{kind=link}
面板数据模型分析及交通事故预测
[孙璐1, 2  , 徐建
, 徐建1, 3 , 崔相民4 ]
, 徐建|
|


作者简介:孙璐(1972-),男,教授,博士生导师.研究方向:交通工程,道路工程.E-mail:sunl@cua.edu
构建了一种基于面板数据的空间非集计模型——负二项面板模型,包括混合效应、固定效应和随机效应3种类型,以同性质路段为研究单元,选取道路线形、交通特性、土地利用和降雨量等影响因素,利用事故率比例指标IRR,分析和预测未受伤事故、受伤事故、死亡事故和事故总数等4种类型事故,并通过F检验和Hausman检验以及对数似然值和离差信息准则DIC,对比分析3种类型模型的拟合效果。发现协变量对各类型交通事故的影响作用和统计显著性不尽相同,如限速每增加1.609 km/h(1 mile/h),未受伤事故、受伤事故、事故总数分别减少3.89%、2.24%和2.79%,而死亡事故增加6.38%。研究结果表明:负二项面板固定效应模型比混合模型和随机效应模型更优,另外越严重的事故,模型拟合效果越好。
Spatially disaggregated panel data models using negative binomial process, including pooled model, fixed-effects model and random-effect model, were developed. The contributing factors, such as roadway geometrics, traffic characteristics, land usage and rainfall were collected. Incidence Rate Ratio (IRR) and homogeneous segments were employed for analysis and prediction of crash count, which contains Property-Damage-Only (PDO) crashes, injury crashes, fatal crashes, and total crashes. Meanwhile, F test and Hausman test, log-likelihood value and Deviance Information Criterion (DIC) were used to compare the performance of the three types of models. It is found that the effects and statistical significance of covariates on the four types of crashes are not the same. For example, if the speed limit is increased by 1.609 km/h, the PDO rate, injury crash rate and total crash rate are reduced by 3.89%, 2.24% and 2.79%, respectively; however, the fatal crash rate is increased by 6.38%. Results show that the fixed-effects panel negative binomial model surpasses the pooled model and random-effect model, and the modeling is even better for crash count associated with more severe injuries and fatalities.
