

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于网络处理器的流媒体应用架构模型(VPL)
[李明哲1, 2  , 王劲林
, 王劲林1 , 陈晓1 , 陈君1 ]
, 王劲林]
|
|


作者简介:李明哲(1988-),男,博士研究生.研究方向:网络新媒体技术.E-mail:limz@dsp.ac.cn
研究了多核网络处理器上流媒体应用的软件架构,在混合流水线(HPL)模型的基础了提出了虚拟流水线(VPL)模型,该模型能够克服HPL负载难以均匀分配的问题。VPL模型将功能逻辑设计和资源分配相分离,增强了应用开发阶段的灵活性。为VPL提出了AF和NAF两种数据流映射策略,并对两种策略的性能进行了理论分析和实验测试, 探讨了二者之间如何选取。作为VPL的应用实例,基于VPL模型在Cavium OCTEON处理器上设计了流媒体网关应用HiliMG。对HiliMG的实验结果证明了VPL相对于HPL模型的性能优势,VPL使得吞吐率提升13%以上。
Designing of high-performance software architectures for streaming media applications on network processors is studied. The VPL (Virtual Pipeline) model is presented as an enhancement to the commonly used the HPL (Hybrid Pipeline) multi-core architecture model. VPL overcomes the load imbalance problem of HPL. Besides, VPL separates application logic design from resource mapping which improves flexibility of software development. VPL supports a variety of data flow mapping strategies. Two of such strategies are proposed. Performance of these strategies was analyzed theoretically and measured on real hardware to explore when to use each. As an example application of VPL, HiliMG, a streaming media gateway application, was designed and implemented on a Cavium OCTEON network processor. Experimental results on HiliMG further confirmed that VPL performs better than HPL in term of data throughput by at least 13%.
