


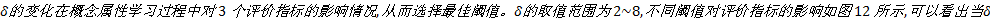
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向文本的本体学习方法
[王俊华1, 2, 3  , 左万利
, 左万利1, 2 , 彭涛1, 2 ]
, 左万利, 彭涛|
|


作者简介:王俊华(1982-),女,博士研究生.研究方向:本体工程和自然语言处理.E-mail:wangjh10@mails.jlu.edu.cn
借助文本预处理工具Gate和通用本体WordNet,采用统计、频繁项挖掘、模式匹配、启发式学习和主动学习等技术,学习本体基元——概念(含实例)、概念间的分类关系、概念间的语义关系和概念属性,其中概念属性学习为本文首次提出。实验结果表明,本文方法改善了概念语义排歧效果,丰富了短语概念学习与语义关系学习,提高了本体自动构建的准确度,降低了本体学习的代价。
The techniques of statistics, frequent item mining, pattern matching, heuristic learning and active learning are employed to learn the concepts (including instances), taxonomic relations, semantic relations and the concept properties from the documents based on preprocessing tool Gate and general ontology WordNet. The concept property learning was first proposed in this paper. Experiment results show that the proposed ontology learning method can improve the effect of word semantic disambiguation, enrich phrase concept learning and semantic relationship learning, increase the accuracy of automatic ontology construction and reduce the cost of ontology learning.
本体是共享概念模型的明确的形式化规范说明。本体 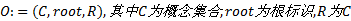
