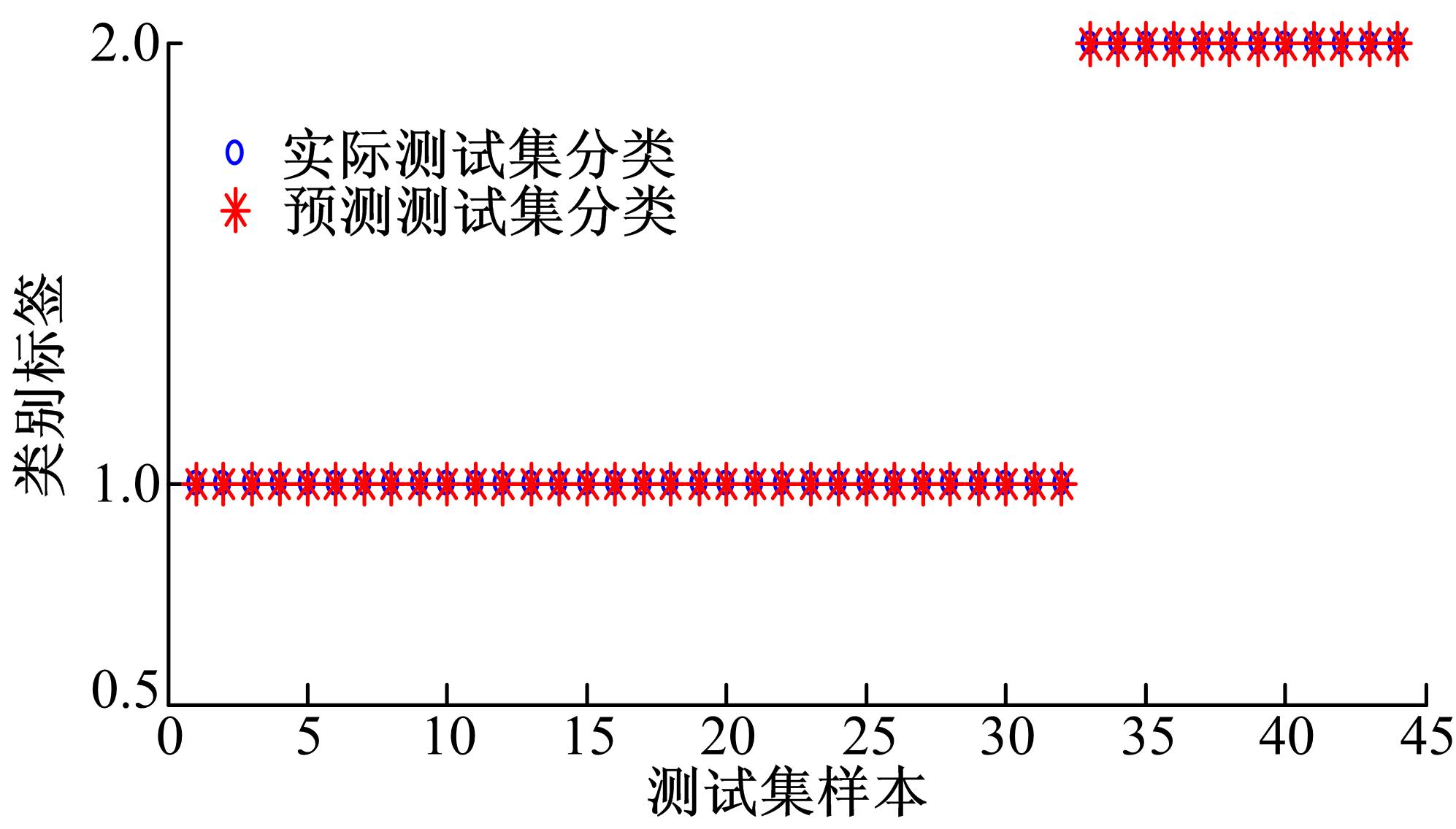 | 图4 测试样本的实际分类和预测分类比较Fig.4 Predicted classification and true classification about test data |
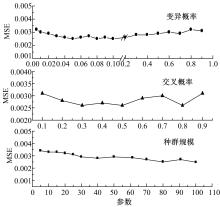
从Ⅰ类的66对样本中随机抽取61对数据作为训练样本,5对数据作为检测样本。遗传算法部分影响网络性能的参数为种群规模、交叉概率和变异概率,根据相关研究[ 13, 14, 15],这三者的经验取值范围分别为20~160、0.25~1.0、0.005~0.1,随着参数取值的变化,网络性能的变化与所研究的具体对象有关。本文使用预测值与实际值的均方误差和(MSE)作为衡量网络性能最常用的参考指标,MSE越小,表示网络预测性能越好。结合寿命预测实例,研究了在上述取值范围内,遗传算法进化次数为100时,三个参数对网络训练性能的影响,其结果如 图5所示。
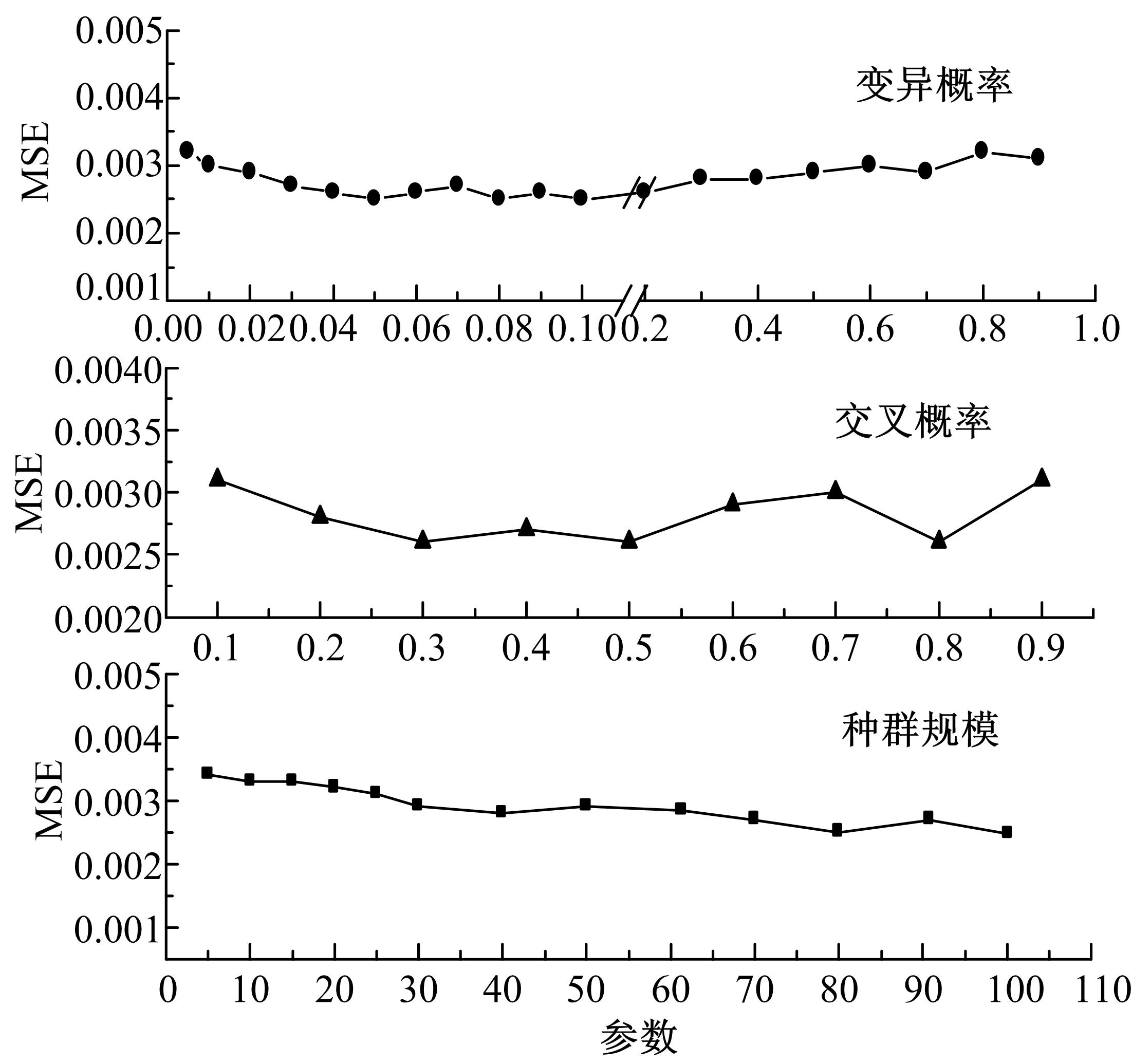 | 图5 遗传算法参数对网络性能的影响Fig.5 Influence of parameter in genetic algorithm to network property |
