









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于时空兴趣点的单人行为及交互行为识别
引用本文
王世刚, 孙爱朦, 赵文婷, 惠祥龙. 基于时空兴趣点的单人行为及交互行为识别. 45(1): 304-308
WANG Shi-gang, SUN Ai-meng, ZHAO Wen-ting, HUI Xiang-long. Single and interactive human behavior recognition algorithmbased on spatio-temporal interest point. Journal of Jilin University Engineering and Technology Edition, 45(1): 304-308
Permissions
WANG Shi-gang, SUN Ai-meng, ZHAO Wen-ting, HUI Xiang-long. Single and interactive human behavior recognition algorithmbased on spatio-temporal interest point. Journal of Jilin University Engineering and Technology Edition, 45(1): 304-308
Copyright©2015, 吉林大学学报编辑部
版权所有.吉林大学学报编辑部
基于时空兴趣点的单人行为及交互行为识别
作者简介:王世刚(1962-),男,教授,博士生导师.研究方向:多媒体通信,视频压缩,视频通信.E-mail:wangshigang@vip.sina.com
摘要
本文方法首先从视频中提取出代表足够运动信息的时空兴趣点,并通过人体前景剪影连通性分析判别时空兴趣点的点集范围。然后对每个视频的兴趣点样本进行高斯混合聚类生成时空单词。最后对时空单词进行训练得到每个行为的高斯混合模型用于人体行为的识别。该方法既可用于单人行为识别也可用于双人行为识别。在行为库上的实验结果证明了该方法有较高的正确率。
关键词:
通信技术; 人体行为识别; 时空特征点; 混合高斯模型
中图分类号:TN911
文献标志码:A
文章编号:1671-5497(2015)01-0304-05
Single and interactive human behavior recognition algorithmbased on spatio-temporal interest point
Abstract
First, spatio-temporal interest points containing enough human motion information are detected, and a set of spatio-temporal interest points are selected based on the information of connectivity of human silhouettes. Then, the GMM clustering is performed on the points in the training set and the spatial-temporal words are generated. Finally, these spatial-temporal words are trained to obtain the GMM of each behavior for human behavior recognition. This algorithm can be applied both to single behavior recognition and to interactive behavior recognition. Experiment results on activity database show that this approach has a satisfactory identification rate of human activities.
Keyword:
communication; human action recognition; spatio-temporal interest point; Gaussian mixture model
引言
人体行为识别是计算机机器视觉、模式识别研究领域的一个非常重要的研究方向[1, 2, 3], 近年来, 已经在视频监控、病人监控及人机交互等很多领域内得到广泛的应用。一般来说, 人体行为识别可以分为以下的几个基本过程:底层的特征提取和运动表征、简单动作识别; 高层的复杂行为和场景理解等[2]。
大部分研究在分析双人交互行为时都先分析单人原子行为, 再分析双人行为。例如Park等[4]采用贝叶斯网络识别单个人体部分的姿态, 然后建模单人原子行为, 最后创建描述交互行为的决策树。Ryoo等[5]将交互行为分为人体部分提取层、姿态层、单人动作层和交互行为层。韩磊等[6]将两人的交互行为识别分为底层采用概率图模型建模单人原子行为。本文认为, 双人交互行为同单人行为一样, 可以被看做是一个整体的行为, 在识别时不需要将两人单独进行研究, 所以本文提出一种将交互行为作为一个整体的人体行为的识别方法, 既可用于单人行为识别又可用于双人交互行为识别。最后, 通过实验验证了本文方法。
1 时空特征的提取
1.1 时空特征点的提取
在空间域内提取兴趣点有很多种方法, 比如比较常见的Harris角点检测方法[7]。该方法认为, 角点为图像中正交方向上梯度向量比较大的点。该梯度向量由以下公式获得:

式中: 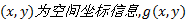
通常空域中的兴趣点只包含图像中的空域信息, 而没有图像的运动信息, 这对人体行为的特征表示而言是非常重要的。Laptev等[8]将Harris的角点检测思想扩展到了时域, 该方法认为, 时空角点是在 
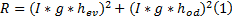
式中: 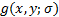
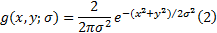