邢军等[8]以面向对象思想的分析方法为基础, 把传统的单层文本向量空间模型改进为2层向量空间模型, 并在此基础上引入模糊形式概念分析本体学习技术。Zouaq等[9]提出了OntoCmaps, 是一领域独立的和开放的本体学习工具, 它从语料库中抽取深层的语义表达。OntoCmaps以概念图的形式生成丰富的概念表示, 并提出一种基于度量的创新的过滤机制。Ruiz-Martinez等[10]提出了一种面向文本构建生物医学本体的方法。该方法通过自然语言处理和增量知识获取技术来获得相关概念和关系, 这些被包括在OWL本体中。此外, 他们用UMLS来连接本体中孤立的概念区域。Yang等[11]提出了一新的本体学习模型, 该模型提高了抽取概念的效率, 减少了构建本体的时间。该模型包括几个方面, 其中区域概念抽取是最主要的方面, 它把概念抽取与个性化推荐联合起来实现了一个更精确和稳定的领域概念抽取方法。Jiang等[12]提出了CRCTOL系统, 用于从指定的领域文档中自动地挖掘本体。CRCTOL采用一种完全的文本剖析技术及统计与lexicon-syntactic方法相结合的综合策略, 包括一个统计算法用于从文档集中抽取关键概念, 一个语义消歧算法用于消除关键概念中的单词的歧义, 一个基于规则的算法用于抽取关键概念之间的关系, 一个改进的广义关联规则挖掘算法用于修剪对本体学习不重要的关系。以上成果较早期成果有所改进, 但仍不能满足各类本体的应用需求。
本文借助文本预处理工具Gate和通用本体WordNet, 采用统计、频繁项挖掘、模式匹配、启发式学习和主动学习等技术, 学习本体基元— — 概念、概念间的分类关系、概念间的语义关系和概念属性。提出了基于主动学习的语义排歧算法, 弥补了SSI算法[13]无法处理所有术语在WordNet中都不是独义的情况的不足; 并增加了概念属性的学习。
概念可以是词, 也可以是短语, 是在特定领域表示想法、观念、范畴或类的实体集合, 是特定领域具有语义的词汇的集合。概念由术语经语义排歧后获得, 术语是领域知识的外在表现。概念学习包括术语抽取和词义消歧。
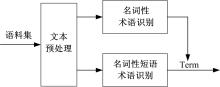
术语是代表领域知识的短语或单词, 其语言结构较固定, 一般有前后界标记、长度较短、为名词性单词或符合一定模式的短语, 停用词除外。术语亦具有较明显的统计特性, 一般为高频词。综合术语的如上特征, 本文结合语言学采用统计和模式匹配技术学习术语, 术语抽取如图1所示。
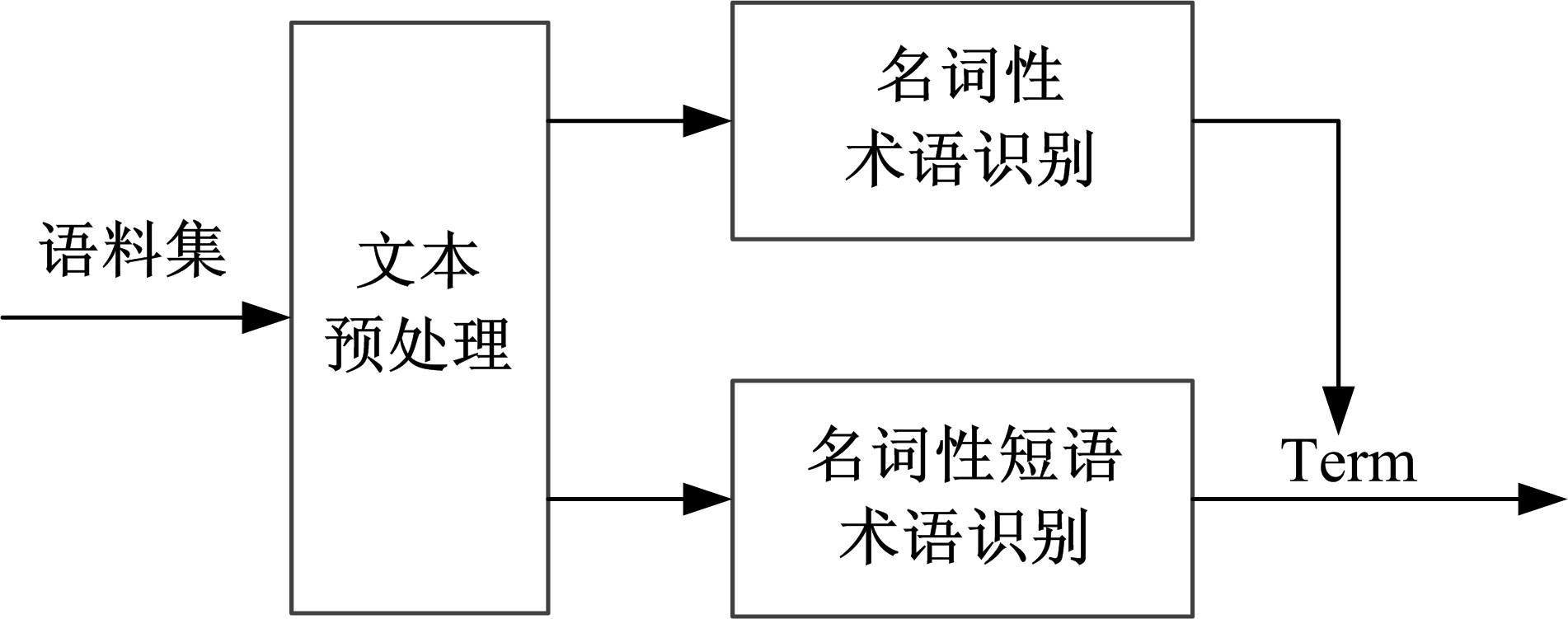 | 图1 术语抽取Fig.1 Term extraction |
术语抽取步骤如下:
Step1 调用Gate接口, 预处理语料集, 并将词性标注结果输出到XML文档中。
Step2 借用dom4j处理XML文档, 依次抽取单词和其词性, 并逐行存入文本中。
