

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
一种交互感知的并行查询调度策略
[张青峰 , 许静, 李珊珊]
, 许静, 李珊珊]
, 许静, 李珊珊]
|
|


作者简介:张青峰(1979-),男,博士研究生.研究方向:数据库性能评估和优化,软件工程.E-mail:zhangqf@mail.nankai.edu.cn
为了捕获数据库并行查询之间的交互作用,本文利用实验驱动的方法对查询交互进行性能建模,并基于性能模型提出了一种交互感知的并行查询调度策略,通过减小交互作用带来的消极影响来获得较好的系统性能。与其他调度算法的实验比较结果表明,交互感知的调度策略可以更好地提升数据库性能。
To capture the impact of concurrency on query performance we present an experiment-driven modeling approach and propose an interaction-aware scheduling strategy to achieve better performance by reducing the negative interactions. Experiment results demonstrate that, compared with other methods, the proposed scheduling strategy can effectively improve the database performance.
在数据库系统应用中, 查询任务往往占绝大多数, 因此查询优化是数据库性能优化的一项最为重要的技术手段。随着数据库变得越来越大, 大量业务数据被收集和存储起来, 并基于海量数据进行更加智能的分析和决策。为了提高数据库服务器的资源利用率和吞吐率, 并行计算技术被引入到了数据库系统中, 通过并行查询技术, 可以使用更少的时间来完成相同数量的查询任务, 大大提升数据库的性能。但同时当大量查询任务并行执行共享计算资源和数据的时候会出现非常复杂的交互作用, 这些复杂的交互作用将对系统性能产生巨大的影响[1]。这些影响可能是积极的, 也可能是消极的, 因此并行查询任务的调度算法比传统数据库的查询调度要复杂得多, 选择合适的调度算法将会显著提升系统性能, 从而使得查询任务的执行总时间最小。
针对以上问题, 本文通过对并行查询的交互作用进行实验分析, 构建了一个基于查询交互的性能模型, 并提出了一种交互感知的并行查询调度算法。交互感知的调度算法和传统查询调度方法的主要区别在于考虑了并行查询之间的交互作用。通过基于MySQL/TPC-H的实验研究证明了ICMF调度策略的有效性。通过利用ICMF调度算法, 相同数量查询任务的整体执行时间比SJF算法和FCFS算法大大减少。
并行查询的优化和调度算法有很长的研究历史, 但大部分的研究工作都是依赖于查询内部的信息以及对系统底层资源信息的监控, 如国内学者曹阳等人提出了使用遗传算法来解决多连接表达式的并行查询优化问题[2]。国防科技大学的张丽等人提出在海量数据管理平台中利用语义缓存技术对聚焦查询进行优化, 提升查询速度[3]。这些研究工作主要是基于查询任务内部的语法结构信息和语义相关性来重用缓存数据, 从而达到提高系统性能的目的。而本文的研究工作不需要提前知道查询任务内部的语义信息, 通过实验驱动的性能建模方法来捕获并行查询之间的交互作用来实现并行查询的优化。
