{kind=link}
一种求解分类问题的自适应人工蜂群算法
[马安香 , 张长胜, 张斌, 张晓红]
, 张长胜, 张斌, 张晓红]
, 张长胜, 张斌, 张晓红]
|
|


作者简介:马安香(1979-),女,讲师,博士研究生.研究方向:智能算法,Web数据集成.E-mail:maanxiang@ise.neu.edu.cn
考虑到分类算法学习到的分类器的可理解性,提出一种求解分类问题的自适应人工蜂群算法——A_ABC,该算法生成一组可理解的分类规则。在基于规则的分类方法中,采用合适的规则评价函数能够提高分类算法的性能,A_ABC算法能够针对不同数据集自适应选取相适应的规则评价函数,同时能够有效处理连续类型的属性和离散类型的属性。最后,在多个公用的真实数据集上,将A_ABC算法与相关算法进行了比较,结果表明A_ABC算法能够更加有效地解决分类问题。
Appropriate rule evaluation functions are important to improve the performance of classification algorithm based on rules. In order to obtain the comprehensible classification rules, an adaptive artificial bee colony algorithm, called A_ABC algorithm, is proposed. The A_ABC algorithm can adaptively select a appropriate rule evaluation function for the given data, and effectively process both discrete attributes and continuous attributes. The proposed A_ABC algorithm is evaluated by experiment using different standard real datasets, and compared with existing classification algorithms. Results show that the A_ABC algorithm can solve classification problems more effectively than the existing algorithms.
分类学习包括两个阶段, 分别是学习阶段和分类阶段。在学习阶段, 根据训练样本学习一个或一组样本属性与预定义类别相关的分类器, 在分类阶段, 根据学习到的分类器, 按照未知类别样本的属性特征将其划分到预定义的类别中。根据分类算法学习到的分类器是否具有可理解性, 可以分为分类器不可理解和分类器可理解两类算法, 神经网络方法、支持向量机方法[1]属于前者, 这类方法学习到一个难以理解的复杂的数学函数; 决策树学习[2]属于后者, 学习到一组人类可以理解的分类规则。很多实际的分类任务需要学习到的分类器具有可理解性, 进而领域专家可在分类器基础上进行验证和调整。
分类器可理解的分类方法主要分为并行覆盖方法和序列覆盖方法两类。并行覆盖方法一次性学习出所有的分类规则, 如决策树学习, 采用贪婪方法从训练样本中学习一颗决策树, 该方法在建树过程中不进行回溯, 容易收敛到局部最优解。序列覆盖方法一次学习一个精确度最好的分类规则, 以递增的方式学习有序规则集合, 由于蚁群算法和粒子群算法等元启发式方法能够有效求解优化问题, 并具有自适应性强、鲁棒性好等优点, 因此基于元启发式方法的序列覆盖算法近年来受到研究者的关注。基于蚁群系统的分类算法AntMiner[3]是第一个用蚁群优化思想来求解分类问题的方法, 该方法定义了与分类问题相关的启发式信息和信息素更新模型, 从而解决分类问题。为提高AntMiner算法的性能, AntMiner+[4]算法对AntMiner进行了改进和扩展, 主要从所采用的基础蚁群算法、启发式规则设计、信息素更新函数、规则评价函数等方面进行了改进。PSO/ACO2[5]是粒子群优化和蚁群优化相结合的混合分类算法, 两种优化方法的结合使得该算法可以有效处理离散和连续的属性。文献[6]提出一种基于蜂群优化的分类方法, 可以有效处理连续属性, 但无法处理离散属性。实际分类问题中通常同时包括离散属性和连续属性, 因此分类算法能兼顾离散属性和连续属性的处理, 对于分类性能至关重要。
序列覆盖算法采用规则评价函数来评价规则的优劣, 文献[7-9]总结了几种常用的规则评价函数如Klosgen、F-measure、Reletive cost measure和M-estimate等, 现有的基于元启发式方法的序列覆盖算法均是固定某一个规则评价函数, 而从文献[7-9]中对比实验可知, 给定一个序列覆盖算法, 在同一数据集上, 采用不同的规则评价函数算法性能也各不相同; 同时, 针对不同的数据集, 不存在一个规则评价函数能在所有数据集上性能都最优。由此可见, 序列覆盖算法中如果固定了一个规则评价函数, 将不能保证在所有数据集上都取得较好的效果。