Step3 抽取名词并计算其频数 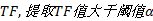
Step4 获取名词性短语并计算其频数 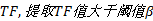
定义1 名词性短语。字符串 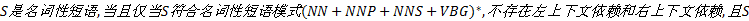
定义2 左上下文依赖。 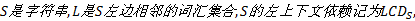
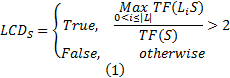
定义3 右上下文依赖。 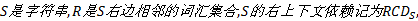
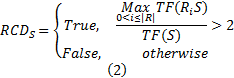
定义4 互信息。用于度量字符串间的关联程度。已知 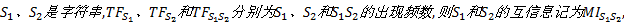
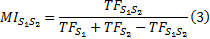
字符串 
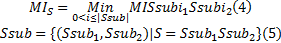
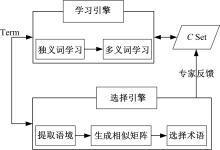
术语可能具有多个语义, 而概念的语义是唯一的, 因此需要确定术语的语义。相同语义的术语集合可以唯一标识特定的概念语义。词义消歧可确定术语的语义, 获得相同语义的术语集合。本文利用主动学习技术改进SSI算法实现术语的语义消歧以获取概念, 消歧过程由学习引擎和选择引擎两部分组成, 如图2所示。选择引擎自动选择信息增益大的未消歧术语, 提交领域专家标注, 系统将反馈结果添加到概念集 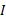
 | 图2 基于主动学习的词义消歧Fig.2 Word semantic disambiguation based on active learning |
词义消歧步骤如下:
Step1 提取术语的语境特征, 生成术语语境。
定义5 语境。术语的语境表征了术语应用的上下文, 记为 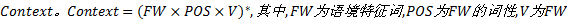
语境特征提取有滑动窗口法[14, 15]、基于词间依赖关系的语境特征提取法[16, 17, 18]和基于句法分析的语境特征提取法[19, 20, 21]三类。滑动窗口法易实现, 但由于没有考虑句法和语义关系致使结果中包含了邻近的但不相关的词而遗漏了较远的但相关的词。基于词间依赖关系的语境特征提取法的准确率较高, 但提取的语境词数目较少。基于句法分析的语境特征提取法在一定程度上弥补了以上不足。综合语境特征提取的研究现状, 本文选用了基于句法分析的语境特征提取法。
