{kind=link}
基于查询转换的RDF高效查询方法
[佟强1  , 程经纬
, 程经纬2 , 张富2 , 张丽丽2 , 马宗民2 ]
, 程经纬, 张富|
|


作者简介:佟强(1975-),男,讲师,博士.研究方向:本体,数据库.E-mail:tongq@swc.neu.edu.cn
为实现RDF的高效查询,提出了一种基于SPARQL到SQL查询转换的RDF查询处理方法。给出了SPARQL图模式到SQL查询的转换规则,以及SPARQL查询到SQL查询的转换规则。建立了SPARQLtoSQL实验系统,通过对实验结果分析,证明了实验系统的可行性、正确性以及有效性。
To achieve efficient Resource Description Framework (RDF) querying, an approach of translation of Simple Protocol and RDF Query Language (SPARQL) into Structured Query Language (SQL) is proposed. The translation rules of SPARQL graph patterns to SQL queries, and SPARQL queries to SQL queries are provided. An experimental system called SPARQLtoSQL is implemented. The experimental results are analyzed, which demonstrate the feasibility, correctness and effectiveness of the system.
语义Web的核心是通过为Web资源添加能够被计算机理解的语义元数据, 使Web成为一个通用的信息交换媒介。资源描述框架(RDF, Resource description framework)是语义Web资源标注的推荐标准[1]。现有的大部分RDF管理系统都采用DBMS来存储和管理RDF数据。这样, 就可以利用关系数据库成熟的数据查询和优化技术来达到高效查询RDF数据集的目的。RDF的标准查询语言是SPARQL[2](Simple protocol and RDF query language), 而关系数据库的标准查询语言是SQL, 因此需要将SPARQL查询转换为SQL查询。
Kiminki等通过在SPARQL语言与SQL语言中间定义了一种新的过渡性语言AQL, 实现了SPARQL查询到SQL查询方法实现[3]。这类方法由于需要定义中间语言, 并且需要进行两次语言的转换, 所以相对复杂、费时。采用直接映射转换的方法相对较多, Chebotko等[4]通过研究SPARQL查询的匹配原理, 推理出了三元组图模式匹配原理的SQL表示, 提出了SPARQL查询中不同图模式到SQL查询的转换实现方法, 该方法采用的主要思想是对基本图模式实行边转换边查询的策略, 并且一个SPARQL查询中的多个图模式之间采用顺序处理的方式完成。Elliott等人在文献[4]的基础上提出了全面转换SPARQL到SQL的算法[5], 实现了包含在SELECT查询模式内大部分查询到SQL查询的转换, 与文献[4]不同的是, 该方法不是顺序处理每个基本图模式, 而是采用类似树模型存储关系操作符, 递归完成FlatSPARQLtoSQL实验系统的设计。国内浙江大学的Zhou等通过重写用户提供的SPARQL语义查询, 提供更多的查询信息, 由此提出了重写后的SPARQL查询到SQL查询的实现方法[6]。吴涛等对SPARQL查询机制进行了分析, 基于图模式的实现方式提出了语义Web查询语言的转换方法, 但转换范围只限于图模式的转换, 不能接受SELECT之外的其他查询模式[7]。雷云飞等通过在关系表之间添加键值约束联系, 使关系表具有一定语义, 进而分析关系表的查询与SPARQL查询的联系, 但是并没有给出SPARQL语言到SQL语言的转换方法和规则[8]。王进鹏等[9]给出了图模式关系代数与SQL语句之间的转换方法。该方法需要首先将SPARQL转换为关系代数, 再执行关系代数到SQL的转换。此外, ASK和DESCRIBE等其他查询形式的转换还没有实现。
本文提出的查询转换方法采用了一次转换后再执行的策略, 能够有效地降低查询转换的时间, 提高执行效率。此外, 包含了不同的查询模式和图模式, 扩展了可接受查询的范围。
从形式上看, 一个SPARQL查询一般由五部分组成:声明、查询形式与结果集、数据集、图模式和结果修饰。
