{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于信号能量的浊语音盲信号分离算法
[李鸿燕 , 屈俊玲, 张雪英]
, 屈俊玲, 张雪英]
, 屈俊玲, 张雪英]
|
|


作者简介:李鸿燕(1973-),女,副教授,博士.研究方向:盲信号处理,模式识别.E-mail:tylihy@163.com
针对以往单声道浊语音分离算法对目标语音信号分离不稳定性和信噪比低的不足,引入了浊语音的另一个重要特征,即信号能量。提出了一种基于信号能量的浊语音分离算法,算法对经典的Hu-Wang算法进行了改进,将能量特征应用于听觉重组部分,通过能量特征来改进目标语音听觉流的重组性能,降低噪声对重组后的目标听觉流的干扰,提高算法的稳定性。实验结果表明:与Hu-Wang算法相比较,该改进算法可提高目标语音的分段信噪比,改善了目标浊语音的分离性能。
Considering the shortcoming of instability and low SNR in existing monaural voiced speech separation algorithms, a new voiced speech separation algorithm based on signal energy is proposed, which introduces the signal energy as another important voiced speech feature. This new algorithm is based on the improvement of the classical Hu-Wang algorithm, applying energy feature to the auditory reorganization part. It further improves the reorganization performance of the target speech auditory stream as well as reduces the influence of noise and improves its stability by applying the energy feature. The experiment results show that compared with Hu-Wang algorithm, this improved algorithm can improve the segmental SNR of the target speech segmentation and improve the separation performance obviously.