一些传统的查询调度算法, 如最短时间优先(SJF)算法在实施访问控制时, 主要是基于查询单独执行时的运行时间来进行调度, 却完全没有考虑多查询任务并行时的运行时间和单独运行时可能会发生巨大的变化。当前, 对并行查询调度算法的研究还有很多新的方法, 如文献[4]提出了一种基于分段线性的服务水平协议的调度策略, 并通过预测查询超时时间来进行动态的任务调度。文献[5]通过动态调整数据库的并行级别(MPL)来进行查询调度, 首先利用排队论为系统设定一个初始的并行级别, 并实时通过反馈监控动态调整并行数, 从而使得系统性能达到最优, 但对并行级别的调整策略也没有考虑并行查询之间的交互作用。在本文中, 假定数据库的并行级别是固定不变的, 而基于并行查询之间的交互作用动态调整数据库的并行级别是未来的研究方向之一。本文认为并行查询操作具有不同的处理特性, 对资源的竞争使用模式也不同, 并行查询之间的交互作用会对系统性能产生巨大的影响, 因此在进行查询任务调度时, 必须考虑并行查询之间的交互作用才能实现更优的系统性能。
查询交互作用指的是并行执行的查询任务之间的资源冲突, 这些冲突会对系统性能产生巨大的影响[1]。目前, 在数据库研究领域对查询优化和查询调度的研究非常多, 但关于普通意义上的查询交互的研究却非常少。
国外的一些研究机构中已经有一些学者开始针对查询交互进行探索, 主要基于查询交互进行延迟预测和性能评估。2008年滑铁卢大学的Mumtaz Ahmad等人首次提出了并行查询交互作用的概念, 并在文献[1, 6, 7]中详细描述了查询交互会对系统性能产生巨大的影响作用, 并提出了基于查询交互的性能优化和调度算法, 但与本文的调度算法不同的是对交互成本的计算方法, 在文献[6]中是基于并行查询组合的不同类型查询的数量来计算交互成本的, 而本文中是基于不同查询类单独运行(MPL=1)和两两运行(MPL=2)的交互时间成本来进行建模的。Sean Tozer等人在文献[8]中通过对查询交互作用进行分析和建模, 针对多层架构的网络应用提出了一种基于并行查询交互的访问控制策略, 在文中提出当一个网络请求到达服务器时, 通过预测请求的执行时间来判断是否允许访问服务器, 而此时需要考虑并行请求之间的交互作用。此外, 布朗大学的Jennie Duggan等人在文献[9]中提出了基于查询交互来预测查询任务的响应延迟, 并提出了一个新的查询延迟的度量指标BAL(Buffer access Latency)。这些研究结果都证明了以下几点问题:①查询交互对性能有非常大的影响; ②并行查询之间的交互作用是非常复杂的, 而且很难进行白盒分析; ③通过实验的方法可以有效地捕获这些交互作用, 并且能够对查询交互建立正确的性能模型。这些研究成果都给了本文很大的启示。
而在国内, 目前还没有发现有学者明确提出基于查询交互作用进行任务调度这方面的研究资料, 本文的工作是在实验的基础上尝试在并行查询的优化和调度策略研究中引入了查询交互的分析。目前一些具体的研究工作, 例如查询优化技术[10]、负载管理[11]等, 都没有考虑这些并行查询执行中所产生的交互作用影响。本文将通过实验证明被这些研究工作忽略的交互作用会对性能产生非常巨大的影响, 因此并行查询的交互作用研究是一个非常值得深入研究的领域。