采用基于句法分析的语境特征提取法提取的术语语境特性, 为在句法分析树结构中与术语拥有共同祖先或位置上相邻的节点。提取术语语境特征的步骤如下:
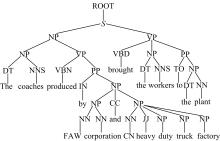
①生成句法结构分析树。图3是语句“ The coaches which brought the workers to the plant are produced by FAW corporation and CN heavy duty truck factory.” 的句法分析树。
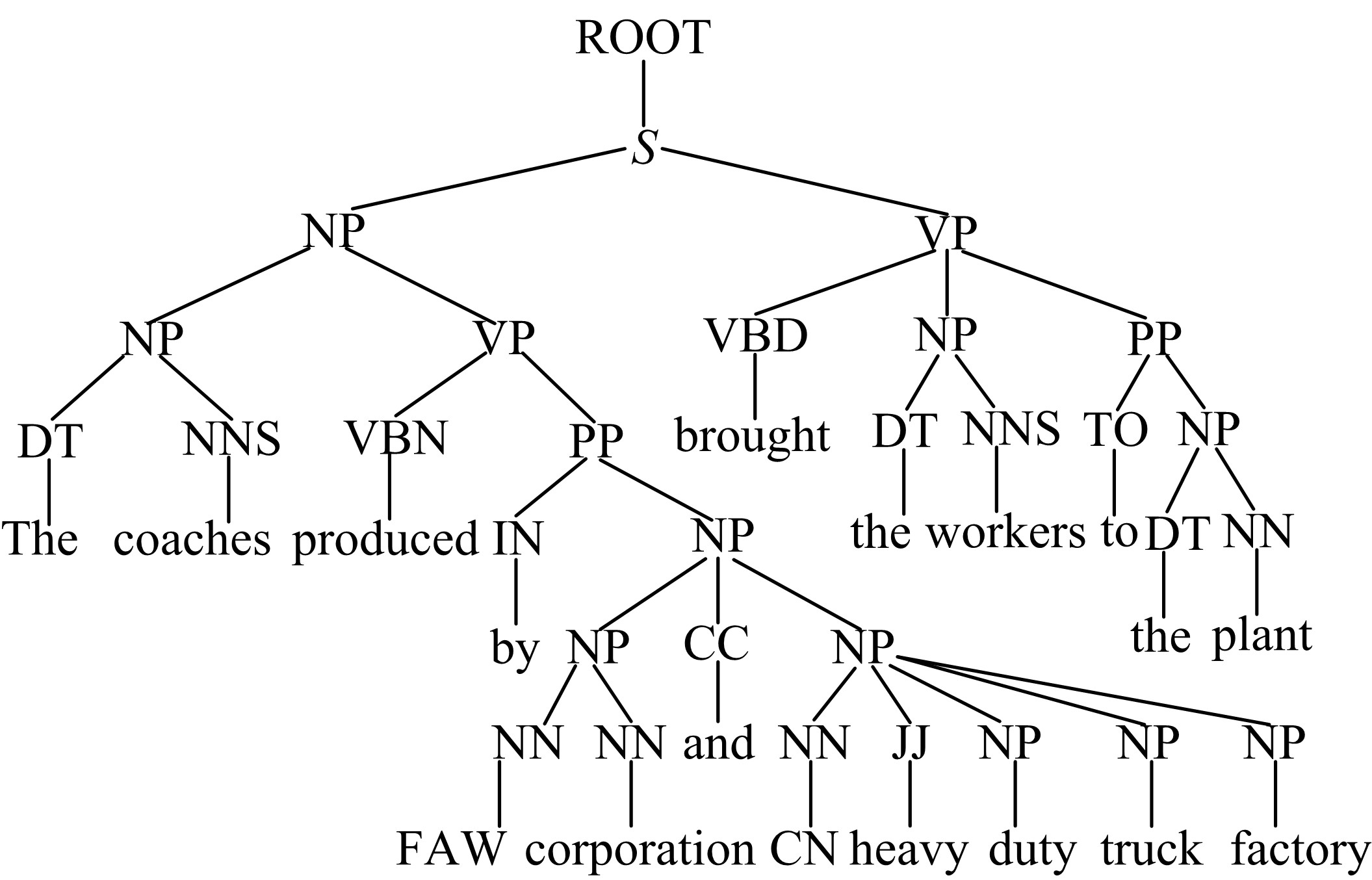 | 图3 句法分析树示例Fig.3 Example of syntactic analysis tree |
②按照树的层次结构, 从目标节点开始遍历树结构, 逐层搜集邻近节点选为候选语境特征词, 并利用候选特征节点和歧义词间的层次关系和路径距离, 依据式(6)计算其权重, 直到根节点为止。
式中: 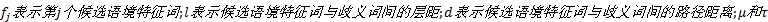
③将候选语境特征词按其权重降序排列, 去掉虚词, 选取前8个作为歧义词的语境特征, 获得术语语境。
Step2 计算术语语义相似度, 生成术语语义相似矩阵 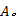

式中: 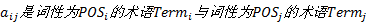
定义6 术语语义相似度。已知词性为 
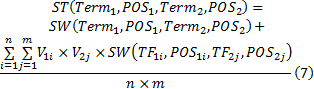
式中: 
定义7 词语义相似度。已知词性为 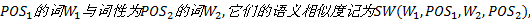
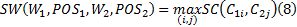
式中: 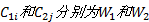
定义8 概念语义相似度。已知概念 
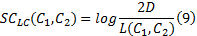
式中: 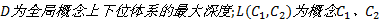
Step3 处理在WordNet中只存在一个语义的术语, 添加相应概念到集合 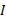
Step4 处理与 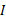
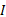
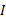
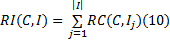
