
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于GPS轨迹的规律路径挖掘算法
[何雯1, 2  , 李德毅
, 李德毅1, 2 , 安利峰1 , 张天雷1 , 郭沐1 , 陈桂生2 ]
, 李德毅, 安利峰|
|


作者简介:何雯(1982-),女,博士研究生.研究方向:智能交通,空时数据挖掘.E-mail:he-w09@mails.tsinghua.edu.cn
基于用户的历史轨迹数据,对用户的规律路径进行挖掘和提取。在轨迹预处理和聚类的基础上,定义了支撑路径的概念,提出了一种基于支撑得分的规律轨迹挖掘算法。并通过规律停止率特征,提高了对轨迹交通模式识别的准确率。基于178名用户4年的GPS轨迹记录,以及37名用户的实际轨迹数据,开展了用户试验。结果表明,本文算法能够有效地提取用户的规律路径,并对路径中的干扰具有一定的鲁棒性。
Based on users' historical trajectory data, users' regular routes were mined and extracted. A concept of support route was defined after route pre-processing and grouping. A regular route mining algorithm was proposed based on the support score. A feature of Regular Stop Rate (RSR) was used to improve the accuracy of the transportation mode recognition. The effectiveness of the approach was validated based on the GPS data of 178 users over four years. A real user study was also performed among 37 users. The experiment results demonstrate that the algorithm can effectively extract the regular routes and is robust to slight disturbance in trajectory data.