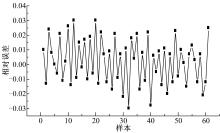
由 图5可知,随着种群规模的增大,MSE逐渐缓慢减小。种群规模越小,遗传算法的运算速度越高,但是种群的多样性降低,容易引起遗传算法早熟,出现假收敛,但种群规模较大时,又会使运算效率降低。随着交叉概率的增大,MSE逐渐减小,在0.3~0.5范围内,MSE趋于平缓,而后又逐渐增大。这是由于交叉概率越大,群体中产生的新模式越多,但已形成的优良模式也越容易遭到破坏,使搜索的随机性太大;而太小则会使发现优良新个体的速度太慢,导致搜索阻滞。变异概率的变化对MSE的影响与交叉概率相似,取值太大使遗传算法在整个搜索空间内跳跃幅度增大,成为随机搜索;太小则使其在特别区域进行局部搜索,引起遗传算法早熟,对于本文的模型,取值为0.05~0.1时MSE较小且变化平稳。当上述三个参数取值分别为85、0.45、0.06时,训练样本预测值与真实值的相对误差如 图6所示。
从 图6中可以看出,预测值和真实值的相对误差均在5%以内,训练效果较为理想。
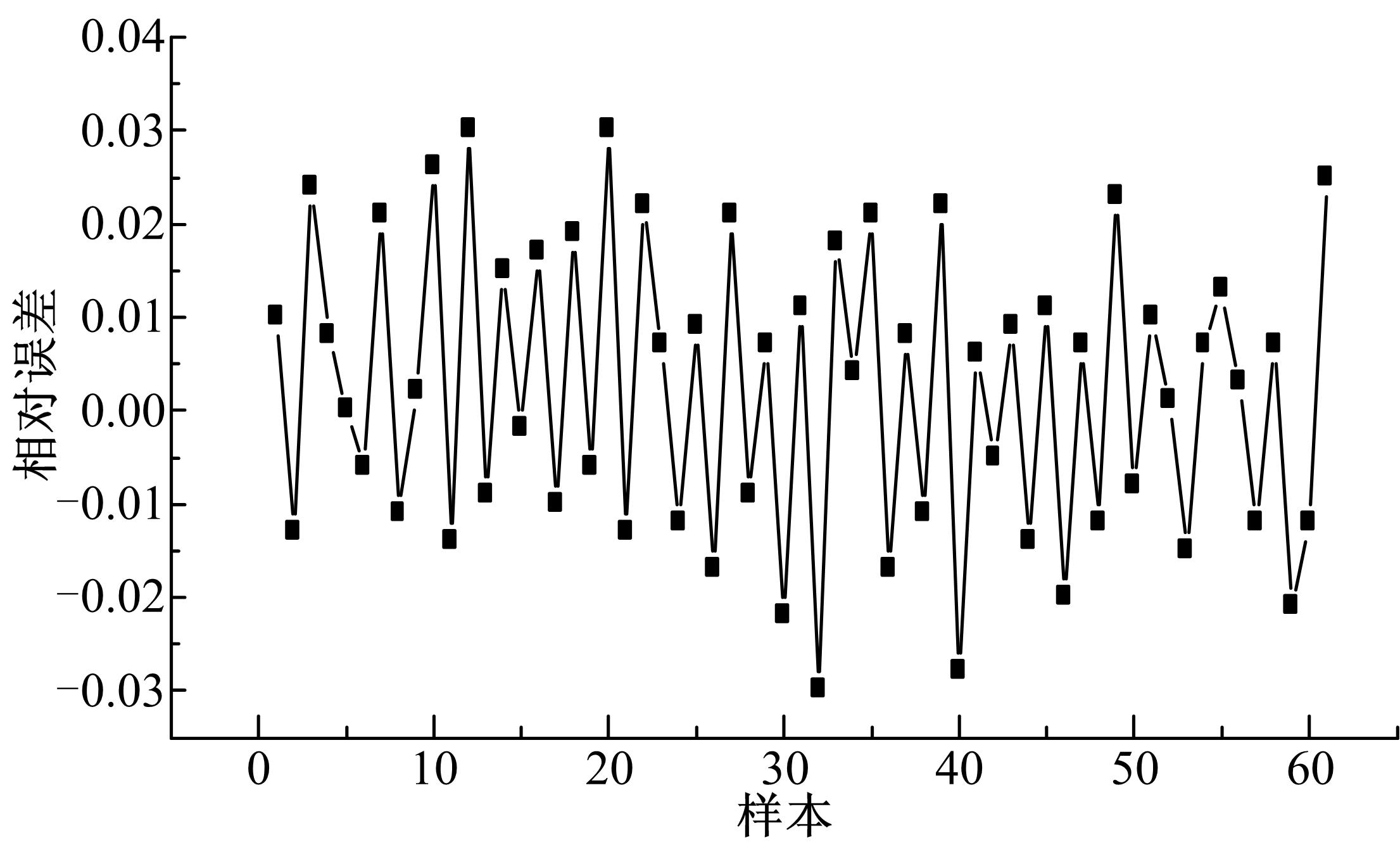 | 图6 训练样本预测值与真实值的相对误差Fig.6 Relative error between the prediction and true value of training data |
利用测试样本对训练好的网络进行验证。预测值、利用传统方法得到的计算值以及它们与试验结果的误差均列于 表2中。比较预测值和计算值的相对误差可以看出,5个样本预测值的相对误差绝对值均在5%以内;第1、3、5个样本计算值的相对误差绝对值在5%以内,而第2个和第4个样本的计算值却超过10%,偏离较大;除第1个样本预测值的相对误差略大于计算值外,其他几个样本的相对误差都小于计算值。从整体数据对比可以看出,预测值要优于计算值,预测效果比较理想。
| 表2 神经网络预测结果 Table 2 Prediction of neutral network |
针对传统的材料疲劳寿命计算方法与实际值之间误差较大的问题,建立了基于遗传算法优化的BP神经网络的寿命预测模型。实例预测结果表明:
(1)利用该模型预测的材料疲劳寿命与真实值的相对误差绝对值均在5%以内,预测精度较高,满足使用要求。
(2)与利用广义S-N曲面方程的传统计算方法相比,预测误差相对较小,整体上更为接近真实值,可以作为获取材料的疲劳寿命数据的一种更为有效的手段。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|