{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于k 近邻法和脊线追踪的指纹匹配算法
[于明 , 皮海龙, 王岩, 阎刚, 郭迎春]
, 皮海龙, 王岩, 阎刚, 郭迎春]
, 皮海龙, 王岩, 阎刚, 郭迎春]
|
|


作者简介:于明(1964-),男,教授,博士.研究方向:计算机图像处理.E-mail:yuming@hebut.edu.cn
首先,综合运用
A new fingerprint matching algorithm is proposed in this study. First, the
由于指纹具有唯一性、终身不变性以及方便性,因此,指纹自动识别系统一直是生物特征识别的一个研究热点。指纹自动识别系统包括指纹预处理、特征提取、伪特征点去除和指纹匹配4个过程。而指纹匹配是最关键的一步,影响到整个指纹自动识别系统的拒识率、误识率以及匹配速度。拒识率 FRR:出自同一手指的两个指纹却不被接受。试验中挑选指纹对B组进行150次真匹配。误识率 FAR:错误地接受了两个不同手指的指纹。所谓指纹匹配,就是比对两幅指纹图片的特征信息,判断是否来自同一枚手指。
国内外学者对指纹匹配算法做了大量的研究,目前主流的指纹匹配算法可以分为基于图形的指纹匹配方式和基于人工神经网络的匹配方式[ 1]两种。基于图形的匹配方式对指纹图片质量要求较高、匹配时间较长、对低质量图片的拒识率和误识率较高。而基于神经网络的算法虽然容错性高,但有大量样本需要事先训练,不适用于对运行速度要求较高的指纹匹配系统。