{kind=link}
多方式诱导下通勤出行链交通方式组合选择行为模型
[赵丹1  , 邵春福
, 邵春福2 , 王军利1 , 李娟2 , 王博彬2 ]
, 邵春福|
|


作者简介:赵丹(1983-),女,博士研究生,讲师.研究方向:城市交通规划与管理.E-mail:zhaodanbjtu@163.com
从出行链的角度出发研究多方式诱导信息对通勤出行方式选择的影响。通过RP&SP调查获取通勤者的实际和意向出行链数据,建立了综合考虑尺度系数差异、非显化异质性效应和参照依赖效应的mixed logit模型,并设计仿真方法求解。结果表明,尺度系数差异解释了RP数据与SP数据融合时隐含的方差差异;异质性和参照依赖效应的引入可以度量偏好差异较大的随机变量的影响程度,反映随机变量的偏好分布;综合考虑3种因素的mixed logit模型比多项logit模型和普通mixed logit模型的精度高,解释能力更强。参数标定结果表明:多方式诱导信息服务对引导小汽车通勤出行链转向其他交通方式有积极作用,有利于从源头上缓解道路交通拥堵。
To study the influence of multi-modal guidance information on the travel mode of commuters from the viewpoint of trip chain, A Revealed Preference (RP) and Stated Preference (SP) survey was carried out to get the revealed and stated trip chain data. Then a mixed logit model, which takes scale parameter difference, heterogeneity and reference dependence effect into account, was established. A simulation method was proposed to complete estimation. The estimation results show that the introduction of scale parameter difference is helpful to explain the unobvious variance differences between RP data and SP data when they are combined together; the adoption of heterogeneity and reference dependence effects are not only conductive to measure the impacts of some variables, whose random preferences vary obviously across individuals, more accurately, but also benefits to reflect the preference distribution of random variables. The accuracy and predictive capacity of the mixed logit model considering the three aspects are better than the multinomial logit model and the ordinary mixed logit model. It is also manifested that multi-modal guidance information service contributes to encourage commuters to shift from car trip-chain to other modes, and helps to ease traffic congestion at source.