交通事故分析是为了研究交通事故总体分布情况、发展趋势以及影响因素对事故的作用和相互关系, 从宏观上定量地认识事故的本质和内在规律性, 能够为道路线形设计、安全改善措施、政策法规制定等提供重要依据。国内外学者对交通事故进行了大量研究, 国内学者主要对交通事故数据进行统计描述, 利用统计指标对道路进行安全性评价或事故预测[1, 2, 3]。而国外学者的研究工作相对广泛而深入, 关于研究单元, 有城市层面[4]、县域层面[5]、人口普查区层面[6]、路段层面[7]等; 关于影响因素, 主要集中于道路线形和交通特性对交通事故的影响, 如选取路宽、分隔带宽度、平纵线形、限速、年平均日交通量(AADT)、车辆行驶里程(VMT)、设计小时交通量等因素[8, 9]; 关于模型, 有负二项模型[10]、对数正态模型[11]、混合回归模型[12]、零膨胀模型[13]、空间模型[14]等。
从国内外的研究工作可知:①目前研究多集中于截面数据, 即对某一定时期内交通事故数据分析, 而较少考虑事故的时间相关性, 较少研究面板数据[15, 16, 17]; ②目前研究多集中于事故黑点、特殊路段等, 影响因素多选取道路线形和交通特性等, 而对土地利用、自然环境、气候等因素研究较少; ③目前研究多选取区域水平的研究单元, 而根据Openshaw在1984年提出的修正面积单元问题(MAUP)[18], 不同的单元层面, 有不同的统计推断和解释, 区域水平的研究单元往往存在异质性问题, 导致研究存在不足。
针对目前研究工作的不足, 本文构建一种基于面板数据的空间非集计模型— — 负二项面板模型, 包括混合效应、固定效应和随机效应3种类型, 以同性质路段(指路段上几何线形与交通特性等指标一致)为研究单元, 选取道路线形、交通特性、土地利用和降雨量等10种影响因素, 以美国德克萨斯州奥斯汀市2007~2011年交通事故为研究数据, 分析并预测未受伤事故、受伤事故、死亡事故和事故总数等4种类型交通事故, 同时对比混合效应模型、固定效应模型与随机效应模型的拟合优良性。
本文构建负二项面板模型研究交通事故, 为了便于分析, 首先分别介绍标准泊松模型和负二项模型, 其次引入泊松面板模型, 最后建立负二项面板模型。泊松模型是最早应用于交通事故研究的回归模型, 它的形式为:
式中:Y为随机变量, 表示交通事故起数(本文共有4种类型:未受伤事故起数、受伤事故起数、死亡事故起数和事故总起数); yi为Y的具体观察值, i=1, 2, 3, …, n, 即共有n条路段单元。
泊松模型具有等散布性, 即均值与方差相等, E(Y)=Var(Y)=λ i。交通事故起数与协变量(即交通事故影响因素)之间的关系为:
式中:β k为第k个协变量的系数; β 为系数向量; xik为对应于第i条路段的第k个协变量; xi为协变量向量。
由于泊松模型响应变量的均值和方差相等, 而实际交通事故的方差往往大于均值, 所以该模型有较大的局限性。在泊松模型的基础上, 负二项模型由于不受这样的约束, 而得到广泛的应用。负二项模型的均值方程包含随机变量ε i, 并服从伽马分布, 即ε i~Gamma(θ , θ ), 其表达式为:
式中:ρ 为过度散布系数, 表示变量的散布程度, ρ =1/θ , 当ρ =0时, 负二项模型变为泊松模型。
面板数据模型通常有3种形式:①混合估计模型(Pooled regression model):从时间上和截面上均不存在显著性差异, 那么即可直接把面板数据混合在一起用普通最小二乘法(OLS)估计参数; ②固定效应模型(Fixed effects regression model):对于不同截面或不同时间序列, 模型的截距不同, 则常采用在模型中添加虚拟变量的方法估计回归参数, 即为固定效应模型; ③随机效应模型(Random effects regression model):如果固定效应模型的截距项包括截面随机误差项和时间随机误差项的平均效应, 并且这两个随机误差项都服从正态分布, 则成为随机效应模型。对于面板数据模型的选择, 通常采用F检验决定选用混合模型还是固定效应模型, 然后用Hausman检验确定建立随机效应模型还是固定效应模型。泊松面板随机效应模型的条件联合分布为:
式中:参数α i~gamma(θ , θ ), 均值E(α i)=1, 方差Var(α i)=1/θ ; α i为路段i的随机效应; Ti为面板数据的时间单元数(本文选取的交通事故数据为2007~2011年, 即Ti=5)。
将伽马分布α i积分后, 式(4)变为非条件分布, 表达式为:
对于泊松面板混合效应模型, 由于将面板数据合并后估计参数, 因此表达式为:
式中:α 为路段效应总和。
而对于泊松面板固定效应模型, 路段效应α i可取任何值。若在交通事故总数
前面分别介绍了标准泊松模型、负二项模型和泊松面板模型, 下面建立负二项面板模型。负二项面板分析中, 个体效应不应用于平均事故率, 而应用于分散度参数分布。当路段上分散度随机变化时, 随机效应模型是最合适的, 这类似于线性或连续的面板事件:个体效应在线性随机效应模型中随机分布, 而在线性固定效应模型中取任何值[17]。在标准随机效应事件中, 根据贝塔分布(参数为ϕ 和φ ), 分散度在各路段上随机变化, 而伽马分布是一种特殊的贝塔分布, 能很好地拟合随机效应负二项模型, 表达式为:
式中:λ it=exp(x'itβ ); δ i为分散度参数。
更广义的随机效应负二项模型中, 分散度参数是随机变化的, 1/(1+δ i)~beta(φ , φ )。由此可得, 路段i的联合分布为:
与泊松面板混合效应模型类似, 负二项面板混合效应模型表达式与式(6)一致。而对于负二项固定效应模型, 同样与泊松面板模型类似, 路段上的分散度参数可取任意值。Hausman等学者研究发现[19], 当采用条件似然估计方法时, 分散度参数将消失, 而系数β 可被估计, 不必处理所有的固定效应参数。类似于泊松面板模型, 基于交通事故总数
对于混合效应、固定效应和随机效应面板模型的选择问题, 可采用F检验和Hausman检验以及比较模型的对数似然值和拟合优度, 本文将在第3节研究结果分析中予以介绍。
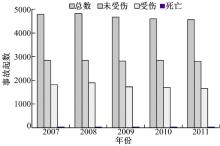
本文选取了美国德克萨斯州奥斯汀市2007~2011年交通事故资料作为研究数据。未受伤事故起数(仅财产损失事故PDO)、受伤事故起数、死亡事故起数和事故总起数等4种类型交通事故作为自变量, 图1为这4种类型事故随年份的分布数据图。从图1可知, 每年交通事故起数保持平稳, 变化较小, 但总体上呈微弱减少趋势。同时, 为了避免修正面积单元问题(MAUP), 将奥斯汀市的州级道路网(由德克萨斯州交通厅管理的路网)切割成1824条同性质路段作为研究单元, 平均路段长度为0.462 km(0.287 mile), 其中90%以上的路段集中于0~1 mile。
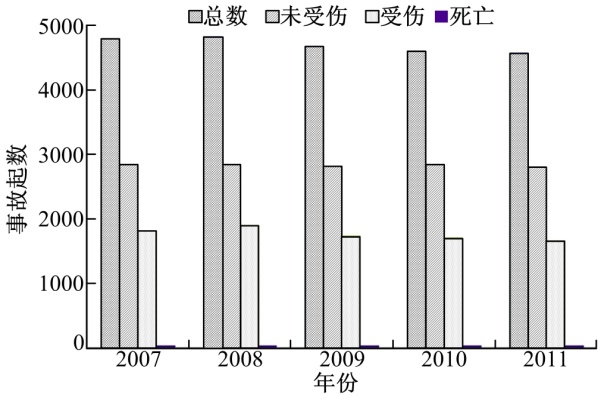 | 图1 奥斯汀市各类型事故的分布图Fig.1 Distributions of all types of crashes in Austin |
然后, 利用ArcGIS软件将每年各类型交通事故与同性质路段合并, 即可得到每条路段上每年各类型交通事故起数。本文研究的协变量选取了车辆路段行驶距离(VMT)、平均路肩宽度、车道数、平曲线长度、平曲线度数、最大限速、卡车比例、降雨量、人口密度和就业密度等。其中道路线形与交通特性指标由德克萨斯州交通厅提供的RHiNo和GeoHiNi两大数据库通过计算获得, 其中RHiNo数据库包含了该州交通厅管理的所有道路的几何线形、标识符号、交通特性等一百多个指标, GeoHiNi数据库包含了所有道路中曲线路段的平纵横等几十个指标。降雨量与土地利用指标从美国国家统计局网站获取, 这两类指标都是基于人口普查区层面, 利用ArcGIS软件的线性参考功能将两类指标与相应的路段匹配。需说明的是, 奥斯汀市的土地利用资料无法获得, 由于土地利用类型包含商业用地、居住用地、农业用地、混合用地等, 而人口密度和就业密度在一定程度上能反映某区域的土地利用类型, 因此选取这两类密度指标替代土地利用类型。另外, 平均路肩宽度指外侧路肩和内侧路肩的平均值, 中央分隔带宽度不包含内侧路肩宽度, 平曲线度数指每一百英尺对应的曲线度数。交通事故对应的年份作为哑变量(是为1, 其他为0)应用于模型中, 其中2007年为参考变量, 2008~2011年为协变量。同性质路段的自变量与协变量的统计情况(均值、标准差、最小值和最大值)如表1所示。
