{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于 K-均值聚类算法的行驶工况构建方法
[秦大同 , 詹森, 漆正刚, 陈淑江]
, 詹森, 漆正刚, 陈淑江]
, 詹森, 漆正刚, 陈淑江]
|
|


作者简介:秦大同(1956-),男,教授,博士生导师.研究方向:智能传动与控制.E-mail:dtqin@cqu.edu.cn
提出一种基于 K-均值聚类算法的城市循环工况构建方法,该方法通过实车采集某城市道路行驶工况的数据,将工况数据预处理后划分为工况块,运用平均速度,行驶距离和巡航时间比3个参数对工况块进行 K-均值聚类分析,采用距离聚类中心越近越能代表簇特征的原则选取工况块,最终拟合出某城市循环工况,并对其从特征参数,转毂实验和废气分析采集的油耗和排放数据3个方面与其他典型城市循环工况进行了对比.对比分析结果表明:采用本方法构建的城市循环工况能够很好地反映某地实际交通道路状况,具有实用价值.
A construction procedure of driving cycle is proposed using K-means clustering method. Experimental data of a city driving cycle is obtained by driving test vehicle, and is divided into "micro-trip" after preprocessing. The micro-trips are then clustered into groups in "average speed","distance" and "cruise time percentage" using the K-means clustering method. The micro-trips are pick out on the principle of the closer distance between the micro-trip's driving feature and the center of cluster, which is more representative of the cluster. Then the final city driving cycle is developed. The data of fuel consumption and pollutant emission are collected using revolving drum test and exhaust-gas analysis. The characteristic parameter, fuel consumption and pollutant emission among different typical driving cycles are compared. Results show that the driving cycle constructed by this new approach can better reflect the city actual traffic conditions and it has high practical value.
将行驶工况用于确定汽车污染物排放量和燃油消耗量, 新车型的技术开发和评估以及测定在交通控制方面的风险等, 为新车型的技术开发和评估等提供了参考依据.世界各国均重视开发适合本国的行驶工况, 美国, 欧洲, 日本分别使用FTP-15, ECE15+NEDC, J10-15作为本国标准循环工况[1], 国内不少城市也都构建出了适合本地区的循环工况[2, 3, 4, 5, 6, 7, 8], 对行驶工况构建方法的研究不仅具有理论意义, 而且具有实用价值.姜平等[9]利用小波压缩和数理统计相结合的方法, 提出了一种典型道路行驶工况构建方法, 这种方法消除了实验时路面干扰因素的影响.石琴等[10]通过对工况块特征参数进行主成分分析提取三个代表性的主成分, 再运用SOFM神经网络和K-均值聚类对其进行分析, 这种方法得到的循环工况更接近实际的道路运行状况.Lin等[11]采用工况块以及随机过程选择方法来构建行驶工况.Ou等[12]运用工况块构建循环工况, 分析构建混合动力客车的行驶工况的特点, 并根据该行驶工况对混合动力客车的匹配进行优化.目前国内外行驶工况构建方法的研究主要集中在行驶数据的采集和工况块的分类上, 对如何选取合理的特征参数来构建工况和构建工况块的选取原则研究很少.针对构建行驶工况, 选取优化后的特征参数, 不仅能减少整个构建过程的运算量, 还能消除与油耗和排放相关性差的不必要的特征参数.而现在构建最终行驶工况的代表性工况块的选取方法主要是随机选取, 拼凑工况时长, 此方法选取工况块效率低, 准确性差.
本文以某城市为例, 在K-均值聚类算法与工况块相结合的基础上, 通过综合考虑各特征参数之间的相关性, 各特征参数与油耗的相关性来优化特征参数, 结合K-均值聚类算法提出并运用距离聚类中心越近越能代表簇特征的原则选取代表性工况块, 最终构建出该城市典型循环工况.研究结果表明, 这种工况构建的方法选择的特征参数少且特征参数具有很强的代表性, 代表性工况块选取准确迅速, 所构建的城市行驶工况能够很好地反应城市的交通道路特点.
本文行驶工况的构建分为基础实验, 实验数据的分析和处理, 以及验证实验3个部分.
基础实验:通过调研, 结合现有实验设备和实验目的制定出实验方案.确定实验方案后进行工况数据采集, 并通过滤波器对原始数据进行预处理, 消除原始数据中的噪声.将预处理后的工况数据划分为工况块, 从而完成基础实验.
实验数据的分析和处理:选择适当的工况块特征参数对其进行聚类分析, 再选取代表性工况块并拟合出城市循环工况.
验证实验:将拟合好的循环工况与预处理后的整体工况数据进行比对, 同时与其他城市典型循环工况进行油耗和排放的比较, 以验证所得到的循环工况是否符合要求.
