{kind=link}
{kind=link}
{kind=link}
基于二次预测的粒子滤波算法
[武勇 , 王俊, 曹运合, 张培川]
, 王俊, 曹运合, 张培川]
, 王俊, 曹运合, 张培川]
|
|


作者简介:武勇(1987-),男,博士研究生.研究方向:雷达信号处理,粒子滤波,并行计算.E-mail:wuyongxidian@163.com
为了解决粒子滤波在粒子采样阶段没有利用观测信息的问题,提出一种基于二次预测的粒子滤波算法(SP-PF),并在图形处理器(GPU)上进行了并行实现。首先,从状态转移函数中采样得到预测粒子,通过最小二乘估计,构建一个新的粒子采样器;然后,在预测粒子的基础上,将当前的观测信息引入到粒子的二次预测中,经过两次预测后,每个新粒子都是对当前状态的无偏估计;最后,通过粒子加权的方式对当前状态进行估计,估计完成后再对粒子进行重采样。实验结果表明:该算法的估计精度优于标准粒子滤波(SPF)、辅助粒子滤波(APF)和无迹粒子滤波(UPF),且GPU显著提升了SP-PF的处理效率。
In order to handle the problem that current observation information is not used in the particle sampling stage of the Particle Filter (PF), a novel particle filter algorithm based on Second-Prediction (SP-PF) is proposed and implemented on the Graphics Processing Unit (GPU). First, sampling from the state transition function is performed to obtain the predicted particles, and by least square estimation, a new generator of sampling particles is constructed. Then, on the basis of the predicted particles, the current observation information is introduced into the secondary particle prediction. After double predictions, each new particle is an unbiased estimate of the current state. Finally, the current state is estimated by means of weighting these particles, and after the completion of state estimation, resampling is conducted. Experimental results demonstrate that the proposed algorithm improves the precision of estimation compared with Standard Particle Filter (SPF), Auxiliary Particle Filter (APF) and Unscented Particle Filter (UPF). Furthermore, the processing efficiency of SP-PF is greatly raised by using GPU.