网络处理器(Network processor, NP)是为处理网络应用而设计的专用处理器, 近年来得到了广泛应用[1, 2]。网络处理器不但具有良好的可编程性, 也在网络应用处理方面具有卓越的性能[3, 4]。当代的网络处理器大多使用多核架构, 以突破单核处理的主频和功耗瓶颈。这些核被做成片上系统(System-on-Chip, SoC), 能够降低处理延时, 平滑分组延迟抖动。针对一些网络处理应用中的常见操作, 网络处理器还利用各种协处理器实现硬件加速。网络处理器平台需要相应的软件结构来组织底层的硬件资源, 发挥硬件性能, 同时又要求软件平台兼顾应用程序的开发效率。在解决开发效率方面, OpenNP[5], NP-Click[6], NPPlatform[7]等模块化方法和开发框架相继被提出。然而这些工具在简化程序设计的同时, 带来了运行效率的开销。另外, 这些框架的模块化编译工具往往只针对少数厂商和产品, 缺少可移植性, 远远无法解决网络处理器硬件生态高度异构化的问题。作者认为, 为简化软件开发过程而采用的软件设计工具本身也不宜过分复杂, 要有足够的通用性, 以适应各种各样的平台。本文面向流媒体类应用, 致力于对网络处理器平台上通用的轻量级软件架构的研究, 以求在简化应用开发过程的同时提升运行效率。
在多核平台上开发应用时, 需要合理地设计多核软件架构, 将数据处理任务分解后映射到各个核心上。不合理的多核架构会严重限制计算能力的发挥, 甚至导致系统性能低于单核系统。网络分组处理应用主要有RTC(Run-to-completion)模型和流水线(Pipeline, PL)模型[8]两种多核架构模型。RTC模型下, 一个执行的进程或线程完成整个分组所有处理阶段, 中间没有停顿和切换。在流水线模型下, 一个分组的处理操作被分成多个不同的阶段, 每个阶段只完成一部分数据处理工作, 由专门的核上运行。执行各个阶段的核心依次串联起来构成一条逻辑上的流水线。
RTC模型适合于简单的L2/L3的分组处理应用, 这类应用的分组间几乎没有依赖关系, 分组到达后在单个核上即时完成处理, 然后不再访问。然而当前的流媒体应用大都有复杂的处理逻辑, 对数据在OSI模型的L4~L7层进行处理, 往往是针对数据流而非基于分组, 不适合RTC模型。这里的数据流是指一批相互关联和依赖并存在时间顺序性的网络分组, 一般对应L4层的一个连接或L5层的一个会话, 具有较长的持续时间, 下文中简称为流。
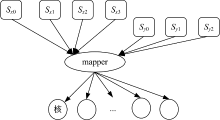
由于网络应用通常具有顺序性, 能够分解成多个依次承接的阶段(Stage), 如果采用PL模型则会使得编程流程比较自然[7]。阶段间负载均衡是PL模型所面临的问题。一条流水线的吞吐率取决于吞吐率最低的那个阶段。在单一流水线(Single pipeline, SPL)模型(图1所示)下, 每个阶段被分配到一个处理器核心, 工作量最大的阶段会成为瓶颈。而在混合流水线(Hybrid pipeline, HPL)中, 每个阶段可在多个核心上并行运行, 应根据各阶段的负载大小分配相应的核数。
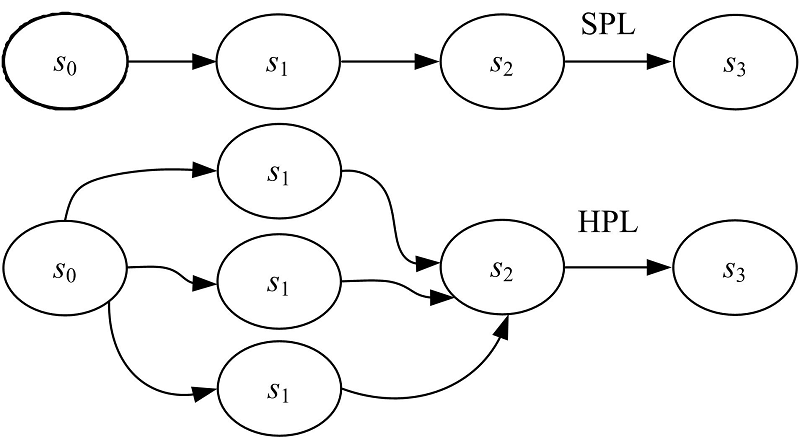 | 图1 SPL与HPLFig.1 SPL and HPL |
记C={1, 2, …, nc}为物理核心编号(core_id)的集合, S={s1, s2, …,