(1)调研:调研的目的是确定研究城市的地域分布, 线路选择.某城市为内陆山地城市, 两江交汇的区域为城市中心, 并向周围扩散.实车数据采集的路线需要包括:高速公路, 市郊, 居民生活区, 城市中心繁华地带.
(2)工况数据采集设备:实验用车为搭载美国ATI公司开发的ATI vision network hub工具箱的长安之星460.ATI vision network hub工具箱如图1所示, 长安之星460的基本参数如下:整备质量为1140 kg; 满载质量为1840 kg; 排量为1298 mL; 最大功率为60 kW; 轴距为2605 mm; 前, 后轴距分别为1425, 1435 mm.
 | 图1 数据采集仪器ATI vision network hubFig.1 Data acquisition instrument ATI vision network hub |
(3)工况数据采集实验方案:驾驶实验用车在包括高速公路, 市郊, 居民生活区, 城市中心繁华地带的某路段反复驾驶以采集基础实验数据.采样数据共30组, 采样周期为0.1 s, 实验时间包括上, 下班高峰, 双休日, 同一天不同时段, 以保证有足够的样本容量和测试数据的可靠性.
通过实验用车在选定的路段进行30组的工况数据采集, 数据时长共约18 h.
在实验车采集到的数据中, 由于驾驶员的不当操作, 汽车会产生脉冲噪声和高频噪声, 两种噪声会影响到最终的实验结果, 需要用滤波器消除这些噪声.具体方法是采用脉冲噪声滤波器去除工况曲线的奇点, 再通过高频噪声滤波器使工况曲线平滑.脉冲噪声滤波器定义为:
式中:
平滑曲线滤波器定义为:
式中: K(x)为在t时刻前后车速的权值; 本文中h取值为4 s,
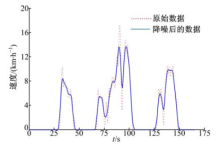
图2是一组工况数据在降噪前后的对比图.
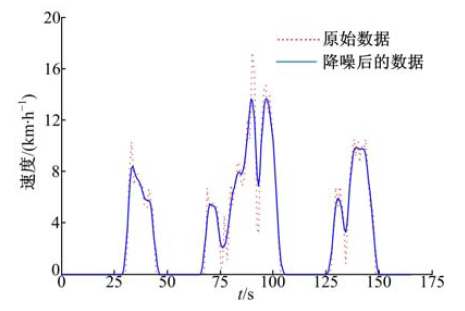 | 图2 降噪前后的数据对比图Fig.2 Data comparison before and after the denoiser |
K-均值聚类也称快速聚类, 先选定k个类和初始聚类中心.然后计算各样本和聚类中心之间的最小距离, 把每个样本分配给距离它最近的聚类中心.之后不断计算聚类中心和调整各样本的类别, 使簇内具有较高的相似度, 而簇间的相似度较低.具体过程如下:
(1)针对n个样本按照某种原则选取k个样本作为初始聚类中心(z1, z2, , et al., zk).
(2)应用欧式距离将任意样本xi 分配到距离它最近的簇中心.欧式距离是指两个样本所有n)个变量值之差的平方和的平方根, 即:
式中:xi , yi 分别为样本x和y的第i个变量的变量值.
(3)重新计算每个簇中样本的平均值, 用此平均值作为新的聚类中心.
(4)重复以上步骤, 直到聚类中心不再发生变化.
选取适当的工况块特征参数进行分析, 不但有利于减少聚类分析运算的时间, 同时也提高最后运算结果的准确性.本文首先选取平均速度vmean, 最大车速vmax, 平均加速度amean, 平均正加速度ameana, 平均负加速度ameand, 怠速时间比ridel, 巡航时间比rdrive, 最大加速度amax, 最小加速度amin, 行驶距离
式中:
各特征参数之间的相关系数如表1所示.vmean, vmax, amean, ameana, ameand, ridel, rdrive, amax, amin, s, vvar, avar, vspa, vspa与油耗的相关系数分别为0.700, 0.661, 0.0157, 0.0103, -0.0125, -0.286, 0.286, -0.0269, 0.0671, 0.993, -0.197, -0.123, 0.150, 0.0219.通常情况下通过以下取值范围判断变量的相关强度:相关系数在0.8~1.0为极强相关; 相关系数在0.6~0.8为强相关; 相关系数在0.4~0.6为中等强度相关; 相关系数在0.2~0.4为弱相关; 相关系数在0~0.2为极弱相关或无相关.选取特征参数的原则如下:相关系数在0.8以上的特征参数可以相互替代, 特征参数与油耗相关系数需大于0.2.最终取平均速度vmean, 巡航时间比rdrive, 行驶距离
平均速度vmean, 行驶距离
式中:n为某工况块的时间长度; vi 为在某工况块内i时刻的车速; ndrive为某工况块内速度不为0的时间长度.