| 表1 路段的自变量和协变量统计结果 Table 1 Summary statistics of dependent variables and covariates for segments |
本文运用3类负二项面板模型(混合效应、固定效应和随机效应)分析4种类型交通事故与影响因素的关系。选取了车辆路段行驶距离(VMT)、平均路肩宽度、车道数、平曲线长度、人口密度等多种协变量。近些年研究人员发现, 不同的协变量与交通事故存在不同的主次关系, 其中VMT、AADT(年平均日交通量)与路段长度等影响因素与交通事故起数存在主要关系, 一般情况下保持其他因素不变, VMT(或AADT、路段长度)与事故起数一一对应[6]。因此, 为了提高模型拟合效果, 引入曝光变量。本文将VMT作为曝光变量, 如式(12)所示:
式中:VMTi表示第i条路段上车辆行驶总长度; α 为VMT的系数, 通常情况下曝光变量与事故起数一一对应, 根据Kweon和Kockelman的研究结果[18], 当系数α =1时, 模型有最好的拟合优度和最好的预测效果。
为了全面比较负二项面板模型的三种效应模型, 本文引入F和Hausman两种检验以及对数似然值和离差信息准则(DIC)拟合优度。F检验是为了比较混合效应模型与固定效应模型, 零假设为H0:各路段的效应都相等且为0, 检验表达式在文献[16]中查询。经计算, 未受伤事故的F值为2.38, 受伤事故的F值为2.44, 死亡事故的F值为6.07, 事故总数的F值为2.02, 均拒绝原假设。因此, 固定效应模型相对混合模型更适合本研究数据。
Hausman检验是为了比较固定效应模型与随机效应模型[19], 其基本思路为:在α i于其他协变量不相关的原假设下, 采用OLS估计固定效应模型和采用GLS估计随机效应模型得到的参数估计无偏且一致。若原假设不成立, 则固定效应模型的参数估计仍一致, 而随机效应模型不一致, Hausman检验表达式可在文献[19]中查询。经计算, 本文采用的4种类型交通事故的Hausman检验全部拒绝原假设, 说明随机效应模型估计不一致, 而固定效应模型更合适。
赤池信息准则(AIC)是衡量统计模型拟合优良性的一种标准, 表达式为AIC=2k-2ln(L), 其中, k为参数的数量, L为似然函数; 而离差信息准则(DIC)是基于贝叶斯理论并考虑了模型的复杂性, 它与赤池信息准则(AIC)意义相同, 其表达式为DIC=D
经计算, 三种类型负二项面板模型的对数似然值和DIC如表2所示。
| 表2 三种类型负二项面板模型的对数似然值和DIC Table 2 Log likelihood and DIC for three types of panel negative binomial data models |
从表2可知, 固定效应模型的对数似然值和DIC值在4种事故类型中均最小, 与F检验和Hausman检验的结果一致, 固定效应模型相对于混合模型和随机效应模型来说, 更加合适。值得注意的是, 从表2中发现, 大部分情况下, 随机效应模型的对数似然值和DIC值比混合模型小, 但在少数情况下, 结果却相反。另外, 4种类型事故中, 死亡事故的对数似然值和DIC值最小, 其次是受伤事故和未受伤事故, 而事故总数最大。这说明对于越严重的事故, 模型拟合效果越好, 该结论与Noland和Quddus两位学者的研究结果一致[5]。