用户行为是开展用户推荐和个性化用户服务的基础。用户轨迹是用户行为的重要组成部分,不仅包含用户的出行信息,还包含用户的出行习惯、生活经验等。近年来,随着GPS智能终端的普及,越来越多的人开始习惯于记录并分享轨迹日志。基于这些日志,可以分析并挖掘出用户的一些行为特征,从而为用户提供个性化的基于位置的智能服务,有效地提升和改善用户的应用体验。
规律路径是用户行为中频繁且最具预测性的行为,对理解和预测用户行为具有重要意义。规律轨迹在气象、生态等领域也有着广泛的应用[ 1, 2, 3]。
近年来,很多学者对用户的GPS轨迹进行了分析和挖掘。例如,对用户个人路径的挖掘和预测[ 4, 5],以及对用户行为目的的推测[ 6, 7]。Gidofalvi等[ 8]基于车辆的GPS数据,挖掘了可共享的最长路径。郭黎敏等[ 9]针对轨迹中的不确定性问题,在路网框架下提出了一种路径补全和预测的方法。Lee等[ 10]提出了一种分割和聚类的方法用于发现轨迹中密度较高的公共子轨迹。Zheng等基于用户的历史轨迹,分析并挖掘了轨迹中的潜在知识,包括交通模式[ 11],感兴趣区域及旅行序列[ 12],以及更高效的出行路径[ 13]等。
本文以用户的历史轨迹数据为基础,对用户的日常规律路径进行挖掘和提取,并识别用户在轨迹中所采用的交通模式。最后基于178名用户4年的轨迹记录,对算法进行了性能测试。并邀请37名用户对算法进行了实测,证明了本文算法的有效性。
受GPS精度以及信号干扰等因素的影响,原始的GPS数据中,通常包含一些异常点。这些异常点的存在会影响后续轨迹处理的精度和准确性。
给定一个GPS轨迹序列 T{ p1, p2,…, pk},每个点 p( lat, lngt, t)是一个GPS记录点,其中 lat、 lngt和 t分别表示记录的纬度、经度和时间。依据常识,序列 T中相邻点的移动距离应小于最大行进距离。为了加快检测效率,适当放宽检测标准为:
式中: d( pi, pj)为点 pi和 pj间的欧氏距离,该距离小于两点间的路网距离; Vmax为用户的最大移动速度,本文设置 Vmax为160 km/h。
当用户在某一区域驻留超过一段时间,则该区域可能是用户的一个停留区域。当在一个连续的GPS轨迹中,发现了一个停留区域,据此,将轨迹拆分为两段:通往和离开该区域的轨迹,并同时从GPS轨迹中删除停留区域的数据点。
本文采用文献[8]的方法对停留区域进行检测。一个停留区域 S{ pm, pm+1,…, pn}⊂ T满足:
式中: δ为停留区域的距离阈值; τ为停留区域的时间阈值。
去除停留区域后,轨迹 T成为{ p1,…, pm-1, pn+1,…, pk},点 pm-1与 pn+1间存在一个至少为 τ的时间间隙(以下简称间隙)。
当GPS轨迹中存在下列两种情形之一时,将其拆分为两条路径:①轨迹中存在停留区域;②相邻GPS点的时隙大于一定阈值。第1种情形已在1.2节中进行了介绍。而第2种情形,则可能是用户关闭了GPS设备,或GPS设备在一段时间内未接收到卫星信号等原因造成的。
由于从GPS轨迹中去除停留区域时留下了一个较大的时隙。因而,可以统一检测GPS点间的时隙,当大于某一时间阈值时,就进行路径分割。
定义1 一条路径是一个GPS序列,记为: R{ p1, p2,…, pn},满足 pi+1 .t-pi.t<ε,其中,1≤ i<n-1, ε为时间阈值。 R.s和 R.e为路径的开始和结束时间。
网格映射是GPS轨迹预处理中常用的数据压缩和序列化方法。本文将GPS点映射入预先划分好的坐标网格中。当连续的GPS点映射入同一网格时,压缩记录为一个时序格。
定义2 一个时序格定义为 G( gi, ta, tl),其中, gi为网格的标识号; ta和 tl分别为用户进入和离开 gi的时刻。
这样,一条路径 R{ p1, p2,…, pn}就可以表示为一条时序格链表 R{ G1→,…,→ Gn}。
经过数据准备,用户的轨迹日志被形式化为一系列的时序格链表。本节将从时序格链表中挖掘出用户的规律出行路径,并识别每条路径的交通模式。为了定义规律路径,首先给出有向边的定义。
定义3 有向边是坐标网格间的有向链表,记为 Em, n,表示用户从 gm移动至 gn。所有包含 Em, n的路径保存至 Em, n.visit={ Ri,…, Rj}。 Em, n.f=|Em, n.visit|,其中 |· |表示集合中的元素个数。每条路径经过 Em, n时的速度定义为:
式中: D( Gm, Gn)表示网格 gm与 gn间的路网距离。
定义4 规律路径是指某一用户经常在同一近似时间所经过的一条完整路线。一条规律路径由一组有向边构成,记为 RR{ Ei, n,…, Em, n}。
用户每天会产生大量的路径,要从一段历史时期的所有路径中,提取出规律路径,运算量是很大的。但由于规律路径发生在每天的近似时刻,因而,可以先依据时间对路径进行聚类。
当路径 R与滑动时间窗( t-ω, t+ω)有交集时,则将该路径记入时段 t的路径集,表示为: Γ={ Rm,…, Rn}, Ri∈ Γ满足:
式中: t为时间窗的中心时刻; ω为控制窗宽和步进的时间阈值。
由于用户在周末及工作日通常会有不同的生活习惯,所以本文按照时刻和路径发生的日期分别对路径进行聚类。
用户的规律路径是指用户经常访问的完整路线。用户每次经过同一路线,均会产生一条路径记录,称为该路线的支撑路径。故支撑路径是对一条路线的一次访问实例。如果一条路线要成为规律路径,必有多条支撑路径。故规律路径上的每一路段都会被多条支撑路径所访问。简而言之:
If Em, n为组成规律路径 RRj的一部分,
Then RRj的大部分支撑路径会经过 Em, n;
If 路径 Ri为 RRj的支撑路径,
Then Ri的大多数有向边会被 RRj的支撑路径频繁访问。
基于此思路,本文提出了一个基于支撑得分的规律路径提取算法,基于每组 Γ提取规律路径。
(1)计算频繁有向边
为了找到规律路径,首先要找出支撑路径。而支撑路径的特征是:它会频繁访问大部分有向边。所以可以先找出被频繁访问的有向边。
定义5 在一组路径中,当 Em, n的访问频率( Em, n.f)大于给定阈值 α,则被称为频繁有向边(Frequent directed edge,FDE)。
算法1给出了计算频繁有向边的伪代码。
算法1: CalFDE
Input:一组路径tR,频率阈值α
Output:一组FDE
1 FDE=Φ. Eset=Φ
2 Foreach Ri in tR do
3 Foreach Em,.n in Ri do
4 Eset.Add(Em,n)
5 Em,n.f++
6 Em,n.visit.Add(Ri) //添加访问路径
7 Foreach Em,n in Eset do
8 If Em.n.f ≥ α
9 FDE.Add(Em.n)
10 Return FDE
(2)提取支撑路径
现在可以用FDE来提取可能的支撑路径,但会提取出一些错误的支撑路径,它们的大部分有向边被路径频繁访问,但不是支撑路径,后续的步骤将对此进行修正。
定义频率得分 fs来衡量路径中FDE的比例:
式中: n、 m分别为 Ri中有向边和FDE的数量。
频率得分可以反映出一条路径被访问的情况。频率得分越高,说明路径中越多的部分被用户频繁访问。
如果一条路径 Ri的频率得分 fs( Ri)≥ β,则路径 Ri就可能是某规律路径的一条支撑路径。阈值 β同时具有调节算法抗干扰的能力。若设置 β=1,则要求所有的支撑路径完全相同;若降低 β的取值,则每条支撑路径间可以存在一定的不同。