用Q1, Q2, …, Q22来表示TPC-H的22个查询类型, 在实验中用QGEN程序自动生成查询语句中的参数, 从而获得具体的查询实例[12]。数据库系统的并行级别用MPL(multi programming level)来表示, MPL是指在任何时候数据库系统允许并行执行查询实例的最大数量。
接下来通过不同的实验来分析不同的MPL并行情况下查询交互对查询组合中每个查询任务完成时间的影响。在实验过程中, 测试数据都是均匀分布的, 因此对同一查询类型的不同查询实例, 在相同的环境下其执行时间可以看做近似相等。
(1)单独运行(MPL=1)
首先, 通过实验获得每个查询类单独运行(MPL=1)时的平均运行时间。
从TPC-H查询类型中选择10个中等量级的查询类型, 并用QGEN程序为这个10个查询类分别生成10个实例, 然后在10 G数据库上单独运行这100个查询语句, 记录每个查询任务的执行时间, 从而可以计算获得每个查询类单独运行时的平均运行时间。
在计算平均运行时间时, 假定每个查询任务都是预先加载好缓存的, 因为每个查询类第一个执行的查询实例都会有一些初始化缓存的开销, 因此对每个查询类不计算第一个执行的查询实例的运行时间, 从而可以获得更准确的平均时间开销。
在表1中可以看到这些查询类在10 G数据库上运行时的平均花费时间。Tj代表了特定的查询类型的10个实例的平均运行时间。Tj将作为以后研究并行查询交互作用的基准时间。
| 表1 MPL=1时的平均完成时间 Table 1 Average completion time when MPL=1 |
(2)两两并行(MPL=2)
在研究了每个查询类单独运行时的平均运行时间之后, 将对这10个查询类两两并行的交互作用进行实验分析。所有10个查询类之间的唯一的两两组合, 共有n* (n+1)/2=55个查询组合, 分别执行这55个查询组合, 并记录相应的运行时间的变化。
用Ti表示Qi单独运行时的执行时间, Ti/j表示Qi与Qj并行时的执行时间, 则可以Δ Ti/j来表示Qi与Qj并行时的变化。
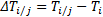
如果Δ Ti/j是正的, 说明速度变慢了, 如果是负值, 说明速度变快了。需要注意的是两两查询之间的交互作用不是对称的(Δ Ti/j≠ Δ Tj/i)。
如表2所示, 表中分别记录了55组两两交互的运行时间。从表中可以看出, 当Q19和Q21一起运行时, 它们分别获得了大约4 s和77 s的加速; 当Q3和Q21一起并行时, Q21获得了约38 s的加速, 而Q3的执行时间却增加了17 s; 当Q5和Q14并行运行时, 它们的运行时间分别增加了大约52 s和54 s。在此注意到Q19和Q21一起并行时, 分别都获得了性能加速, 这个现象是因为两个SQL在并行时, 互相为对方加载了缓冲数据, 因此同时出现了积极的交互影响, 加快了查询处理速度。
| 表2 MPL=2时的交互作用分析 Table 2 Interaction effect analysis when MPL=2 |
通过表2中的数据可知, 当不同的查询类两两并行时, 其完成时间会出现不规则的变化, 有减少也有增加。这也证明了并行查询之间的交互作用会对查询性能产生非常显著的影响, 这些影响有时会是积极的, 但有时也会是消极的。