He等[ 2]利用了与细节点相连的脊线特征改进了基于图形的指纹匹配算法,该方法通过追踪脊线上的点,利用脊线上的点与当前细节点的方向差以及距离描述脊线特征。该方法的误识率和拒识率较低,但是匹配速度较慢。Benhammadi[ 3]利用中心特征点以及周围特征点的方向编码描述邻域特征,对指纹的图形匹配方式做出了改进。该方法运行速度较快,但是拒识率和误识率较高。
本文针对已有算法匹配速度慢、拒识率和误识率较高的缺点,将脊线特征、邻域特征与细节点特征相结合,降低了指纹匹配的拒识率和误识率。在匹配流程中做出了相应的改进,提高了匹配速度,但是匹配速度的下限仍不能低于传统的图形匹配算法。本文主要研究的是一对一的指纹验证算法。
传统的指纹拓扑结构只提取脊线特征,或只提取邻域特征。王业琳等[ 4]通过提取纹线特征,进行指纹纹线相似度的匹配。王伟希等[ 5]以中心点为圆心,提取中心点周围的方向场进行匹配,属于提取邻域特征。这两类方法的误识率和拒识率均较高,因此本文将脊线特征、邻域特征和细节点特征相结合,设计了新的拓扑结构。
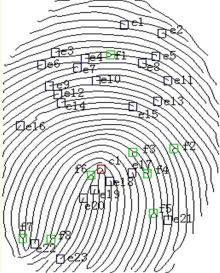
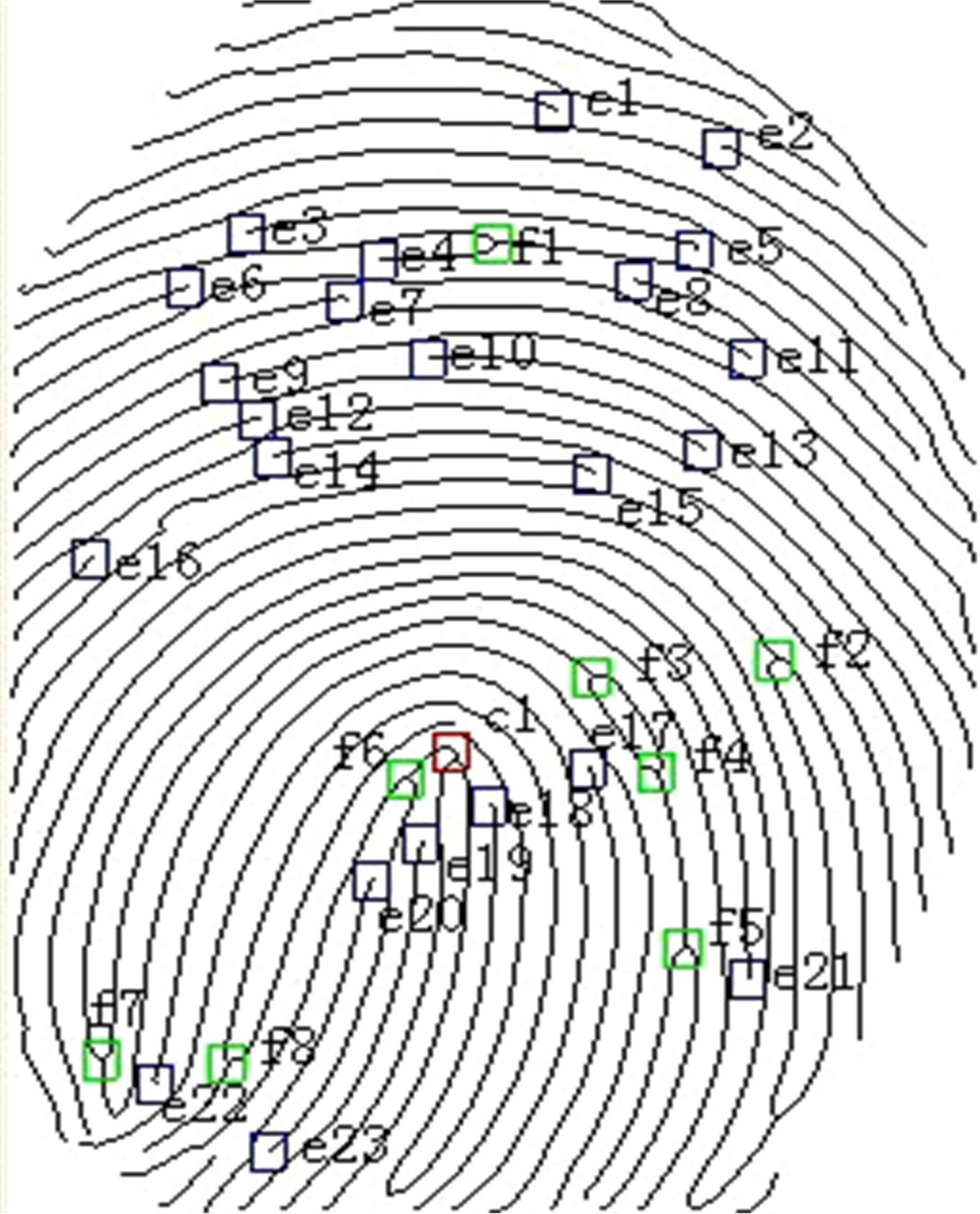 | 图1 指纹特征点标定Fig.1 Calibration of fingerprint feature points |
指纹的特征点有叉点和端点。如 图1所示,该图片标定了该指纹图像上的所有叉点,端点和中心点,叉点标号为 f1, f2,…, f8;端点标号为 e1, e2,…, e23;中心点标号为 c1。(绿方格代表叉点;蓝方格代表端点;红方格代表中心点)
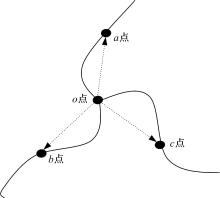