一条规律路径的所有支撑路径集记为: RR.sup={ Ri,…, Rj}。算法2给出了提取支撑路径的伪代码。
算法2: FindSupR
Input: 一组路径tR,一组FDE,频率得分阈值β
Output: 一组支撑路径SR
1 SR=Φ
2 Foreach Ri in tR do
3 nf=0,n=0
4 Foreach Ej in Ri do
5 n++
6 If Ej in FDE
7 nf++
8 Ri.fs=nf/n //频率得分
9 If Ri.fs≥β
10 SR.Add(Ri)
11 Return SR
(3)提取支撑有向边
有了支撑路径,就可以统计出被支撑路径频繁访问的支撑有向边(Support directed edge,SDE)。
定义6 在一组路径中,一条有向边 Em, n被支撑路径访问的频率大于给定阈值 γ,则被称为支撑有向边。
SDE与FDE的区别是,FDE仅被路径频繁访问,而SDE被支撑路径频繁访问。定义支撑得分 E.ss来统计经过有向边 E的支撑路径数量:
如果有向边的支撑得分满足 E.ss>γ,则被认为是某规律路径的支撑有向边。所有经过 E的支撑路径集记为: Em, n.sup={ Ri,…, Rj}。则
E.ss=|Em, n.sup|。算法3给出了提取支撑有向边的伪代码。
算法3: CalSDE
Input: 支撑路径集SR,一组FDE,支撑得分阈值γ
Output: 一组SDE
1 SDE=Φ
2 Foreach Em,n in FDE do
3 Em,n.ss=0 //支撑得分
4 Foreach Rj in Em.n.visit do
5 If Rj in SR
6 Em,n.ss ++
7 If Em.n.ss ≥ γ
8 SDE.Add(Em.n)
9 Return SDE
(4)更新支撑路径
现在,需要从支撑路径集中去除错误的支撑路径。这些路径经常被FDE访问,但不是SDE。用SDE替代FDE,重复步骤(2)和(3),直到规律路径的支撑路径集( RR.sup)不再发生变化。也就是说在计算式(5)时, m表示 Ri中SDE的数量。
最终,规律路径就是所有SDE的集合。算法4给出了提取规律路径完整算法的伪代码。
算法4: RegularRouteMinining
Input: 一组路径tR
Output: 一组SDE
1 FDE=calFDE(tR)