通勤出行链(Commute trip chain)是指通勤者以工作单位为停驻点, 从家出发再返回家的活动和出行组合[1]。出行链中每次出行选择的出行方式构成的组合即为出行链交通方式组合。一般, 通勤者第一次出行选择的交通方式会对整条出行链的交通方式起到决定性作用。例如, 诱导通勤者第一次出行选择公共交通, 则其后续选择公共交通的可能性变大, 可以达到从源头上控制小汽车使用量的目的。
目前城市交通诱导信息内容和服务对象均比较单一, 主要为道路交通使用者服务。针对这种情况, 本文提出多方式诱导的概念, 其实质是多种交通方式运行和运营信息的综合利用, 且形式上保证实时动态。其中的多方式既指信息提供媒介的多样性, 也蕴含信息内容与多类交通方式相关的含义。多方式诱导从优化出行链的角度出发, 通过提供出行前和出行中的动态信息服务谋求减少机动车出行, 增加公交系统和换乘出行。但信息能否发挥作用取决于通勤者的反应, 因而研究多方式诱导下的通勤者的选择行为十分必要。
目前大多数文献的研究对象均为单次出行的交通方式选择[2, 3, 4], 没有延伸到出行链范畴, 割裂了出行间的相互联系。并且, 本文的背景条件— — 多方式诱导, 是尚未实施的智能交通手段, 该背景下的出行行为数据只能依靠RP(Revealed preference)调查与SP(Stated preference)调查相结合的方法获取。RP-SP融合数据本身的特性对模型有一定要求, 大量文献忽略了这些特性, 仅采用多项logit(Multi-nominal logit, MNL)[5]模型、巢式logit(Nested logit, NL)[6]模型和一般mixed logit模型[7]直接应用融合数据, 降低了模型的解释能力和精度。
本文基于多方式诱导下通勤出行链调查数据, 深入分析了RP-SP融合数据特性, 建立了综合考虑尺度系数差异、非显化异质性效应和参照依赖效应的mixed logit模型。研究了多方式诱导下通勤出行链交通方式组合选择行为, 分析其内在规律, 并论证了模型的优越性。
RP数据, 又称实际偏好数据, 是根据现有交通条件设置选择集, 通勤者的选择结果反映的是实际偏好, 该方法在社会经济环境变化不大或没有新的政策实施的情况下, 可以很好地用于分析出行行为。SP数据, 又称意向偏好数据, 在研究对象区域尚未达到某标准或未实施某政策时, 给出假想选择方案集, 得到出行者的意愿偏好, 以弥补RP数据的不足。在RP数据中融入SP数据, 不仅能够消除单独使用SP数据产生的偏差, 也增强了模型对出行环境变化下出行者潜在选择行为的预测和解释能力[4, 8], 尤其是两种数据反映出的选择行为受到同一变量的影响近似相同时, 优势更加明显[9, 10]。纵然RP-SP融合数据具备很多优点, 但以下几个问题不容忽视:
(1)尺度系数差异。效用函数建立过程中, 难以测量和量化的影响因素通常作为非显化效用被计入选择方案效用函数的随机误差项中。尺度系数来源于误差项的分布, 与误差项的方差成反比[11]。由于RP数据和SP数据收集方法、选择方案设置不同, 二者随机误差项的方差必然存在差异, 因此使用RP-SP融合数据时必须考虑二者尺度系数的差异。
(2)被访者的非显化异质性效应。每个通勤者做出选择时都存在一些难以观测到的偏好差异, 称为非显化异质性。例如, 更愿意使用小汽车, 为个人偏好异质; 对费用变化十分敏感, 一旦出行费用增加, 便会改变选择结果, 为属性偏好异质。非显化异质性效应存在于RP和SP调查的各个环节, 很多假设出行者具有共同偏好的模型被证实精度低于考虑异质性的模型[8, 10, 12]。
(3)SP选择结果对RP选择结果的参照依赖性。被访者的实际出行经验会对虚拟情景下的选择产生一定作用, SP选择结果受到RP选择结果的影响称为参照依赖效应。若不将参照依赖效应作为单独的变量在效用函数中列出, 这部分影响会被误差项分担, 由此降低模型精度; 并且, 数据集中被访者的选择行为惯性的程度也不完全相同, 建模时还要考虑参照依赖效应的异质性[13]。