声明:将一个用IRI表示的资源缩写成一个简单的命名空间的形式, 目的就是为了方便标记和节省存储空间。这部分在查询转换中并不涉及。
查询形式与结果集:SPARQL包含四类查询模式SELECT、CONSTRUCT、ASK和DECRIBLE, 模式匹配的结果形成结果集或RDF图。
数据集:在SPARQL查询中, 采用FROM子句和FROM NAMED子句对数据集进行描述。数据集中可以包括一个没有名字的默认图, 以及零个或者多个通过URI进行识别的具名图。
图模式:SPARQL查询基于图模式匹配实现[10], 最简单的图模式是三元组模式, 类似于RDF三元组, 但主语、谓语或宾语位置允许出现变量。复杂图模式包括:基本图模式、组图模式、可选图模式和多图模式。
结果修饰:结果修饰符能够影响查询的返回结果, 使查询在作用范围的广度和作用效果的程度上都有显著增强。
例1 给定一个图模式为三元组模式的SPARQL查询:
01 SELECT ?name
02 FROM < http://example.org/foaf/aliceFoaf>
03 WHERE {?x name ?name.}
转换为下面的SQL查询:
SELECT tri_1.o
FROM Triple AS tri_1
WHERE tri_1.p=“ name” AND tri_1.res=“ http://example.org/foaf/aliceFoaf”
SELECT:SPARQL中SELECT关键字之后跟随的是变量名集合, SQL中则是属性列集合, 需要将这两种名字在形式上进行转换。这里定义函数label(?a)为SPARQL查询中变量?a的名字到SQL属性列名的映射。在得到的SELECT列选择中需要指定属性列来自于哪个具体的关系表, 如例1中name属性列来自于关系表tri_1。
FROM:SQL中FROM关键字后给出的是查询数据所在的源表, 可以包含关系表的别名形式, 例1中为Triple表分配了别名tri_1。本文中所有的三元组都存储在一个关系表中, 所以在进行每一步的查询操作时, 都需要对关系表进行分配别名操作, 避免直接修改源数据。
WHERE:SPARQL查询中WHERE中包含的是RDF三元组需要满足的图匹配条件集合。SQL查询中WHERE后面是检索记录需要满足的条件集合。例1中SPARQL查询中出现的WHERE条件约束{?x name ?name.}, 转换到SQL查询的形式为:{tri_1.p=” name” AND tri_1.res=” http://example.org/ foaf/aliceFoaf” }。
可以看出, 在转换过程中将SPARQL三元组图模式中的常量术语转换成了SQL查询中的关系属性列值的约束条件, 并且将原SPARQL查询的FROM转换到了对SQL关系表属性列res的值约束上。所以, SQL查询中的WHERE约束条件主要根据SPARQL查询中FROM中规定的RDF图约束以及WHERE中的图模式匹配条件生成。
基本图模式是三元组图模式的有限集合。对于包含在WHERE约束条件中的SPARQL三元组图模式进行SQL转换, 主要是对其中的各个项(sp, op, pp)进行分析, 根据项是常量还是变量分别给出不同的处理策略。此外还要判断在SPARQL查询中是否给定了RDF图的限制。
项为常量:这时需要针对该位置的属性列名添加是约束条件到生成的WHERE约束条件中;
项为变量:这时需要比较该项与其他项是否相同, 如果相同, 则在生成的WHERE约束条件中添加相应位置属性列名的等值约束;
含有对RDF图的限制:这时需要在WHERE条件集合中添加res等于相应RDF图URI的属性值约束条件。
下面给出函数genWhere(tp, G)。该函数根据对SPARQL查询中三元组图模式的形式进行分析, 形成SQL查询中WHERE约束条件的表达式。其具体实现如下:
函数:genWhere(tp, G)
输入:三元组图模式tp(sp, pp, op), RDF数据集G
输出:SQL查询WHERE条件约束
01 初始化where=” ” , alias=tri_(++i)
02 if tp.spÏ var
03 then where+=“ And ” +alias+“ .s=tp.sp”
04 if tp.ppÏ var
05 then where+=“ And ” +alias+“ .p=tp.pp”
06 if tp.opÏ var
07 then where+=“ And ” +alias+“ .o=tp.op”
08 if tp.sp = = tp.pp
09 then where+=“ And” +alias+“ .s=” +alias+“ .p”