本文以人工蜂群优化算法为基础, 根据离散属性和连续属性的特点设计雇佣蜂、观察蜂和侦察蜂的觅食策略, 使得算法能够有效处理连续类型和离散类型的属性; 同时, 研究如何为不同数据集自适应选取相适应的规则评价函数, 从而实现求解分类问题的自适应人工蜂群算法, 提高分类的准确率。
人工蜂群算法[10]源于对蜂群内部分工机制及其觅食行为的模拟, 已被广泛应用于求解多种优化问题, 具有收敛速度快和鲁棒性好等特点。
蜂群优化模型中包含3个基本要素:食物源、受雇佣的觅食者、非受雇佣的觅食者。食物源表示待优化问题的一个可行解, 食物源的丰富程度代表解的质量即适应度。受雇佣的觅食者即雇佣蜂与一个特定的食物源相关联, 携带这个食物源的相关信息, 并以一定的概率共享这些信息。非受雇佣的觅食者包括侦察蜂和观察蜂两种, 侦察蜂主要负责在蜂巢周围搜寻新的食物源, 当雇佣蜂进行一定次数(limit)的搜索之后发现食物源的质量并没有提高时会变成一只侦察蜂; 观察蜂根据雇佣蜂分享的食物源信息按照一定的概率选择雇佣蜂进行跟随, 食物源被侦察蜂选择的概率计算公式如下:
式中:fiti表示第i个食物源的适应度; SN表示食物源的数量, 也是雇佣蜂的数量。
为了找到更好的食物源, 雇佣蜂会在绑定的食物源周围进行邻域搜索, 同样的, 观察蜂选定一个食物源Xi后也会进行邻域搜索, 式(2)是一种邻域搜索策略。
式中:Xi表示当前食物源; Vi表示邻居食物源; j是一个随机索引, 表示修改食物源Xi的第j维元素; Φ ij是一个[-1, 1]区间内的随机数, 控制Vij在Xij的邻域; k是一个不同于i的随机数。算法会采用贪婪选取方法比较食物源Vi和Xi的适应度, 如果新食物源Vi优于Xi, 则让Vi取代Xi, 否则Xi被保留不变。
自适应人工蜂群分类算法的目标是有效处理离散属性和连续属性, 并为不同数据集自适应选取相适应的规则评价函数, 以提高分类性能。自适应人工蜂群算法利用动态分配资源即雇佣蜂的方法, 在算法运行过程中对采用不同规则评价函数所生成的食物源进行比较和选择, 为较优的规则评价函数分配更多的资源, 同时减少其他规则评价函数对应的资源, 当资源数为零时则淘汰相应的规则评价函数, 这一过程不断迭代, 直至最终得到一个性能最优的规则评价函数和相应的分类规则集。
针对分类问题的相关特性, 定义了人工蜂群优化算法中与优化问题相关的部分, 包括食物源编码、适应度计算以及局部搜索策略等。
2.1.1 食物源编码和适应度计算
分类问题是根据给定的训练样例学习到一组分类规则, 分类规则形如“ If规则前件then规则后件” , 其中规则前件是若干属性值约束形如“ Attribute=value” 的合取, 规则后件对应分类结果即类别取值。
给定分类问题, 假设存在n个属性变量Ai(i=1, 2, …, n)和一个类别变量Cj(j=1, 2, …, m), 则分类问题对应的食物源S是由所有属性值约束构成的n维向量, 即:
式中:vi表示属性值约束即属性Ai的取值, 如果属性Ai是一个离散属性(用DA表示), 则属性值约束为Ai的任意一个取值aik(ai, 0=any表示属性Ai可以取任意值); 如果属性Ai是一个连续属性(用CA表示), 则属性值约束为一个由属性值上下界限定的值域。食物源S很容易转换成相应的分类规则R, S对应分类规则的前件, 由S所覆盖的训练样例中最普遍的类别即为分类规则的后件。
由于采用不同规则评价函数所生成的分类规则会有差异, 对训练样例集的覆盖情况也不同, 因此每个规则评价函数对应一组雇佣蜂和一个规则集。自适应人工蜂群算法中共有4种规则评价函数, 分别是Klosgen、F-measure、M-estimate和
食物源的质量由所采用的规则评价函数决定, 因此食物源Si的适应度计算公式如下:
式中:Rfi(Si)表示对食物源Si采用对应的规则评价函数Rfi计算其规则评价函数值。
2.1.2 搜索策略
给定分类问题, 在构造初始种群后(共SN个食物源, SN也表示雇佣蜂或观察蜂的数量), 然后雇佣蜂、观察蜂和侦察蜂在种群所维护的SN个食物源的邻域内迭代搜索直至终止条件满足, 搜索结束。
给定当前食物源Xi, 雇佣蜂在其邻域内搜索生成新的邻居食物源Vi的计算公式如下:
式中:rand[X]表示在集合X中随机取一个值; Φ ij是一个[0, 1]区间内的随机数, 控制Vij在Xij的邻域; k是一个不同于i的随机数, 新生成的邻居食物源必须满足
观察蜂观察与雇佣蜂共享的信息, 根据式(1)计算食物源被选择的概率, 适应度越高的食物源被选择的概率越大, 然后根据式(5)对选定的食物源进行深入局部搜索, 并利用与雇佣蜂相同的贪婪选择策略保留优秀的解。
自适应人工蜂群算法用参数“ limit” 来记录食物源未被更新的次数, 如果侦查蜂发现连续limit次循环之后某个食物源Xi没有改善, 表明这个候选解陷入局部最优, 则侦察蜂放弃这个食物源, 按照公式(6)在蜂巢周围搜寻新的食物源, 用新的食物源替代原来的食物源, 新食物源必须满足