定义9 概念关联度。已知概念 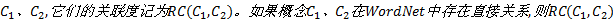
Step5 在未消歧术语集中选择信息增益最大的术语提交领域专家。保存反馈结果到 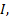
定义10 信息增益。本文中的选择引擎需在未消歧术语集 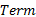
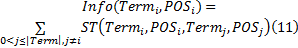
式中: 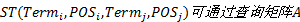
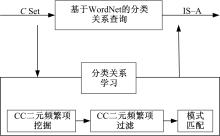
分类关系是一种类属关系, 大多存在于表示事物名称的名词之间, 具有一定的语言模式。直接在WordNet中查找概念间分类关系, 准确率高但查全率不够。如图4所示, 本文通过挖掘CC二元频繁项来提高查全率, 并采用模式匹配的方法自动判别CC二元频繁项集合中的分类关系, 弥补了关联规则学习关系时关系类型需要工作人员确定的缺陷。
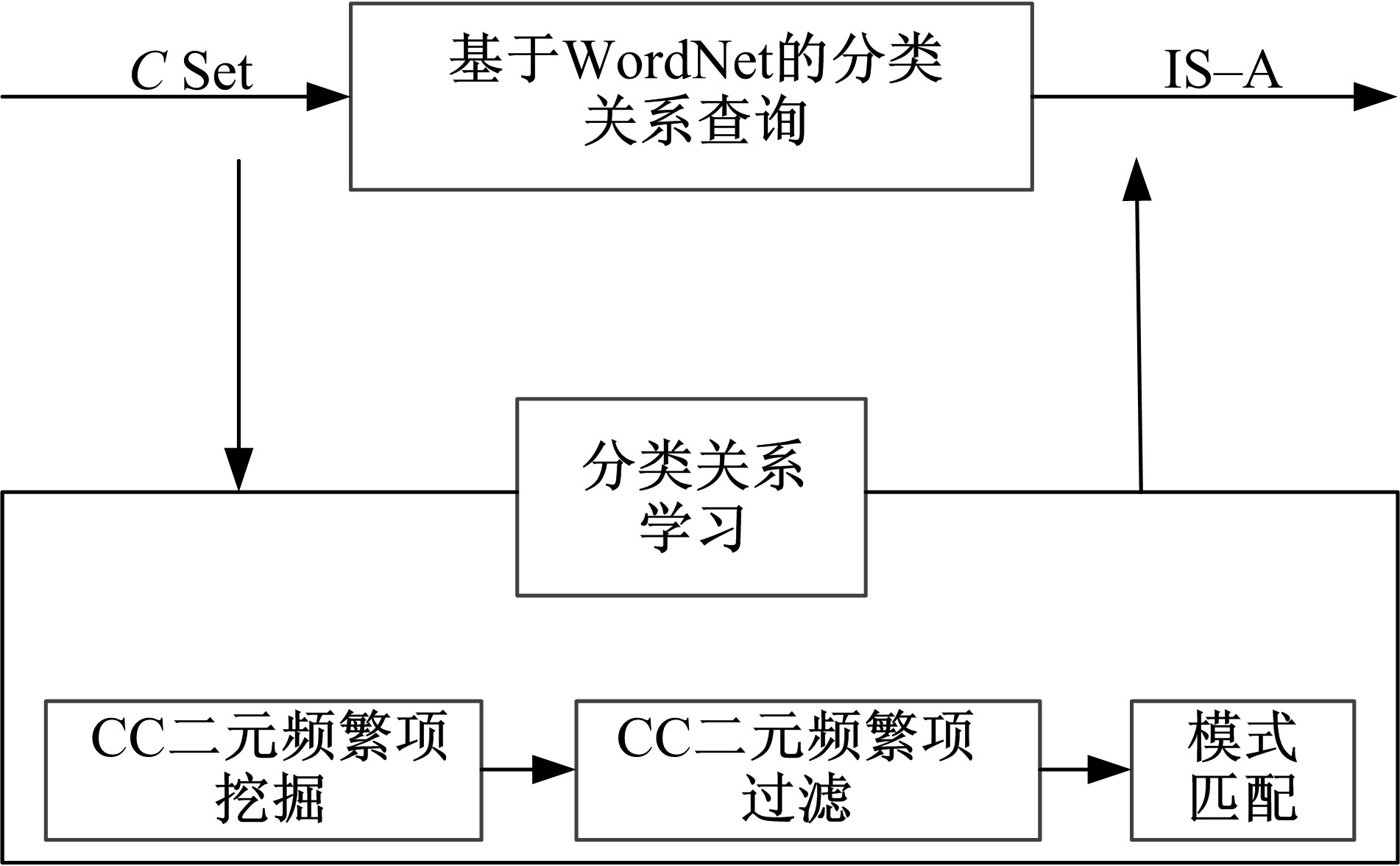 | 图4 分类关系学习Fig.4 IS-A relation learning |
分类关系学习的步骤如下:
Step1 基于WordNet调用 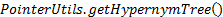
Step2 以概念集为项目集, 以语句为事务, 基于阈值 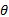
定义11 CC二元频繁项(CC)。表达概念间的二元关系, 以二元组表示CC=(C, C)。
Step3 基于WordNet过滤CC二元频繁项, 删除可识别关系的CC二元频繁项。
Step4 采用模式匹配技术识别CC二元频繁项中的分类关系, 使用如下分类关系模式。
分类关系模式:
NP such as NP, NP… and NP
Such NP as NP, NP… or NP
NP, NP… and other NP
NP, especially NP, NP… and NP
NP is a NP
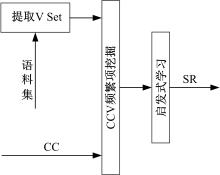
语义关系描述了一种对象属性, 即两个概念间的关系可用一个动词表示。现有VCC(n)事务方法学习概念间语义关系基于假设:如果概念 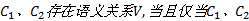
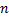
 | 图5 语义关系学习Fig.5 Semantic relation learning |