而交互作用的产生又是非常复杂的, 其原因也是多种多样的。例如, 一个查询Qi会把数据加载到缓冲池中, 然后一个并行查询Qj会用到这个数据, 那就会产生积极的交互作用。而相对应的, 在硬件资源使用上的冲突会使Qi和Qj互相竞争, 例如对CPU、内存或者数据库系统内部资源存取锁的使用上产生的冲突, 就会产生消极的交互作用。
(3)高级别并行(MPL> 2)
当并行级别大于2时, 并行查询之间的交互作用将变得更加复杂和难以捕获。下面分别对不同并行级别情况下的交互作用进行实验分析。
在表3中, 随机抽取三个查询类型进行组合, 记录并行运行时每个查询的执行时间。从表中数据可以看出, 完成时间有减少的, 也有延长的, 不同组合中同一个类型查询的完成时间变化是不规律的。
| 表3 MPL=3时的交互作用分析 Table 3 Interaction effect analysis when MPL=3 |
接下来, 对M=5的两个查询类型的不同组合的交互作用进行分析, 如表4所示。其中, Nij是查询组合Mi中查询类型Qj的实例数量, 把组合Mi中的查询类型Qj的平均运行时间表示为Aij。在表4中依次减少Q19的实例数量, 同时增加Q6的实例数量, 观察Q6和Q19的执行时间的变化情况。
| 表4 两个查询类型的不同组合的交互作用分析 Table 4 Interaction effect analysis for different query mixes |
从表4数据可以看出, 即使只有两个查询类型时, 仅仅用一个查询类型的实例来替换另一个查询类型的实例也会显著地改变查询执行时间, 这也进一步证明了查询交互的重要性。
最后, 将对多种查询类型的组合进行试验, 如表5中所示。选择5个查询类型的实例进行组合变化, 保持组合的实例数量M=5不变, 即保持并行级别MPL不变。
从表5中数据可以知道:当查询组合中有多个查询类型时, 其交互作用将更加复杂, 在并行过程中变化某一个查询类型的数量也可能会对其他并行的查询任务产生非常大的影响。
从本节的大量实验中可以得出以下结论:①一个包含了多种查询类的组合并行运行时可能既包含积极的交互, 也包含消极的交互。②对所有的查询类来说, 它的并行执行时间与和它并行的查询类关系非常密切, 不同的并行查询将产生截然不同的交互作用。③并行查询的交互作用是相当复杂的, 在查询组合中的一个小的改变有时会对其他查询的性能产生巨大的影响, 但这些影响又是非常难预测的。
| 表5 不同查询组合的平均运行时间 Table 5 Average completion time of different query mixes |
基于以上的分析可知, 并行查询交互作用的产生因素是非常复杂的, 要想对这些因素进行建模, 就需要考虑硬件资源(CPU、内存和磁盘I/O), 数据库内部构件(查询计划、访问方法、缓冲池、数据库锁), 操作系统内部调度以及其他可能的因素。对所有这些因素进行建模, 需要监控并行过程中每一个指标的变化情况, 以便于在模型中反应每一个产生因素, 这是非常复杂和困难的, 为了避免建立如此复杂的模型, 本文主张采用实验驱动的性能建模方法。
以上这些实验说明了除非能够对查询组合中的并行交互作用进行建模, 否则不可能得到最优化的查询性能, 如果只关注单独的查询类型而忽略并行查询之间的交互作用, 不可能得出关于性能的准确结论。因此, 下一步的主要工作就是开发基于查询交互作用的性能模型, 准确地建模对于进行性能优化和任务调度都是非常重要的。