经过综合比较, 固定效应模型相对于混合效应模型和随机效应模型更合适, 因此本文以固定效应模型为主分析交通事故与影响因素之间的关系, 并作出相应的预测。负二项面板固定效应模型拟合结果如表3所示。对于未受伤事故, 平均路肩宽度、中央分隔带宽度、平曲线长度、最大限速、卡车比例、降雨量、人口密度和就业密度等协变量成统计显著性, 而其他协变量则不显著。车道数、平曲线度数、降雨量、人口密度等与事故起数成正相关, 而其他变量成负相关。另外, 年份哑变量对事故的影响作用亦不尽相同。如2008年和2010年与未受伤事故起数成正相关, 而其他则相反。对于受伤事故, 协变量统计显著性与未受伤事故不尽相同, 其中车道数和就业密度对于受伤事故呈显著性, 而对未受伤事故却不显著。对于两种类型事故协变量影响作用基本一致。对于死亡事故, 统计显著的协变量大为减少, 可能由于死亡事故起数较少, 即样本量偏少, 对统计结果产生一定的影响。值得注意的是, 最大限速在未受伤事故、受伤事故和事故总数中呈现正相关, 而在死亡事故中却相反, 呈现负相关, 即车道数越多, 死亡事故率越高。这可能由于车道数多的路段, 往往是高等级道路, 车流速度高, 一旦发生事故, 危险性高, 易产生死亡现象。而对于最大限速则完全相反, 即与在未受伤事故、受伤事故和事故总数中呈负相关, 而与死亡事故正相关, 这正好与车道数的潜在因素相对应。同时也说明, 并非限速越高事故越多, 因为限速高的路段线形往往更好, 同时驾驶员注意力更集中, 事故反而少。对于事故总数, 所有协变量均与事故成统计显著性, 且影响作用与未受伤事故和受伤事故基本一致。
| 表3 负二项面板固定效应模型的各类事故估计结果 Table 3 Estimation results of panel negative binomial fixed-effects model for kinds of crash counts |
为了更好地描述协变量对各类型交通事故的现实意义, 本文引入事故率比例指标IRR(Incidence rate ratio)。为了保证事故率非负性, 对交通事故均值模型(如式(2)所示)进行了指数转换, 此时协变量系数影响作用与普通的线性模型不一样, 不能用简单的边际效应或平均弹性描述。本文采用IRR作为替代边际效应, 用于考察协变量对各类型交通事故的具体影响作用, 其表达式为:
例如:如果β j=-0.1, 则IRR(xj)=exp(-0.1)=0.90, 这说明协变量xj增加一个单位量, 平均事故率减少10%。经过计算, 各类型事故模型中协变量的IRR值如表4所示。
| 表4 协变量对各类型事故的影响作用 Table 4 Effect of covariates on all kinds of crashes |
从表4可以清晰地看出, 每个协变量改变一个单位量时, 各类型交通事故率的变化情况。例如, 最大限速每增加1.609 km/h(1 mile/h), 未受伤事故起数减少3.89%; 受伤事故起数减少2.24%; 事故总起数减少2.79%; 死亡事故起数增加6.38%。其中人口密度和就业密度对于各类型事故影响最大, 这在一定程度上说明土地利用类型对交通事故产生重要影响。人口密度越大, 事故率越高, 而就业密度则完全相反。就业密度大的地方往往是商业用地, 而就业密度小的地方往往是农村地区(或农业用地), 该研究结果表明商业地区事故率低, 而农村地区事故率高, 这与Wang和Kockelman两位学者的研究结果一致[6]。年份哑变量与其他连续型协变量不同, IRR值指年份从“ 不是” 变为“ 是” , 即0改变为1时的事故率变化。例如, 2008年相对于参考年份(2007年), 死亡事故率减少了15.6%。
通过F检验和Hausman检验, 以及对数似然值和离差信息准则, 说明负二项面板固定效应模型比混合效应模型和随机效应模型更优, 能较好地拟合面板数据。协变量对4种类型交通事故(未受伤事故、受伤事故、死亡事故和事故总数)的影响作用和统计显著性不尽相同, 其中事故总数的显著变量最多, 而死亡事故最少。同时研究发现越严重的交通事故, 面板数据模型拟合效果越好。事故率比例指标IRR表示协变量对事故的具体作用。另外, 人口密度和就业密度对于各类型事故影响最大, 这在一定程度上说明土地利用类型对交通事故产生重要影响。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|