基于效用最大化理论的离散选择模型是分析出行行为的主要工具。早期的研究多使用MNL模型建立RP-SP融合数据模型, 其中一些文献直接忽略尺度系数差异[4, 5], 还有一些通过改变SP数据的尺度以保证某些关键变量的系数与RP数据接近, 然后将新的SP数据和RP数据融合进行参数估计[14, 15], 但MNL模型完全不能解释异质性效应, 且存在IIA(Independent from irrelevant alternative)特性。Hensher和Bradley[6]利用NL模型解决了尺度系数差异的问题, 但其不能有效地解释SP数据集中重复观测同一对象时, 数据间可能存在的相关性, 也不能考虑个体异质性。基于上述研究, Brownstone[16]利用假设待估参数为随机分布的mixed logit模型使RP数据和SP数据得到了更好的融合, 不仅避免了IIA特性, 也突破了非显化异质性限制问题。随后, mixed logit模型在RP-SP融合数据领域得到了广泛应用[8, 9, 10]; 但是, 这些研究大多仅考虑非显化异质性, 在包容RP-SP融合数据的尺度系数差异和参照依赖效应的特性上显得不够全面。基于上述分析, 本文旨在建立一个包含尺度系数差异、非显化异质性和参照依赖效应的改进mixed logit模型。
结合前面提到的RP-SP融合数据的3点特性, 建立mixed logit模型的效用函数表达式为:
式中:下角i表示方案; n表示通勤者; t表示场景。式中的选择效用由3部分构成:
(1)显化效用β n、Xint。β n和Xint分别为关于选择方案影响因素的行向量和列向量, β n是服从某一分布的随机参数向量, 随通勤者n的不同而变化, 与选择方案i和场景t无关, 体现了异质性效应。β n固定与否是mixed logit与MNL模型的根本差别。
(2)参照依赖效应θ n[(1-
(3)误差项ε int。ε int与β n和Xint独立, 包含了能够影响选择结果却难以测得的变量; 对于任意通勤者和交通方式, 同一场景t中的ε int独立且服从同一Gumbel分布, 不同场景中ε int也相互独立, 但其分布参数不一定相同; ε int的尺度系数λ nt定义为:
式中, λ 为SP数据的尺度系数。λ nt允许RP数据和SP数据的尺度系数不同, 一般设RP数据的尺度系数为1, 然后再求λ 。两种数据尺度参数的比值(用φ 表示)用于比较二者方差的大小, φ > 1说明RP数据的方差大于SP数据; φ =1说明二者方差相等; φ < 1说明SP数据方差更大。
令:
假设
那么在
式中:f(
由于式(6)中
(1)给予σ 初值, 利用Latin超立方序列抽样法从f(
(2)根据
(3)重复K次步骤(1)和(2), 取K次抽样的算术平均值作为仿真概率值

若
(4)确定通勤者n在场景t下的选择结果, 建立通勤者n的极大似然函数, 如式(8)所示:
式中:dint为指示变量, dint=1表示通勤者n在场景t中选择了方案i, 否则为0。
(5)根据式(8)构造模型的仿真对数极大似然函数:

(6)不断改变式(9)中σ 的值, 利用梯度法使LL(σ )取得最大值。
调查中出行链交通方式组合分为3类:
(1)小汽车:出行链中所有出行均使用小汽车, 没有使用轨道交通、路面公交、出租车。
(2)停车换乘公共交通(P+R换乘):①出行链中某次出行使用小汽车(公共交通), 而其他出行使用公共交通(小汽车); ②出行链中某次出行既使用了小汽车又使用了公共交通。
(3)公共交通:出行链中的每次出行均使用公共交通, 并且完全没有使用小汽车。
由于调查对象为当日使用过小汽车的通勤者, 因此设置RP调查部分出行链交通方式组合选择方案集为{小汽车, P+R换乘}; SP调查询问了小汽车通勤者选择公共交通方式的意愿, 设置该部分出行链交通方式组合选择方案集为{小汽车, P+R换乘, 公共交通}。
选取周边配套交通方式完备的北京市回龙观大型社区作为调查区域, 实施网络调查, 调查软件内嵌RP调查和SP调查两个模块, 如图1所示。图中, RP调查包含了3部分内容。其中, 实际出行链部分包含了通勤者当天所有出行使用的交通方式、行程时间及费用等信息, 进而统计整条出行链的方式组合、时间、费用。多方式诱导需求调查则是基于前面得到的实际出行链, 在每次出行前和出行中向被访者提供图中所示的8种信息, 被访者根据需要选择其中3项, 然后采用均匀设计的方法将3个被选项组合成不同SP调查场景, 获取被访者在这些假想场景下的出行行为, 得到被访者的意向出行链。SP调查情景主要根据通勤者每次出行前和出行中选择的诱导信息项产生, 调查场景中信息项的值由调查软件随机生成, 生成规则如表1所示。
