
{kind=link}
{kind=link}
基于整数数据的文档压缩编码方案
[特日跟1, 2, 3, 4  , 江晟
, 江晟1, 2 , 李雄飞3, 4 , 李军3, 4 ]
, 江晟, 李军|
|


作者简介:特日根(1987-),男,博士研究生.研究方向:数据挖掘.E-mail:277093537@qq.com
提出了针对整数数据的CSN-2压缩算法,并将其应用于任意文档的压缩,且CSN-2压缩算法不需额外的数据支持。通过研究CSN-2解压算法,提出了可以正确还原原数据的CSNE-2解压算法,并对解压算法结果的唯一性和正确性进行了理论及实验检验。并通过与其他压缩方案的实验比较,结果表明CSN-2压缩算法对整数型文档具有较高的压缩率,且对任意文档均具有压缩效果。
A CSN-2 compression algorithm for integer data was proposed and applied to the compression of any documents. Moreover, the CSN-2 data compression algorithm does not need additional data support. A CSNE-2 decompression algorithm, which can properly restore the original data, was proposed by studying the CNS-2 decompression algorithm. It was proved that the results of the decompression algorithm are unique and correct in theoretical and experimental tests. Furthermore, it was demonstrated that the CSN-2 compression algorithm for the integer type of documents has a higher compression ratio, and could compress any documents compared with experiments of other compression programs.
随着多媒体计算机技术、计算机网络技术以及现代多媒体通信技术的不断发展, 数据业务和多媒体通信业务等通信量越来越大, 给信息存储特别是网络传输带来前所未有的压力。现有数据压缩算法分为有损压缩和无损压缩[1]。有损压缩通过数据挖掘等手段从数据来源、数据特性出发, 提取关键信息予以保存。语音识别、医学和生物测量[2]、股票价格、市场销售数据、气象数据、电信通信、传感器网络数据等均可采用有损压缩方法处理。有损压缩方法可分为基于概率模型[3]、基于时间序列分析模型[4]、基于数据挖掘模型[5]、基于数据压缩模型[6]这四类, 其共性在于压缩率高, 数据还原质量依赖于算法实现的代价。