在上一节的分析中可知, 为了对查询交互作用进行建模, 主张用实验驱动的性能建模方法。目前, 在查询交互作用的相关研究工作中, 基本上也都采用了实验驱动的黑盒建模方法[6, 7, 9]。当软件系统变得越来越复杂时, 实验驱动的方法也越来越多地被用来建立健壮的软件系统性能模型。关于实验驱动的建模方法国内外都有大量的尝试, 文献[13]用实验驱动的方法预测查询的性能指标, 文献[14]采用了实验驱动技术来自动优化数据库的配置参数, 这些工作证明对于数据库性能建模来说, 实验驱动方法是可行和有效的。
本文中使用WEKA(Waikato environment for knowledge analysis toolkit, 怀卡托智能分析环境)工具[15]来构建并行查询交互的性能模型。在WEKA环境中, 选择线性回归算法来建立模型和测试模型。在建模过程结束后, 可以从样本数据中得到一组回归模型的系数。
当一个新的查询q加入到一个查询组合Mi中时, Mi中并行的其他查询为(c1, c2, …, ct), 则q加入Mi后查询组合的并行交互成本(Interaction cost, IC)可以构造线性回归方程计算如下:
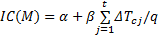
以上回归方程中, 每一个查询类在已经初始化缓存情况下独立运行时间平均值和两两查询之间的交互作用为回归方程求解提供了独立变量的输入值。
回归方程可以用最小二乘法来求解导出相应的系数α 和β , 在每一个并行级别分别求一次。其中α 表示q加入到M中的时间偏移, 而β 是指不同并行级别下两两并行交互成本对整体系统性能的影响。在此处, 回归模型没有考虑加入q后, cj对q产生的交互作用(即Δ 
举例:当查询a加入到(b, c)的查询组合后, 计算因为a的加入而产生的并行交互成本, 则需要以下几个输入值:Ta, Tb, Tc为单独运行时的平均时间; Δ Tb/a, Δ Tc/a为两两并行时的运行时间变化。
可以计算加入查询a后产生的并行交互成本为:
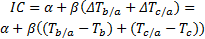
对不同的并行级别需要进行分别建模, 当并行级别为2, 3, 4, 5时, 分别计算回归方程的系数。当MPL=2时, 10个查询类的并行交互需要执行55个组合; 而当MPL=3时, 则需要执行110个并行组合。因为MPL=2和3时, 样本空间数量相对比较小, 因此可以直接对实验数据进行建模分析。当并行级别不断增加时, 回归方程的样本空间呈指数级增长, 因此为了计算高级别并行查询的交互成本, 选择合适的抽样数量是非常必要的。而当MPL大于3时, 因为样本空间相对比较大, 因此对每一个查询类型, 在每个并行级别的样本空间中均匀地随机选取50个观测样本, 运行这些样本可以计算获得每一个并行级别的模型系数。
此外, WEKA还支持很多其他高级的性能建模算法, 如局部加权线性回归模型、神经网络[13]、高斯处理模型[16]等。本文选择线性回归模型是因为对于并行查询的交互作用来说, 虽然其关系比较复杂, 但利用线性回归模型已经能够抓住查询交互作用的主要性能特征, 并且在实验中也已经得到了较好的分析结果。
查询任务完成总时间(Tsum)可以定义为从第一个查询任务开始启动到所有查询任务都完成时总共消耗的时间。