语义关系学习的步骤如下:
Step1 由语料库中提取动词集Vset。
Step2 读取分类关系学习阶段未标识关系的CC二元频繁项。
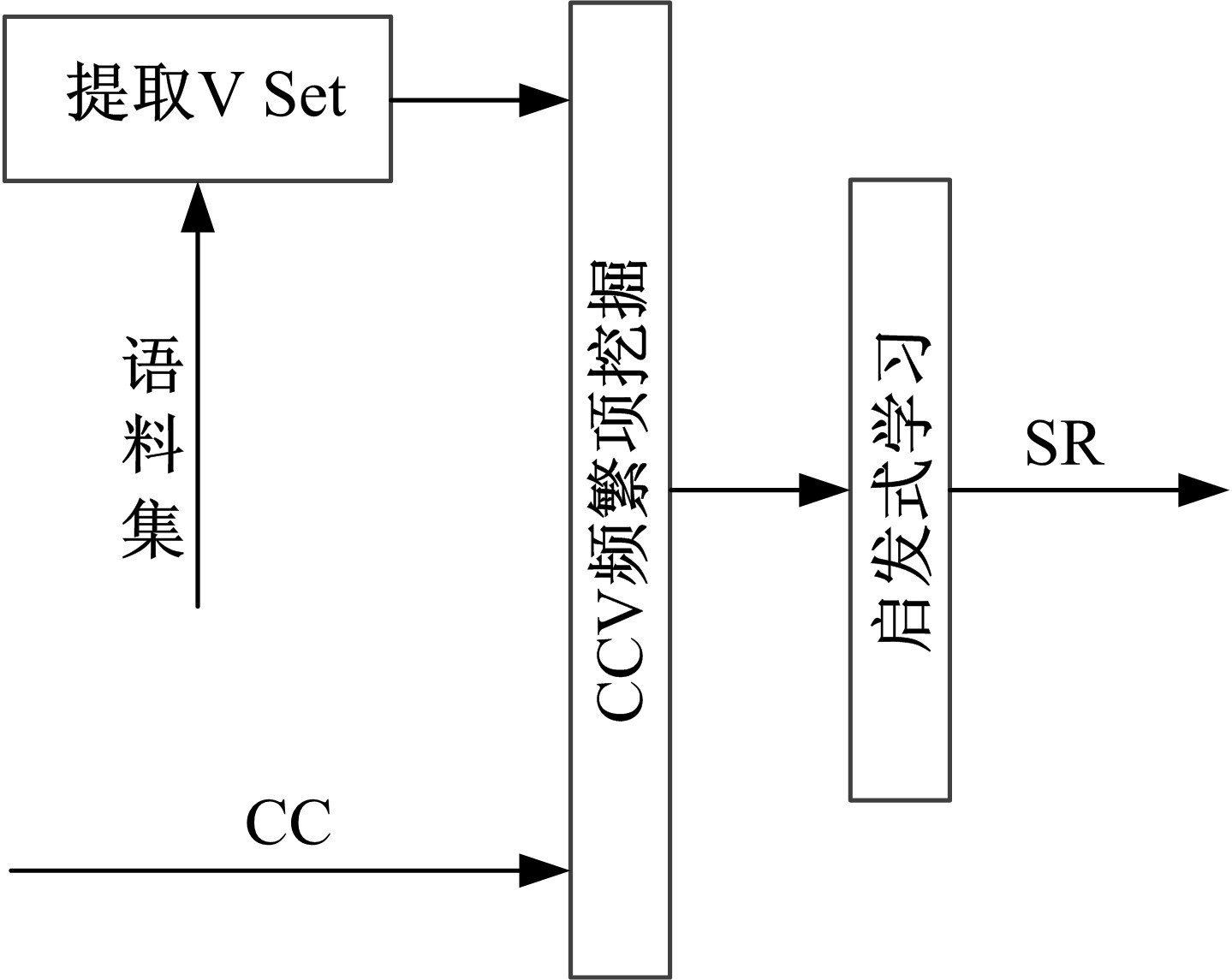
Step3 以语句为事务, 计算 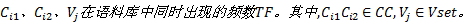
Step4 设定阈值 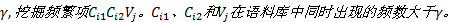
Step5 基于启发式规则1获语义关系集SR。
启发式规则1:若存在频繁项 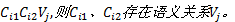
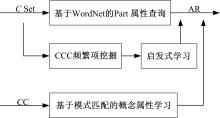
概念属性学习是获取概念内涵的方法之一。从语言学角度, 概念的属性仍为概念, 属性值则是属性的实例, 因此概念属性包含了概念与概念、概念与实例的关联。概念属性包含信息的多样性, 增加了概念属性学习的难度。本文提出了模式匹配、CCC三元频繁项挖掘、启发式规则与WordNet相结合的概念属性学习方法, 见图6。
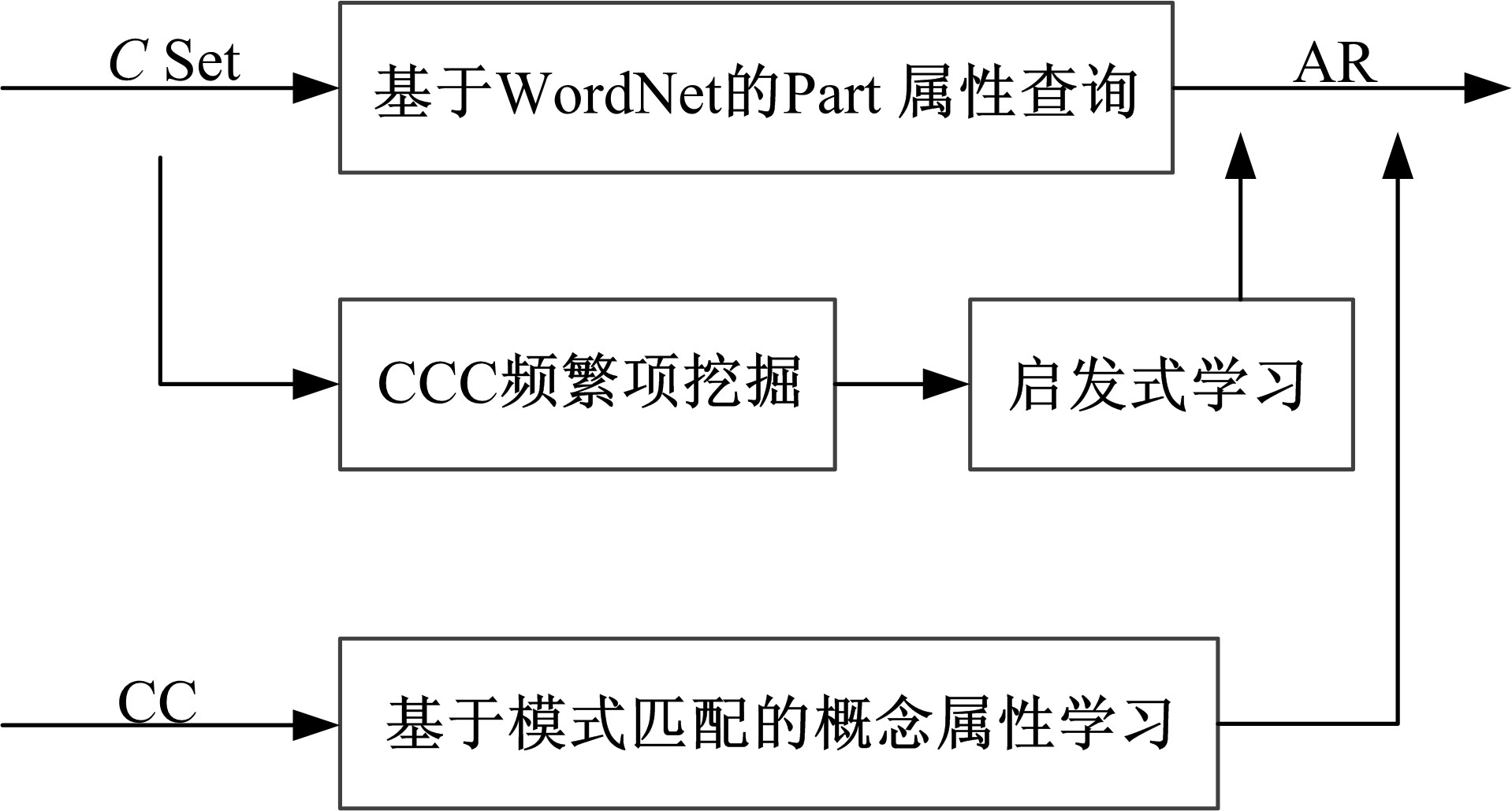 | 图6 概念属性学习Fig.6 Concepts attribute learning |
概念属性学习的步骤如下:
Step1 直接由WordNet中查找概念的Part属性。
Step2 采用模式匹配技术识别剩余CC二元频繁项中的概念属性关系, 使用的模式为如下概念属性模式。
NP’ s NP
NP part of NP
Step3 以概念集为项目集, 语句为事务, 基于阈值 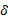
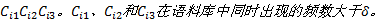
Step4 遍历CCC三元频繁项集, 结合WordNet基于启发式规则2学习概念属性。
启发式规则2:若CCC三元频繁项中有两个概念存在上下位关系, 且剩余概念和上述概念不存在上下位关系和同义关系, 则CCC三元频繁项中存在概念、属性和属性值, 其中属性是属性值的上位概念。
例1 如若 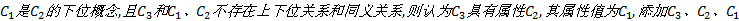
算法1 
输入:K-1元频繁项集LK-1,
事务集D, 阈值V。
输出:K元频繁项集LK。
1 CK-1=LK-1;
2 组成候选集:
3 令CK为容量为K的那些集合的集合,
4 它们的所有非空真子集都属于CK-1;
5 While CK不为空do
6 扫描事务集D:
7 计算CK中每个元素Ei的次数Ti;
8 令LK为CK中频繁集的汇集;
9 IF Ti> V Then