语音在实际传输环境中, 总会受到各种各样噪声的干扰, 如机器噪音、音乐干扰和其他说话者的声音等。噪声干扰对于诸如自动语音识别系统、助听器、视频会议等应用领域提出了挑战[1, 2, 3]。针对这一问题, 过去的几十年里, 研究人员做了大量的工作, 开发计算机系统来分离目标语音或者减弱噪声干扰。
目前, 对于混合语音信号分离的研究主要有两方面:盲信号分离(Blind source separation, BSS)和计算听觉场景分析(Computational auditory scene analysis, CASA)[4, 5, 6]。盲信号分离有一些假设条件, 如要求观测信号的个数大于等于源信号的个数; 假定噪声不存在或噪声很小, 可以忽略不计等, 这些假设条件在某种程度上限制了盲信号分离的应用[7]。近年来, CASA算法由于其不需要假设信号的统计特性和单通道条件下的可实现性, 已受到国内外研究学者的广泛关注。语音由浊音和清音两部分组成, 浊音是语音信号的主要组成部分, 含有语音信号的大部分信息[8]。对于单通道浊语音分离的问题, Hu和Wang等[9]提出的基于谐波和幅度调制的混合语音分离系统有效地改善了目标语音的分离性能, 并且优于以前的CASA算法。但是, 相比于低频部分的信号来说, 语音信号在高频部分(> 1 kHz)的能量比较低, 容易受到噪声干扰, 因此, 当混合语音信号中的噪声干扰变强时, 将会干扰Hu-Wang算法中对应的听觉线索, 从而影响系统的分离效果[10]。声学特性表明, 浊语音具有准周期性, 因此, 谐波特性成为浊语音的重要特征。同时, 在浊语音的谐波上还分布着语音信号的大部分能量, 能量是浊音的一个重要特征[11]。由于语音信号的低频信道上分布了信号的绝大部分能量信息, 而在高频信道上只占有非常少的能量。因此, 对于混合语音信号, 如果某个高频信道上分布了足够多的能量, 可以认为, 目标语音信号在该信道上受到噪声严重干扰。
基于以上研究, 本文提出了一种基于谐波特性[12]和能量特征的计算听觉场景分析(CASA)算法, 与经典的Hu-Wang模型不同之处在于, 在语音的听觉重组部分引入了能量特征来完成目标语音的重组, 减小噪声的影响, 算法更加稳定, 重组之后的目标语音信号更接近于原始纯净的语音信号。实验结果显示, 本文提出的改进算法与Hu-Wang模型相比, 分离性能有明显提高。
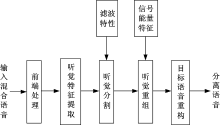
本文提出的单通道浊语音改进算法包括混合语音信号的前端处理、听觉特征提取、基于谐波特性的听觉分割、基于能量特征的听觉重组以及目标语音的重构5个部分, 如图1所示。
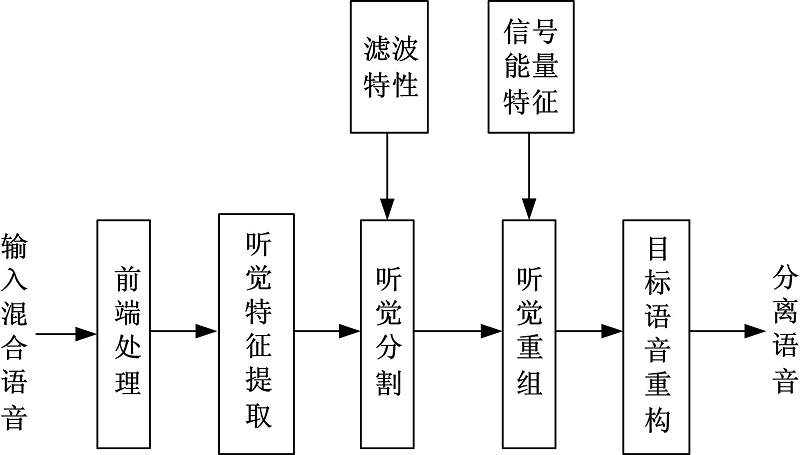 | 图1 浊语音分离改进算法框图Fig.1 Voiced speech separation improved algorithm block diagram |