已知并行负载W由N个查询任务Q1, Q2, Q3, …, Qn构成, 每个查询任务所属的TPC-H查询类型是已知的, 数据库的并行级别为M, 也就是说在并行过程中, 同时最多只有M个查询在执行, 这M个查询就构成了一个查询组合mi, 由所有的mi构成了一个查询组合集X={m1, m2, …, mi}, 调度算法的目标就是生成一个最优顺序的查询组合集X。
首先做两个假设:
(1)所有特定某一类型的查询都有着近似相同的性能。
(2)数据库可以以任意的顺序执行队列中的查询任务。查询之间的优先级限制可以在系统外进行强行控制。
基于以上分析和假设, 交互感知调度算法的实现方法就是优先执行交互成本低(积极交互)的查询组合, 避免执行交互成本高(消极交互)的查询组合, 从而使整个并行任务的交互成本最低, 也就是任务完成总时间Tsum最少。
交互感知的调度策略执行步骤为:
(1)从N个查询任务中选择M个查询组成一个并行交互成本最小的查询组合Mmin启动并行任务。
(2)在任意一个查询Qmin最先结束时, 得到Mmin中的其他(M-1)个查询任务。
(3)对每一个等待队列中的查询, 计算其与正在执行的(M-1)个查询组成的查询组合的并行交互成本。
(4)获得新的并行交互成本最小的查询Qnext。
(5)重新从(2)开始循环执行, 直到完成所有的查询任务。
以上算法用形式化语言可以表示如下:
输入:并行负载W, 由N个查询组成。
输出:并行交互成本最小优先的查询执行顺序。
Algorithm ICMF(W)
Begin
selectMminFromW(W);
runMmin();
while(Qmin is end) do
runQM = getRunQueryMix(M-1);
for each Qi in arrival queue do
IC (i) = EstimateIC(Qi, runQM);
end for
sortArrivalQuery(IC with runQM );
addTheMinICQueryToExecute();
end While
End
在以上算法中, IC(i)指加入Qi后对查询组合的交互成本, 可以直接通过线性回归方程得到交互成本的值。线性回归方程的系数可以通过离线实验获得, 因此不会对查询任务的性能产生大的干扰。
为了验证本文提出的交互感知的并行查询调度算法, 本文用C++语言开发了一个并行查询调度工具。调度工具作为一个独立的组件来进行查询任务的优化调度, 和数据库服务器在逻辑上也是独立的, 从而保证不会对查询任务本身产生过大的压力。
通过实验分别在不同的MPL情况下, 将交互感知的调度(Interaction cost minimum first, ICMF)算法与传统数据库的最短时间优先(Shortest job first, SJF)算法和先到先服务(First come first served, FCFS)算法进行对比实验, 从而证明了ICMF算法的有效性。
实验使用的硬件配置是:Intel Core 2 Pentium 4 Duo CPU 2.83 GHz, 12 GB内存。操作系统为Windows 2008, 数据库采用的是开源的MySQL5.0, 使用的存储引擎是MyISAM, 数据库的缓冲池大小设置为2.4 G, 并假设相关的数据库配置参数都已经进行了较好的优化。
