

{kind=link}
{kind=link}
{kind=link}
基于频繁闭合序列模式挖掘的学生程序雷同检测
[王克朝1, 2  , 王甜甜
, 王甜甜2 , 苏小红2 , 马培军2 ]
, 王甜甜, 苏小红|
|


作者简介:王克朝(1980-),男,讲师,博士研究生.研究方向:程序分析,软件调试.E-mail:erickcwang@126.com
针对学生程序抄袭导致考核可信度降低而人工检测抄袭工作量巨大的问题,提出了程序雷同检测模型,首先通过词法分析将程序转换成token序列,并将其散列映射为数字序列;然后采用BIDE挖掘算法挖掘频繁闭合序列;在此基础上,识别相似代码片段,并计算程序之间的相似度,进而判定程序是否雷同。实验结果表明,与目前应用广泛的雷同程序检测工具MOSS相比,本文方法提高了雷同检测的准确性,不但可以准确地给出雷同统计信息,还能够较为直观地显示雷同代码片段。
Plagiarism in student programs is a common phenomenon, which decreases the credibility of assessment. However, manual detection loads a heavy burden on the teachers. To solve this problem, a plagiarism detection model is proposed. First, student programs are converted into token sequences through lexical analysis. Then, the token sequences are hashed to digital sequences. Then, the frequent closed sequences are mined by the BIDE algorithm. On this basis, the similar code fragments are detected and the plagiarism programs are identified by the calculated similarity. Experimental results show that, compared with the commonly used toll MOSS, the proposed method is more precise. It can not only give accurate statistical information of similar programs, but also explicitly display the plagiarized code fragments.
在计算机程序设计类课程教学中, 经常存在程序抄袭行为。被考核者抄袭他人程序后, 稍作修改甚至不做任何修改便作为自己的程序提交, 在一定程度上限制了考核准确性和效率, 降低考核成绩的可信度。如果采用人工方法去检测学生程序之间的雷同程度, 查找剽窃代码工作量巨大。
目前常用的程序雷同检测方法主要有两类:属性计数法[1, 2]和结构度量法[3, 4, 5, 6, 7, 8]。基于属性计数法的雷同检测计算每一个程序的n个不同的软件度量指标(如控制流、数据依赖、控制结构等), 以便于将程序映射到一个n维的笛卡尔空间, 然后考虑彼此邻近的程序组可能为剽窃。单纯的属性计数法抛弃了太多的程序结构信息, 导致检测结果的错误率很高。例如, 如果抄袭程序只有部分程序段是抄袭的, 或者修改了原程序中条件语句的结构, 则用属性计数法检测是失效的。基于结构度量法的雷同检测通过对程序的内部结构进行分析比较来判断其相似性。目前主流系统大多采用对表达源程序的字符串进行比较的方法, 如MOSS[9]等。这种方法考虑了程序的词法信息, 却没有考虑语义信息, 对多种变化都很敏感, 因此大多只能识别进行简单修改(如标识符重命名等)的剽窃代码。在使用MOSS的过程中还发现, 如果在学生程序中加入一些冗余的语句、声明冗余的变量或者拆分语句, 则会降低剽窃检测的准确性。