上述模型假定τ s在运行时不发生变化, 实际上并不严格成立, 并且τ s的测量并不容易。即使问题能够被求解, 这种以核为粒度的计算资源分配难以做到精确。
流媒体应用的数据处理常常作用于流而非分组, 软件设计应考虑流到计算资源的映射。记F为被处理的数据流的集合, R+为正实数集, 映射MCF:C× R+→ F+{f0}给出了任意时刻一个核所处理的数据流, 其中f0表示“ 无此数据流” , 即MCF(c, t)=f0意味着核c在t时刻空闲, 若c非空闲则MCF(c, t)∈ F。在下文中, 如无歧义, 将省略表示时间的参数t。一种可行的流映射策略是:对于每个阶段, 将每个数据流固定交给该阶段的单一核进行处理, 这种方式避免了阶段内并行访问同一数据流造成的访问冲突, 且具有良好的Cache亲和性(Cache affinity), 下文中称为AF策略。另一种策略对流和核的关系不做任何限制, 称为NAF(Cache non-affinity)策略。
考虑两种策略的Cache特性:对于一个有二级缓存的处理器, 一般L1 Cache为单核独享, L2 Cache为核间共享。平均内存访问时间tA取决于访存次数两级Cache命中率h1和h2, 及访问两级Cache和DRAM的时间tL1, tL2和tL3, 有:
对于AF和NAF两种策略, 其Cache命中率可估算为[8]:
式中:Φ 1和Φ 2分别为前两级Cache容量; Wf为单个流的工作集(内存访问范围)大小, 为应用程序特性; 流并发数nf体现了负载的大小。
由式(2)~(5)可知
一些数据流处理应用会要求并行程序满足“ 阶段互斥性” , 即不允许分配给同一阶段的多个核心同时访问同一个数据流:
另一些应用甚至会提出更强的“ 流互斥性” 要求, 即不允许任意两个核心同时访问同一个数据流:
采用自旋锁等机制可以实现流互斥性要求, 从而必定也能实现阶段互斥性。然而对于AF策略, 即使没有锁的包含, 也能自动实现阶段互斥性。
如前文所述, HPL模型存在诸多缺陷:流水线阶段的相对负载难以确定, 致使流水线拓扑设计缺乏可靠的依据; 计算资源的分配是以核为粒度的静态分配, 难以实现精确的按需分配, 且不能适应负载的动态变化。此外, 计算资源到数据流的映射与到流水线的映射紧密耦合, 让应用开发变得复杂。本节提出虚拟流水线模型(Virtual pipeline, VPL)以解决这些问题。
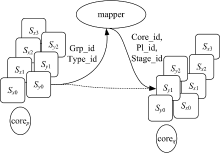
图2为VPL模型的结构, 它包含逻辑流水线、映射器(mapper)和物理核心3个组成要素。逻辑流水线只代表软件上的处理流程, 其中每一个阶段都是一组代码指令, 而不是硬件单元。VPL同时支持多条逻辑流水线相互独立地运作, 在性能允许的情况下, 可任意扩展流水线条数。这里不同的逻辑流水线对应不同的处理流程, 通常代表不同的应用程序模块或组件。多个只包含单一逻辑流水线的应用程序可合并为一个包含多个逻辑流水线的应用程序。如图2中Sx和Sy是两条逻辑流水线, 其中Sx包含Sx0~Sx3四个阶段, Sy包含Sy0~Sy2三个阶段。映射器以数据结构的形式存在, 负责数据处理任务到计算资源上的分配。
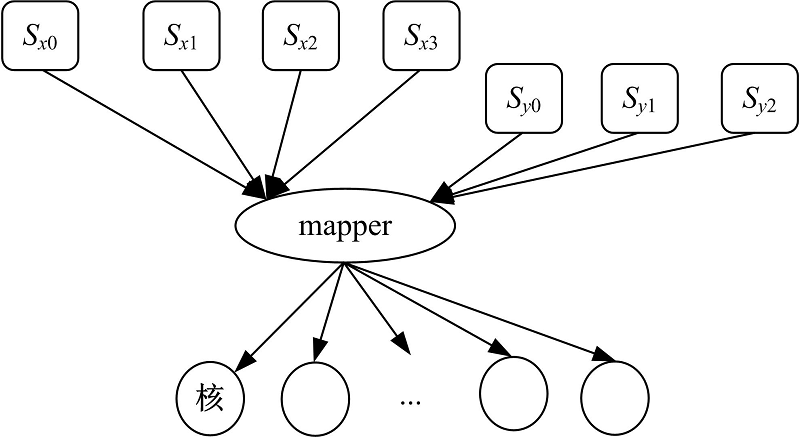 | 图2 VPL构成要素Fig.2 Composition of VPL |