实验基于TPC-H测试标准, 生成了10 G大小的TPC-H测试数据库。TPC-H提供了DBGEN工具来生成测试数据, 并且保证生成的数据是均匀分布的。查询负载是通过QGEN工具来生成的, 因为TPC-H使用均匀分布的数据和查询参数, 因此对一个特定的查询类型来说, 不同参数的查询实例的执行时间的差异是可以忽略不计的。
首先从TPC-H查询类型中选择10个中等量级的查询类型, 这10个查询类的执行时间在所有22个查询类中也都是中等长度的。
选择这10个查询类型的依据是:如果某一个查询任务的运行时间过长, 那么就只能观察到该任务与其他大部分查询任务的交互作用, 而无法更多地捕获其他查询之间的交互作用; 而相反, 如果查询任务的执行时间过短, 就不能反映出它对其他查询任务的影响。
此外, 本文选择10个相同级别的查询类型的另外一个原因是为了避免对不同量级的查询进行建模。文献[11]对这个问题进行了更详尽的研究, 在他们的研究工作中, 将查询类型根据不同的量级进行了分组, 并对每一组查询进行建模分析。另外长事务在并行时可能会产生更加复杂的交互作用, 其调度算法也会完全不同。关于以上这些方面的工作都将作为以后重点关注的研究方向。
基于以上原因, 本文选择了这10个运行时间中等的查询类型作为本论文的研究对象, 每个查询类型可以根据需要生成不同的查询任务实例。
(1)两两并行时(MPL=2)
在MPL=2时, 为10个查询类型分别生成一个查询语句, 分别用ICMF算法、SJF算法和FCFS算法执行10个查询任务, 比较三种算法的性能。
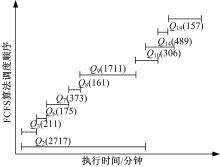
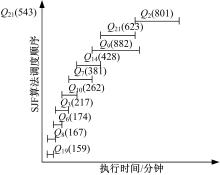
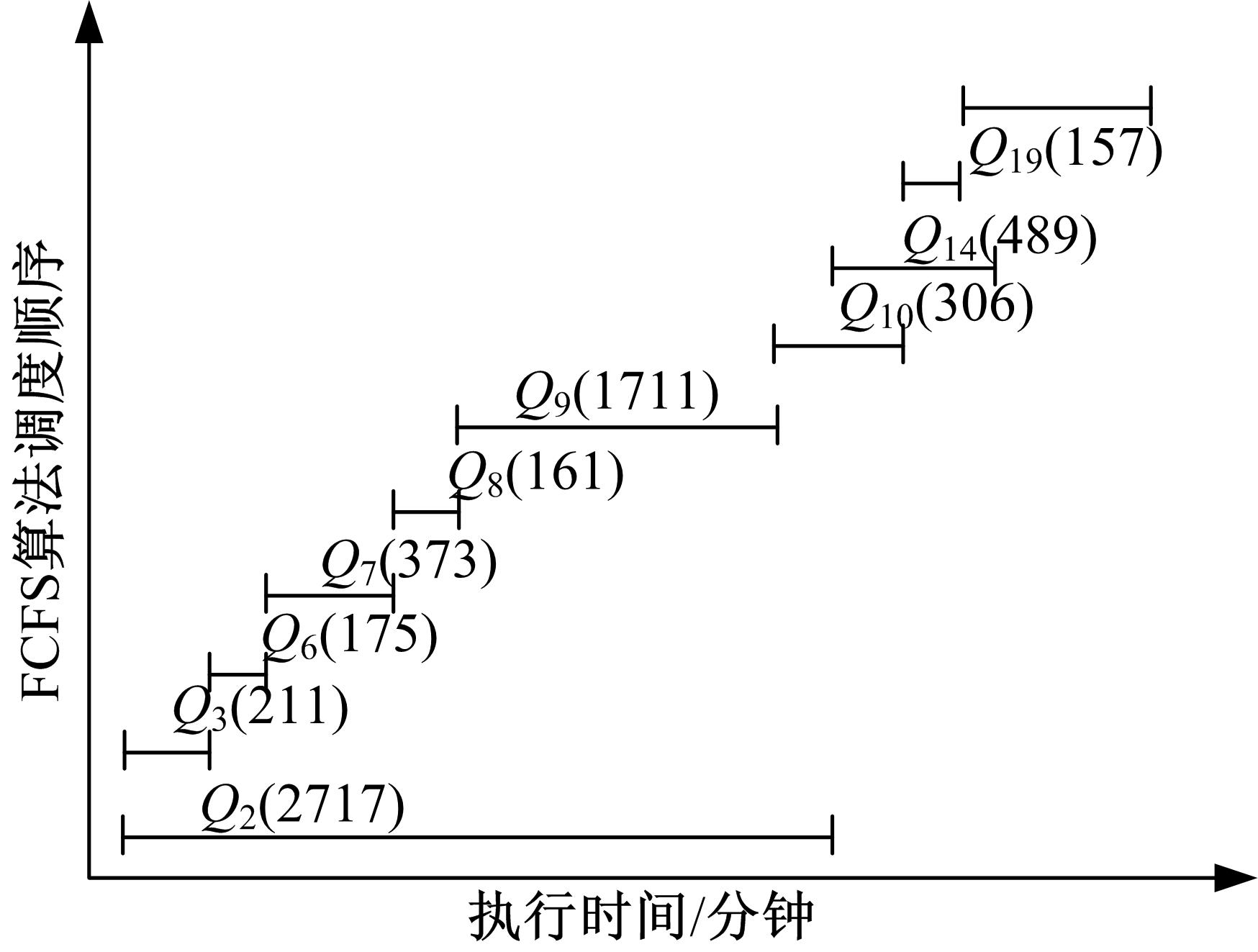
M=2时各算法并行执行时序图见图1, 图1中, 括号内数字表示执行时间。可以看出, 在M=2时, 各种算法执行过程中的调度顺序差别非常大, 而正是因为执行顺序的不同, 导致了查询之间不同的交互作用, 从而使整个负载的完成时间出现了较大的差异。
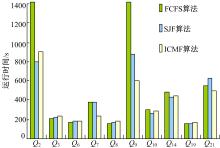
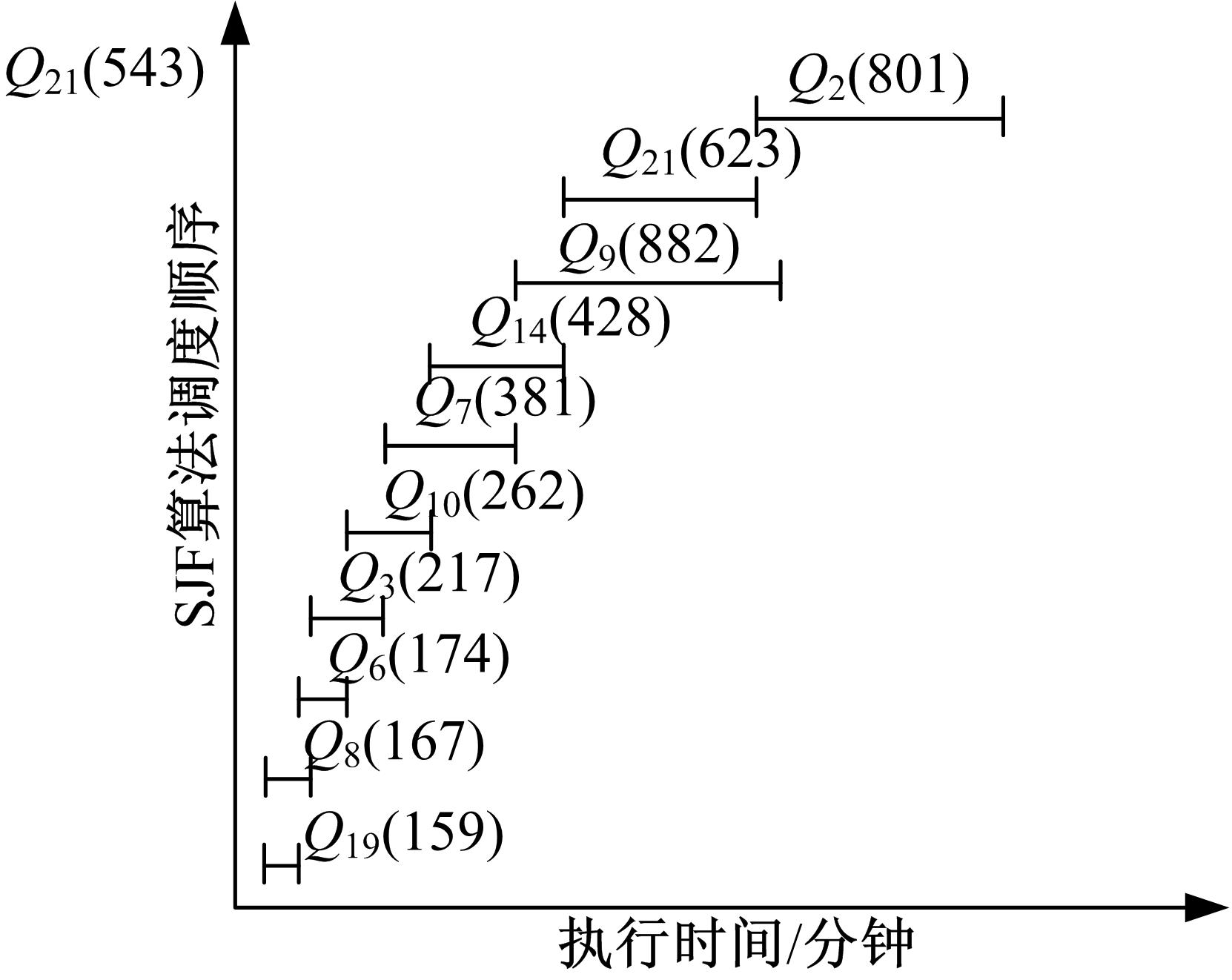
在图2中, 对各个查询类型实例在三种算法中的执行时间分别进行了比较, 可以看出在不同的算法中, 各个查询类型的执行时间变化也不尽相同, Q3、Q6、Q8、Q10、Q19相对来说变化差异比较小, 也就是说这些查询类型在并行时表现的更加平稳, 而Q2、Q7、Q9、Q14、Q21相对来说变化差异比较大, 这些查询类型对并行时产生的交互作用更加敏感。
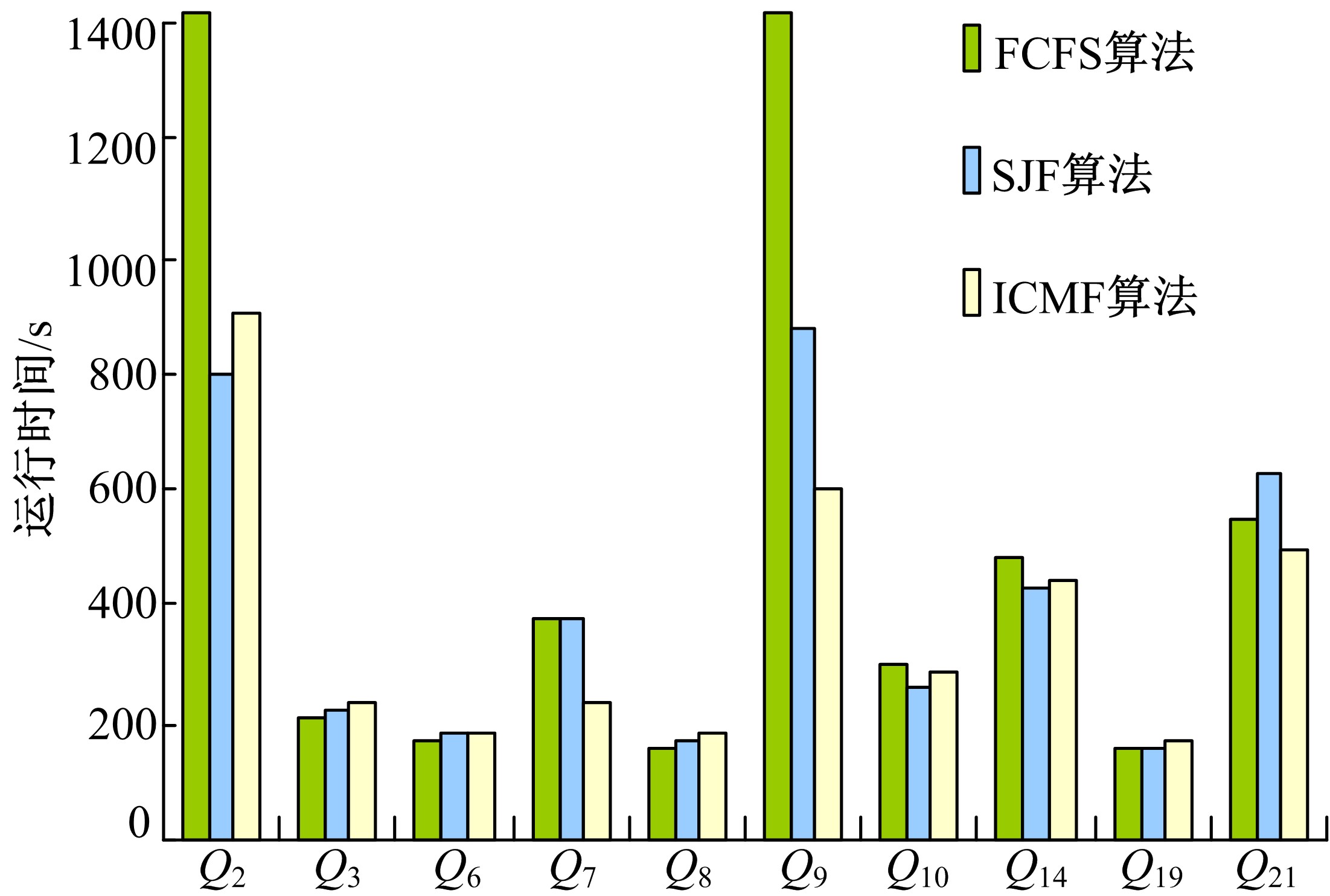 | 图2 各个查询类型在不同算法中的执行时间比较Fig.2 Completion time of each query template n different algorithms |
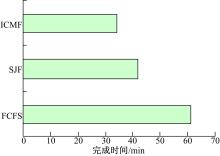
通过以上比较也可以发现, 在ICMF算法中正是因为多数的查询实例完成时间发生了较为积极的变化, 而使得整个任务的总完成时间最小。在实验中, 相同负载在三种算法中的总完成时间比较如图3所示。通过图3可以看出, 对于10个相同的查询任务, MPL=2情况下, ICMF算法比FCFS算法的运行时间提高了大约26 min, 比SJF算法的运行时间提高了约9 min。因此可以证明在并行级别为2的情况下, 考虑了并行任务之间交互作用的ICMF调度算法查询性能更好。