2 SR=FindSupR(tR,FDE)
3 SDE=FDE //初始化SDE
4 do
5 SDE=CalSDE(SR,SDE)
6 SR=FindSupR(SR,SDE)
7 while no change in SR
8 return SDE
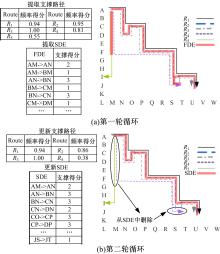
图1为从一组包含有5条路径的 tR中提取规律路径的步骤示意图。首先设置 α=2,则所有访问超过2次的有向边被选为FDE( 图1(a)中粗线表示)。计算每条路径的频率得分(见 图1(a)左上表)。设置 β=0 .8,则得到4条支撑路径, R1, R2, R3和 R4。
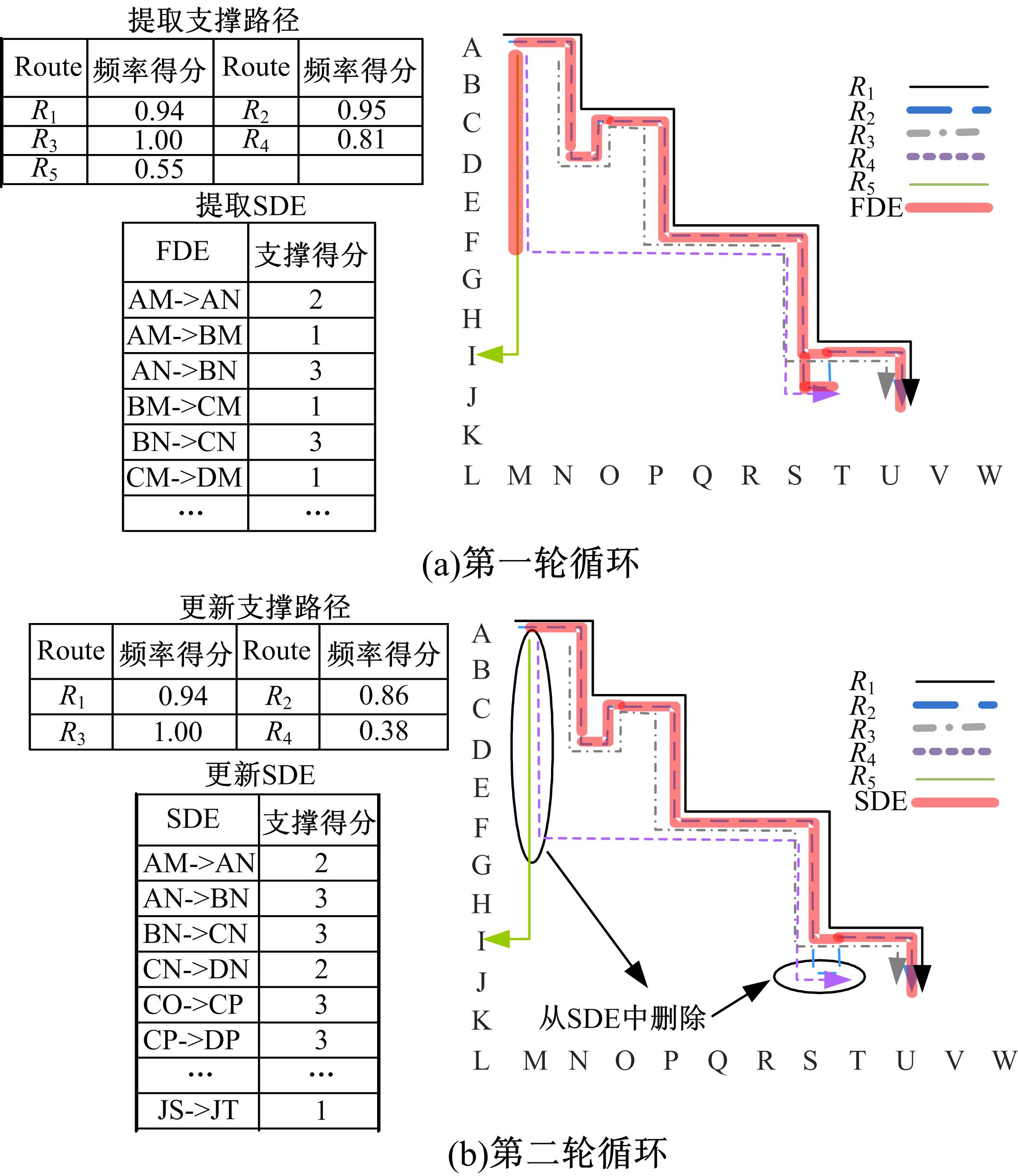 | 图1 规律路径提取示意图Fig.1 Example of regular routes mining |
基于4条支撑路径,分别计算每段FDE的支撑得分,部分结果见 图1(a)左下表。设置 γ=2,则所有支撑得分大于等于2的FDE被选为SDE。
重复上述步骤,进行第2轮循环,并用SDE代替FDE更新支撑路径集,结果见 图1(b)。该轮循环后, R4和JS→JT分别被滤出支撑路径和SDE。
继续执行第3轮循环,得到的支撑路径没有发生变化,循环结束。最终得到的所有SDE(见 图1(b)中粗线表示)就是本组 tR提取出的规律路径。
文献[ 8]给出了一种GPS轨迹交通模式的识别算法。本文在此基础上,对其中的停止率特征进行了改进。文献[8]关于停止率特征的主要思想是,公交车相对于私家车会有更多的停止。但事实上,公交车还会有更规律的停止。利用这一特征,可以更好地对交通模式加以区分。
由于在提取规律路径时,已经得到了若干条支撑路径。所以,可以统计各条支撑路径中是否存在一些用户总是低速通过的共同区域,该区域很可能就是规律停止点。如果一条规律路径上分布有较多的规律停止点,那么该路径的交通模式就可能是公共交通,反之则为私人驾驶。
定义7 停止率是指用户以较低速度通过规律路径有向边的概率,即:
式中: Vthre为判断停止的速度阈值。如果 Em, n的停止率高于给定阈值 Pstop,则认为是一个规律停止点。
定义8 规律停止率是指一条规律路径中,单位距离上规律停止点的比例,即:
式中: RRj.distance为规律路径 RRj的长度。