10 if tp.sp==tp.op
11 then where+=“ And” +alias+“ .s=” +alias+“ .o”
12 if tp.pp=tp.op
13 then where+=“ And” +alias+“ .p=” +alias+“ .o”
14 where+=“ And (”
15 for each g in G
16 where+=“ OR” +alias+“ .res=g”
17 where +=“ )”
18 return where
在genWhere(tp, G)的函数实现中, 分别对上述三种情况进行了分析, 并对where值进行了相应的条件添加。在第02到07行中, 处理了第一种情况, 分别对图模式中的每个常量项进行判断, 并对where添加属性值约束条件; 在第08到13行中, 处理了第二种情况, 分别判断了三元组中任意两个变量项相同的情况, 并在where中添加了属性列间的约束条件; 在第14至17行, 对SPARQL查询中指定RDF图的情况进行了处理, 在where条件中添加了属性列res的值约束条件。在形成的where条件表达式中每个项约束条件都是以AND为连接, RDF图约束之间用OR连接。
根据以上的分析进而提出只包含基本图模式的SPARQL查询到SQL的转换方法, 现定义一个函数trans(m, G)以实现该功能。该函数对基本图模式的构成进行分析, 并将其转换为SQL查询。
函数:trans(bgp, G)
输入:基本图模式bgp, RDF数据集G
输出:SQL查询
01 初始化select=“ ” , from=“ ” , where=“ ” , first=true
02 for each ?a in bgp
a)if first==true then first=false else select+=“ , ”
b)select+=label(?a)
03 from+=“ Triple AS” +tri_i
04 for each tp in bgp
05 where+=genWhere(tp, G)
06 return query=“ SELECT” +select+“ FROM” +from+ “ WHRER” +where+ “ AS T_” +(++j)
SQL查询的结构是“ SELECT+FROM+WHERE” 形式, 所以trans函数要实现这三个基本结构的生成。在该算法中, 第02行生成SELECT语句, 第03行生成FROM子句, 为要查询的数据表分配别名, 第06行将genWhere(tp, G)产生的约束条件添加到生成的SQL查询中。
这里用m表示复杂图模式, 将其表示为子模式连接形式为m.leftchild op m.rightchild, 其中op可以为AND、OPT和UNION, 分别代表组图模式、可选图模式和多图模式。
复杂图模式分解的基本思想是:首先分别对复杂图模式中每个子模式进行转换, 得到相应的SQL子查询, 然后根据子模式之间的逻辑关系, 将子查询结果按照不同的连接形式添加到最终的FROM源表约束中。
2.2.1 组图模式到SQL语言的转换
满足组图模式的每一个结果必须对该组图模式内的每个基本图模式都匹配成功。假定r为存储RDF数据集的关系表中的一条记录。对于任意满足trans(m.leftchild AND m.rightchild, G)的记录r, r必定同时满足trans(m.leftchild, G)和trans(m.rightchild, G)。在关系代数中, 这种同时满足的关系可以用表之间的内连接来表示。
具体地说, 首先转换子模式, 得到SQL查询trans(m.leftchild, G)的结果集合R1和trans(m.rightchild, G)的结果集合R2; 然后根据m.leftchild和m.rightchild之间的AND关系, 对结果关系表R1和R2进行内连接操作。
下面给出组图模式到SQL转换的函数trans(m, AND, G)。连接条件设定为“ TRUE AND(m.leftchild.a=m.rightchild.a OR m.leftchild.a is null OR m.rightchild.a is null)” , 其中“ m.leftchild.a=m.rightchild.a” 代表两个关系表之间的自然连接条件, “ m.leftchild.a is null” 代表的是当m.leftchild中含有可选图模式时, 变量?a未被绑定的情况。
函数:trans(m, AND, G)
输入:组图模式m, RDF数据集G
输出:SQL查询