前端处理是将输入的混合时域信号转化成相应的时频域表示形式。根据人耳的感知机理, 将输入混合声音信号通过128个信道的Gammatone滤波器组进行带通滤波, Gammatone滤波器对于人耳基底膜在不同频率上的响应都能很好地模拟, 是一种标准的听觉滤波模型, 该滤波器的中心频率按照等距宽(Equivalent rectangular bandwidth, ERB)在80~5 kHz之间准对数分布[13, 14]。将时频分解后的每一个Gammatone滤波器的输出送入Meddis内耳毛细胞模型, 得到神经发放率。然后, 在时域上对每个毛细胞的输出以帧长20 ms、50%重叠为帧移进行分帧处理。将输入的混合语音信号分解成为一系列时频单元, 即T-F单元。同时, 为了高频部分的特征提取和听觉重组, 对毛细胞输出进行半波整流和低通滤波, 从而得到每个通道的包络特征。
经过前端处理过程, 混合语音信号在时域和频域上被分解成一系列的T-F单元, 在每个T-F单元中, 计算下列特征函数:自相关函数AH、包络自相关函数AE、主基音周期P(m)、相邻信道互相关CH、相邻信道包络互相关CE。
式中:c为信道; m为时间帧; Nc为采样点数; h(c, · )为神经发放率; 时延τ ∈ [0, 12.5] ms, 表示帧移; hE(c, · )为毛细胞输出包络。
式中:L=采样率× 12.5 ms;
根据听觉特征提取的特征函数, 将混合语音信号经过听觉前端处理后的那些T-F单元合并成对应的听觉片段。在时频域中, 将属于某一个声源的连续T-F单元的片段区域定义为段, 它是介于时频单元和语音听觉流的中间表示。听觉分段的目的在于分辨出时频域中可以利用的那些连续T-F单元, 并且每个分段惟一地对应着某一个声源。
(1)类型“ 1” 听觉片段
Gammatone听觉滤波器组中, 由于相邻的带通频率之间表现出明显的重叠现象, 从而多个邻近滤波器受到同一个谐波的激励, 导致相邻信道的高度相关性。听觉滤波器相邻信道互相关(CH)程度越高, 即其值越接近于1, 表明这两个相邻信道来自于同一声源的可能性越大[14]。因此, 对于频率信道上的两个相邻T-F单元u
语音信号具有时域连续性, 通常会持续一段时间(> 50 ms)。基于语音信号的这两个特性, 可以成功地将标记是“ 1” 的那些相邻T-F单元合并到听觉片段中, 从而得到类型“ 1” 的听觉片段, segment
(2)类型“ 2” 听觉片段
语音信号的高频范围(> 1 kHz)内, 听觉滤波器的频率通带较宽, 一个滤波器会同时响应多个谐波, 以至于这些不确定谐波的滤波响应产生幅度调制(AM)现象, 并且相邻通道的包络具有很强的通道互相关。相邻信道包络互相关程度越高, 表明高频范围内的两个相邻信道来自于同一声源的可能性越大。因此, 对于频率通道上的两个相邻T-F单元, 如果其相邻信道包络互相关CE满足式(7), 则将这两个相邻T-F单元标记为“ 2” 。