无损压缩技术[7]在数据压缩过程中不允许损失精度, 可以保真还原。主要用于文本文件、数据库、程序数据和特殊应用场合的图像数据(如指纹图像、医学图像)等压缩。相对于有损压缩, 无损压缩的压缩率较低, 一般为1/2~1/5。无损压缩可以分为基于统计的压缩算法和基于字典的压缩算法两类。两类压缩算法都需要一个额外数据库。本文提出的Compress sequence number(CSN)压缩算法通过增加每个字节的信息表达能力实现压缩, 本文还对解压算法结果的唯一性和正确性进行了理论及实验检验。
基于统计的压缩算法的本质是根据字符的出现频率来对字符本身重新编码, 属于熵编码类, 主要算法有香浓-凡诺编码、游程长度编码、哈夫曼编码和算术编码。香浓-凡诺算法[8]由贝尔实验室开发, 核心是构造一个通过叶子节点记录字符信息的二叉树, 它是一种自顶向下的、非自适应的编码算法。游程长度编码(Run-Length-Coding)[9]通过去除文本中的冗余字符或字节中的冗余位, 达到减少数据文件所占的存储空间的目的, 其压缩效能取决于整个数据流的重复字符出现次数、平均游程长度及所采用的编码结构。由于该算法是针对文件的某些特点所设计的, 具有一定的局限性。Huffman编码是Huffman在1952年提出的一种基于信号概率的数据压缩算法[10]。它根据字符重复出现的概率生成的一种前缀编码方法, 其核心也是构造二叉树, 与香浓-凡诺编码相反, 是一种自下向上的、非自适应的编码算法。1978年提出的动态哈夫曼算法[10, 11]取消了统计过程, 一边压缩一边动态调整哈夫曼树, 提高了压缩效率。算术编码[12]也是一种根据字符出现概率重新编码的压缩方案, 该方法打破了哈夫曼算法必须用整数来表示字符的限制。压缩效果逼近信息熵极限的编码方法。
字典编码方法是以较长的字符串或经常出现的字母组合构成字典中的各个词条, 并用相对较短的数字或符号来表示的方法。压缩效果与重复数据量、字典大小等因素有关。主要算法包括:LZ77算法[13]、LZ78算法[14]、LZSS算法[15]、LZW算法[16]等。LZ77算法[13]是第一个具有实用价值的基于词典编码的数据压缩算法, 它利用一个窗口在原始数据中滑动, 超前查看缓冲区中的刚刚由输入文件中读入的未编码字符, 实现数据压缩、解压缩, 也称为基于滑动窗口的自适应的字典压缩方法。LZ78.压缩算法是LZ77的改进算法, 放弃了窗口, 采用树形结构字典保存短语, 对区间重复性强的数据压缩效果较好, 但它的编译码方法较复杂, 实现起来比较困难。LZSS算法采用二分搜索树, 解码时无须生成和维护字典树, 大大加快了速度。该算法的压缩率较高, 编译算法较简单。LZW算法[16]是1984年Welch提出的基于LZ78算法的一个变种压缩算法。主要用于GIF格式的图像数据的压缩。该算法的压缩效果好、速度快且算法描述易于接受, 是目前最常用和最有效的无损压缩算法。
上述算法的共同特征是需要一个辅助数据库。Gö del[17]提出一种不依赖于数据库的无损压缩方法称为哥德尔数, 但其使用范围局限于对图灵机程序的压缩, 而不具有普遍性。哥德尔数是将一组正整数序列b1, b2, b3, …, bn通过公式(1)计算得出, 其中P为递增的质数。
由公式可知哥德尔数会随着序列长度的增加成指数增长, 因此不适合于其他类型数据的压缩。
定义1:对于长度为n, 存在最小元素为1的整数序列:b1, b2, b3, …, bn, 取T=max(b1, b2, b3, …, bn)+1, 由递推公式(2)可得CSN数。