本文采用两套数据集分别对算法的效率以及有效性进行验证。数据集1是微软亚洲研究院发布的Geolife项目数据集[ 11, 12, 14]。该数据集记录了178名用户,自2007年至2011年间的生活轨迹。在该数据集上提取了每名用户每个月的规律路径。数据集2是来自37名用户两周的生活轨迹记录,然后由每名用户分别对提取出的规律路径以及识别的交通模式进行评分。评分内容包括:
召回率:是否检测到了全部规律路径(1~5分);
准确率:检测出的规律路径是否正确(1~5分);
交通模式正确性:判断是否正确(1~5分)。
图2是在数据集1上得到的所有规律路线。当设置 α=γ=3, β=0 .8时,共得到389条规律路径,如 图2(a)所示。设置 α=γ=8, β=0 .8时,得到31条规律路径,如 图2(b)所示(结果中滤除了短于2 km的路径)。从结果可以看出,提取出的规律路径基本覆盖城市的主要街道,并且在城市的西北角较为密集,这里正是本数据集的发布地。
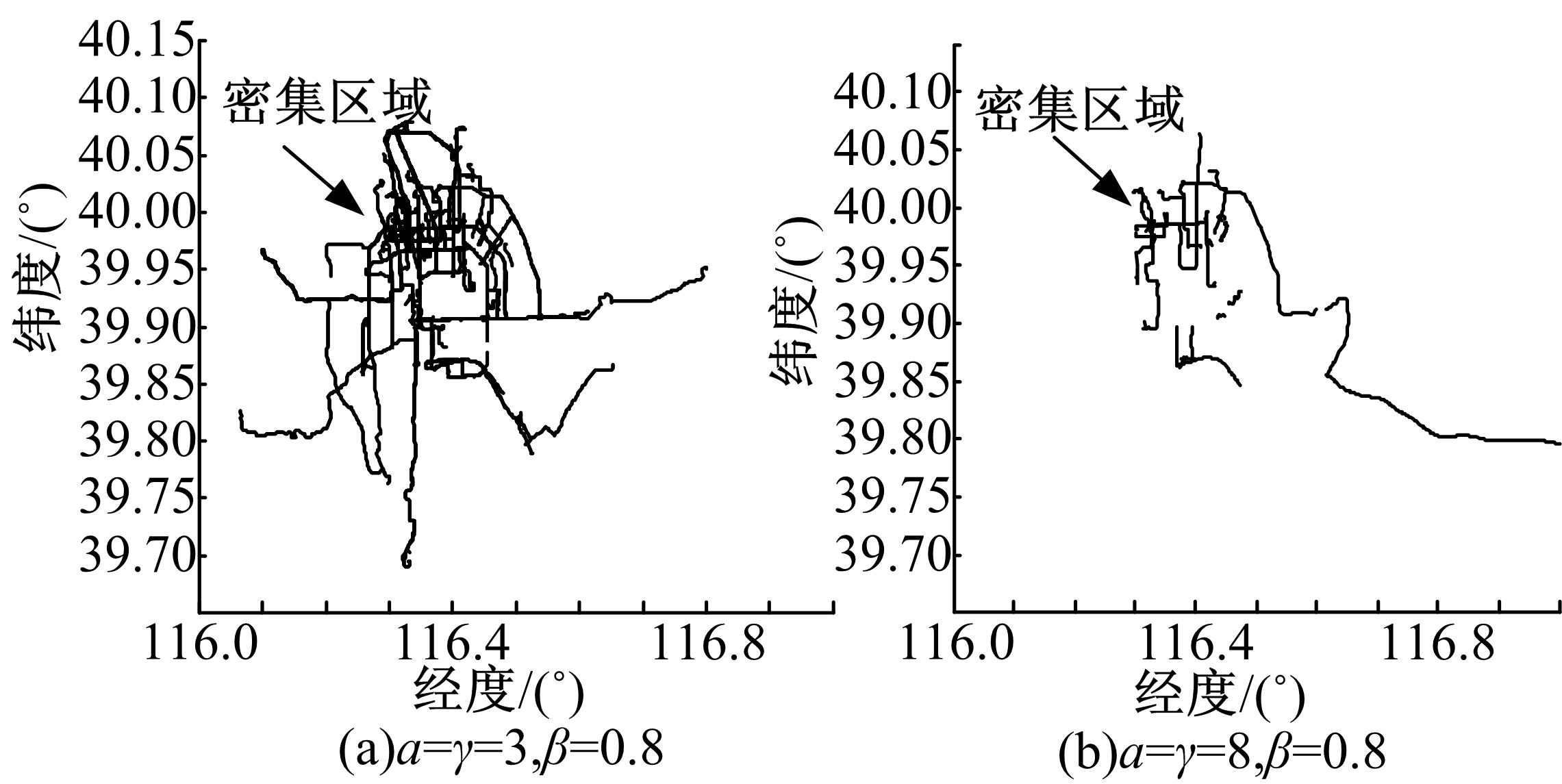 | 图2 不同阈值下提取出的规律路径Fig.2 Regular routes under the different threshold |
在数据集2上,挖掘到规律路径72条。用户对挖掘结果以及交通模式识别结果给出了评分。各项评分的平均结果如 表1所示。
| 表1 对规律路径挖掘结果的评分 Table 1 Rating result on regular routes mining |
从 表1可以看出,用户对挖掘的整体结果表示满意。分析错误案例时发现,有些用户会交替采用私家车或是公交车去上班,尽管出发地和目的地相同,但路线上存在差别,但用户觉得这仍然属于规律路径。此外,在交通模式的识别中,由于忽视了自行车出行,记录中自行车的最大时速达到了27 km/h,远高于城区道路拥堵时的驾车时速。
鉴于目前鲜有基于历史轨迹的规律路线挖掘算法,试验无法与现有方法进行比较,因此只考虑本文所提方法的性能。
表2给出了算法各步骤对存储空间的需求变化。第一行为每一步的记录数量。第二行为相对于原始数据的比例。从结果可以看出,提取出的路径相对于原始数据集而言,所需的存储空间非常小。
| 表2 算法的存储需求 Table 2 Storage cost of the algorithm |
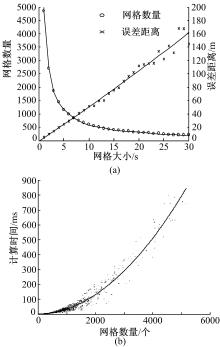