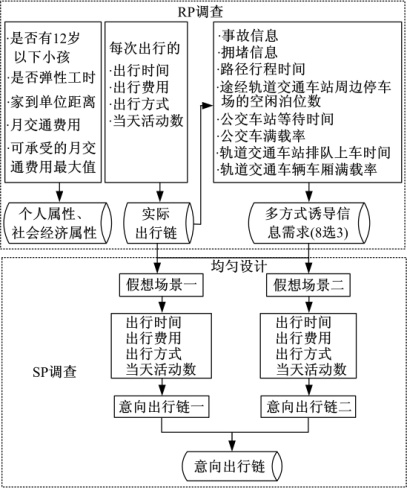 | 图1 通勤出行链RP and SP网络调查模块和内容Fig.1 RP and SP online survey module and investigation contents of commute trip chain |
| 表1 SP调查场景中随机数的生成规则 Table 1 Random number generation rules in SP choice situation |
表1中, HRP为与实际出行链相对应的该次出行的行程时间。考虑到出行链中第一次出行方式对后续方式选择的重要影响, 整理数据时主要选取SP调查中第一次出行前和第一次出行中的选择行为数据, 得到两条意向出行链。
调查于2012年6~8月实施, 回收的367份合格问卷中有效问卷175份。最终本文应用的数据为:RP数据175条, SP数据350(175× 2)条。
考虑到出行链整体与单次出行的差异, 以及RP-SP融合数据本身的特性, 确定影响通勤出行链交通方式组合选择的变量及其说明(见表2)。每个通勤者面临的SP调查场景由其选择的多方式诱导信息项决定, 若信息项选择不同, 则场景不同。为了避免场景不同导致的模型形式差异, 与时间相关的信息项均计入出行链时间, 以变量X7的形式带入模型。调查中拥挤度等信息项被选择的频率较低, 对应数据稀少, 本文采用引入常数项的方法对这些因素产生的作用做整体衡量。
| 表2 模型变量说明 Table 2 Explanations of variables in the mixed logit model |
构造选择方案的效用函数Uint, 分别是:RP数据中小汽车和P+R换乘的效用函数U1n, RP和U2n, RP; SP数据中小汽车、P+R换乘和公共交通的效用函数U1n, SP、U2n, SP和U3n, SP。
设定抽样次数K=525, 对数似然函数收敛标准为相邻两次迭代系数估计值的改变量Δ
表3给出了4种模型的参数估计结果。模型1未考虑RP和SP数据集的方差差异, 直接将二者合并, 建立MNL模型; 模型2假设RP、SP数据集的方差不同, 用尺度系数乘以SP数据, 使之具有与RP数据相同的方差, 然后建立尺度化MNL模型, 并估计系数, 详细步骤参见文献[15]; 模型3为包含尺度系数差异和通勤者对各选择方案本身及某些属性偏好(异质性)的mixed logit模型, 但没有考虑SP调查中被访者的参照依赖效应; 模型4为综合考虑上述3种因素的mixed logit模型。
| 表3 四种通勤出行链交通方式组合选择模型的参数估计结果 Table 3 Four different models’ estimation results related to combined mode choice of commute trip chains |
表3中, 第3列Uint表示变量所在的效用函数; 尺度系数比φ 用于分析RP数据和SP数据的方差情况, ρ 2用于检验模型精度高低, ρ 2称为优度比, 计算公式为:
式中:LLmax为对数似然函数的最大值; S为样本量(本文中S=525); L(0)为所有变量系数均为0时的对数似然函数值。
ρ 2越大模型精度越高。一般认为ρ 2的值大于0.2, 模型精度即达到标准[18]。
分析表3中数据, 解释各变量对通勤出行链交通方式组合选择产生的影响, 比较模型的精度。
(1)模型精度比较分析
从模型1到模型4, 模型精度逐渐增大, 且mixed logit模型的精度整体高于MNL模型。考虑参照依赖效应的mixed logit模型精度最高, 说明此变量的引入对解释通勤出行链交通方式组合选择行为及提高模型精度大有帮助。
(2)数据方差比较分析
尺度系数比φ 用于比较RP数据和SP数据的方差。模型1直接假设二者的方差相等, 因此φ =1; 模型2的尺度系数比小于1, 说明尺度化MNL模型中SP数据集的方差更大, 但其t检验结果不显著, 无法拒绝RP和SP数据集具有相同的方差的假设; 两个mixed logit模型的尺度系数均大于1, 表明mixed logit模型中RP数据集方差更大。两类模型所得结果截然相反的原因可解释为:与MNL模型相比, mixed logit模型的非显化效用被随机参数部分和误差项分为两块, 随机参数部分有效分担了在MNL模型中全部来自于误差项的方差。模型4的尺度系数比大于模型3, 说明被访者的选择习惯(参照依赖效应)是非显化效用的重要组成部分, 故而成为影响方差大小的重要因素。参照依赖效应的显化可以降低误差项的方差。