10 Ei加入LK;
11 End IF
12 End
算法2 模式匹配算法
输入:概念C1、C2, 模式P。
输出:True或者False。
1 生成模式:Pattern。compile(C1, C2, Pi);
2 扫描语料集:
3 以每篇文档为母字符串生成匹配器;
4 执行模式匹配, matcher。find();
5 IF 匹配成功 Then
6 Return True;
7 Else
8 Return False;
9 End IF
10 End
本文提出的面向文本的本体学习方法简记为TOL。并选择旅游领域的英文语料作为测试语料(http://www.lonelyplanet.com/destinations)验证TOL。评价指标采用查准率、查全率和 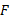
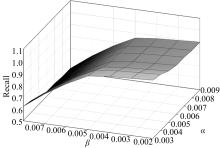
实验1 主要考查TOL方法中阈值 
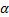
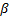
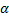
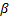
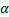
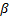
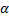
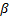
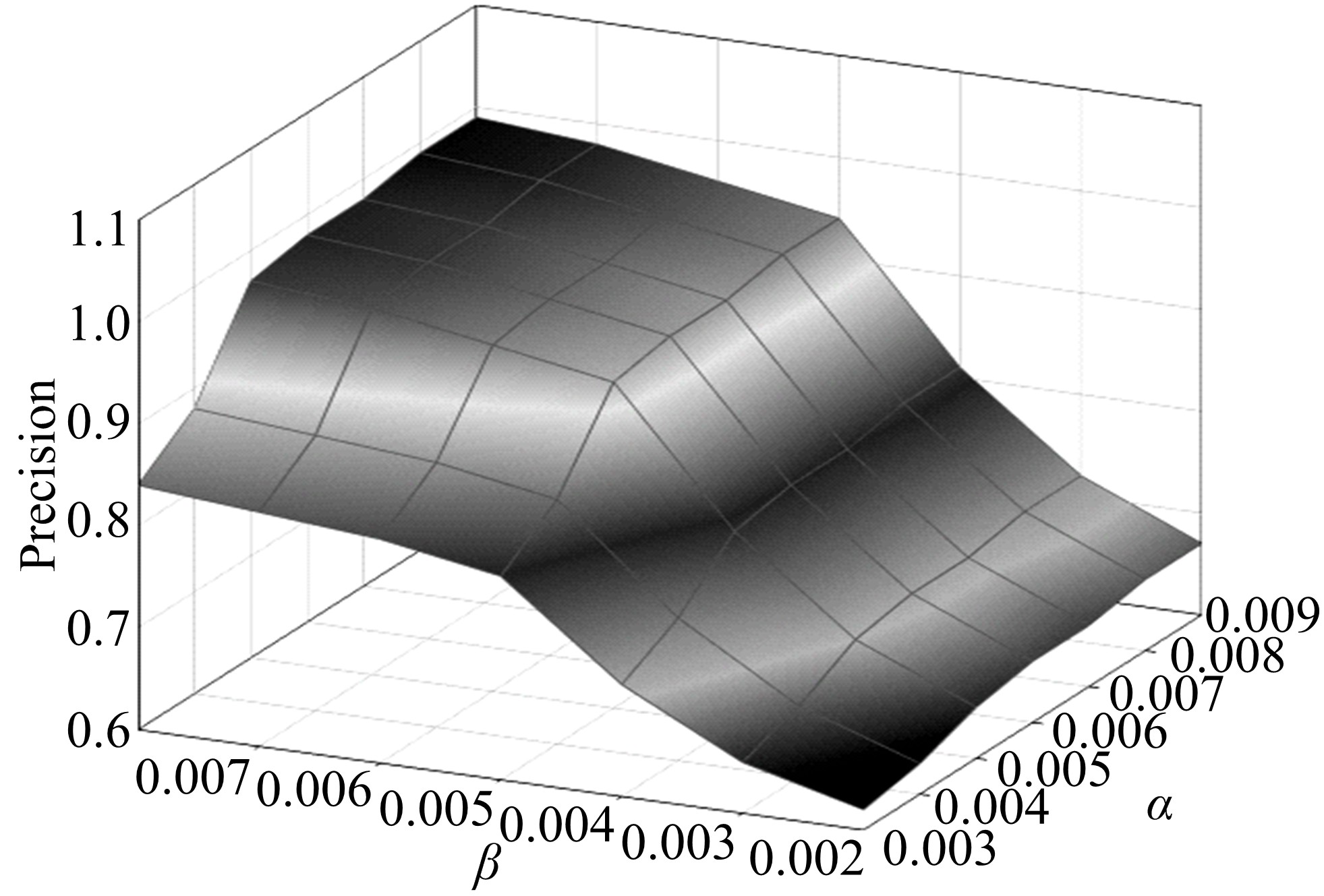 | 图7 α -β -准确度Fig.7 α -β -precision |
 | 图8 α -β -召回率Fig.8 α -β -recall |
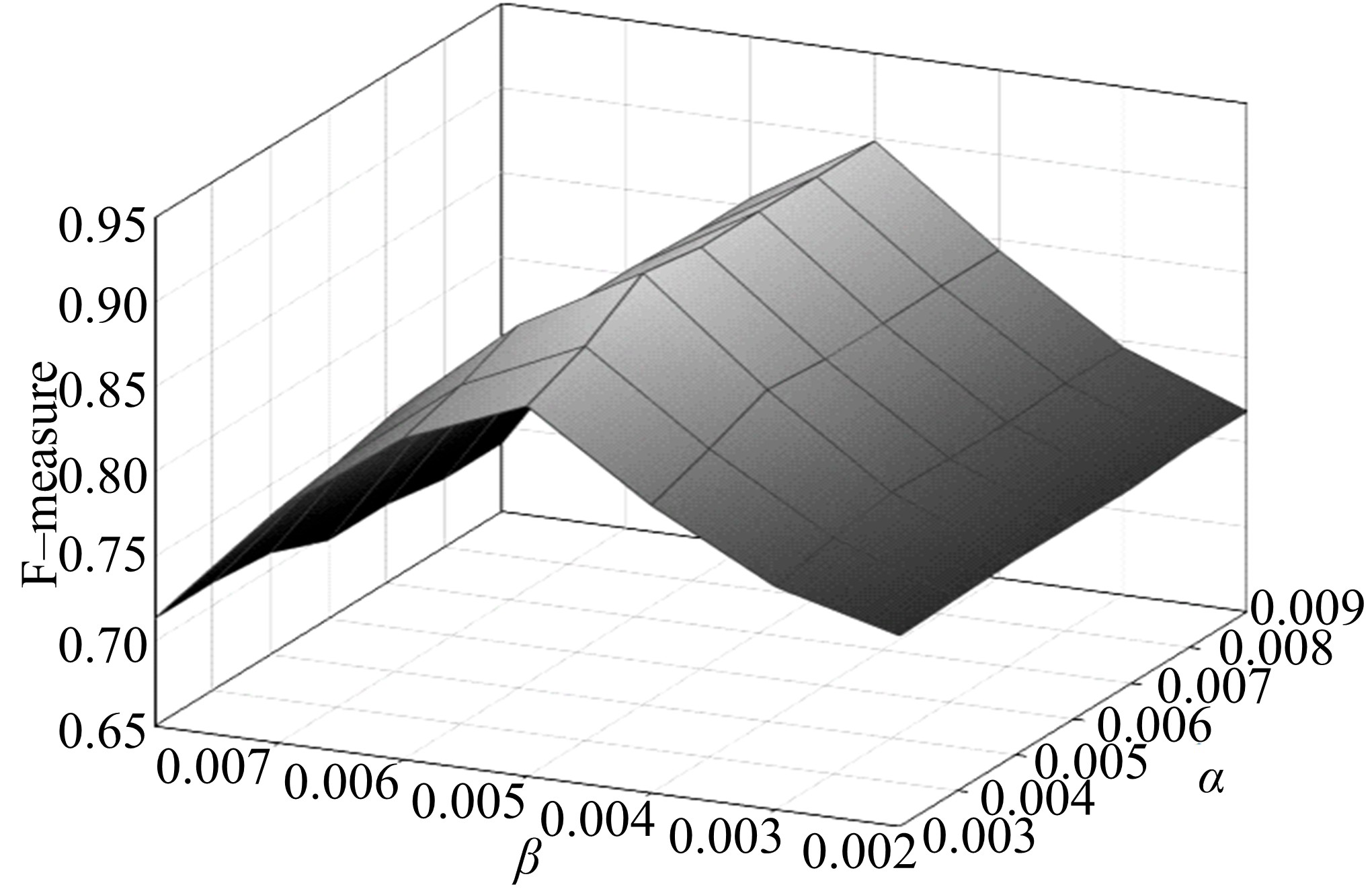 | 图9 α -β -F-measureFig.9 α -β -F-measure |
| 表1 术语抽取实验结果对比 Table 1 Comparison of term extraction experiment |
实验2 主要考查TOL方法中基于主动学习的词义消歧算法的性能。实验数据采用Senseval-3中的全文消歧任务作为测试集, 该测试集由3篇文档组成, 共包含349个句子、4903个单词, 需要消歧的单词有1969个, 短语有114个。Text2Onto直接将术语作为概念未提供词义消歧功能, 因此仅将实验结果与SSI算法的结果做了对比分析, 对比结果见表2。TOL各项指标均显著高于SSI, 可见专家的适当干预是提高词义消歧的有效途径。