实验中, 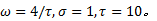
1.2 双人交互行为时空点集的选取
时空兴趣点可以正确地表示视频序列中具有明显运动的区域, 值得注意的是, 当两人进行双人交互行为时, 那些包含信息量最大的兴趣点通常是在两人有接触时, 即两个人体剪影区域 
设视频序列的时空兴趣点集为 

(1)视频序列中有两个互不连通人体剪影的区域 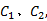
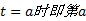
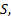
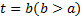
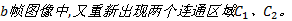
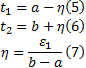
(2)若在整个视频序列中, 始终有两个互不连通的人体剪影区域C1、C2。这是因为某些交互行为比如挥拳或踢腿发生时会有闪躲发生, 两人并没有接触到。针对这种情况, 选取一个中心时间:
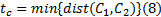
则可以得到:

式中: 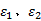
选取的时空兴趣点集时间轴上的范围为 
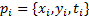
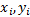
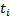
由式(7)可以看出, 

2 时空单词的生成及行为模型建模
高斯混合模型是一种聚类算法, 按一定的概率将样本划分给不同的类, 一般用于视频背景的生成及前景的提取。在本文中, 将其应用于时空兴趣点的聚类, 生成时空单词。再对时空单词进行聚类, 产生最终的高斯混合模型, 即行为模型的建模。
对于不同人的相同行为动作, 由于行为尺度的不同, 所得到的时空单词也会不同, 即高斯混合模型的聚类中心 
2.1 GMM及其参数估计
高斯混合模型的公式如下:
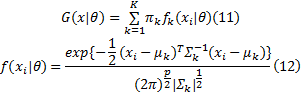
式中:参数 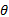
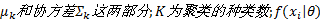
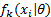

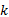
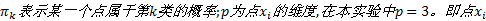
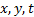
由于样本的分类即模型参数未知, 需要对高斯混合模型的参数进行估计, 这里采用EM算法对其进行估计。在GMM建模中, EM算法的公式为:
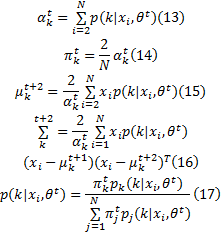
这样就得到了高斯混合模型中的各个参数。
2.2 时空单词的生成
由于时空特征点集里的点都是一些散乱无关的点, 所以需要对这些时空兴趣点进行统计, 生成时空单词。大部分研究者采用K-means聚类算法[3, 6]来对时空兴趣点进行聚类, 这种方法将点强硬地分配给各个聚类中心, 没有考虑其概率分布, 不符合实际情况。高斯混合模型是按一定的概率将点分配给各个聚类中心, 所以本文采用高斯混合模型对时空兴趣点进行聚类, 生成时空单词。为保证时空兴趣点的平移与缩放的不变性, 本文对所有时空兴趣点进行归一化。
归一化后的时空兴趣点集为:将 