(3)固定参数的影响
分析出行链费用X2/lnX3(X3为月最大可承受交通费用)对P+R换乘模式的影响时发现:通勤者面临出行链费用相等的情况时, 其月交通费用的承受能力越小, 选择P+R换乘模式完成出行链的可能性越大; 当通勤者对月交通费用的承受能力相同时, 出行链费用越高, 通勤者选择P+R换乘方式完成出行链的可能性越大。弹性工时X4对P+R换乘模式的选择具有显著的负效用, 尤其是在仅有两个选择方案的RP调查中, 工作时间没有严格规定的通勤者更倾向于选择小汽车完成出行链。活动引发出行, 出行链包含的活动数(X6)越多, 则出行次数越多, 为了避免时间成本上升以及换乘、等待带来的额外体力消耗, 通勤者倾向于选择更加舒适便捷的小汽车完成出行链。CCRP是U1n, RP的固定项, 用于概括除模型变量之外其他所有因素产生的影响, 当CCRP被设为随机参数时, 均值和方差均未通过检验, 因而确定其为固定参数, CCRP大于0说明还有其他因素对小汽车方式的选择产生正向影响, 有可能是小汽车本身的优势, 也有可能是通勤者自身特性。
(4)随机参数的影响
出行链时间X7对3种交通方式的选择都有显著的负作用, 而泊位数信息的影响则各不相同。轨道交通车站周边停车场的可用泊位数越多, 选择小汽车和公共交通方式的概率越下降, 但选择P+R换乘方式的概率增加, 这一结果肯定了泊位数信息对引导通勤者减少使用小汽车有正面作用。对于基础设施建设的启示是:扩大P+R换乘停车场的规模, 有利于促进通勤者从单纯的私人交通向公共交通方式转移。
CCSP和PCSP均大于0, 可知存在除模型变量以外的其他因素对两种方式的选择有正影响, 二者的标准差全部通过检验, 表示样本对小汽车和公共交通的偏好异质性是显著的, 但PCSP的标准差很大, 反映出样本对两种交通方式的偏好态度正负并存。
参照依赖效应(Y)系数的均值为正, 说明样本整体的选择惯性较强, 大部分样本在SP场景中做出的选择与其实际选择行为一致, 换言之, 大部分使用小汽车和P+R换乘模式完成出行链的通勤者不会轻易放弃现在的选择; 参照依赖效应的标准差很大, 说明存在部分通勤者对目前采用的交通方式并不满意, 这部分人更倾向于放弃当前选择, 表现出对新交通方式的偏好, 这也是PCSP为正数的原因。
考虑到4个模型的随机误差项方差不同, 不能以同一变量在不同模型中参数值的大小来比较其影响程度的高低(横向比较)。但是, 可以通过比较同一模型中不同变量参数值的大小(纵向比较)来判断通勤者对各影响因素变量的偏好。显然, 与泊位数信息相比, MNL模型中出行链时间对通勤出行链交通方式组合选择的影响非常微弱, 远低于mixed logit模型中此变量产生的影响; 这一现象表明:考虑个体异质性的模型可以更加准确地度量某些变量的作用, 而全部样本都具有相同的偏好(全部倾向于选择出行链时间最短的交通方式)的假设显然不合理。并且, 相对于CCSP, 模型4中PCSP的影响有所下降, 再次验证了样本整体具有较强选择惯性的事实, 即:公共交通方式是RP场景中没有的选择方案, 保持当前选择会降低通勤者对该新交通方式的偏好。
(1)尺度系数比指标反映了RP数据与SP数据在融合时隐含的差异, 而异质性和参照依赖效应的引入则提高了模型精度, 不仅帮助mixed logit模型准确度量了随机偏好差异较大的变量的影响程度, 也可以根据随机变量的标准差判断出通勤者对出行链交通方式组合选择的偏好态度是否一致。
(2)模型变量参数估计结果表明:调查对象群体对小汽车出行链的正向偏好比较一致, 对公共交通的偏好态度正负并存, 选择行为惯性较强。当诱导信息显示可用泊位充足时, 通勤者选择P+R换乘的概率明显增加, 可知此信息服务有利于引导通勤出行链从小汽车转向其他交通方式; 减少每天的活动数可以降低通勤者使用小汽车的概率或频率, 相应地, 选择P+R换乘和公共交通的可能性会增加, 达到从源头上缓解拥堵的目的。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|