例:序列20, 53, 3, 58, 8, 17, 43, 1通过公式(2)计算可得
T=58+1=59
a1=59× 0+20=20
a2=59× 20+53=1233
a3=59× 1233+3=72750
a4=59× 72750+58=4292308
a5=59× 4292308+8=253246180
a6=59× 253246180+17=14941524637
a7=59× 14941524637+43=881549953626
a8=59× 881549953626+1=52011447263935
得该序列的CSN-1数为52011447263935。CSN-1具有明显的局限性, 要求序列中最小数只能为1, 且必须含有1, 因此需要对CSN-1进行改进。
在CSN-1中, 若整数序列中, ∃bi∈
定义2:对于长度为n的整数序列:b1, b2, b3, …, bn, 取
由递推公式(2)可得CSN数。
例:序列20, 53, 3, 58, 8, 17, 43, 10通过公式(3)计算可得:
M=3
T=58-3+2=57
a1=57× 0+20-2=18
a2=57× 17+53-2=1077
a3=57× 1077+3-2=61390
a4=57× 61390+58-2=3499286
a5=57× 3499286+8-2=199459308
a6=57× 199459308+17-2=11369180571
a7=57× 11369180571+43-2=648043292588
a8=57× 648043292588+10-2=36938467677524
得:该序列的CSN-2数为36938467677524
因为CSN-1的局限性, 文章随后的实验均使用CSN-2来完成。
CSN的压缩原理就是针对CSN数进行二进制存储。因为原序列通常是以字符串形式或占用完整机器位数来存储和传输, 且具有一定的局部聚合性, 因此CSN数是通过整数数据中局部数据范围比全文小的特点, 将数据分段, 利用其剩余的机器位数, 减少无用空间, 进而实现压缩。
例:序列20, 53, 3, 58, 8, 17, 43, 10。
序列的CSN数为34948661300524。
CSN数对应的二进制数为111111|11001001|00011110|10001010|11001101|00101100。
该序列在不同情况下所占空间如表1所示。
| 表1 CSN压缩数与原数据的比较 Table 1 CSN compressed with the original data |
CSNE解压算法是CSN压缩算法的逆过程, 将每个压缩段按压缩的逆过程进行还原, 公式(4)和公式(5)分别为CSN-1和CSN-2压缩算法的逆运算, 即为CSNE-1和CSNE-2解压算法。
由公式(2)得(rem为取余运算)CSN-1的解压公式(4), 其中当ak=0时, 递归结束。

由公式(3)得(rem为取余运算)CSN-2的解压公式(5), 其中当ak=0时, 递归结束。

例:一个序列的CSN-2数为36938467677524, T=57, M=3
因此最终还原出序列为:20, 53, 3, 58, 8, 17, 43, 10