图3给出了网格尺寸对算法性能的影响分析。 图3(a)给出了随着网格尺寸的变化,轨迹映射误差和时序格数量的变化趋势。随着网格尺寸的增大,轨迹的映射误差呈线性增加,而时序格数量呈指数下降。 图3(b)给出了时序格数量对算法计算性能的影响曲线。随着时序格数量的增加,规律路径提取所需的计算时间呈明显上升趋势。因而网格尺寸的选择,需要在网格误差和网格数量上做适当的调整。从 图3中可以看出,当网格尺寸大于10''后,网格数量的减少趋势明显放缓,而误差仍在持续增加。同时网格尺寸为10''时,平均映射误差约为50 m左右,满足城市大部分道路的分辨距离。综上所述,本文选取网格大小为10''。
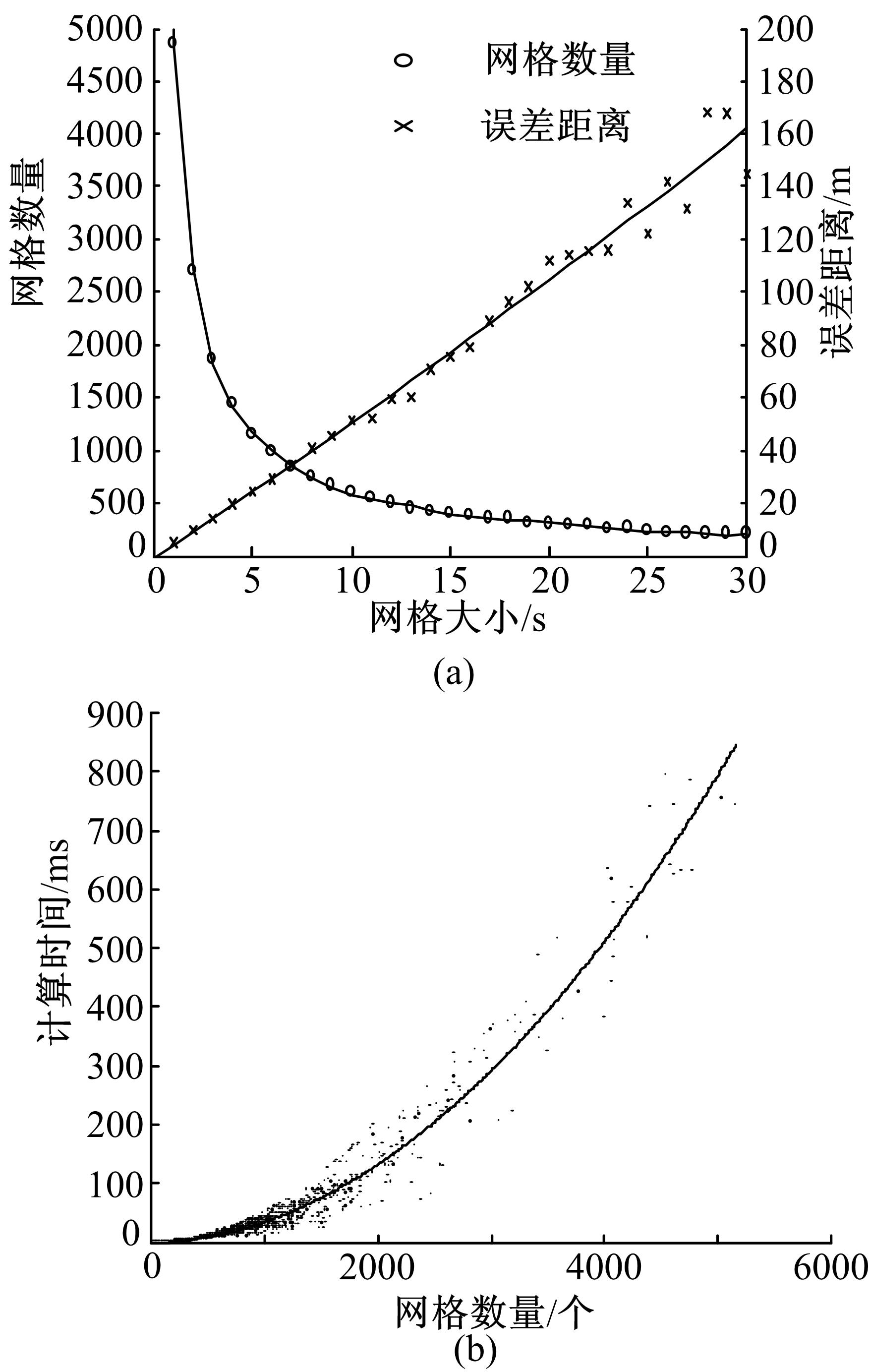 | 图3 网格尺寸对计算性能的影响Fig.3 Impact of gird size on computing performance |
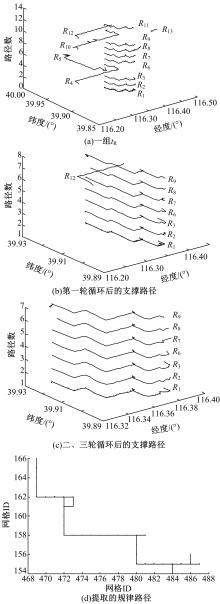
图4演示了一个实际的规律路径提取过程。 图4(a)是一组包含有13条路径的 tR。设置参数 α=γ=3, β=0.8。 图4(b)(c)分别是1~3轮循环后得到的支撑路径。第3轮循环后,支撑路径的数量不再发生变化,运行结束。 图4(d)为最终提取的规律路径。从 图4(c)可以看出:每条支撑路径在细节上都有细微的差别,显示了算法的鲁棒性。
 | 图4 规律路径提取示例Fig.4 Example of Regular route mining |
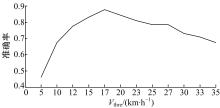
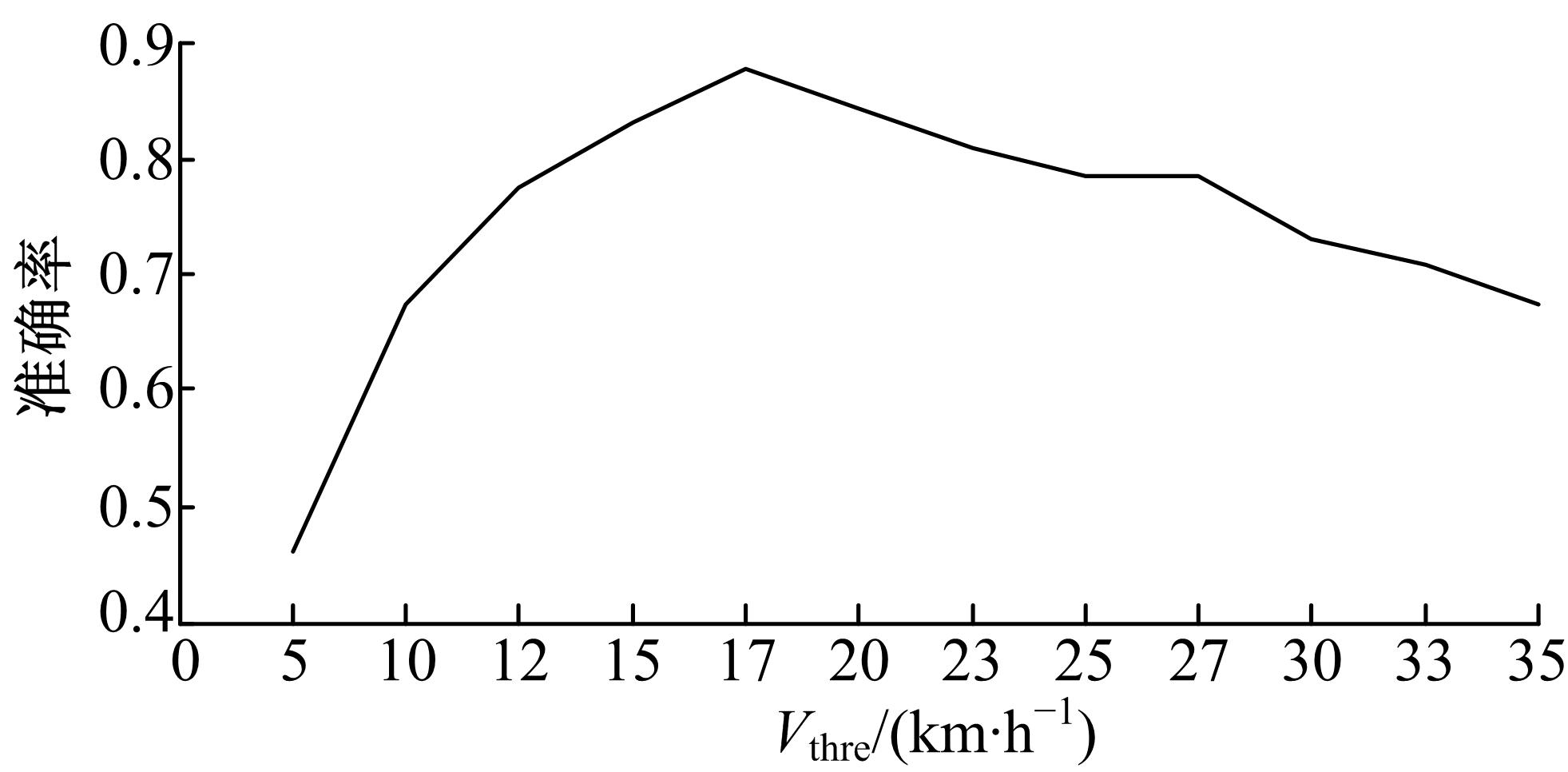 | 图5 不同停止率阈值的识别准确率Fig.5 Recognition auuracy of different threshold for stop rate |
图5给出了在不同的停止率阈值下,交通模式识别的准确率曲线。在数据集1中,有69名用户对GPS轨迹的交通模式进行了标记。规律路径89条,并对交通模式进行了识别。从结果可以看出,设置适当的低速阈值后,方法的准确率可以达到0.876,比文献[11]仅采用停止率,在该数据集上所得到的0.6的准确率有了较大提升。
基于用户的历史轨迹记录,提出了一种规律路径的提取方法,并通过规律停止率特征提高了交通模式识别的准确率。通过在两套数据集上的测试,表明了该方法的有效性和鲁棒性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|