01 query+=“ (” +trans(m.leftchild, G)+“ INNER JOIN” +trans(m.rightchild, G)
02 first=true
03 for m.leftchild与m.rightchild的相同属性列a
04 if first=true
05 then first=false
06 else query+=“ AND (m.leftchild.a= m.rightchild.a OR m.leftchild.a is null OR m.rightchild.a is null)”
07 query+=“ ON TRUE”
08 query+=“ ) AS T_” +(++j)
09 return query
2.2.2 可选图模式到SQL语言的转换
可选图模式由OPTIONAL子句构成, 其功能是对OPTIONAL子句内的图模式可选匹配, 如果匹配失败, 就用NULL来代替变量绑定。在关系代数中, 这种选择的概念可以用左连接体现。
可选图模式中包含着两类OPTIONAL子句, 一类是平行OPTIONAL子句, 一类是嵌套OPTIONAL子句。
嵌套OPTIONAL子句是指在一个OPTIONAL子句中还包含至少一个OPTIONAL子句。嵌套OPTIONAL子句的转换方式为:先使用基本图模式进行查询, 然后再将得出的关系表与整个嵌套OPTIONAL子句的查询结果进行左连接操作。
下面分析平行OPTIONAL子句, 如例2所示。
例2 (平行OPTIONAL子句)给定一个包含平行OPTIONAL子句的SPARQL查询如下:
01 SELECT ?a, ?n, ?ew
02 WHERE {
03 {?a name ?n.}
04 OPTIONAL{?a email ?ew.}
05 OPTIONAL{?a web ?ew.}
06 }
此查询共包含三个基本图模式gp1、gp2、gp3, 分别在第03、04、05行内。对应的图模式查询结果分别为:R1(a, n), R2(a, ew), R3(a, ew)。
首先, gp1与gp2的查询结果合并表示为:
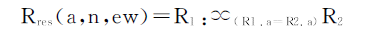
然后进行Rres与R3的连接, 其连接条件分为两种情况:
(1)如果共享变量在Rres中已经绑定, 则R3中同一变量必须绑定相同的值。
(2)如果共享变量在Rres中未被绑定, 即值为NULL, 则R3可以对该变量进行任意值的绑定。
根据以上的分析, 可以将Rres与R3的连接表示为:Rres(a, n, ew)=

因为在Rres与R3之间存在着两个相关联变量?a和?ew。在Rres中变量?a必须绑定, 所以在连接条件中需判断Rres.a=R3.a。第04行可选图模式中变量?ew如果未被绑定(Rres.ew is NULL), 则在第05行的可选图模式中进行绑定操作。
根据以上对各种情况的分析, 给出OPTIONAL子句到SQL的转换函数trans(m, OPT, G)。
函数:trans(m, OPT, G)
输入:组图模式m, RDF数据集G
输出:SQL查询
01 query+=“ (” +trans(m.leftchild, G)+ “ LEFT OUTER JOIN” +
02 trans(m.rightchild, G)
03 first=true
04 for m.leftchild与m.rightchild的相同属性列a
05 if first=true then first=false else query+=“ AND (m.leftchild.a= m.rightchild.a OR m.leftchild.a is null OR m.rightchild.a is null)”
06 query+=“ ON true”
>07 query+=“ ) AS T_” +(++j)
08 return query
该转换方法的原理是:首先利用trans(m, G)将m.leftchild和m.rightchild转换为SQL查询; 然后利用关系代数中左连接操作上述SQL查询的结果表。如果m.leftchild与m.rightchild中存在相同的变量属性列a, 则m.leftchild: m.rightchild的连接条件为“ m.leftchild.a=m.rightchild.aÚ m.leftchild.a is NULLÚ m.rightchild.a is NULL” 。
2.2.3 多图模式到SQL语言的转换