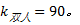
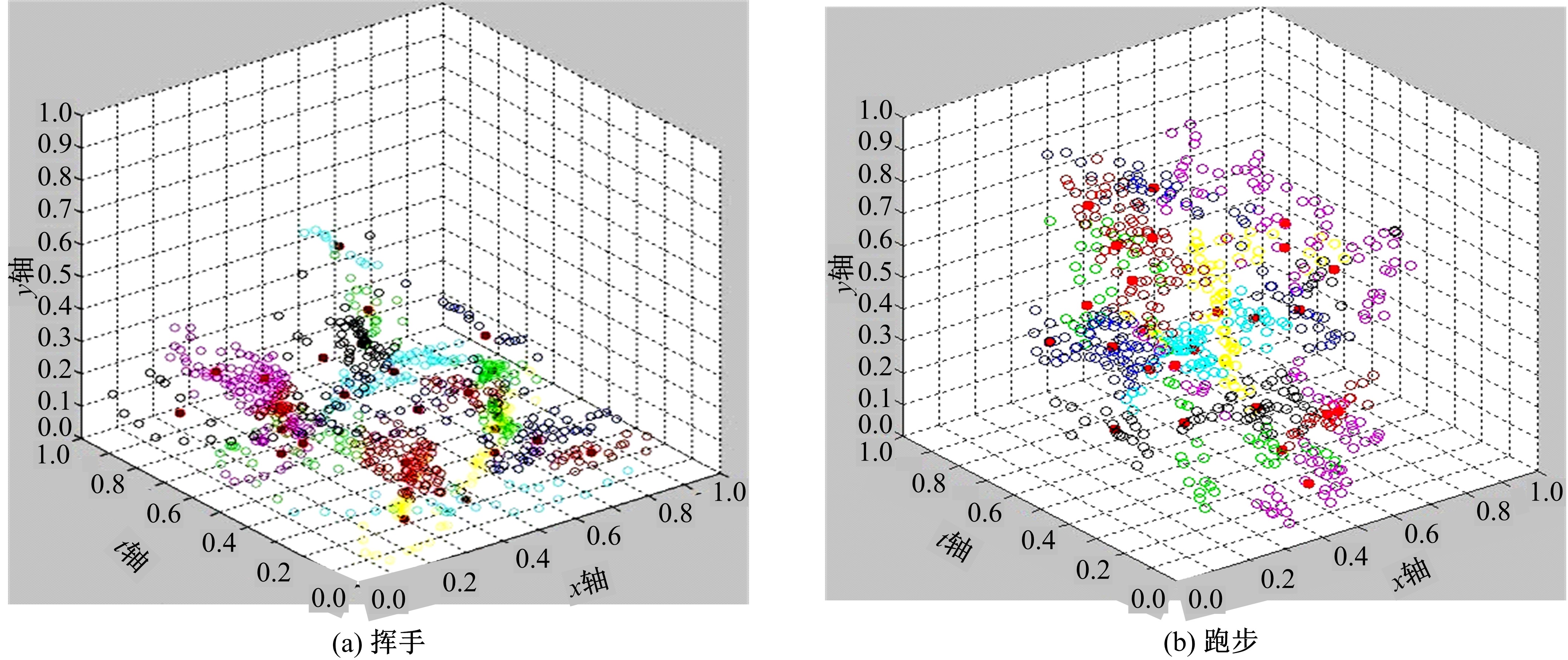
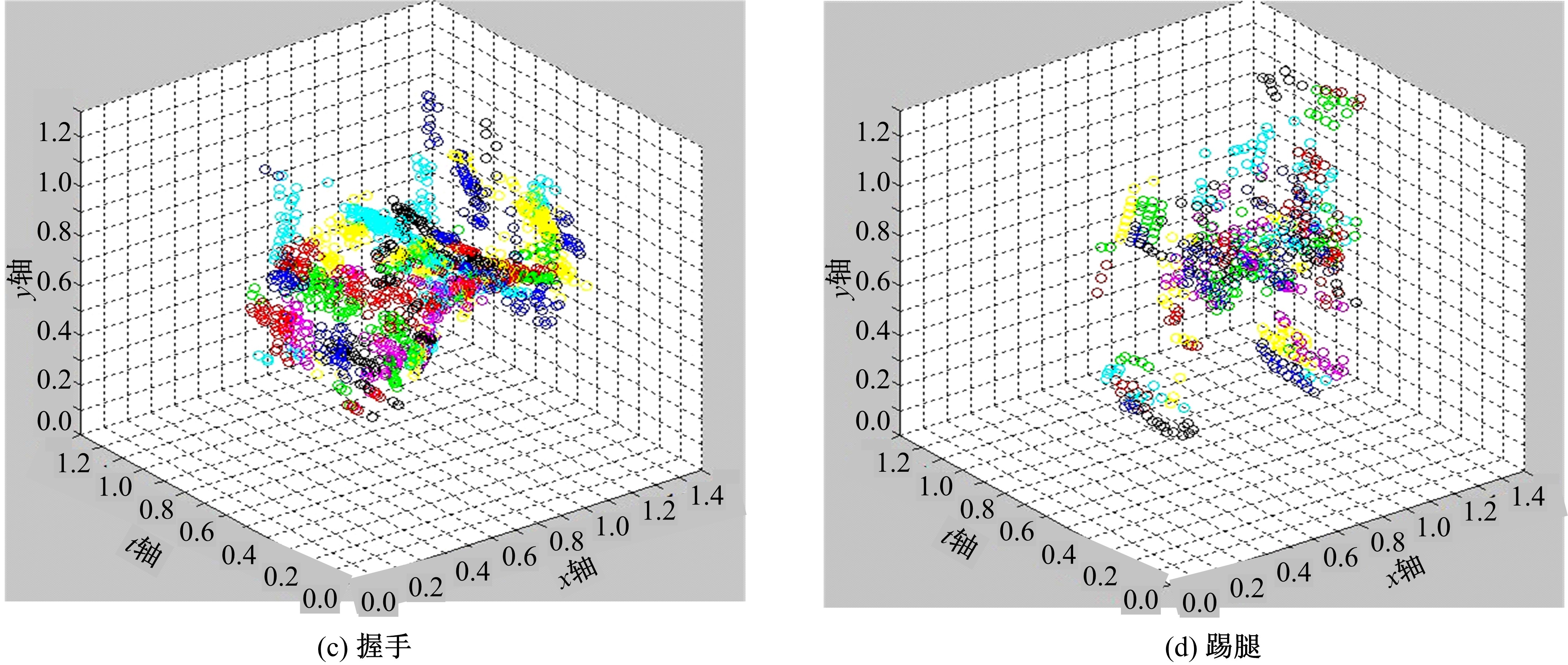
图2分别是挥手、跑步、握手、踢腿的时空兴趣点聚类结果及其聚类中心。
2.3 行为模型建模
得到行为库中所有的时空单词后, 要对其进行高斯混合模型训练。设行为库中某一行为的所有时空单词集为:
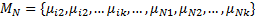
式中: 