非线性滤波问题广泛存在于信号处理、雷达探测、目标跟踪、卫星导航等诸多领域[1, 2], 这类问题可归纳为存在观测噪声时非线性系统的状态估计问题。贝叶斯概率统计理论为这种状态估计问题提供了一套完整的数学解决方案, 其基本思想是将状态估计问题转化为后验概率密度函数或后验分布的逼近问题, 并通过递归的方式实现对状态空间的迭代估计。对于线性高斯模型来说, 传统的卡尔曼滤波被公认为是最优的贝叶斯估计, 其通过递推式更新有限维统计量来精确计算状态空间的后验分布[3, 4]。然而对于大部分非线性、非高斯的情况, 状态空间后验分布的闭式解不存在或难以求解[5], 这就需要对后验分布进行近似计算。文献[6-7]提出的粒子滤波算法是一种通用的非线性滤波算法, 其采用一系列带有权值的样本点对状态的后验概率分布进行近似, 这种算法本质上是基于状态搜索进行的。首先通过重要性密度函数随机生成若干个粒子, 每个粒子代表一个可能的状态, 然后在状态空间对它们进行传播, 使用似然函数选出最有可能生成当前观测值的若干个粒子点, 并赋予一个较大的权值, 最后通过保留下来的粒子对状态的后验分布进行近似。由于在状态逼近的过程中使用了大量的粒子, 因此该算法具有较高的计算复杂度。粒子滤波因优良的性能, 一经被提出便获得了广泛的应用[8, 9, 10]。但在粒子滤波中存在着两个主要的问题:①当粒子采样不准确时, 如采样得到的粒子位于实际后验分布的拖尾区域, 经过状态搜索后, 绝大部分的粒子权值都会趋于0。这会为后验分布的近似带来很大的误差, 甚至有可能引起滤波发散。因此, 采样粒子的质量直接决定着对后验分布近似的精度。从最优重要性密度函数的表达式可以看出, 在采样粒子时, 应考虑最新的观测信息[7]。基于此, 相继出现了辅助粒子滤波[11]、无迹粒子滤波[12, 13]、扩展卡尔曼粒子滤波[14]以及多种卡尔曼相结合的粒子滤波[15]等方法, 这几种方法都是将当前时刻的观测值引入到粒子的采样过程中, 以提高所选粒子的质量。②在对状态进行迭代估计过程中, 会出现粒子退化以及粒子贫化的现象[16], 减少了状态估计中可用粒子的数量和种类, 增大了状态估计误差, 一般通过重采样技术来缓解这种现象的发生, 即在每次迭代后对粒子进行重新采样, 根据重采样的策略不同, 状态估计的精度也各不相同, 如差分演化粒子滤波及其变种[17]。
综合以上的分析, 对粒子滤波存在问题的改进主要从如何有效利用观测信息提高采样粒子的质量和重采样策略两个方面进行。本文从第一个方面出发, 提出了一种基于二次预测的粒子滤波算法, 称为二次预测粒子滤波(SP-PF)。算法首先使用状态转移密度函数对粒子进行初采样, 获得预测粒子, 然后在预测粒子的基础上, 通过求解一个最小二乘问题, 将当前时刻的观测信息引入到粒子的二次预测中, 并使用似然函数计算新粒子的权值, 最后通过粒子加权对当前的状态进行估计, 估计完后再对粒子进行重采样。SP-PF算法的优势在于:将当前时刻的观测信息融合在粒子采样阶段, 充分利用了可信的观测信息, 避免了传统粒子滤波中观测信息仅用来评判粒子好坏的问题, 提高了位于真实后验分布附近采样粒子的数量, 缓解了迭代过程中出现的粒子退化问题, 进而改善了状态估计的精度。