对于不确定性时频单元, 根据幅度调制现象和时域连续性这两个特性, 可以成功地将标记为“ 2” 的相邻T-F单元合并到听觉片段中, 从而得到类型“ 2” 的听觉片段, segment
(3)对于不满足上述条件的那些T-F单元, 不被合并到任何一个听觉片段中, 并且将其标记为“ 0” , 即为噪声片段。
听觉重组是混合语音信号分离算法的重要部分, 将上一阶段来自同一个声源的那些听觉片段分别重组到对应的目标语音流和干扰噪声流中, 从而实现目标语音分离。
对于一段混合语音信号, 如果有足够多的能量信息分布在某个高频信道上, 则认为目标语音信号在该信道上受到噪声严重干扰, 将该T-F单元标记为噪声干扰主导。基于此, 在信号重组过程中, 可以去除目标听觉流中由噪声主导的那些T-F单元, 使得重组的目标听觉流更少地受到噪声干扰, 性能更加稳定, 效果更理想。
基于能量特性的听觉组织改进算法主要集中在语音信号高频部分的改进, 具体步骤如下:
(1)T-F单元标记
对于类型“ 1” 听觉片段中的T-F单元, 利用该T-F单元的自相关函数和目标语音基音频率来刻画谐波关系, 即周期性准则。如果片段“ 1” 中的时频单元u
则标记u
听觉片段“ 2” 中主要对应非确定T-F单元, 其滤波响应包络具有明显的幅度调制现象, 这里采用幅度调制(AM)准则对其进行标记。如果片段“ 2” 中的时频单元u
则认为u
根据上述标记的T-F单元, 将混合语音信号的所有听觉片段分别重组到对应的目标语音听觉流stream
(2)最终听觉流形成
对于目标语音信号中高频部分的那些T-F单元, 为了估计其被噪声干扰的程度, 需要计算混合信号在各个频率信道上的能量, 本文通过对每一个信道上的信号提取时间包络, 进而可得到混合信号在各个信道上的能量E
具体步骤如下:
①在混合语音信号的低频范围内(低于1 kHz), 根据得到的各个频率信道能量E
②对高频范围内的T-F单元进行调整, 如果某个频率信道上的能量满足:
则计算该频率信道上所有T-F单元的平均能量:
式中:N为该频率信道ci中时间帧的总数。
③对于该频率信道ci上的各个T-F单元求取能量值E
则认为该T-F单元由噪声干扰主导, 将其从目标语音听觉流stream
④通过迭代重组将stream
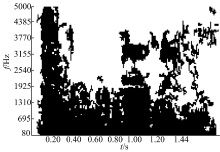
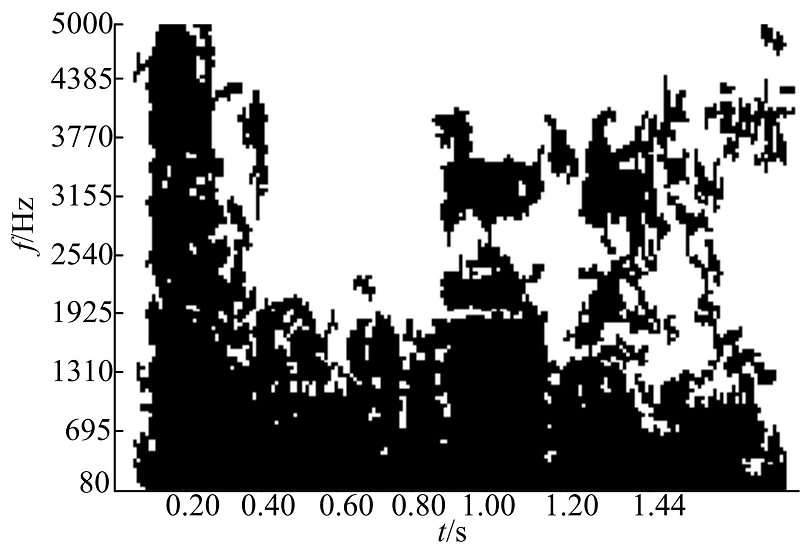 | 图2 目标语音二值掩膜图Fig.2 Binary mask image of the target speech |
利用二值模和Gammatone滤波器结构来合成目标语音信号的时域波形图, 从而实现语音信号的分离。目标语音重构算法的具体步骤如下:
(1)各个Gammatone滤波器信道的输出信号先进行时间反转, 并将其结果再次送入Gammatone滤波器。