| 表2 词义消歧实验结果对比 Table 2 Comparison of WSD experiment |
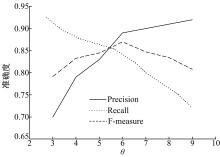
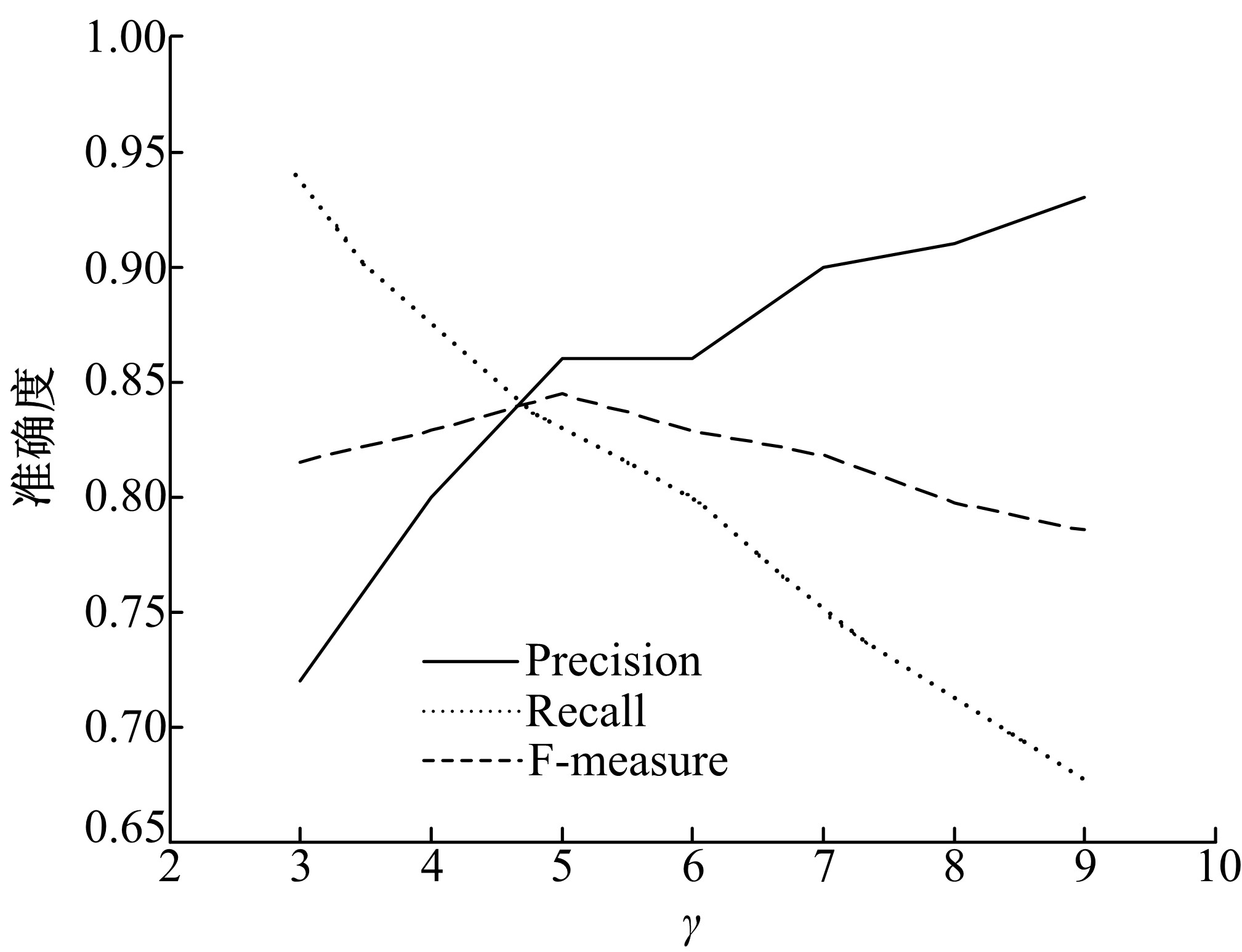
实验3 主要考查TOL方法中阈值θ 的变化在分类关系学习过程中对3个评价指标的影响情况, 从而选择最佳阈值。θ 的取值范围为3~9, 不同阈值对评价指标的影响如图10所示, 可以看出当θ 为6时, 整体效果较好。另外把θ 为6的结果与Text2Onto的结果相比较, 对比结果见表3。TOL各项指标均高于Text2Onto, 其中准确率高出Text2Onto 6个百分点。这要归功于本文采用了多种策略相结合的分类关系学习方法。
| 表3 分类关系学习实验结果对比 Table 3 Comparison of IS-A relation learning |
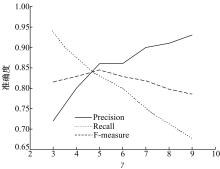
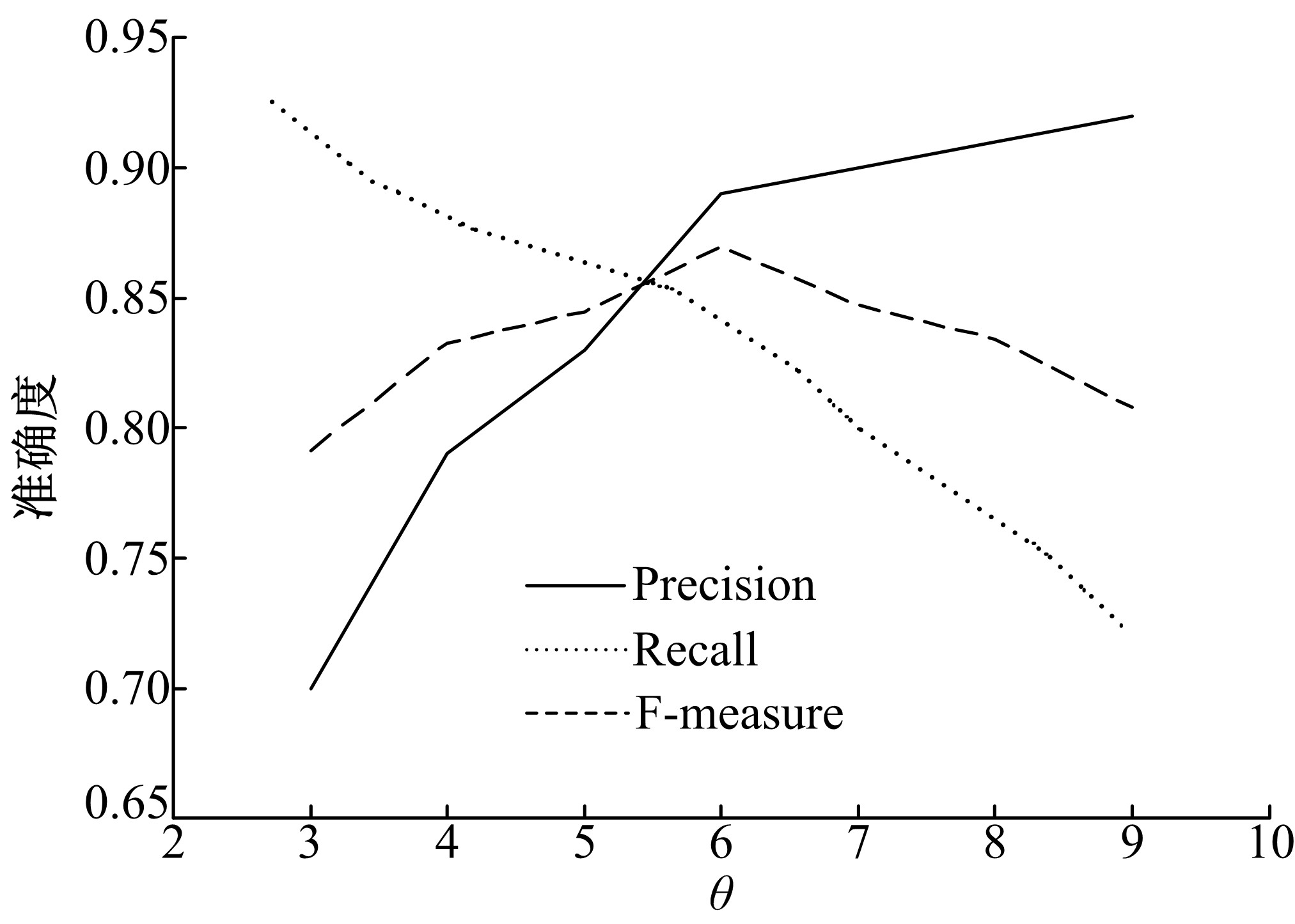
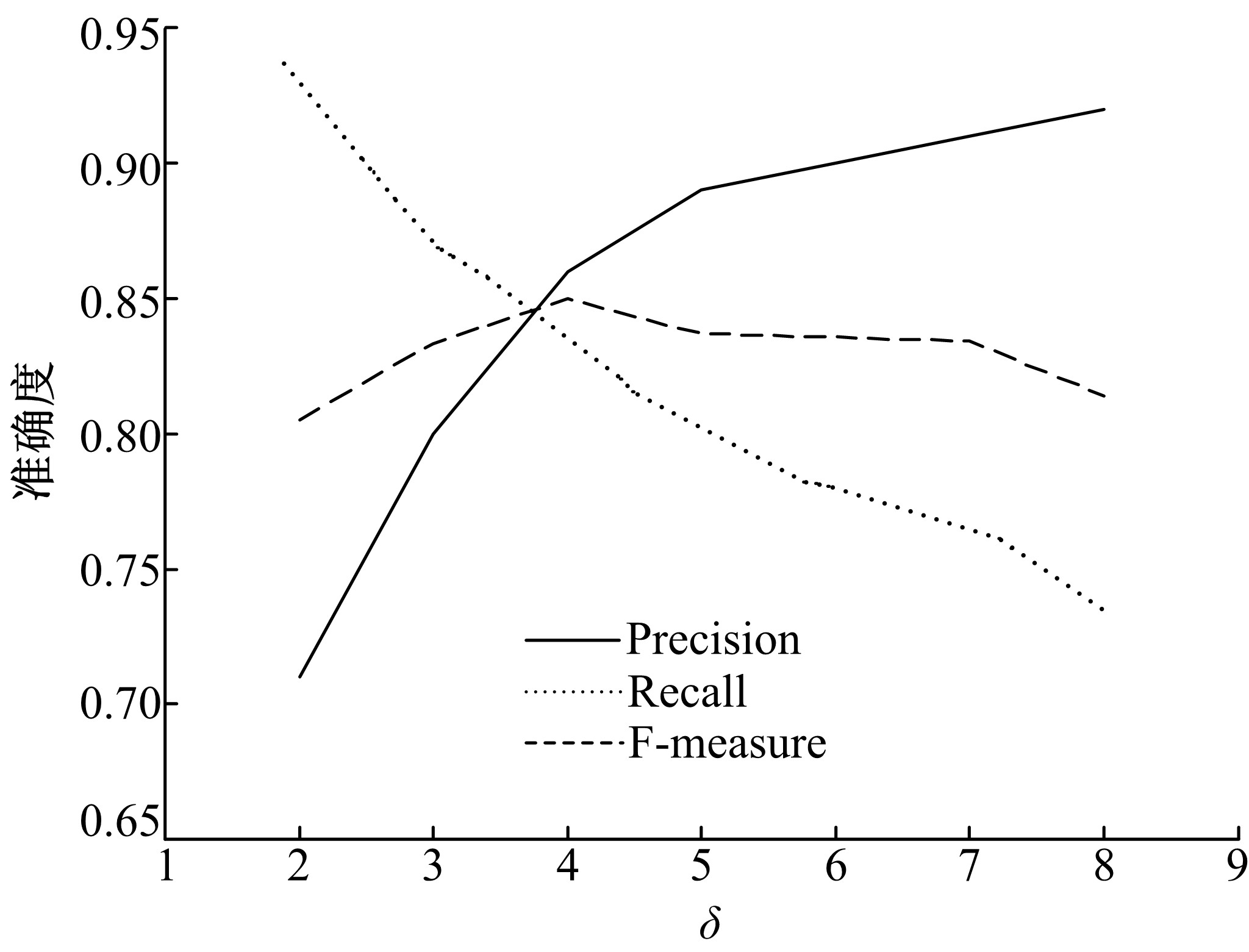
实验4 主要考查TOL方法中阈值γ 的变化在语义关系学习过程中对3个评价指标的影响情况, 从而选择最佳阈值。γ 的取值范围为3~9, 不同阈值对评价指标的影响如图11所示, 可以看出当γ 为5时, 整体效果较好。另外把γ 为5的结果与Text2Onto的结果相比较, 对比结果见表4。TOL的准确率、召回率和F-measure值均稍高于Text2Onto。
| 表4 语义关系学习实验结果对比 Table 4 Comparison of semantic relation learning |
本文提出的面向文本的本体学习方法, 使用统计和名词性短语模式学习术语, 并利用主动学习技术改进SSI算法实现术语的语义排歧以获取概念, 采用频繁项挖掘与模式匹配技术结合WordNet学习概念上下位关系, 通过挖掘CCV频繁项启发式学习概念语义关系, 结合模式匹配、CCC三元频繁项挖掘、启发式规则与WordNet学习概念属性, 实验结果表明TOL方法整体效果较好, 改善了概念语义排歧效果, 丰富了短语概念学习与语义关系学习, 提高了本体自动构建的准确度, 可降低本体构建的代价。其中, 提出的基于主动学习的语义排歧算法, 弥补了SSI算法无法处理所有术语在WordNet中都不是独义的情况的不足; 并增加了概念属性的学习。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|