假设非线性系统的状态模型和观测模型分别为:
式中:xk∈ Rm为k时刻的m维状态向量; yk∈ Rn为k时刻的n维观测向量; f(· )、h(· )为已知的函数; uk、vk分别为分布已知的系统噪声和观测噪声, 它们之间相互独立。
滤波的目的就是利用当前时刻的观测值和上一时刻的状态估计值, 对当前时刻的状态(后验概率密度函数)进行迭代更新。
SP-PF算法是在经典粒子滤波的框架下发展的, 通过蒙特卡洛积分的方法对状态的后验概率密度函数进行估计, 其估计的数学表达式为:
式中:N为采样的粒子数; y1:k为到k时刻所有观测量构成的观测序列y1:k={y1, y2, …, yk};
归一化前, 粒子的重要性权重通过下式获得:
通常选择状态转移密度函数作为重要性密度函数, 即:
在k(k≠ 0)时刻, 首先通过重要性密度函数进行初采样, 获得预测粒子, 每个预测粒子满足:
通过式(5)得到的预测粒子没有包含当前时刻的观测信息, 仅是对当前状态的先验估计。为了使采样粒子包含当前时刻的观测信息, 构建如下最小二乘估计问题:
上式是一个无约束极小化问题, 其代价函数为:
式(6)所述问题可转换为代价函数求导等于0的问题, 即:
利用状态的先验估计xk|k-1, 通过一阶泰勒展开式对观测函数h(xk)进行近似, 即:
式中:Hk=
对J(xk)求导后式(8)可以转化为:
求解式(11), 经整理变形后可得当前状态xk的最新估计为:
将从式(5)采样得到的预测粒子分别代入式(12), 即可获得新的预测粒子。在新粒子中, 不仅包含了对状态的预测值(先验信息), 同时也包含了当前时刻的观测值(后验信息), 即:
通过式(3)计算新粒子的重要性权值, 易得:
对重要性权值进行归一化处理:
利用最新采样的粒子和相应的权值对当前的状态进行更新:
最后, 按文献[6]中的方法进行粒子的重采样, 重采样后各粒子的权值为1/N。
本文提出的基于二次预测的粒子滤波算法可归纳为如下步骤:
初始化:从先验概率分布p(x0)采样得到粒子
(1)根据式(4)选择重要性密度函数q(xk|xk-1, y1:k)。
(2)根据q(xk|xk-1, y1:k)对粒子进行初采样, 得到预测粒子
(3)计算观测函数h(xk)的雅克比矩阵Hk。
(4)根据式(13)进行二次采样, 得到包含观测信息的新粒子
(5)根据式(14)计算粒子的重要性权值, 得到
(6)根据式(15)对权值进行归一化, 得到
(7)根据式(16)对状态进行后验估计, 得到
(8)对粒子进行重采样。
(9)k=k+1, 转到步骤(2)。
通过传统采样获得的粒子仅是对当前状态的先验估计, 这种粒子的生存能力不强, 容易出现粒子分布严重偏离真实分布的情况, 而式(12)恰好可以将观测信息和状态的先验信息有机结合在一起, 充分利用观测信息来提高采样粒子的稳健性。另外, SP-PF算法需要计算非线性观测方程的雅克比矩阵, 为状态估计过程增加了额外的运算量。由于对每个粒子的处理是相互独立的, 因此可通过并行技术(如GPU高性能并行计算)来提高算法的处理效率。