(2)由于滤波器频率信道间存在相位延迟, 需要将上一阶段每个滤波输出的信号再一次时间反转来消除滤波器本身的时延。
(3)利用每帧20 ms, 帧移10 ms的分帧原则, 采用升余弦函数作为窗函数, 对各个滤波信道的输出信号分帧处理。
(4)以二值模为权值(即权值1和0), 在频率轴上对T-F单元滤波响应进行加权求和, 其输出结果即为重构后的目标语音信号。
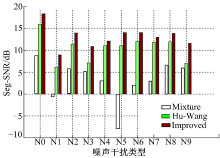
实验采用英国谢菲尔德大学提供的Cooke语音库。它是由10句连续的浊语音与10种不同的噪声干扰混合形成100个混合语音信号, 其中, 10句目标语音是由两名男性分别朗读5个句子, 采样频率是16 kHz, 16 bit量化。10种不同的噪声干扰分别是:1 kHz的纯音调N0, 白噪声N1, 突变噪声N2, 鸡尾酒会噪声N3, 摇滚音乐N4, 警报声N5, 电话铃声N6, 女生语音N7, 男生语音N8, 女生语音N9。
为了评估改进算法的语音分离性能, 需要采用一种客观评价方法。通常人们根据信噪比(Signal to noise, SNR)的提高来对性能进行评估, 但是SNR并不能充分地反映语音信号的时变特性, 因此, 采用分段信噪比(Seg-SNR)作为评估标准, 它是基于帧的SNR, 计算公式如下:
式中:M为语音信号的帧数; N为每一语音帧的长度; s
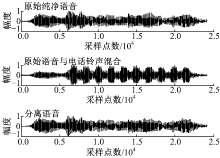
以N6为干扰噪声, V0为原始纯净的语音信号, 其发声内容是“ I’ ll willingly marry Marilyn” , 简单线性叠加信号为V0N6。图3给出了V0、V0N6以及分离语音的时域波形图。
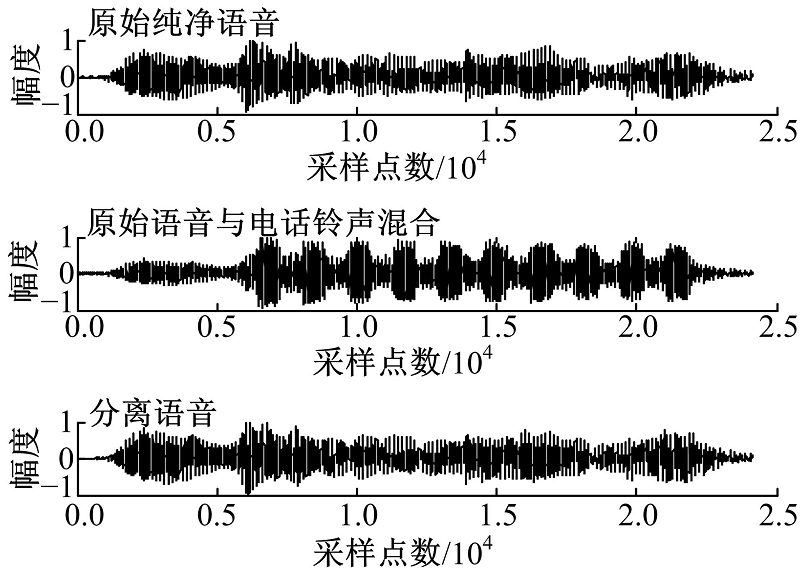 | 图3 原始纯净语音和电话铃声混合的分离结果Fig.3 Separation speech of mixture with original speech and the jangle of the telephone |
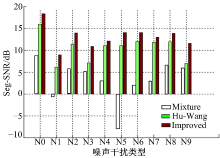
本文通过计算目标语音V0分离前后的Seg-SNR来分析语音信号的分离性能, 并与经典的Hu-Wang算法进行比较, 如图4所示。
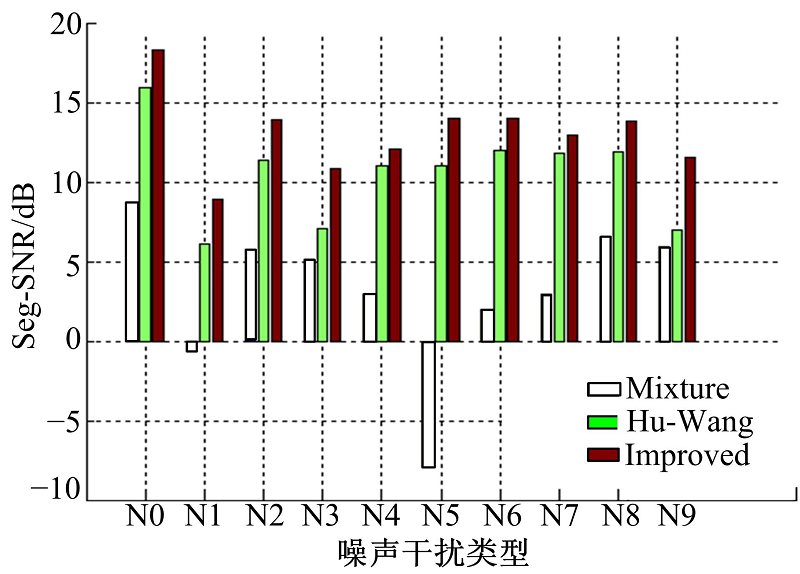 | 图4 本文算法与Hu-Wang算法的Seg-SNR比较Fig.4 Seg-SNR comparison between Hu-Wang and the improved algorithm |
从图4可以看出:在同一个噪声干扰条件下, 经过本文算法分离之后的目标语音Seg-SNR相比于分离之前的Seg-SNR都有非常明显的提高, 与Hu-Wang算法相比, 本文所提算法的Seg-SNR平均提高了2.494 dB。