为了解决上述问题, 本文引入数据挖掘算法中的双向扩展频繁闭合序列模式挖掘(BI-directional extension based frequent closed sequence mining, BIDE)技术[10], 提出基于BIDE挖掘的学生程序雷同检测方法。
基于BIDE挖掘的学生程序雷同检测模型如图1所示, 具体实现步骤如下:
(1)将学生程序进行词法分析, 转化成token序列表示。为了能够识别修改过的雷同代码片段, 将所有类型相同的标识符(变量、函数名等)映射成相同的值, 不考虑它们实际的名字, 并将等价关键字统一表示。
(2)将步骤1中得到的token序列散列映射为数字序列。以基本程序块为单位将数字序列划分为若干段, 创建一个数字序列数据库, 以便将雷同代码检测问题转换成一个频繁序列模式挖掘问题。
(3)使用数据挖掘技术中的频繁闭合序列模式挖掘BIDE算法, 将支持度阈值设为2, 即查找在序列数据库中至少出现两次的频繁序列— — 这些频繁序列对应于源程序中完全匹配的代码片段。采用的挖掘算法允许序列中插入gap, 因此, 可以识别插入、删除或修改了语句的代码片段。
(4)计算程序之间的相似度, 进而判定是否是雷同程序; 同时对挖掘出来的程序中的雷同代码片段所在的行设置标志位, 根据标志位合并雷同代码片段, 分析出程序中对应的雷同代码。
(5)输出疑似雷同程序列表, 显示相应雷同代码。
散列处理把源程序经过词法分析生成的token序列的各个子串映射为比本身短得多的散列值, 相同的子串得到同样的散列值。采用“ hashpjw” 散列算法能够尽可能地避免不同子串产生相同的数字序列, 从而把字符串的匹配问题转换为整数的匹配问题, 进而通过BIDE挖掘算法挖掘出相同的数字序列。采用“ hashpjw” 散列算法得到的数字序列示例如图2所示。
 | 图2 采用“ hashpjw” 散列算法生成的数字序列实例Fig.2 Example of digital sequence mapped by “ hashpjw” |
BIDE是一种采用双向扩展策略频繁闭合子集挖掘方法。前向扩展用于增加前缀模式并检查前缀模式的闭包, 后向扩展用于检查前缀模式的闭包并通过剪枝缩小搜索空间。因此与其他同类方法相比更为高效。BIDE及其子算法描述如下所示。
Algorithm:BIDE(SDB, min_sup, FCS)
输入:序列数据库SDB, 最小支持度阈值min_sup
输出:频繁闭合序列集合FCS
1.FCS=⌀;
2.F1← 频繁1模式序列;
3.foreach 频繁1模式 f1 in F1
4. SDBf1← 为f1建立伪投影数据库;
5.foreach f1 in F1
6. 将f1作为前缀;
7. if(向后扫描不能将f1剪枝)
8. BEI← f1向后扩展事件的个数;
9. FCS← 调用bide算法产生闭合序列模式;
10.return FCS;
Algorithm: bide(Sp_SDB Sp, min_sup, BEI, FCS)
输入:投影序列数据库Sp_SDB, 前缀序列Sp, 最小支持度阈值min_sup, 后向扩展事件数BEI
输出:当前频繁闭合序列集合FCS
1.LFI← 扫描Sp_SDB找出Sp的本地频繁项;
2.FEI← Sp向前扩展项的个数;
3.if((BEO+FEI)==0)
4. FCS=FCS∪ {Sp}
5.foreach i in LFI
6.