多图模式中子模式之间由UNION关键字连接, 表示满足任一子模式的查询结果都是多图模式的查询结果。文献[4]为解决UNION多图模式到基本图模式的方法, 引入了操作符。该操作符对结果关系表的操作用关系代数的形式表示如下:
R1∪ R2=(R1:
在处理多表连接操作时, 连接条件设定为false, 目的是只进行两表属性列的合并, 属性值不参与表的合并, 使得生成两个关系表的属性结构相同, 能够直接执行SQL中的UNION操作。该处理方法可以用函数trans(m, UNION, G)表示。
函数:trans(m, UNION, G)
输入:组图模式m, RDF数据集G
输出:SQL查询
01 query+=” ((” +trans(m.leftchild, G) +” LEFT OUTER JOIN ” +trans(m.rightchild, G) +” On (false))” +” UNION(” +trans(m.rightchild, G)+” LEFT OUTER JOIN ” +trans(m.leftchild, G) +” On (false))” +” AS T_” +(++j)
02 return query
SPARQL语言包含多个结果修饰符和查询模式, 影响结果返回的形式和顺序。在转换过程中, 需要将这些结果修饰符和查询模式映射到SQL语言中相应的关键字。
3.1.1 相同关键字结果修饰符的映射
SPARQL中结果修饰符DISTINCT、ORDER BY、LIMIT n和OFFSET m在SQL中同样存在, 且用法和功能相同, 因此可以直接映射。当SPARQL查询中出现这些关键字时, 在SQL查询中SELECT关键字后添加该关键字即可。
3.1.2 FILTER到SQL的映射
FILTER(expr(r))实现对结果集的限制, 只有使expr(r)为真的数据记录或者三元组才可以在结果集中表现出来。其中的布尔型表达式expr(r)会涉及到很多方面, 包括逻辑符号(Error! Objects cannot be created from editing field codes.), 数字运算符号(< , ≤ , ≥ , > , =), 一元运算符包括bound, isIRI和一些其他运算符等。
当SPARQL查询中出现FILTER关键字时, 只需在转换后的SQL查询的WHERE条件集合中添加FILTER内的限制条件即可。当变量出现在关系表中时, 在WHERE中添加对变量值的约束。另外需要考虑的是其中涉及到的数据类型的转换, 以及String字符串的转换和比较操作。
在转换中需要以下几个替换规则:将变量var用变量名代替, 如?a的变量名为a; 文字型和URI都转换为字符型, 数值型转换成” l” 型; 逻辑运算符Ø 、Ù 和Ú 分别替换成NOT、AND和OR; expr为“ bound(?x)” 替换成“ x is not NULL” 。
SPARQL查询语言中包含着四种查询模式:SELECT、CONSTRUCT、DESCRIBE和ASK。
3.2.1 SELECT查询模式转换方法
首先定义包含SELECT查询模式的SPARQL查询Q={Ssel, G, Tree}, 其中Ssel表示查询变量集合; G代表SPARQL查询中指定的RDF图; 参数Tree就是包含了所有图模式和限定约束条件的SPARQL结构树的根节点。
SELECTtoSQL算法的主要思想是:根据WHERE中包含的图模式, 分别对每个图模式进行转换, 得到相应的SQL子查询, 然后根据各个图模式之间的逻辑关系, 将得到的SQL子查询按照不同的连接形式添加到最终的FROM源表约束中。
算法:SELECTtoSQL
输入:SPARQL查询 Q={ Ssel, G, Tree }
输出:SQL查询
01 初始化 select=“ ” , from=“ ” , i=1, query=“ ”
02 for 先序遍历SPARQL结构树Tree中的每个节点m
03 if m为基本图模式(组图模式)节点 then trans(m, AND, G)
04 if m为可选图模式节点then trans(m, OPT, G)
05 if m为多图模式节点then trans(m, UNION, G)
06 first=true
07 for each ?aError! Objects cannot be created from editing field codes.Ssel
08 if first=true then first=false
09 else select+=“ , ”
10 select+=label(?a)
11 from+=query+“ AS T_” +(++j)