为了进一步验证算法的有效性和稳定性, 计算改进算法分离之后的目标语音与原始纯净语音之间的相似系数, 并且与Hu-Wang算法进行比较, 结果如图5所示。其中, 相似系数定义为:
e
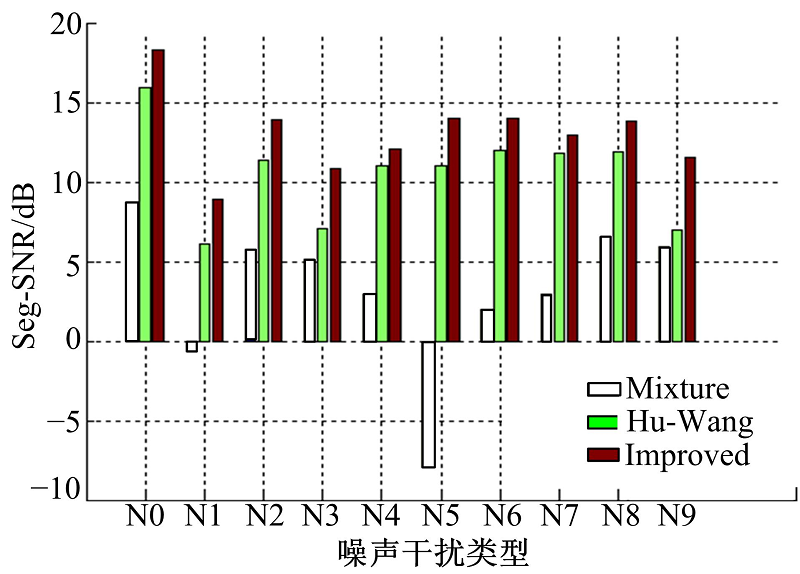 | 图5 本文算法与Hu-Wang算法分离语音的相似系数比较Fig.5 Similarity coefficient comparison between Hu- Wang and the improved algorithm |
由图5可以看出:两种算法分离后目标语音与原始纯净语音的相似系数接近于1, 相比于Hu-Wang算法, 改进算法的相似系数更接近于1, 算法更加稳定, 分离效果更好。
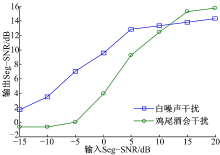
为进一步验证改进算法的抗干扰性, 本文选用了两种干扰噪声(白噪声N1和鸡尾酒会噪声N3), 在目标语音为V0保持不变的情况下, 分别改变这两种干扰噪声的强度使得混合语音信号Seg-SNR在-15~20 dB范围内变化, 其输出Seg-SNR随输入Seg-SNR的变化情况如图6所示。
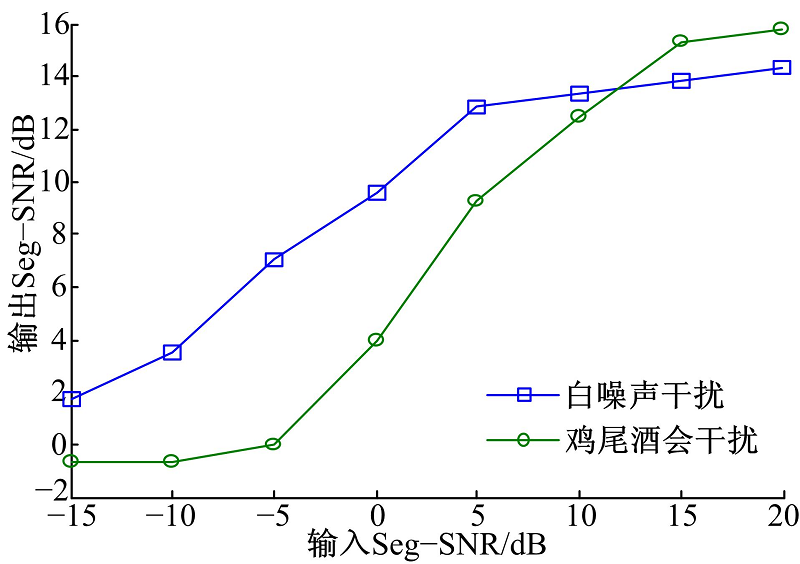 | 图6 输出Seg-SNR随不同输入Seg-SNR的变化Fig.6 Output Seg-SNR variation with different input Seg-SNR |
由图6可以看出:输入Seg-SNR在小于-10 dB范围内, 输出Seg-SNR几乎为0, 这是因为, 噪声干扰在所有的T-F单元上几乎都高于目标语音信号, 以至于输入信号都被噪声干扰覆盖。当输入的Seg-SNR不断增大时, 相应的输出Seg-SNR有较大的提高。但是, 当输入Seg-SNR足够大时, 即大于15 dB时, 虽然目标语音信号在大部分时频单元都高于噪声干扰, 但是经过该算法后仍然丢掉了一些目标语音的能量信息, 因此, 输出Seg-SNR并没有很大的提高。
基于语音信号的谐波特性以及能量特征, 提出了一种对浊语音分离进行改进的基于语音能量特征的CASA改进算法。该算法在以往算法的基础上, 对听觉重组部分进行改进。算法将语音的能量特征应用于听觉重组部分, 通过语音信号高频信道的能量信息, 对目标听觉流中的T-F单元进行处理, 降低噪声对重组后的目标听觉流的干扰, 改善了以往纯净语音的大部分信息。实验结果表明:相比于以往的方法, 本文提出的算法能更好地分离浊语音信号, 具有更稳定的性能, 可以应用于语音识别和语音信号处理的前端处理设备。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|