2.1.3 规则集比较和资源重分配
规则集比较模块用来比较当前各个规则评价函数对应的局部分类规则集的优劣, 从而判断出规则评价函数的优劣。通过计算规则集的正确率对规则评价函数进行评价, 正确率越大, 规则评价函数排名越高。正确率计算公式如下:
式中:pi表示规则评价函数i对应的局部规则集正确覆盖的训练样例数; ni表示规则评价函数i对应的局部规则集错误覆盖的训练样例数。
资源重分配模块用于重新分配资源, 人工蜂群算法中的资源主要有两个, 一个是雇佣蜂个数, 另一个则是迭代次数。通过雇佣蜂个数与算法正确率关系实验和迭代次数与算法正确率关系实验发现, 最终正确率与雇佣蜂个数之间存在一个正相关的关系, 而与迭代次数不存在很明显的正相关关系。因此, 选择雇佣蜂作为资源, 在重分配的时候, 给优秀的规则评价函数分配更多雇佣蜂, 给劣势的评价函数分配较少的雇佣蜂。
算法设置了两个变量, 分别是初始雇佣蜂个数InitnbBees和步长step。规则评价函数i对应的雇佣蜂数量变化公式如下所示:
式中:x是一个与规则评价函数排名有关的整数值; R(i)值从大到小对应的x取值分别为2、1、-1和-2。
自适应人工蜂群算法主要包括数据初始化、规则生成、规则集比较、资源重分配和终止条件判定5个部分。算法初始化时将雇佣蜂平分为4组。规则生成模块对每个未被淘汰的规则评价函数, 基于基本人工蜂群方法找出当前最优规则。规则集比较模块用来比较各个规则评价函数对应的局部规则集, 并根据局部规则集的优劣对规则评价函数排序。资源重分配模块给排名靠前的规则评价函数更多的资源, 同时减少排名靠后的评价函数的资源数量。算法终止条件判定模块判断算法是否满足终止条件, 并返回最优的规则评价函数及相应的规则集。
根据上述分析, 给出A_ABC的具体描述:
Algorithm 1 A_ABC(dataset)
Parameter
int cycle;
int BeeCounti;
Begin
initialize the food sources Sj, j=1, 2, …, Csize;
For i=1 to 4
BeeCounti=InitnbBees
RuleSeti=null;
Repeat
cycle=1;
For i=1 to 4
If BeeCounti> 0
while(cycle< MCN or TermiCondition is satisfied) do
//send employed bees
Produce new food sources for the employed bees corresponding to Rfi by formula(5) and evaluate them by formula(4);
Apply the greedy selection process for the employed bees;
//send onlookers
Calculate the probability values for the food sources by formula(1);
Produce the new food sources for the food sources selected depending on the probability values and evaluate them;
Apply the greedy selection process for the onlookers;
//send scouts
Replace the abandoned food source with a new randomly produced food source by formula(6);
Memorized the best food source Xi achieved so far;
cycle=cycle+1;
end while
For i=1 to 4
convert the best solution Xi to a classification rule ri;
add ri to RuleSeti;
remove the examples coverd by ri from training examples set TEi;
judge the performance of rule evaluation function by formula(7);
redistribute employed bee resources(namely updating BeeCounti) by formula(8);
Until EndCondition;
For i=1 to 4
If BeeCounti > 0
RuleEvalFunc= Rfi;
RuleSet=RuleSeti;
Return RuleEvalFunc and RuleSet;
End
为验证自适应人工蜂群算法(A_ABC)的有效性, 本节首先探讨算法重要参数设置问题, 然后在公共数据集上将A_ABC与相关算法进行性能对比。共选取了6组数据集[11], 基本信息如表1所示。