叉点相比于端点而言,信息量大且可靠,不易受非线性形变的影响,因此,首先对叉点 o的3个分支进行脊线跟踪,如 图2所示,沿3个分支各追踪 N个像素找到3个脊线点 a、 b、 c。记录脊线点和叉点的方向角度差 α、 β、 γ,提取相应叉点与3个脊线点的长度 oa、 ob、 oc,存入特征向量。叉点的坐标记作( x, y),特征点的类型中, E代表端点, F代表叉点,所得到的叉点的特征向量为{( x, y), F,( α, oa),( β, ob),( γ, oc)}。
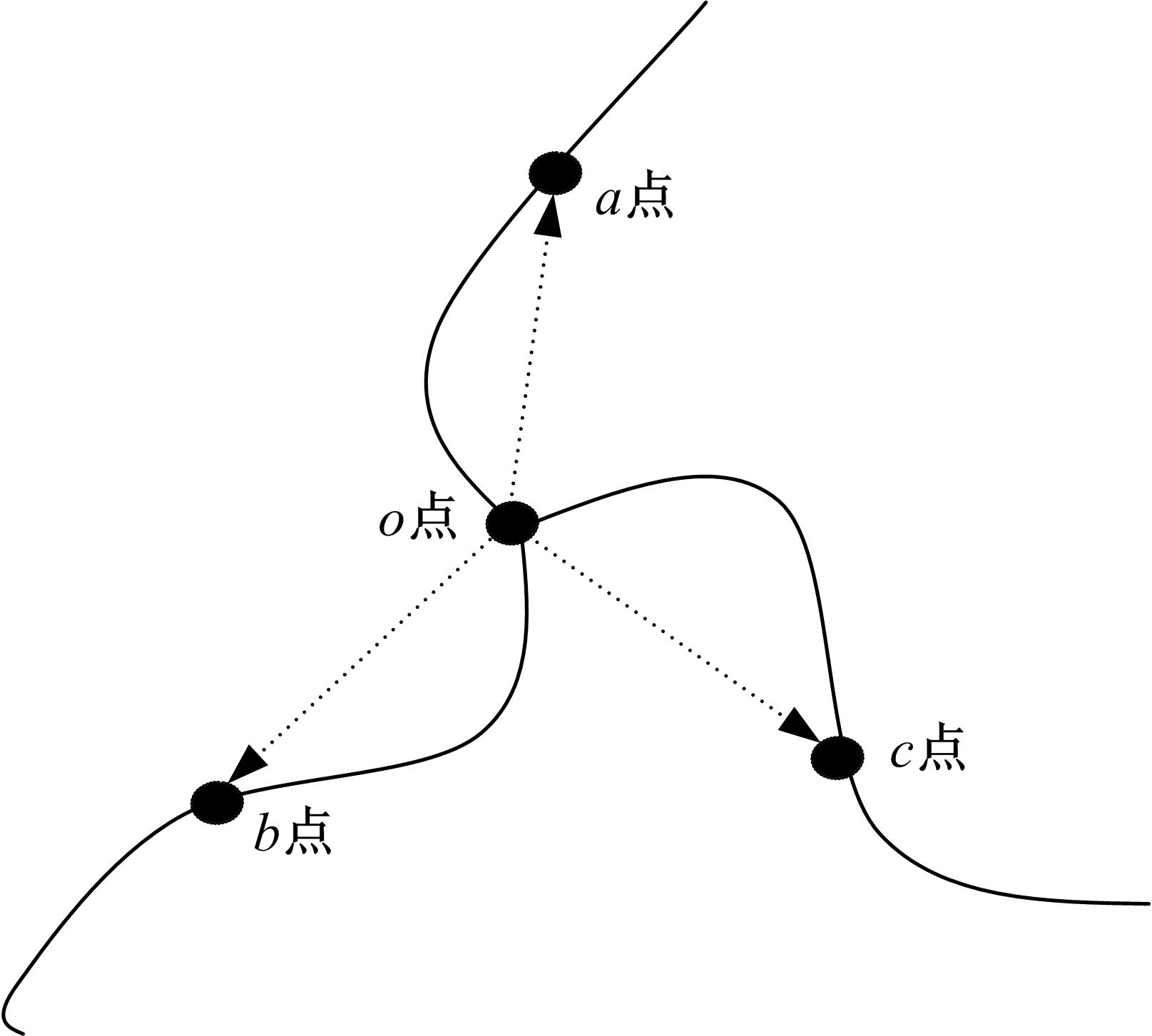 | 图2 叉点拓扑结构Fig.2 Topology of fork point |
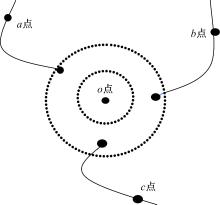
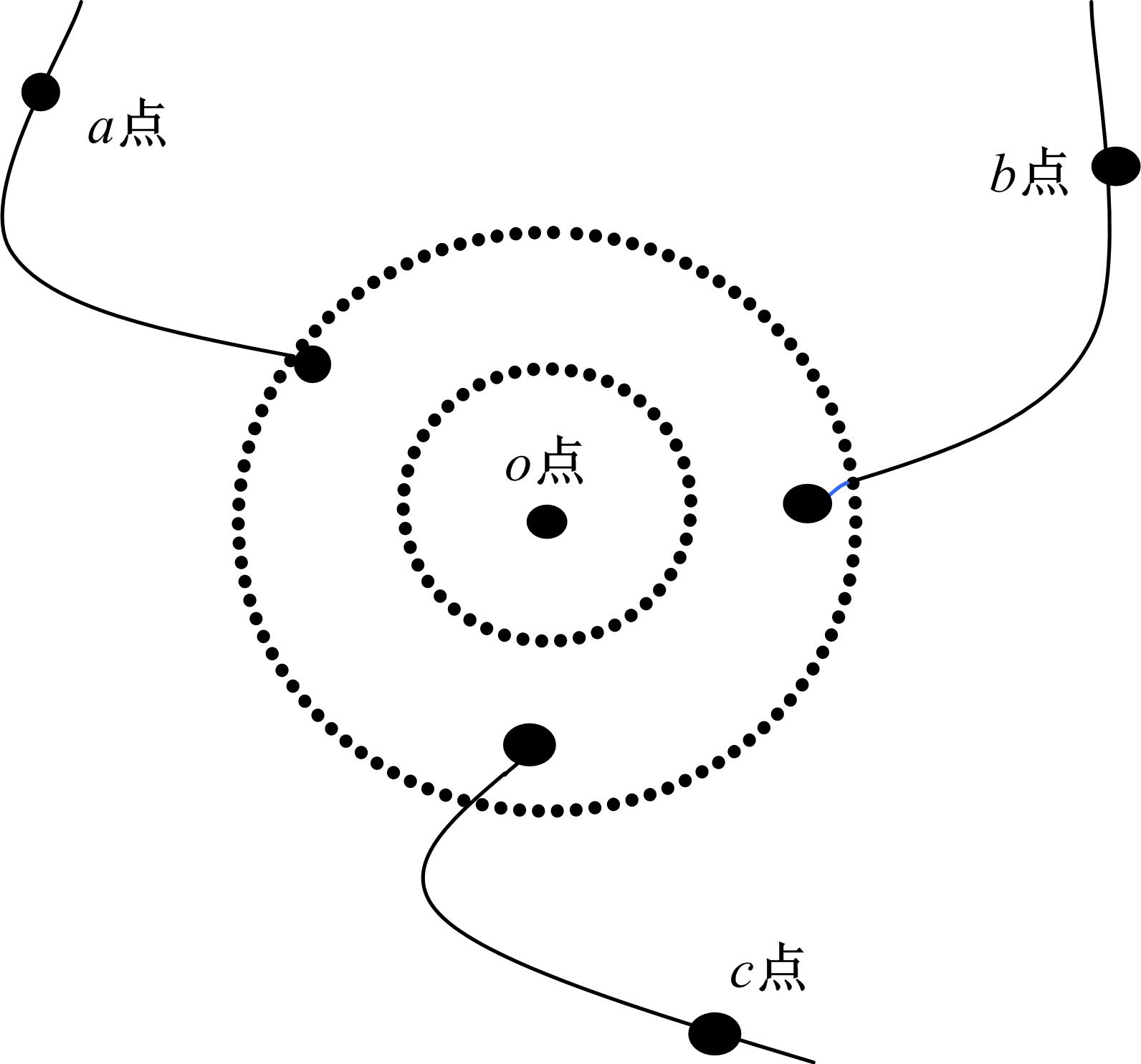 | 图3 端点拓扑结构Fig.3 Topology of end point |
端点由于只在一条脊线上,邻域特征和脊线特征均较少,因此 k近邻法作为脊线追踪法的补充,可以进一步提取邻域特征和脊线特征。如 图3所示,首先对叉点 o利用 k近邻法找到距离较近且在环形域内的3个脊线点作为邻域特征点,然后再对脊线点所在脊线进行 N个像素的脊线追踪,找到最终的脊线点 a、 b、 c。环形域的半径依次为 R1和 R2。将相应的脊线点与端点的方向角度差 α、 β、 γ以及长度 oa、 ob、 oc存入特征向量。端点的坐标记作( x, y),特征点的类型中, E代表端点, F代表叉点,所得到的端点的特征向量为{( x, y), E,( α, oa),( β, ob),( γ, oc)}。