定理1:每个整数序列可对应一个且唯一的一个CSN-1数。
定理2:每个整数序列可对应一个且唯一的一个CSN-2数。
CSN-2编码过程是将序列先整体平移, 使得序列中最小元素为1, 在满足CSN-1条件的基础上, 通过使用CSN-1的压缩方法进而完成其压缩过程。CSNE-2的解压过程, 则是将CSN-2数先通过CSNE-1的解压过程得到序列, 通过平移还原为原序列, 因此若定理1成立, 则定理2也成立。
定理1证明:
设两个序列C1和C2, 其中C1为
当n≠ m时, 假设n> m, 通过公式(2)可得
CSN=Tn-1
Tm-1
所以:
又因为:
及
所以
Tn-1
…+
即等式不成立。所以n> m时, 等式不成立。
同理可得n< m时, 等式也不成立。所以当n≠ m时, 等式不成立, 即n=m。
当n=m时, 通过公式(2)可得:
所以:
T(Tn-2
Tn-3
若
所以:
︙
≥ 1得:
所以当n=m且
同上可知, 若
以此类推最终可得
证毕。
通过上述证明可知, 定理2亦正确。
在CSNE-2解压算法中除输入CSN-2数以外, 还应包括CSN-2数的T和增值M, 因此, 在存储CSN-2文档时, 需要在文档前面加上T和M, CSN-2文档中实际存储的内容有三个, 即T、M和CSN-2数。
定义3:
实验1:已知序列1:1~200, T=201; 序列2:1~400, T=401; 序列3:1~800, T=801。这三个序列均以整型形式存储, 计算三个序列的CSN-2的文档大小及其压缩率。结果如表2所示。
| 表2 实验1三个序列的压缩率 Table 2 Experiment 1 compression ratio of three sequences |
结论1:压缩率受T影响, 当M不变时, T越大压缩率越小。
实验2:已知序列1:1~200, T=201;
序列2:200~1, T=201。
序列3:共有200个整数数据, 且至少包含一个1和一个200, 其余198个整数在1~200内随机选取。T=201以上三个序列均以整型形式存储, 计算三个序列的CSN-2的文档大小及其压缩率。结果如表3所示。
| 表3 实验2三个序列的压缩率 Table 3 Experiment 2 compression ratio of three sequences |
结论2:压缩率不受序列中整数大小顺序的影响。
在众多压缩算法中哥德尔数也是不依赖任何数据库的压缩方法, 因为原数据内容的不确定性, 所以原序列以整型序列进行了测试, 对比结果参见表4。在最坏情况下, 针对不同序列长度的实验结果如图1所示(计算机为32位)。
| 表4 CSN-2压缩数与哥德尔数的比较 Table 4 Compare CSN-2 compression numbers and Gö del numbers |
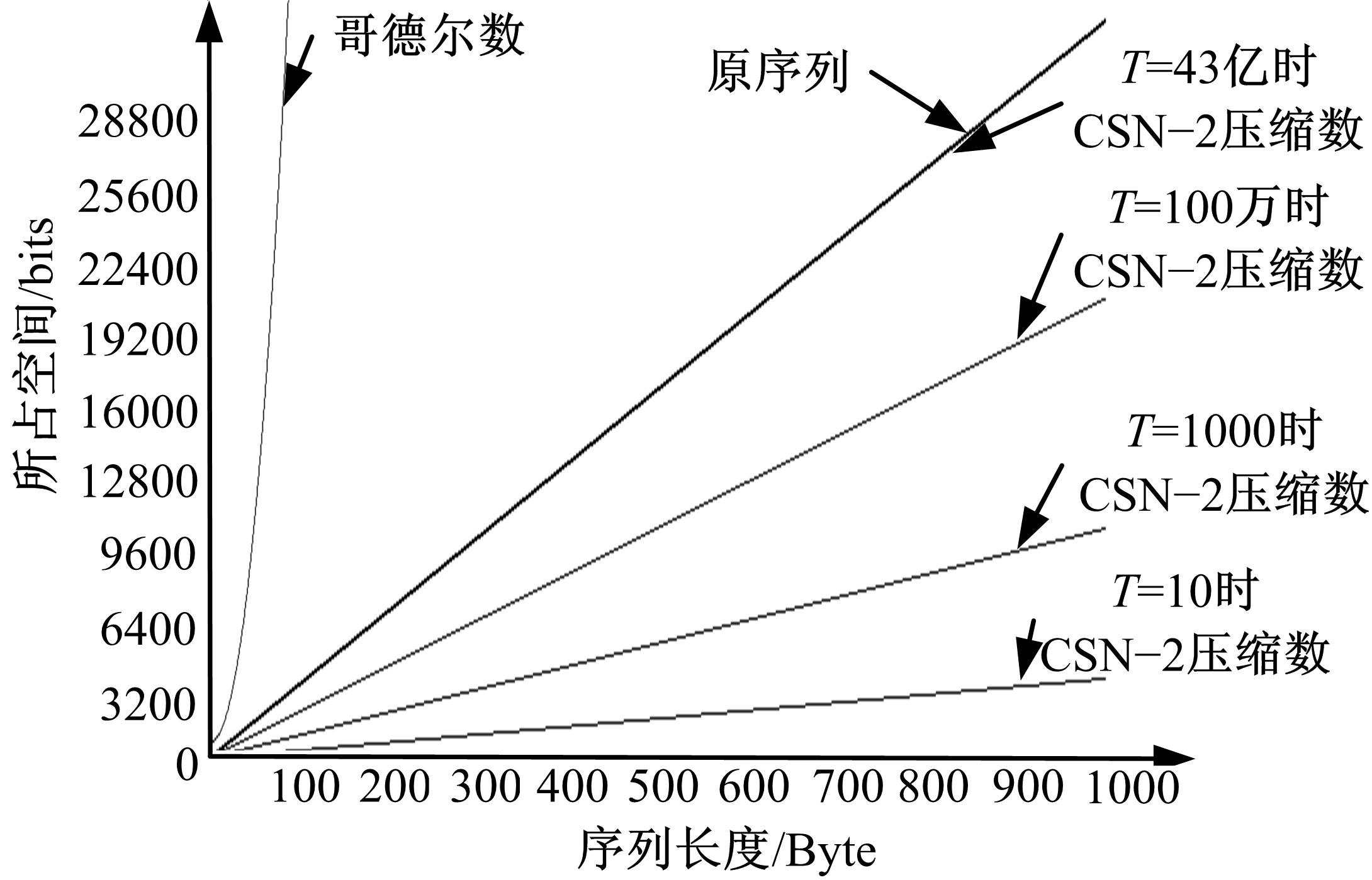 | 图1 CSN-2压缩数与哥德尔数空间利用率比较Fig.1 CSN-2 compressed space utilization compared with Gö del number |
由图1可知在CSN-2不同T情况下的空间压缩率是不相同的, 压缩率如表5所示。