| 表1 测试数据集简介 Table 1 Testing dataset introduction |
二元分类表示类别为“ 是/否” 的形式, 而非二元分类的类别则超过两种。属性类型中, 数值型和整数型为连续类型, 命名型则为离散类型, 混合型则既有连续类型也有离散类型。
实验1 参数设置
自适应人工蜂群算法中包含多个参数, 具体有蜂群算法基本参数Csize、limit和MCN, 规则评价函数中参数ω 、γ 和m以及自适应人工蜂群算法特有的资源重分配参数step。根据经验将Csize和MCN分别设置为50和2000。规则评价函数中参数ω 、γ 和m的设置与算法准确率间关系在文献[7]中有详尽的实验, 此处, 采取结果较优的参数设置, 即ω =0.40、γ =0.25、m=4。参数limit表示食物源质量连续limit次没有提高, 将被放弃。该参数设置的优劣直接决定算法的全局搜索能力; 参数step代表每次资源调整的幅度, 如果设置的不好, 算法会过早收敛到某个规则评价函数上, 这将导致一个次优的规则评价函数可能会占据大多数的资源, 从而导致其他更好的规则评价函数没能够得到表现。
本文为每一个参数设定了一个合理的候选取值范围, 如表2所示。在讨论任一参数对算法的影响时, 固定其他参数的取值, 对于已讨论过的参数, 其值设置为取值范围内统计结果最佳值; 对于尚未讨论的参数其值取中间值。针对参数limit和step, 取不同值在各数据集上运行10次, 算法终止条件为找出最优规则评价函数(其余规则评价函数全部淘汰), 并且未被覆盖的训练样例数少于5%, 最终10次运行结果的平均值作为算法的最终准确率, 结果如图1所示。
| 表2 参数取值范围表 Table 2 Turned parameters |
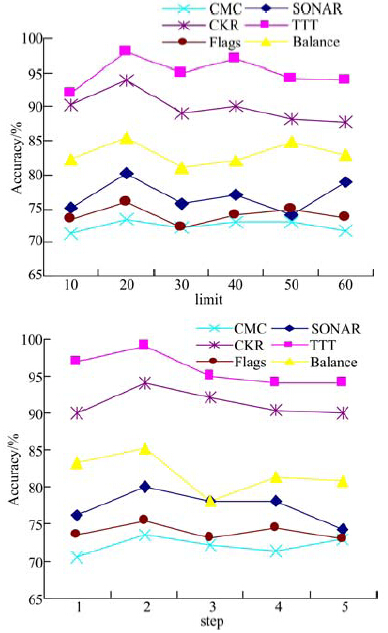 | 图1 参数设置结果图Fig.1 Parameter setting result |
参数的不同取值对算法性能的影响较大, 其中limit=20和step=2, 从统计意义上来讲是一种相对较好的设置。
实验2 分类算法性能对比
将分类器不可理解的Kalman Filter+SVM算法[1]、分类器可理解的WrapTree[2]、Antminer+[4]和PSO/ACO2[5]算法, 与本文提出的自适应人工蜂群算法A_ABC进行性能对比, 同时为说明规则评价函数对算法性能的影响, 将Antminer+算法分别固定Klosgen、F-measure、M-estimate和Q+四种规则评价函数进行性能测试, 算法的参数和终止条件与实验1相同, 其他对比算法除终止条件外保留原始研究中的参数设置不变。最终实验结果分别如表3和表4所示。表中“ REF” 表示A_ABC算法自适应选择的规则评价函数, “ Acc” 表示算法的正确率, “ #RN” 表示规则条数, “ #AAC” 表示平均每条规则所包含的语句数(即属性值约束的数量)。
| 表3 分类算法性能对比实验 Table 3 Performance comparison among classification algorithms |
| 表4 分类算法性能对比实验(续) Table 4 Performance comparison among classification algorithms |
首先, 从Antminer+算法(分别固定4种规则评价函数)在各个数据集上的测试结果可以看出, 针对同一个数据集, Antminer+算法随采用规则评价函数的不同, 算法性能也不同, 并且不存在一个规则评价函数, 能够使得Antminer+算法在所有数据集上性能都最优; 其次, 从A_ABC算法在各个数据集上的运行结果可以看出, 针对不同数据集A_ABC算法所选取规则评价函数也不尽相同; 最后, 从5种算法的总体运行结果来看, 在Balance数据集上Kalman Filter+SVM算法性能明显优于其他算法, 在SONAR、Contraceptive method choice和Flags数据集上A_ABC算法执行正确率明显优于其他算法, 在Tic-Tac-Toe数据集上A_ABC和Antminer+算法的正确率相当, 在Chess-King-Rook数据集上A_ABC、PSO/ACO2和Antminer+(M-estimate)算法的正确率相当。总体上, 在分类器可理解的分类算法中, A_ABC算法的性能较好, 原因在于A_ABC算法能够为各个数据集自适应选出相适应的规则评价函数并能有效处理连续类型的属性, 使得A_ABC算法具有更好的性能和适用性。
本文针对现有基于元启发式优化方法的分类算法存在的问题, 提出一种求解分类问题的自适应人工蜂群算法, 能够为不同数据集自适应选取相适应的规则评价函数, 同时能够有效处理连续属性和离散属性, 实验结果证明了本文算法的有效性。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|