7. SD
8.foreach i in LFI
9. 将
10. if(向后扫描不能将
11. BEI←
12. FCS← 递归调用bide算法产生闭合序列模式;
13.return FCS;
本文应用BIDE算法, 从已经生成的序列数据库中查找支持度大于等于2的频繁序列, 这些频繁序列与程序之间的雷同代码相对应。识别出的学生程序间的一个雷同代码片段组实例如图3所示(其中, SEQ表示代码片段的数字序列, LEN表示代码片段的长度, SUP表示代码片段的支持度, FilePath表示代码片段所在程序的路径, Lines表示代码片段在程序中的所在行, RELAL表示代码片段在原程序函数中的行数)。
 | 图3 BIDE算法挖掘出的雷同代码片段实例Fig.3 Example of similar code mined by BIDE |
程序相似度的计算公式定义如下:
式中:|A|和|B|分别为程序A和程序B中代码行数; A∩ B是经过BIDE挖掘算法后计算出的两个程序之间的相似代码行数; sim(A, B)是程序A和程序B之间的相似度值。
(1)统计每个源程序中的代码行数。
(2)计算程序之间相似代码的行数:对程序中的每行相似代码设置标志位, 若该行相似代码已经出现过, 则跳过处理, 否则继续处理, 从而得到程序中所有不重复出现的相似代码。
(3)计算程序之间的相似度, 查找程序之间对应的雷同代码:若计算出的sim(A, B)高于预定的阈值, 则认为程序A和程序B是雷同程序。
(4)排序算法:经过上述步骤(1)(2)(3)之后, 根据得到的程序之间的相似度, 按降序排序算法进行排序, 得到由高到底的雷同程序列表。
(5)输出雷同程序列表和相对应的雷同代码。
为了测试本文方法的检测效果, 选择5个实际的学生作业题目。这些程序已被第三方授课教师采用人工检测的方式确认了其中的雷同程序组。然而由于实际剽窃的程序组数有限, 本文还采用了人工注入的方式, 对每组题目由授课教师模拟学生常见的抄袭方式, 在已有程序的基础上进行修改, 如标识符重命名、插入和删除部分语句, 生成新的雷同程序组。最后将原程序和人工注入的程序集合统称为人工检测集合, 作为本实验的基准测试集, 如表1所示。分别采用MOSS和本文方法对每组程序进行雷同检测, 统计检测结果的误检率和漏检率。
| 表1 基准测试集 Table 1 Benchmark |
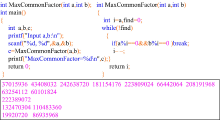
图4标注出来的代码为系统检测出的两程序之间对应的雷同代码, 雷同度为91.25%。
雷同检测结果的误检率和漏检率计算公式如下:
误检率=
漏检率=
式中:绝对值符号表示检测出的雷同程序组数; |系统检测∩ 人工检测|表示系统检测出基准测试集合中所提供的雷同程序组数。
根据实际经验, 由于初学者在程序设计时具有类似的实现思路, 并且常常需要使用指定的语法结构, 因此程序会存在一定的相似性。一般相似度为70%以下的程序组是雷同程序的可能性比较小。即使这些程序中可能存在剽窃, 也是经过了较大的修改, 加入了抄袭者自己的思考。因此, 本文重点分析MOSS和本文方法输出的相似度大于70%的雷同程序组, 结果如表2所示。表中∩ 表示|系统检测∩ 人工检测|。
由表2可以看出:两种方法对于相似度较高的代码均具有较高的准确性。对于相似度80%以上的雷同程序组的误检率为0。但是在实验中本文方法和MOSS均出现一次误检, 误检的两个程序比较类似于修改了的雷同程序, 而实际中是由相似的编程思路和编程风格导致的。对于这种相似度不是很高的雷同程序组而言, 教师最好进一步确认是否真正是雷同程序。但是对于相似度70%~80%的雷同程序组而言, 大多情况下是对抄袭程序进行了修改, 本文方法具有较低的误检和漏检。这是因为本文方法是在词法分析生成的token序列的基础上进行分析和BIDE挖掘的, 可以有效检测各种标识符重命名、插入和删除了部分语句的雷同代码片段。
 | 图4 检测出的一组雷同程序实例Fig.4 Example of plagiarized programs |
| 表2 本文方法与MOSS的误检率和漏检率 Table 2 False positive rate and false negative rate of our method vs MOSS |
(1)提出了基于频繁闭合序列模式挖掘的学生程序雷同检测方法。在词法分析的基础上, 将学生程序映射为数字序列, 进而应用数据挖掘技术中的频繁闭合序列模式挖掘BIDE算法检测雷同代码片段。该方法不但可以准确地给出雷同程序的统计信息, 还能够较为直观地显示雷同代码片段。
(2)通过检测实际的学生程序, 证明本文方法可以有效检测各种标识符重命名、插入和删除了部分语句的雷同代码片段, 因此与MOSS工具相比, 本文方法具有较低的误检率和漏检率。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|