流水线的每一个阶段都按照事件驱动编程模型[12, 13]进行设计。事件驱动编程模型也叫消息驱动模型, 在这种模型下应用程序的主流程循环地执行读取消息-处理消息操作, 因此程序可看作由事件(消息)分发器和各种事件对应的事件处理器构成。事件分发器查看事件类型(下文中记作type_id), 将该事件调度到相应的事件处理器, 而事件处理器则执行数据处理操作。对于数据流处理应用, 事件包括网络包到达事件和其他应用逻辑事件, 如模块间消息和定时器超时事件等。事件以消息的方式到达各个流水线阶段, 一个分组在遍历一条流水线的过程中, 依次以消息方式驱动各个阶段的处理。消息传递都要经过VPL的映射器调度分发。阶段向映射器主动地提交和申请消息, 映射器按照一定的原则将已提交的消息分发给申请消息的核心。核心根据消息类型type_id确定对应的流水线和流水线阶段, 并定位到对应的事件处理器, 最终调用该事件处理器完成数据处理操作, 如算法1所示。
算法1 VPL Core
1. procedure COREROUTINE
2. while True do
//申请到消息
3. msg← mapper.getMsg(core_id)
//确定对应流水线r
4. r← mapper.getPipeLine(msg.type_id)
//确定对应的阶段s
5. s← r.getStage(msg.type_id)
//确定相应的事件处理器
6. h← s.getHandler(msg.type_id)
//调用事件处理器
7. h.process(msg)
8. end while
9. end procedure
与HPL模型不同, VPL的流水线设计和计算资源映射被隔离开来, 两者相互独立, 于是负责实现数据处理功能的开发者不再需要关注每个阶段核的数量, 而将这一工作由映射器解决, 映射器按照一定的策略给流水线的阶段分配执行核心。记P为系统同时运行的逻辑流水线的集合, P中的任一流水线ρ 可视为ρ 中各阶段构成的集合, 记S为各流水线所有阶段的集合, 即S=∑ ρ ∈ P{s|s∈ ρ }, 则流水线阶段到核的映射可用MSC:S→ {Ci|Ci⊆C}表述。
图3描述了阶段映射的原理。虽然每个核都能访问所有阶段对应的代码, 但映射器通过控制消息的分发方式来控制每个核心实际能够调用的事件处理器的集合, 从而实现各种MSC设计。因此, 映射器可以实现为消息队列和映射规则表。
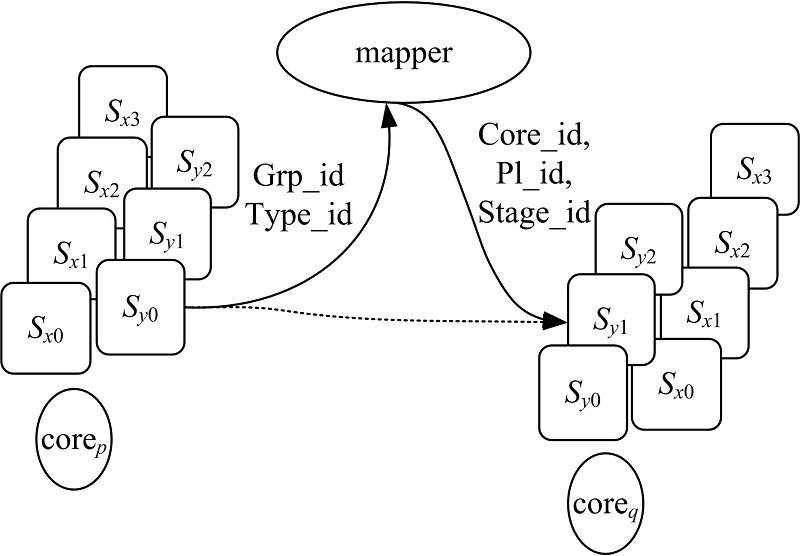 | 图3 VPL消息传递Fig.3 Message path in VPL |
为实现阶段间负载均衡, 一个简单的策略是将每个阶段都映射到全部核心上:
显然, 在这种策略下, 只要有尚未完成处理的数据就不会出现空闲的核心, 这样就确保了阶段间计算资源的按需分配, 避免了上文所述的HPL阶段间负载不均衡问题。如果不考虑映射器本身的开销, 式(8)所示的MSC设计能够体现出相对于HPL的性能优势。此外, 有的应用可能需要将不同的逻辑流水线在物理上隔离开, 以免在异常情况下互相影响。这种情况下不能采用式(8), 需要将划分为