12 return “ SELECT” +select+“ FROM” +from
其中select代表需要投影的属性列集合, from代表源表选择, query表示条件约束条件集合。算法使用子查询生成的关系表作为源数据表, 也就是将query查询生成的关系表作为FROM中的数据源部分。因为组图模式是由基本图模式通过AND连接而成, 第03行对基本图模式的判断和对组图模式的判断合并在一起。R作为一个临时关系表用于存储基本图模式转换后的查询结果。第04行和05行分别是对可选图模式和多图模式进行处理。第07至10行形成了select需要投影的属性列集合。最后第12行对结果关系表进行投影操作, 选择在Ssel中出现并且以其中的变量名命名的属性列, 最终返回V, 完成SELECT查询。
3.2.2 CONSTRUCT查询模式转换
CONSTRUCT查询模式按照用户指定的图模板返回一个RDF图, 其中查询结果置换图模板中的变量。
CONSTRUCT查询模式会先按照WHERE约束条件对数据集进行查询操作, 然后将结果以CONSTRUCT中指定的RDF三元组形式输出。由于RDF图存储在关系数据库中, 所以只能用关系表近似地表示作为查询结果的RDF图。
将CONSTRUCT查询转换为SQL查询的主要思想是:以RDF图G和Tree结构树的根节点作为参数调用SELECTtoSQL算法, 返回CONSTRUCT中要求的变量绑定。为了使关系表包含CONSTRUCT中的所有属性, 包括常量属性列和变量属性列, 需要对拥有变量属性列的关系表和拥有常量属性列的关系表进行笛卡尔积操作。针对形成的全属性列关系表, 根据CONSTRUCT中出现的每个基本图模式的属性结构, 投影出相应的属性列, 并把相应的元组加入到结果关系表中。最后, 依据元组所属图和元组的主语使用GROUP BY关键字对结果关系表的元组进行分组排序, 将结果集返回给用户。上述转换思想形式化表示为以下算法:
算法:CONSTRUCTtoSQL
输入:CONSTRUCT query Q=(Sty, G, Tree)
输出:SQL query result
01 建立一个临时表X, 拥有Sty中常量属性列Adcol=( literal1, literal2, …)
02 设Ssel为Sty中要求表示的变量集合
03 CREATE VIEW V /* 建立视图V作为结果关系表* /
04 视图Y=exec(SELECTtoSQL(Ssel, G, Tree))
05 Y=Y´ X /* 两个关系表的笛卡尔积* /
06 for Sty中每个gpi
07 确定该图模式的属性结构
08 从Y中投影出图模式中包含的属性列, 并将元组加入到V中
09 对V中的元组进行分类(GROUP BY (res, s))
10 return V
其中Sty表示CONSTRUCT内的结果输出格式, 可以包含多个基本图模式; 参数Tree是包含了所有图模式和限定约束条件的结构树的根节点; G代表要查询的RDF图集合。第01行中建立临时表X, 包含了CONSTRUCT中要返回格式的常量属性列。第02行的Ssel代表着CONSTRUCT中需要返回的变量集合。第04行以G和Tree作为参数调用SELECTtoSQL函数, 将中间结果集存储在视图Y中。第05行将拥有变量属性列的Y与拥有常量属性列的X进行笛卡尔积操作, 并以此更新视图Y, 目的是使关系表中每条记录都包含CONSTRUCT要求返回的全部属性列。第06到08行将Y中记录按照CONSTRUCT的要求把相应的属性列进行重新排列, 加入到结果关系表V中。第09行是对V中的记录进行分组排列, 主分组词为res, 即RDF图的URI, 次分组词为三元组的主语。最后将结果关系表返回给用户, 完成从CONSTRUCT查询模式到SQL的转换。
3.2.3 DESCRIBE查询模式转换
DESCRIBE查询返回关于某个变量 ?descri的全部描述。首先, 找到每个满足Where条件的 ?descri的变量绑定bind。然后, 寻找以bind为主语的元组和以bind为主语的元组中的谓词为主语的元组, 以及以bind为宾语的元组。最后, 将所有的元组按照RDF图IRI和主体进行分组排列返回给用户。DESCRIBE查询转换形式化表示为以下算法:
算法:DESCRIBEtoSQL
输入:SPARQL query Q=(Descri, G, Tree)
输出:SQL query result
01 CREATE VIEW V
02 if(isIRI(Descri))
03 V=exec(SELECTtoSQL(* , Descri, Tree)))
04 if(isVAR(Descri))