在极坐标下进行特征点匹配比直角坐标更有优势,因为极坐标可以更好地描述非线性形变对指纹的影响,而且不用考虑输入指纹图片与模板指纹图片之间特征点的平移,只需要考虑它们的旋转即可,因此本文采用极坐标进行指纹匹配。
转换过程:首先选取中心点,或三角点,或第一个满足阈值的特征点作为对应的参考点( xo, yo),以此点建立坐标系,实现{( x, y), α}到{ ρ, θ, r}的转换,转换公式如下:
式中:( x, y)为坐标; α为角度; ρ为极径; θ为极角; r为角度差。
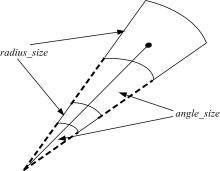
由于指纹特征点对不可能完全重合,在方向和位置上通常会存在偏差,因此引入限界盒[ 5],如 图4所示,从而有效地解决了非线性形变问题,实现了一定限度的误差容忍度。
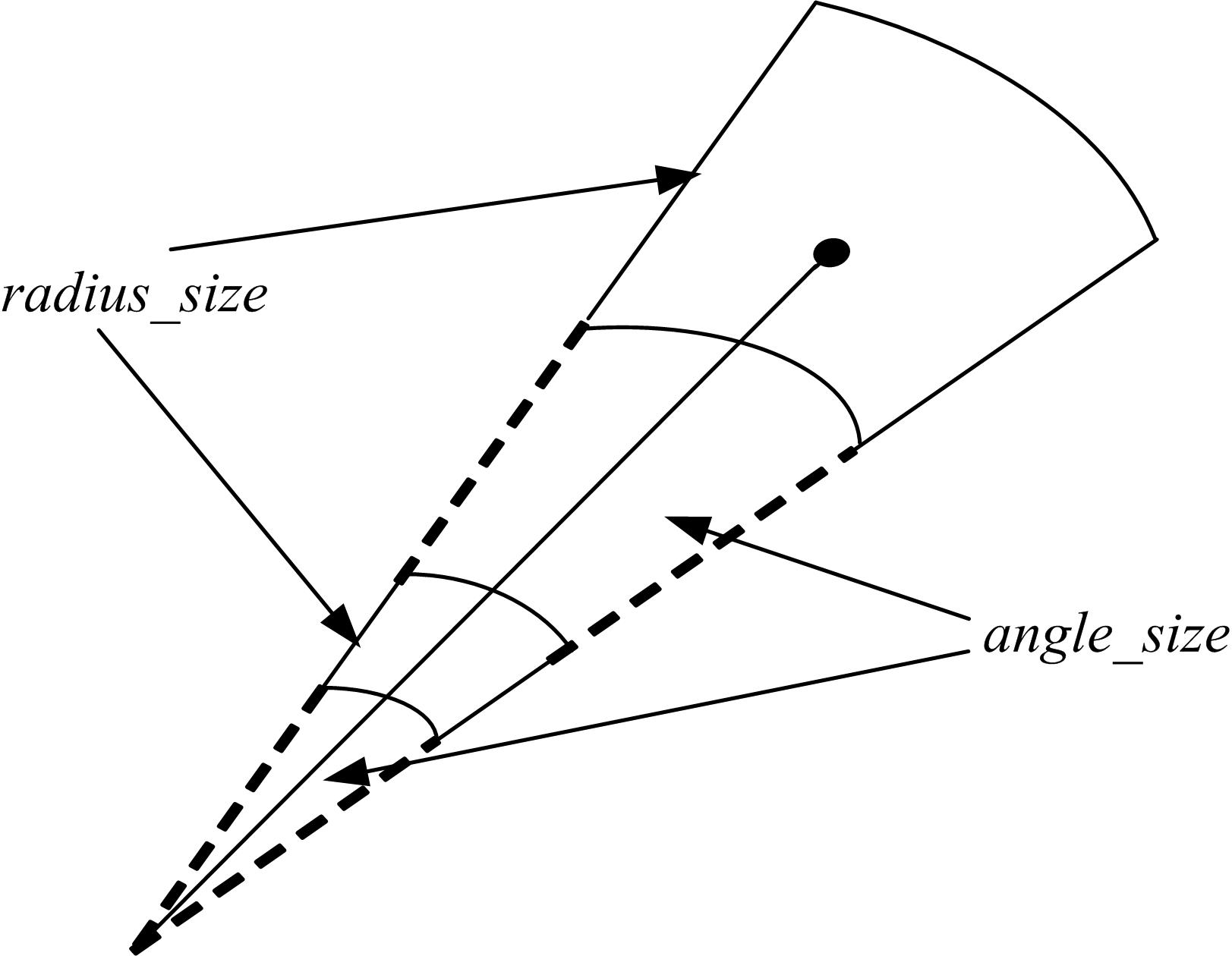 | 图4 限界盒Fig.4 Bounding box |
传统的固定限界盒极径和极角均是不可变化的,虽然时间效率高,但是拒识率和误识率也较高,而全可变限界盒(即极径和极角均可变化),虽然拒识率和误识率很低,但是时间效率很差。本文借鉴二者的优缺点,将限界盒的极角设为固定值,成为半可变限界盒,相对于传统的固定限界盒和全可变限界盒,该限界盒的匹配速度较快,拒识率和误识率较低。大多数的图像增强算法是将半个圆周划分为八个方向,再进行方向角的提取[ 6],由于方向角量化过程中已经实现了一定范围的鲁棒性,允许特征点方向上有一定的误差,因此将限界盒的宽度 angle_size设为固定值,不影响匹配的拒识率和误识率[ 7]。半可变限界盒高度 radius_size的计算公式如下:
式中: r_small、 r_large分别为半可变限界盒高度的上、下限; m为先设定的常数。
本文根据特征的可靠性不同,为指纹特征分配不同的权值[ 8],以增加指纹匹配的准确性,分配结果如 表1所示。
| 表1 特征向量的权值分配体系 Table 1 Weight distribution system of feature vector |
由于在指纹图像质量下降的情况下,叉点与端点之间是会发生相互转化的,因此不同类型的特征点不一定不匹配。但是特征点类型(叉点和端点)不易受非线性形变影响,所占比例较少,因此在对类型不同的特征点对进行匹配时,匹配阈值的设定较类型相同的特征点更高。
将叉点和端点的特征向量中的各个分量与 表1中所对应的权值相乘,得到匹配分数,将加权后的匹配分数与阈值相比较,若大于或等于阈值,就表明两点匹配。大量试验结果表明:类型相同的特征点对,将其匹配阈值 NUM设为9;类型不同的特征点对,将其匹配阈值 NUM设为12,匹配效果较好。
传统的指纹匹配过程分为单次匹配和二次匹配。二次匹配分为先局部后全局二次匹配和先全局后局部二次匹配。单次匹配的方法是对每个特征点对的特征向量依次逐个扫描,匹配时间较长。传统的二次匹配[ 5, 9]改进了单次匹配的缺点,在初匹配时淘汰了低于阈值的特征点,将初次匹配分数最高的特征点作为二次匹配的基准点,并利用半可变限界盒、极坐标转换等技术进行二次匹配。但是这种二次匹配的缺点是必须在初匹配阶段对所有特征点进行扫描匹配,时间效率较差。本文在传统的先局部后全局二次匹配算法的基础上,提出了新的二次匹配流程:初次匹配不扫描所有的特征点,而是将每个特征点对应的局部匹配(初匹配)和全局匹配(二次匹配)同时进行,加速了所有特征点对的匹配过程。主要过程如下:
(1)初匹配:对特征点的特征向量进行匹配,找到达到阈值的首个特征点对,然后立即进入二次匹配。
(2)二次匹配:将此特征点对从直角坐标转化为极坐标,然后判断两者是否在同一半可变限界盒中,若在,就表明两者匹配;若不在,就表明两个特征点不匹配。然后进入步骤(3)。
(3)循环过程:对特征点数组进行循环处理,每个循环过程均包括初匹配和二次匹配两个过程,直到最后匹配的特征点数达到阈值 NUM,则匹配成功,若匹配结束,仍未达到阈值 NUM,则匹配失败。
本文采用的试验样本是FVC2002指纹库[ 10]B组中挑选的部分高质量指纹。运行环境是Intel i5-760,内存为4 G。
本试验采用拒识率、误识率以及二次匹配阶段所耗时间(包括预处理,特征提取,指纹匹配三个阶段的总耗时)的平均值作为算法评价标准。试验中挑选指纹对B组进行600次假匹配。本文一共进行了(150+600)×3=2250次指纹匹配。
本文通过试验设定最佳阈值 NUM,试验结果如 表2所示。
| 表2 匹配阈值优化的试验对比结果 Table 2 Results of matching threshold optimization experiments |
从 表2可以看出:当匹配阈值 NUM设置较大时,误识率下降,系统安全性增加,但是拒识率升高;相反,当匹配阈值 NUM设置较小时,拒识率下降,系统易用性增加,但是误识率会升高。因此本文将 NUM设置为10,此时的误识率和拒识率相对较低,且匹配速度较快。