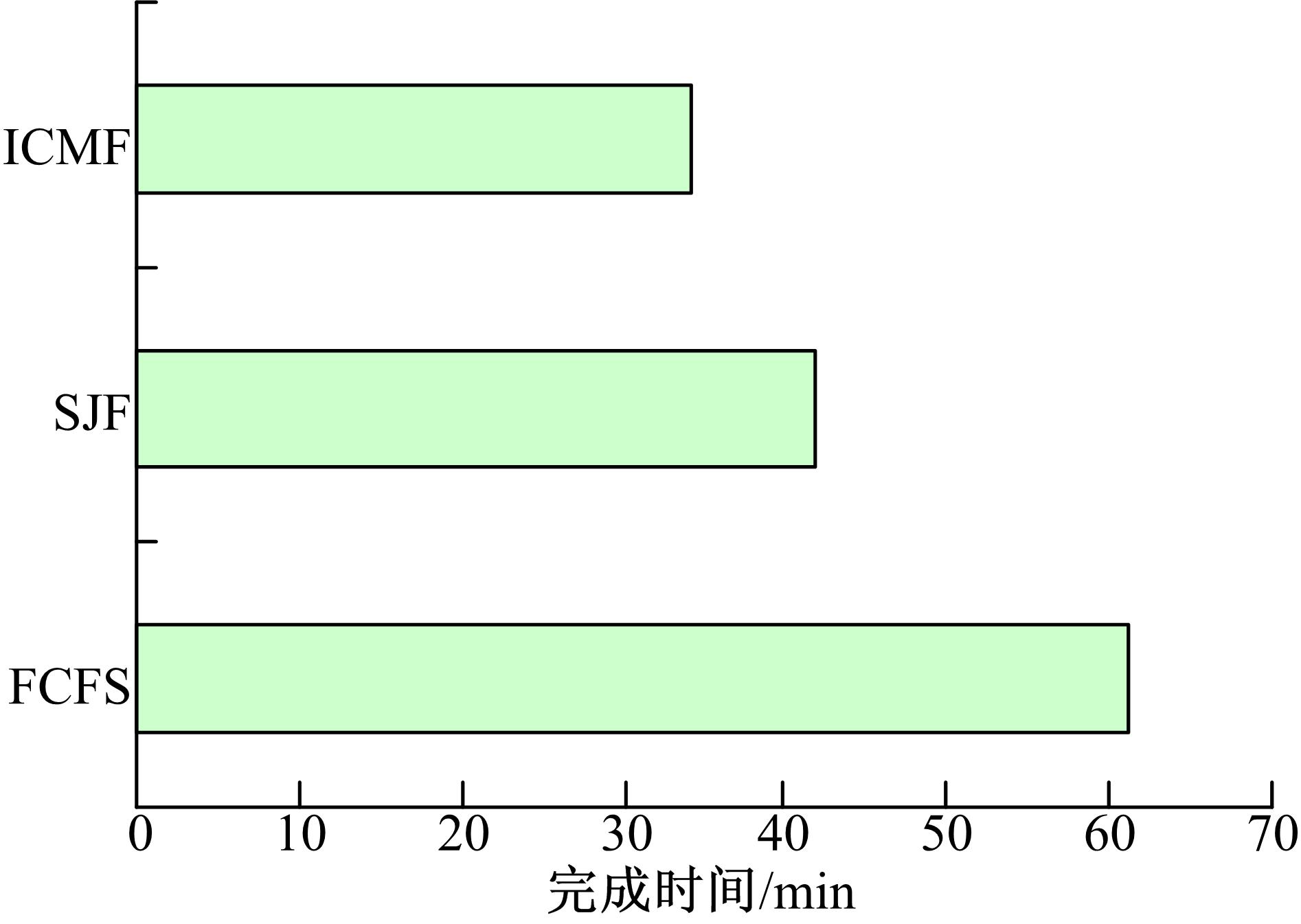 | 图3 相同负载用三种算法调度的总完成时间比较Fig.3 Total time of same work with different algorithms |
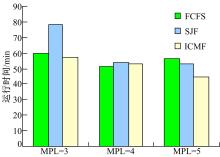
(2)高并行级别时(MPL> 2)
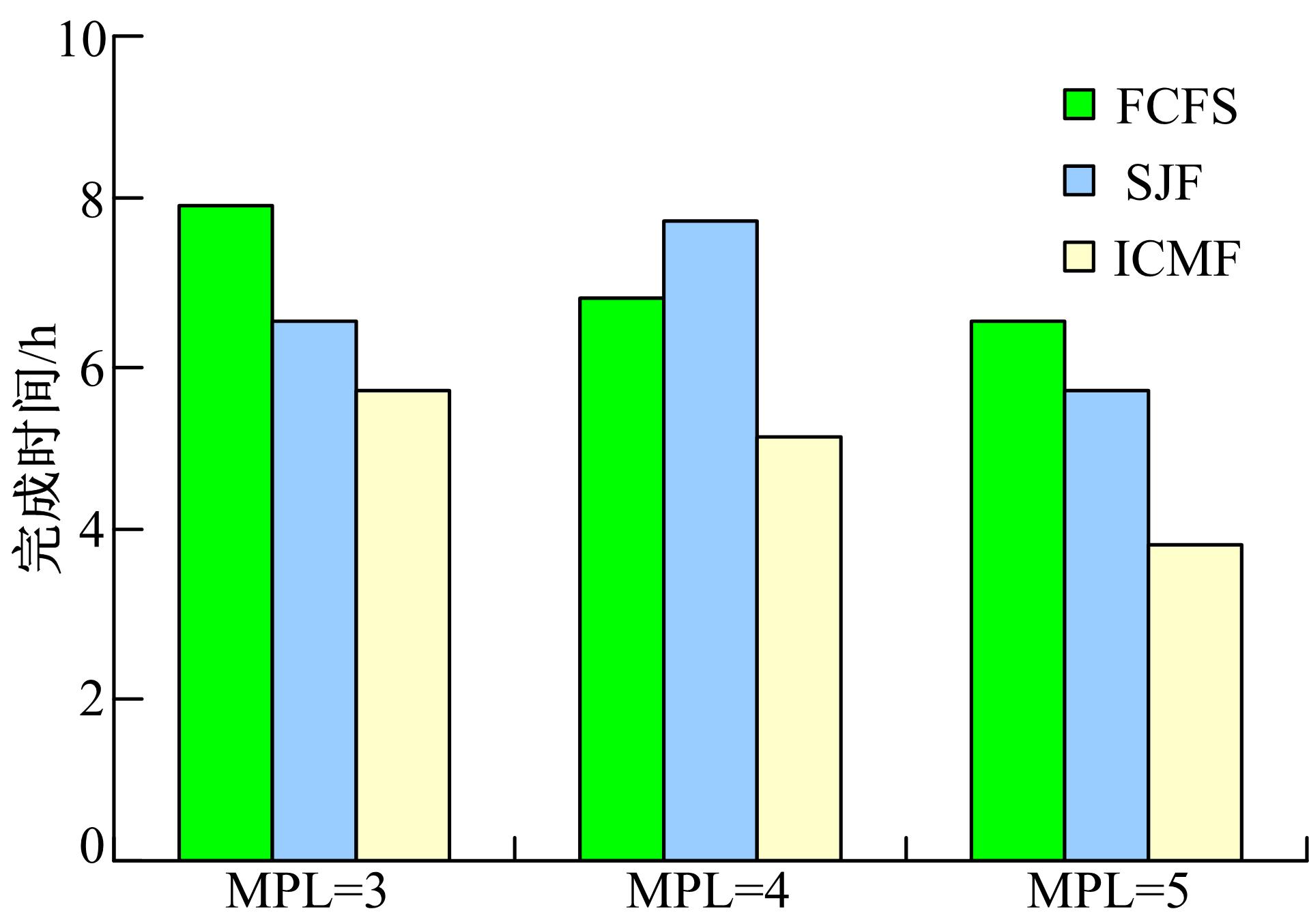
首先对10个查询任务的负载进行实验, 分别设置数据库的并行级别为3, 4, 5, 并在不同的并行级别分别使用ICMF算法、SJF算法和FCFS算法进行调度, 记录执行整个任务所花费的总时间。
在图4中可以看出, 在只有10个查询任务组成的负载情况下, 当MPL=3, 4, 5时, 各个算法执行情况下负载完成总时间差异不是很大, 这是因为负载数量较少, 不能很好地体现各个算法之间的优劣。
 | 图4 10个查询任务在不同MPL情况下的总完成时间Fig.4 Total time of 10 queries with different MPL |
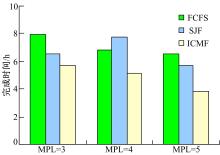
为了更好地分析高并行级别时的交互作用, 需要首先增加负载的数量, 为每个查询类型分别生成了6个查询语句实例, 总共60个查询任务实例。假设60个查询语句按照轮流加载1个查询类型实例的顺序到达, 调度工具可以预先知道即将到来的10个查询任务的类型。
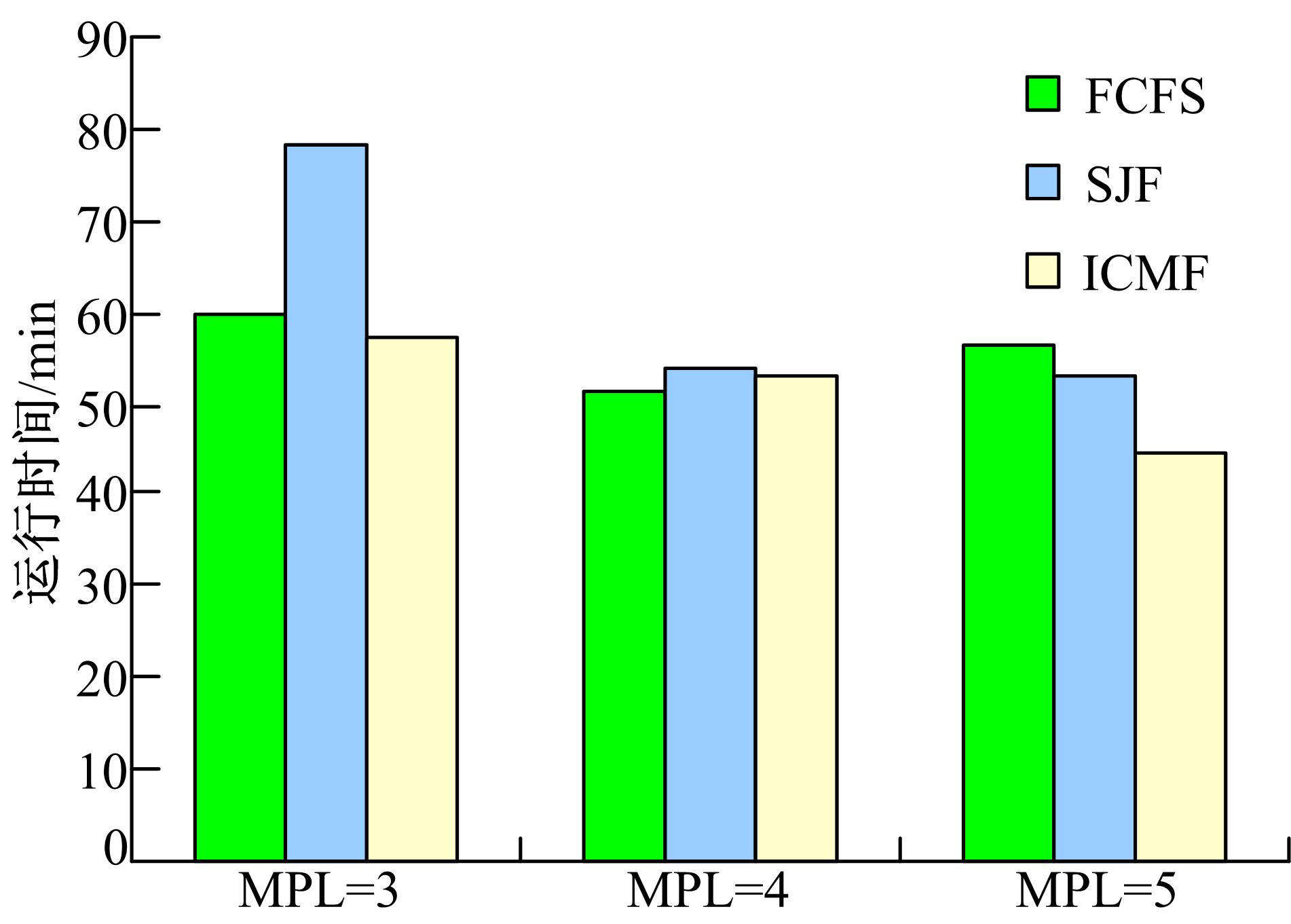
分别在不同的并行级别用三种算法进行调度, 每次调度时对即将到来的10个查询实例分别计算加入到正在运行的任务中所产生的交互成本IC, 选择交互成本最小的查询任务加入执行队列, 记录执行所有负载所花费的总时间。实验结果如图5所示。
 | 图5 60个查询任务在不同MPL情况下的总完成时间Fig.5 Total time of 60 queries with different MPL |
通过以上实验数据可以知道, ICMF算法与最短时间优先算法和先到先执行算法比较, ICMF算法能够较大幅度地提升系统性能, 通过消除并行查询之间的消极影响, 能够显著提高系统的吞吐率, 并且随着并行级别的提升, 其优势也更加明显。但同时伴随着并行级别的提升, 查询之间的交互作用也更加复杂, 因此下一步工作将对更高级别的并行查询交互进行实验和探索。
首先回顾了查询调度领域的相关研究工作, 在此基础上通过实验证明了并行查询之间的交互作用会对系统性能产生非常巨大的影响。因此, 在进行并行查询性能优化时考虑这些交互作用是非常有必要的。引入了一个并行查询负载的性能指标(IC)来度量查询之间的交互成本, 并提出了一个交互成本最低优先(ICMF)的调度算法, 通过本算法可以对数据库系统中的并行查询实现较为理想的任务调度。实验结果表明, 交互成本最小优先的调度算法是一种有效的任务调度算法, 比传统的查询调度方法在整体性能上有较为显著的提升。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|