通过式(12)得到的新粒子不仅包含了当前时刻的观测信息, 而且也是当前状态的无偏估计, 证明如下:
将式(9)代入式(1)中的观测方程, 可得:
将式(17)代入式(12), 化解易得:
式中:E[
对于可信观测的非线性滤波问题, 本文所提出的SP-PF算法具有良好的状态估计精度。为了验证SP-PF算法的有效性, 本文将SP-PF与基于序贯重要性采样的标准粒子滤波(SPF)、辅助粒子滤波(APF)以及无迹粒子滤波(UPF)进行了对比。实验使用的状态方程、观测方程分别为:
xk=1+sin(0.04π k)+0.5xk-1+uk-1(20)
式中:系统噪声uk服从Gamma(3, 2)分布、观测噪声vk服从高斯分布N(0, 0.0001), 状态初值为1, 观测周期为1 s, 观测时间为50 s, 粒子数量为50。如无特别说明, 以上参数均为默认值。
实验采用均方根误差(RMSE)作为性能评价指标:
式中:M为蒙特卡洛仿真实验次数, 默认取值为500; xm为估计值;
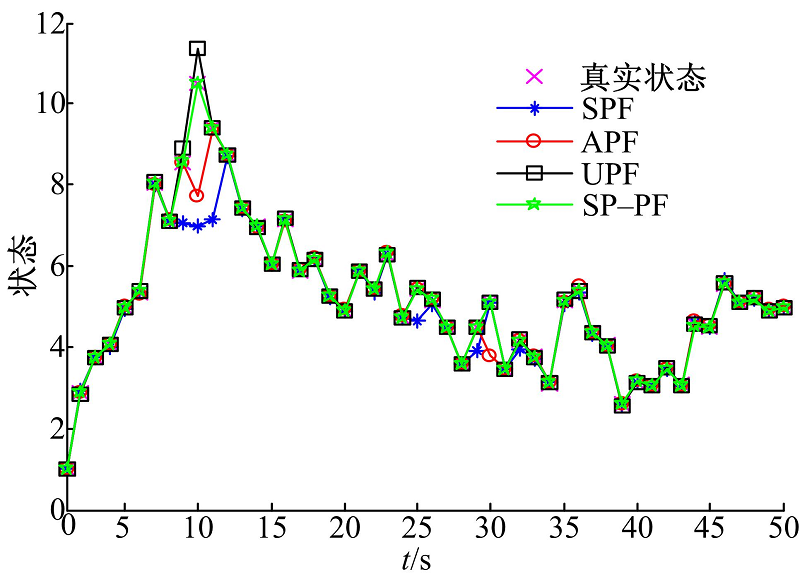 | 图1 不同滤波算法的状态估计结果Fig.1 State estimation results of different filters |
图1为一次仿真实验中4种滤波算法对状态的估计结果。从图中可以看出:UPF和SP-PF都可以很好地对状态进行逼近, 其中, SP-PF的滤波过程更加稳定, 与真值的拟合度更高。相比于UPF和SP-PF, SPF和APF的状态估计过程不够稳定, 在部分采样点上出现了轻微的滤波发散现象。在本次实验中, 从与真值的拟合度和滤波的稳定度两方面考虑, SP-PF优于其他3种算法。
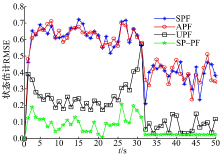
图2给出了经过500次蒙特卡洛实验后SP-PF与其他3种算法的RMSE对比图。由图可知:SP-PF的RMSE明显低于SPF、APF和UPF, 这主要是由于SP-PF的每个粒子融入了最新的观测信息, 与UPF相比, SP-PF没有对状态的后验分布作任何形式的假设。表1分别统计了图2中4种算法的单次平均运行时间、RMSE均值和标准差。RMSE的均值和标准差表征了算法的估计精度和稳定性。从表中可以清楚地看出:与SPF、APF和UPF相比, SP-PF的RMSE均值和标准差是最小的, 说明了SP-PF具有更高的估计精度和更强的稳健性。在算法的平均运行时间方面, SPF最短, SP-PF和APF次之, UPF最长。由于SP-PF需要计算观测方程的雅克比矩阵, 为状态估计过程引入了额外的运算, 因而导致其运行时间略高于SPF。APF在每次迭代中需要对粒子进行两次采样, 两次权值计算和两次重采样, 且每次的处理过程类似, 因此APF的平均运行时间约为SPF的两倍。由于UPF将无迹卡尔曼滤波器(UKF)作为粒子产生器, 每个粒子均需要通过运行UKF来产生, 因此UPF的运行效率最低。
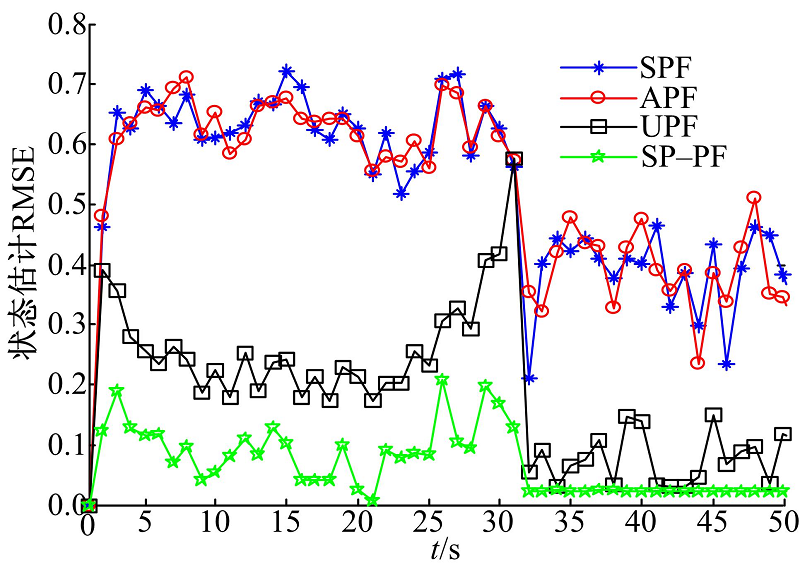 | 图2 不同滤波算法的RMSE对比图Fig.2 Comparison of the RMSE of different filters |