如此, 可实现流水线内各阶段的均衡性。而流水线间的计算资源分配体现为对C进行合理的子集划分, 资源分配的依据常常是某些服务质量指标, 而不是负载的均衡性, 本文不对其进行讨论。
映射器除了负责逻辑执行阶段的计算资源分配外, 也负责数据流的计算资源分配, 这是通过“ 流组” 的概念实现的。VPL的映射器按照一定策略将所有数据流集合F划分成若干子集, 每个子集称作一个流组。划分流组的依据可以是数据流的某些协议字段的哈希值, 此时, 记H为用于流组划分的哈希函数, G为H的计算结果取值空间, H(f)为数据流f对应的哈希值, 则对于G中的任意哈希值g, {f∈ F|H(f)=g}构成一个流组, 称g为该流组的组编号(grp_id)。
为了将计算资源分配给流组, VPL策略需要配置一个映射MCG:C→ {Gi|Gi⊆G}为每一个物理核心分配G的一个子集, MCG满足:
以确保所有的流组都至少被划分给了一个核心对其进行处理, 于是MCG决定了数据流及其计算核心的对应关系。
如图3所示, 当某数据流的一个阶段向其他阶段发消息时, 指定这条流的grp_id和消息类型type_id。映射器按照MCG将grp_id转换成一批核号core_id, 进而将该事件消息调度给正确的核。核心获得消息后, 根据type_id确定对应的逻辑流水线(pl_id)与阶段(stage_id), 最终由目标阶段完成阶段内消息分发。
VPL流映射可以采用前文中提到的AF策略或NAF策略。对于AF策略, 为使物理核间负载均衡, 需要保证流组到物理核心的分配是均匀的, 可如此设计:
易证明本策略满足流互斥性, 且可行的流水线映射只能采用式(8)。由于数据流的生灭是动态的过程, AF策略需要随时掌握各个流组的负载状况, 有一定的实施难度。
对于NAF策略, 可以有:
显然, 这一策略无需考虑数据流的分配问题, 物理核心的负载自动做到了均衡。需要注意的是, 这里的AF和NAF策略分别为1.2节AF和NAF的特例。
考虑AF在处理时间上的优势δ tA=
当Wfnf> Φ 2时, 有:
易知当Wfnf> Φ 1nc时, δ tA关于流数nf的微分
考虑到AF策略很难做到核间负载的完全均衡, 需分析在负载不均衡的情况下两个策略的性能。本文用L(f)表示数据流f造成的负载(CPU开销), 如果系统中只有码率相同的恒定码率(CBR)数据流, 那么认为每个数据流的负载L(f)是相同的。用K表示核间的负载不均衡程度, 定义为压力最大的核的负载相对于平均负载的比值, 即:
粗略假设CPU利用率主要取决于访存时间和访存次数, 那么对于最忙碌的核, 其CPU利用率正比于KtA。AF策略难以避免K大于1, 会削弱其性能上的优势。这样AF相对于NAF在CPU利用率上存在优势, 当且仅当K
基于VPL模型, 在Cavium OCTEON CN5860处理器[14]上实现了一个用于广播电视网络[15]的流媒体网关系统HiliMG[16]。作者之前的工作[17]主要讨论了HiliMG的业务功能和应用总体架构, 本文则考虑数据处理功能模块的架构设计。