05 X=exec(SELECTtoSQL(Descri, G, Tree))
06 for X中的每个变量绑定xi
07 添加exec(SELECTtoSQL(* , G, (s=xi)))的返回结果到表V中
08 for V中的每个记录行提取出谓词pi和宾语oi
09 添加exec(SELECTtoSQL(* , G, ((s=pi)UNION(s=oi))))的返回结果到V中
10 根据res和s进行结果排序
11 return V
其中Descri为要查询的变量或者IRI, WHERE为约束条件, G为指定的RDF图集合。第02、03行处理DESCRIBE关键字后面描述的是一个RDF图IRI的情况, 此时将该IRI内的所有元组存入视图V中。第04到10行处理的是DESCRIBE关键字后面要描述的是某一个变量的情况, 此时将满足图模式匹配的变量绑定存放到临时表X中。接下来查找以X中任意的变量绑定为主语的元组并将其添加到V中。第08、09行查找以V中元组的谓词或者宾语为主语的元组, 并且不断地将元组加入到V中, 直到V中所有元组都被访问过。最后对V中的元组进行分组排列返回给用户。
3.2.4 ASK查询模式转换
ASK查询模式用于检测符合Where条件约束的变量匹配是否存在, 若存在则返回true, 否则返回false。根据其含义, 若执行SELECTtoSQL(* , G, Where)得到的结果集不为空, 则返回true; 否则返回false。其中G为所有RDF图的集合, Where为ASK查询模式中的图模式集合。
算法:ASKtoSQL
输入:SPARQL query Q={G, WHERE}
输出:BOOLEAN(true/false)
01 if(exec((SELECTtoSQL(* , G, WHERE)))返回结果不为空)
02 return true
03 else
04 return false
综上, 给出SPARQLtoSQL算法, 该算法根据不同查询模式, 分别作出不同函数调用, 实现任一SPARQL查询到SQL查询的转换。
算法:SPARQLtoSQL
输入:SPARQL query Q={Pattern, Ssel, G, Tree}
输出:结果关系表V或者布尔值
01 Switch(Pattern){
02 Case SELECT :
03 query=SELECTtoSQL(Ssel, G, Tree); 输出V=exec(query);
04 Case CONSTRUCT:
05 V=exec(CONSTRUCTtoSQL(Ssel, G, Tree)); 输出V;
06 Case(DESCRIBE):
07 V=exec(DESCRIBEtoSQL(Ssel, G, Tree)); 输出V;
08 Case(ASK):
09 b=exec(ASKtoSQL(G, Tree)); 输出b;
10 }
根据上述分析, 实现了SPARQLtoSQL查询转换系统, 以Wine本体作为实验数据对系统进行评测, 选择12个具有代表性的SPARQL查询作为输入(如表1所示), 并对实验结果与其他两种现有的转换方法SparqlTOSql[4]和FlatSqlJoinMySQL[5]进行了分析和比较。
| 表1 查询实例 Table 1 Query examples |
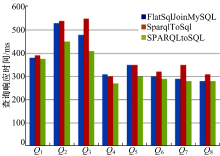
图1给出了三种不同查询策略的查询响应时间。查询响应时间是指从输入SPARQL查询, 经过查询转换, 到查找出满足匹配条件的RDF数据所用的时间。由于前两种方法不支持Q9到Q12的查询模式, 所以不对这四个查询实例的查询响应时间做对比。由图可知本文提出的查询转换策略的查询响应时间最短。与FlatSqlJoinMySQL方法相比, 由于该方法使用的方法是延续SparqlToSql方法中的多次转换多次查询的策略, 所以与本文提出的多次转换一次查询的方法相比查询响应时间略长。
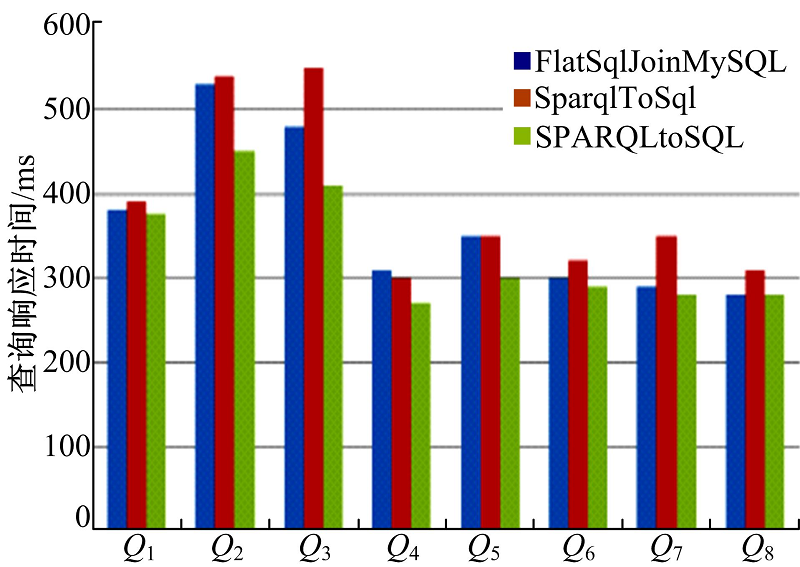 | 图1 查询响应时间对比图Fig.1 The query response time of different systems |
本文提出了SPARQL查询到SQL查询的转换方法, 给出了图模式、结果修饰符和不同查询模式到SQL的转换规则, 构建了SPARQLtoSQL查询转换系统。以往转换算法通常采用边转换边执行的方式, 导致转换耗时、效率低。本文采用一次转换再执行的方式, 显著提高了转换效率。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|