表3为匹配试验对比结果。表中参考文献的试验数据均出自原始文献[11-12]给出的试验结果。
| 表3 匹配试验对比结果 Table 3 Results of matching experiments |
基于拒识率和误识率的分析:文献[12]的指纹匹配是基于遗传算法的,拒识率和误识率较基于图形的指纹匹配算法差。文献[11]提取矢量三角形作为拓扑结构,再利用判断细节点构成的矢量三角形是否相似的方法进行指纹匹配。从试验结果来看,均没有分别为叉点和端点设计拓扑结构、将脊线特征、邻域特征和细节点特征相结合的方法好,本文算法较上述算法在拒识率、误识率方面有了较大的改进,拒识率达到5.3%,误识率达到0.5%。
匹配所耗时间的分析:基于遗传算法的文献[8]进行一次匹配的最长耗时为0.3 s。文献[7]利用的全可变限界盒,并进行传统的先局部后全局二次匹配,此算法虽然较基于遗传算法的指纹匹配时间缩短到0.264 s/次,但是因为初匹配要扫描所有特征点,匹配时间仍较长。本文算法利用了半可变限界盒和新的匹配流程,即不在初次匹配中扫描所有特征点,提前结束匹配过程,结果显示,匹配速度较传统的二次匹配以及传统的全可变限界盒有了一定的提升,每次匹配时间平均仅需0.23 s。
在原有的指纹匹配算法基础上,提出了综合运用 k近邻法和脊线追踪法的特征提取方法,设计了新的拓扑结构,提取了邻域特征、脊线特征和细节点特征,并且改进了二次匹配过程。通过试验证明了本文算法能够有效地实现指纹匹配,不仅降低了拒识率和误识率,同时也提高了匹配速度。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|