HiliMG连接IP广域网和IPQAM设备[18], 将HTTP分块传输编码数据流转换为IPQAM设备所支持的传输格式。上述功能实现为一个四个阶段的流水线ρ , 如图4所示。其中Input阶段实现了网络协议栈的功能, 对到达的IP网络数据包进行解析, 对下一阶段输出HTTP数据流; Transcoder对HTTP报文头部和分块传输编码进行提取, 过滤HTTP层元数据, 得到MPEG2 TS流, 再按照IPQAM的输入格式进行封装重组; Delay阶段对载荷数据进行延迟缓冲; Output从Delay中获得数据, 按照一定的策略执行平稳地发送。四个阶段以事件驱动的方式实现, 其中Input将单个网络包的到达作为驱动事件, Transcoder和Delay依次将上一个阶段的输出作为驱动事件。最后一个阶段则以周期性的定时器超时作为驱动事件。这一流水线被映射到CN5860的12个核心上, 其余4个核心负责业务逻辑。
 | 图4 HiliMG流水线Fig.4 HiliMG’ s pipeline |
CN5860处理器的POW协处理器模块为VPL映射器的实现提供了支持。POW协处理器协助软件完成了消息在多核间的调度和传递, 它提供了16个“ 消息组” , 每一个处理核心都被配置成与若干个组相关联, 主动收取发往这些消息组的事件消息。消息组机制实现了上文中流组的概念。考虑流到核的映射FCG, HiliMG在开发过程中先后实现了式(11)和式(12)所示的AF和NAF策略, 下文中将对两种策略进行评估。对于NAF策略, 需要考虑流处理的临界区保护问题。一般在多线程环境下的解决方案是给每一条流分配一个互斥锁, 保护其所有的处理操作。POW的tag切换机制能够有效地降低互斥锁带来的互斥和同步开销。POW将IP流的五元组信息输入一个哈希函数, 具有相同输出值的流的集合被作为一个流束(注意该处理器的流束概念与上文中提到的“ 流组” 无关)。每个消息都被赋予一个属性值, 称为tag。数据包到达消息的tag值被赋予所在流束的Hash值, 应用程序制造的消息的tag值可任意决定。POW确保有相同tag值的两个消息不会被两个核同时收取和处理。假设消息msg1和msg2的tag值都是t, 当msg1被某核c获取后, msg2会被阻塞在POW, 其他核只能收到tag值非t的消息。直到msg1所触发的操作被核c执行完, c转而申请下一个消息, 称此时发生tag切换, msg2才可以被POW释放出。根据这一机制, 只要应用程序保证t所对应的数据流只收到tag值为t的消息, 则即使不加锁也能自动地实现流处理操作的原子性。然而, HiliMG的数据流为业务层数据流, 其生命期可对应多个TCP连接, 输入的数据包tag值可能会发生变化, 为保证程序的可靠性还是需要互斥锁, 尽管如此, tag切换机制还是使得互斥开销大大降低了。
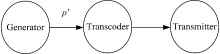
以HiliMG为基础, 在CN5860处理器上对VPL的流水线映射策略和数据流映射策略进行了性能测试实验。为方便实验操作, Input阶段并非真正从广域网中获取数据, 而是在本地构造HTTP分块传输编码数据流。Delay和Output阶段被合并成Transmitter阶段, 于是形成一个新的流水线ρ ', 如图5所示。
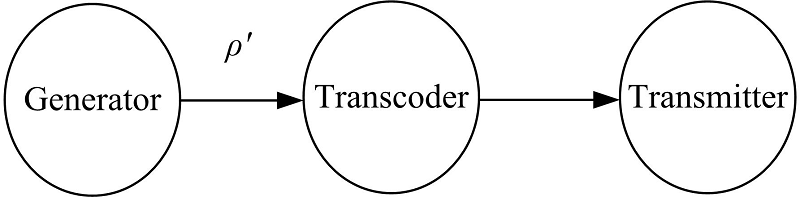 | 图5 测试流水线Fig.5 Pipeline for experiment |
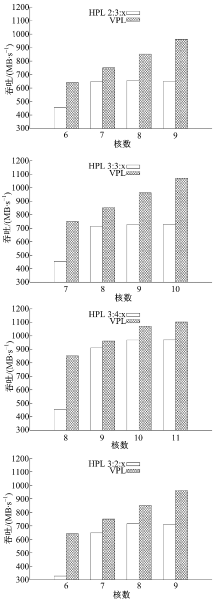