| 表1 不同滤波算法的RMSE均值、标准差和平均运行时间 Table 1 RMSE mean, RMSE standard deviation and average running time of different filters |
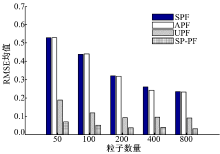
图3给出了粒子数量取不同值时, SPF、APF、UPF和SP-PF算法的RMSE均值变化情况。显然, 增加粒子数对改善算法估计精度是有益的, 随着粒子数的增加, 4种滤波算法的估计精度逐渐提高, 并趋于平稳。此外, 在粒子数量取不同值的情况下, SP-PF算法的误差均值均低于其他3种算法, 且SP-PF算法可以使用更少的粒子, 获得更高的性能, 进一步说明了该算法的性能优于其他3种滤波算法。
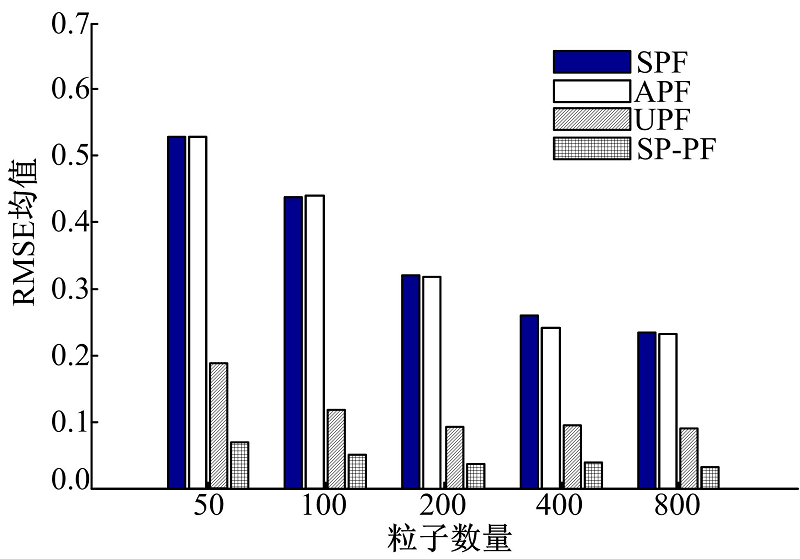 | 图3 粒子数量对算法性能的影响Fig.3 Effects of particle number on the performance of different filters |
针对粒子滤波算法在实际应用中存在的运算量大、处理效率低的缺点, 以SP-PF算法为例, 在英伟达型号为Tesla K20的图形处理器(GPU)上对其进行了并行实现, 并与CPU的处理时间(以Matlab处理时间为代表)进行了对比, 结果如表2所示。由表2可知:GPU实现的处理时间均达到了毫秒级, 且随粒子数的增加变化缓慢, 表现出了较强的数据扩展性, 与CPU的处理时间相比, 获得了最高144倍的加速性能, 极大地提高了SP-PF算法的处理效率, 这主要得益于GPU中的上千个并行运算核。因此, GPU为实现粒子滤波算法的在线处理提供了一条有效途径。
| 表2 SP-PF在CPU和GPU上实现的处理时间对比 Table 2 Comparison of the processing time of the SP-PFimplemented on CPU and GPU |
传统粒子滤波在处理非线性滤波问题时所用的粒子是通过状态转移函数从上一时刻的粒子中采样得到的, 由于在采样粒子中没有任何关于当前观测值的信息, 容易出现粒子分布严重偏离真实后验分布或粒子退化的情况, 进而影响了状态估计的精度。针对这种情况, 本文提出了一种基于二次预测的粒子滤波算法, 其基本思想是将粒子采样分为两个阶段进行。首先采样得到预测粒子, 然后通过最小二乘估计, 将观测信息用于对预测粒子的采样中, 得到包含观测信息的新的预测粒子, 最后利用这些新粒子对状态进行估计。由于在粒子采样中融入了观测量信息, 且所得到的新粒子都是对当前状态的无偏估计, 因此促进了采样粒子向高似然区域的移动, 提高了各个粒子与真实状态之间的关联性, 降低了粒子分布严重偏离真实后验分布的风险, 改善了状态估计的精度。通过计算机仿真, 将该算法与标准粒子滤波、辅助粒子滤波和无迹卡尔曼粒子滤波进行了对比, 结果显示该算法的估计精度更高、稳定性更好。由于该算法在二次预测中需要计算观测函数的雅克比矩阵, 接下来的工作可从降低算法运算量方面进行深入研究。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|