| 表5 CSN-2压缩算法在不同T时的压缩率 Table 5 CSN-2 compression algorithm compression ratio at different thresholds |
CSN-2压缩数通过对序列的重新计算得到与序列唯一对应的一个数, 通过存储压缩数来代替原序列, 节省较大的存储空间。哥德尔数也是通过对序列的重新计算得到的一个数, 但其仅对可计算函数集合具有压缩效果, 对其他类型的数据的压缩效率极低, 甚至超过原数据。
因CSN-2的压缩结果与机器位数相关, 因此对于文档这种在压缩后的数会明显超过机器位数的数据进行处理时, 需要设计明确的分段标准。
由于CSN-2的压缩是一个递推过程, 因此可以随时查看其CSN-2压缩数的大小, 当压缩数超过机器位数时, 则停止此段压缩, 进而执行下一阶段的压缩。文中表6的测试过程就是通过此方法完成实现的。
| 表6 测试文档信息 Table 6 Test document information |
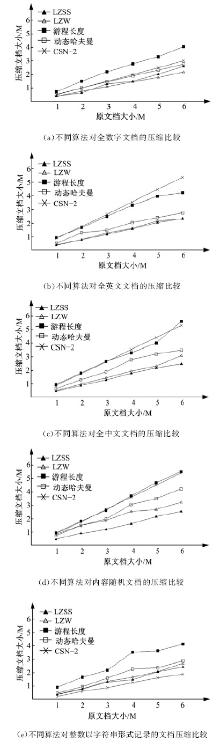
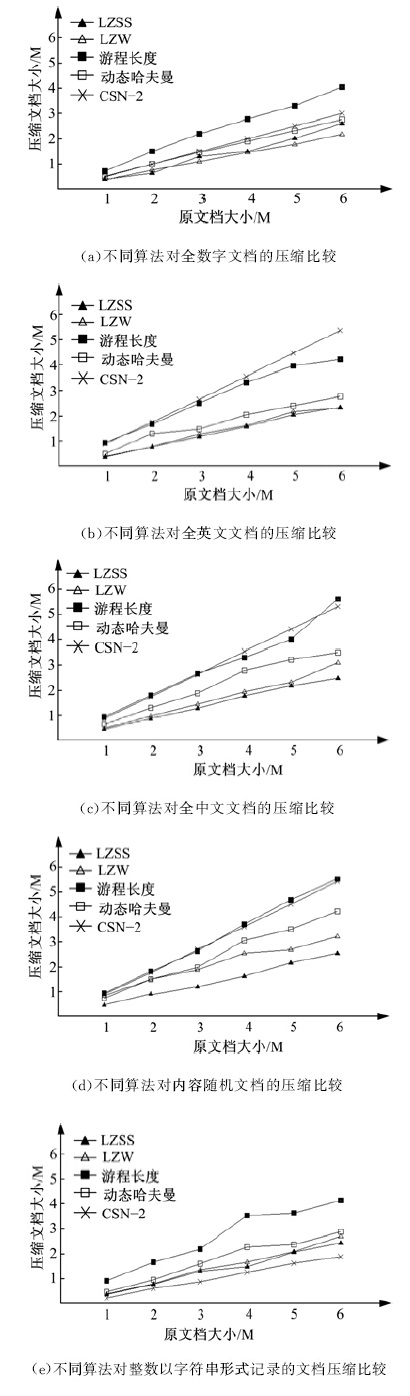
通过使用不同的压缩算法对表6中的30个文档进行压缩测试, 比较不同压缩算法的压缩率, 其结果如图2所示。其中压缩算法分别为LZSS、LZW、游程长度编码、动态哈夫曼编码和CSN-2压缩。
根据图2可知, CSN-2对以字符串形式记录整型数据文档的压缩效果最好, 对纯数字文档的压缩率也比较高。
 | 图2 不同压缩算法压缩效率比较Fig.2 Compare the efficiency of different compression algorithms compress |
因为常用的压缩软件WinRAR和WinZip都是采用多种压缩方案共存的形式, 针对不同类型的数据执行不同的压缩算法, 因此, 针对纯数字文档, 尤其是以字符串形式记录整型数据的文档进行压缩时, 可选择CSN-2压缩算法。
针对文档压缩进行了研究, 提出了CSN-1和CSN-2的存储方式, CSN-2通过对整型数据进行压缩, 使数据的空间复杂度降为O(log22(T+1)n-1)。通过解压算法可以找到对应的原数据, 实现数据还原。CSN-2的压缩不仅可以使其具有更高的空间利用率, 而且能够增加信息传递的可靠性。
通过CSN-2压缩的方式对文本进行压缩, 就是针对文本对应的ASCII码进行压缩。根据CSN-2针对字符串形式的整型数据压缩效率高的特点, 可以通过LZW等基于字典的压缩方案的主题思想进行改进, 即建立文档字典, 并对字典中每个字符串进行整型编码排序, 将文档以整型数组的形式记录下来, 最后通过CSN-2对文档的编码序号(整型数据)进行压缩。
CSN-2压缩方案具有较为广泛的应用范围, 例如环境温度的检测、心跳记录等。因为每种数据都具有其一定的取值范围, 如环境温度可视为-60℃~60℃, 人类心跳每分钟最快可达240次左右。因此每个数据没有必要使用一个INT(整型)数据来存储, 且这类数据具有局部聚合性, 因此通过CSN-2压缩方案进行压缩具有较高的压缩率。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|