为比较HPL和VPL的相对效率, 本文分别按照HPL和VPL的方式对ρ '进行了实现, 并比较其吞吐率, 测试结果如图6所示。实验中, 控制HPL三个阶段中两个阶段的核数,
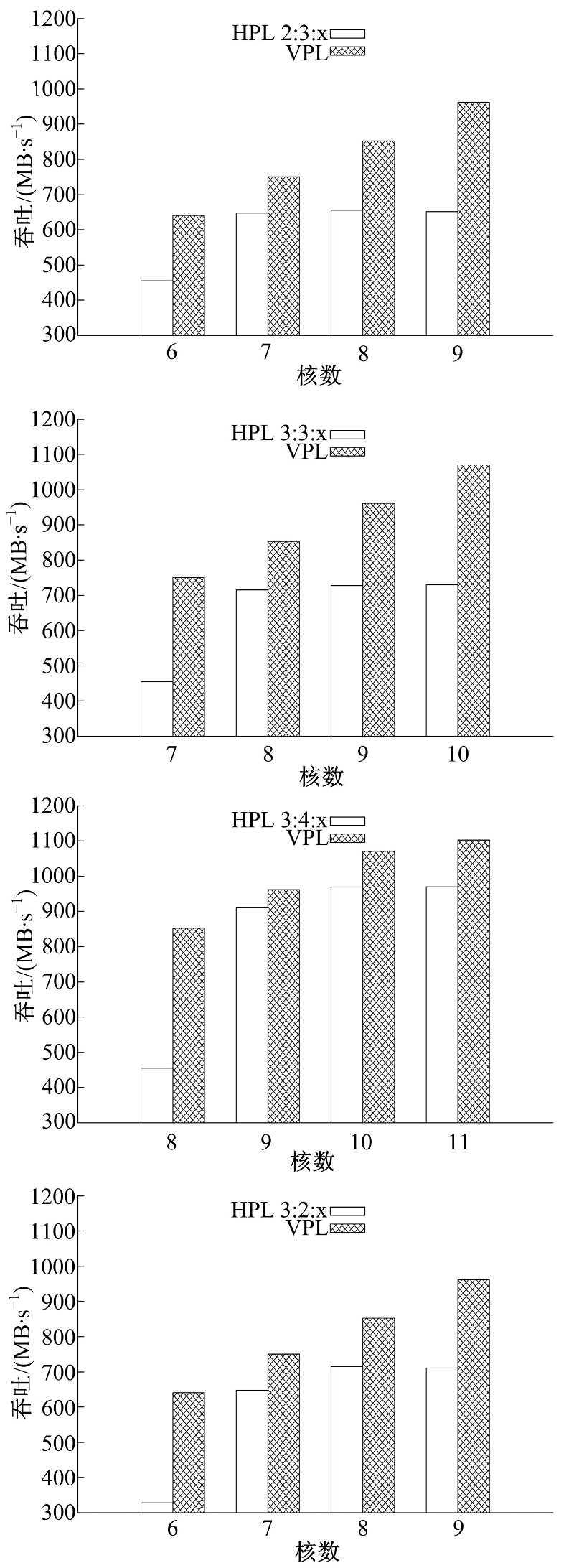 | 图6 流水线映射测试实验结果Fig.6 Pipeline mapping experiment |
变化第三个阶段的核数, 如图例中“ HPL2∶ 3∶ x” 样式的标记表示固定ρ '前两个阶段所用的核数分别为2和3, 变化剩下那个阶段的核数, 而对于HPL的每一种结构, 保持VPL的总核数与之相同。由图6可知, 在核数较少的情况下, 由于HPL阶段计算资源分配的粒度较大, 难以做到均匀分配, 吞吐率明显低于负载均衡的VPL模式。在HPL3∶ 2∶ 1的情形下, VPL的吞吐率高出了95%, 而两者最接近的情形是HPL3∶ 4∶ 4, 此时VPL也有13%的性能提升。
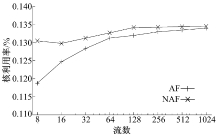
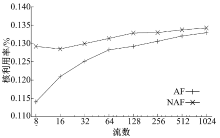
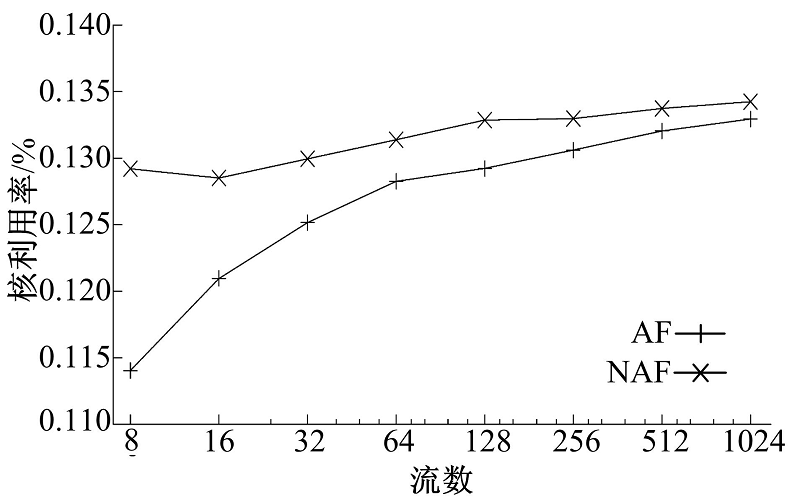
为评估流到核的映射MCG, ρ '实现了式(11)和式(12)所示的AF策略和NAF策略, 并在不同负载压力下测试二者对应的CPU利用率。本组实验固定使用8个核运行ρ ', 变化数据流的数量, 测量平均每个数据流的Generator和Transcoder阶段所占用的CPU利用率。数据流均为静态建立的长数据流, 保持相同的码率(3.75 Mbit/s), 这样只需保持每个流组上的数据流数目相同即可为确保流到核直接的均衡分配。测量结果如图7、图8所示。由结果可知, 在低负载状态下, AF策略由于对Cache友好, 能够使得处理时间有所降低。但是随着负载的升高, 数据工作集的增大, 二者的差距迅速缩小至忽略不计。流媒体网关只有在负载高、资源紧张的状态下才有性能优化的需求, 因此AF策略的Cache亲和性不足以表现出相对于NAF策略的性能优势。考虑到AF策略对流的均衡映射有严格的要求, 实施上有相当的难度, 此应用程序采用NAF策略更为合理。
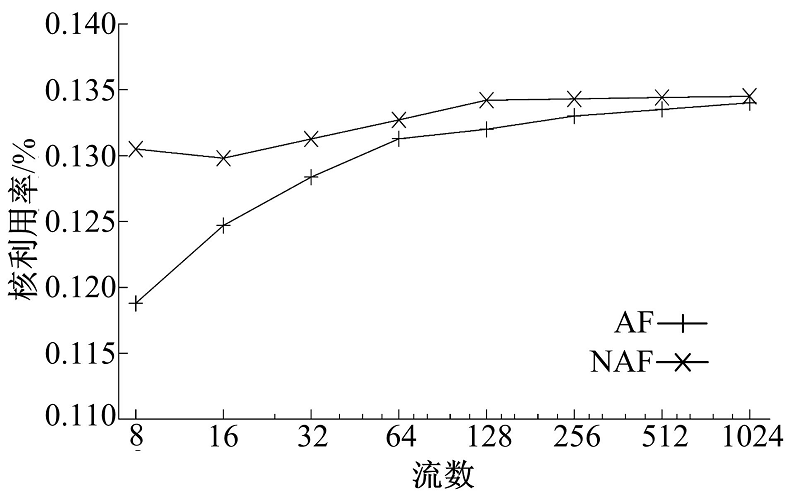 | 图7 数据流映射实验-1 GeneratorFig.7 Flow mapping experiment-1 Generator |
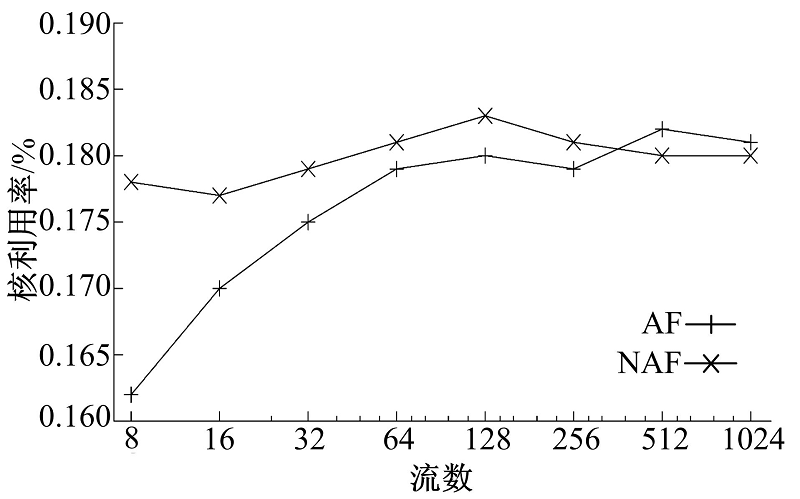 | 图8 数据流映射实验-2 TranscoderFig.8 Flow mapping experiment-2 Transcoder |
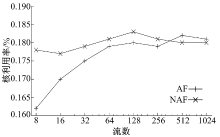
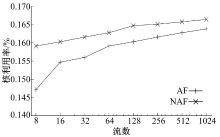