对行为库内每种行为的 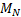
3 实验结果及分析
本文采用Weizmann行为数据库(单人行为), UT行为数据库(双人交互行为)及拍摄的若干单人行为和双人交互行为视频, 对本文算法进行测试及验证。单人行为有10种:bend(弯腰), jack(挥手+跳), jump(向前跳), pjump(原地跳), run(跑), side(横向步行), skip(单腿跳), walk(走), wave1(单手挥手), wave2(双手挥手)。双人行为有5种:拥抱, 踢腿, 挥拳, 握手, 推。在实验中, 每种行为都取公开行为库中的5个与自己拍摄的20个视频片段作为训练集, 用来训练高斯混合模型, 其余的视频片段作为测试集, 每种行为视频45个。表1、表2为实验结果。
由于本实验中, 只采用了时空兴趣点的坐标信息, 所以对归一化的要求比较高, 归一化的效果直接影响到实验结果的准确度。本文中归一化的结果依赖于前景的提取, 而双人行为时, 很难训练得到很好的背景, 以至于无法提取到很好的前景区域, 这是导致双人行为识别准确率不高的一个重要原因。
| 表1 单人行为检测结果 Table 1 Result of single behavior recognition |
| 表2 双人交互行为检测结果 Table 2 Result of interactive behavior recognition |
4 结束语
针对人体行为识别问题, 提出了一种基于时空兴趣点的高斯混合模型聚类信息的人体行为识别方法。该方法分三层:特征提取层, 特征表示层与行为表示层。通过提取视频中的时空兴趣点, 对其进行GMM聚类得到时空单词, 再通过训练得到时空单词的GMM模型来达到行为识别的目的。虽然本文方法双人交互行为识别正确率不高, 但是本文方法可以通用于单人与双人交互行为识别, 且比其他的双人交互行为识别方法减少了一个层次的分析, 使算法更为简洁, 并得到了较为理想的实验效果。由于本文方法只采用了时空兴趣点的坐标信息, 对归一化的要求较高, 需要较好的归一化结果以达到较高的识别正确率, 且需要大量的训练视频以提高训练得到的GMM模型的准确度, 并且本文没有考虑复杂场景或多组行为场景的情况, 这些都是我们下一步要解决的问题。
The authors have declared that no competing interests exist.
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|