从图7、图8可以看出, 应用程序的工作集随着流数的上升迅速增大到导致缓存不能容纳。这是由流媒体类应用的特点决定的。作为流媒体应用的代表, 流媒体网关不仅仅处理报文包头, 还要大量访问载荷内容以进行转码操作, 这类应用的内存访问空间局部性比较弱, 对Cache的亲和性不够好。这一结果提示我们研究应用程序特性与流映射策略的关系。本文对Transcoder用基于DFA的方法[19]进行了另外一种实现。在该方法中, 运行在CPU上的软件基本上不会访问载荷数据, 载荷数据由DFA的硬件协处理器进行扫描, 将局部性限制在更小的范围内。在此基础上测试Transcoder阶段的CPU利用率, 其中20%的数据流由基于DFA的Transcoder进行处理(由于OCTEON CN5860平台上DFA单元的吞吐率较低, 难以让更多的数据流由DFA进行处理), 其余数据流仍按照原有方式进行处理, 结果如图9所示, 图中显示的是两种处理方式的平均CPU利用率。此时AF与NAF之间一直存在着较为明显的性能差距, AF的优势得以体现。
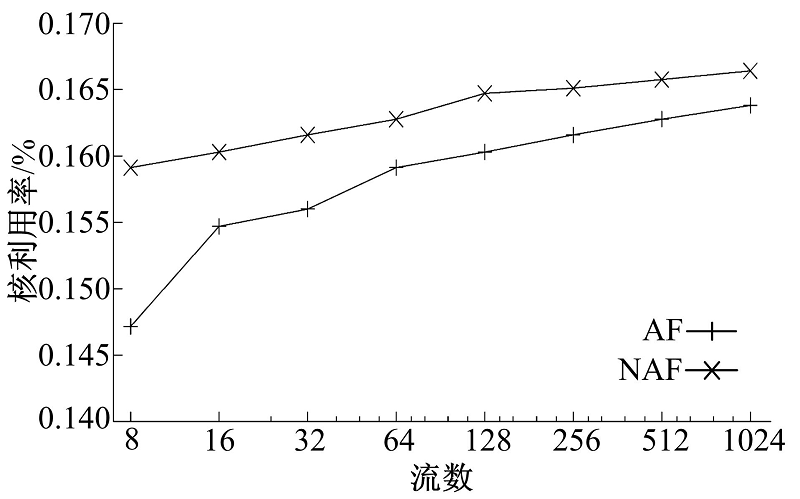 | 图9 数据流映射实验-3 DFA TranscoderFig.9 Flow mapping experiment-3 DFA Transcoder |
另外, 本文对Generator也进行了简化, 使其不再填写TS包结构, 减少了内存访问范围。在此基础上测量该阶段的CPU利用率, 结果如图10所示。与图7相比, 在高负载情况下AF相对于NAF有了略微明显的优势。
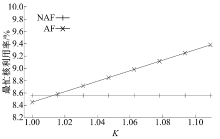
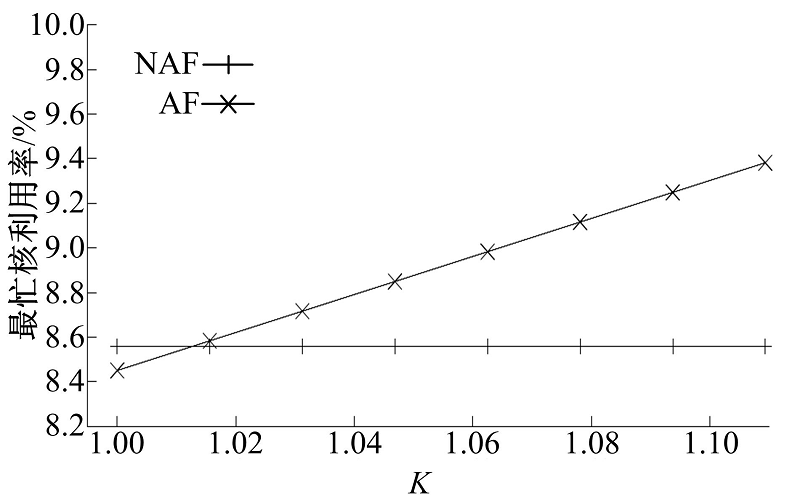
为了对比在负载不均衡情况下AF和NAF的性能, 本文将第二个核上数据流转移到第一个核上, 使得第一个核成为瓶颈, 通过调节瓶颈核上的数据流数目来控制AF策略的K值。用AF策略下运行简化的Generator处理64条数据流, 测试第一个核的CPU利用率, 结果如图11所示。图中也显示了用NAF策略处理64条数据流时第一个核的CPU利用率作为对比。随着K值增加, 瓶颈核上的负载压力随之增大, 削弱并最终抵消了AF策略Cache亲和性带来的优势。在K超过1.02时, AF瓶颈核上的CPU利用率超过了NAF策略。这种情形下, 只有将负载均衡程度K控制在低于1.02以下时使用AF策略才可能有优势, 否则应选用NAF。
综合上述实验可知:流处理应用程序是否采用AF类的策略取决于多种因素, 包括应用程序的内存访问特性, 负载量的大小, 以及能否有效实现核间负载均衡等, 一般情况下NAF策略比较简单有效, 应予以采用。
VPL将功能逻辑设计和计算资源分配相分离, 具有很强的灵活性, 方便了应用开发过程。VPL模型能够克服HPL在负载均衡上的不足, 以细小的粒度实现多核负载的平衡。对HiliMG的测试结果表明了VPL在性能上(相比于HPL)的优势。本文对AF和NAF两种数据流映射策略的性能进行了理论分析, 并在Cavium OCTEON处理器上进行了实验测试, 结果均表明, Cache亲和性策略能够带来一定程序的性能提升, 但其相对的优势与负载状况和应用特性紧密相关, 在负载高、内存访问局部性弱的条件下, AF所带来的性能提升可能非常有限, 因此在工程实践中应考虑更容易做到负载均衡的NAF策略。本文对流映射的Cache性能分析忽略了内存总线竞争的影响, 下一步将对总线竞争进行建模, 以评估它对VPL映射策略的影响。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|