| 表1 各特征参数之间相关系数表 Table 1 Correlation coefficient between the driving features |
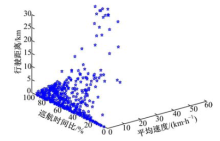
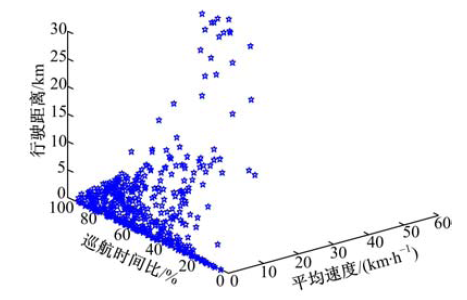
用平均速度vmean, 行驶距离
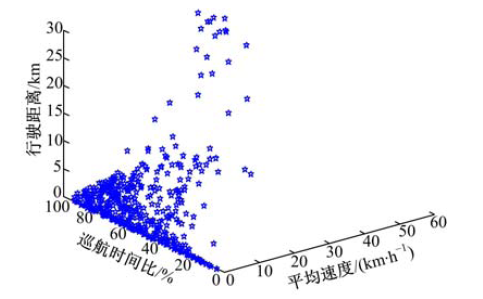 | 图4 工况块三维散点图Fig.4 Three dimensional scatter plot of micro-trips |
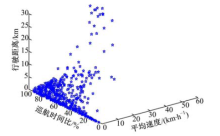
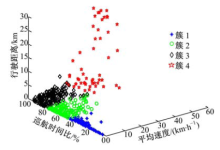
图5是将图3的数据进行K-均值聚类分析后的结果, 将数据划分为4个簇, 分别代表了城市工况中的4种典型行驶工况, 最终的某城市交通循环工况将由4种典型行驶工况拟合而成.
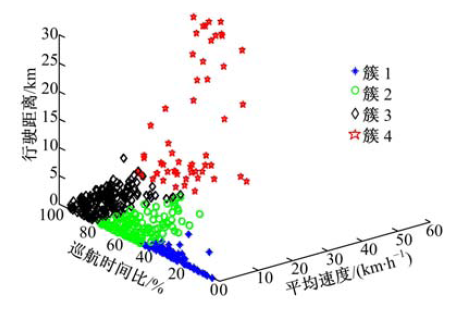 | 图5 工况块K-均值聚类分析二维散点图Fig.5 Two dimensional scatter plot of analysis micro-trips by K-means clustering |
(1)城市闹市工况:在城市的中心地带, 交通状况拥挤, 汽车速度低, 启停频繁, 工况块平均速度低, 巡航时间比低, 行驶距离短.
(2)城市生活区工况:在城市的生活区内, 交通状况一般, 汽车速度较低, 启停较为频繁, 工况块平均速度较低, 巡航时间比较低, 行驶距离较短.
(3)城市郊区工况:在城市的郊区, 交通较好, 汽车车速较高, 启停较少, 工况块平均速度和巡航时间比较高, 行驶距离较长.
(4)高速公路工况:在高速公路上, 交通状况好, 汽车车速高, 启停少, 工况块平均速度和巡航时间比例高, 行驶距离长.
参考国外标准工况, 将城市循环工况的持续时间取为1500 s左右[11].利用各簇总持续时间在整个记录数据中所占的时间比例, 可确定各簇工况块在最终拟合工况中所占的时间:
式中:ti为簇i在拟合工况中的持续时间; tdrivingcycle为最终代表性工况的持续时间; toverall为所有工况块数据的总持续时间; ti, 为簇i中工况块j的时间; nj 为簇i中所有工况块的总数.
根据式(9)可以得到最终某城市循环工况中4种不同行驶工况的时间比例和时间长度, 如表2所示.
| 表2 不同行驶工况的时间比例和时间长度 Table 2 Time scale and time duration of different driving cycles |
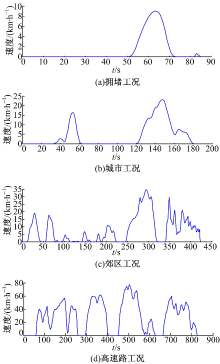
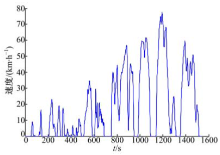
在4个簇中挑选出代表性的工况块来代表每个簇, 根据K-均值聚类算法的原理, 挑选的原则为将距离聚类中心最近的工况块作为各个簇的代表性工况块, 如图6所示.由循环工况各个行驶工况时间和工况块拟合出最终的城市循环工况, 如图7所示.
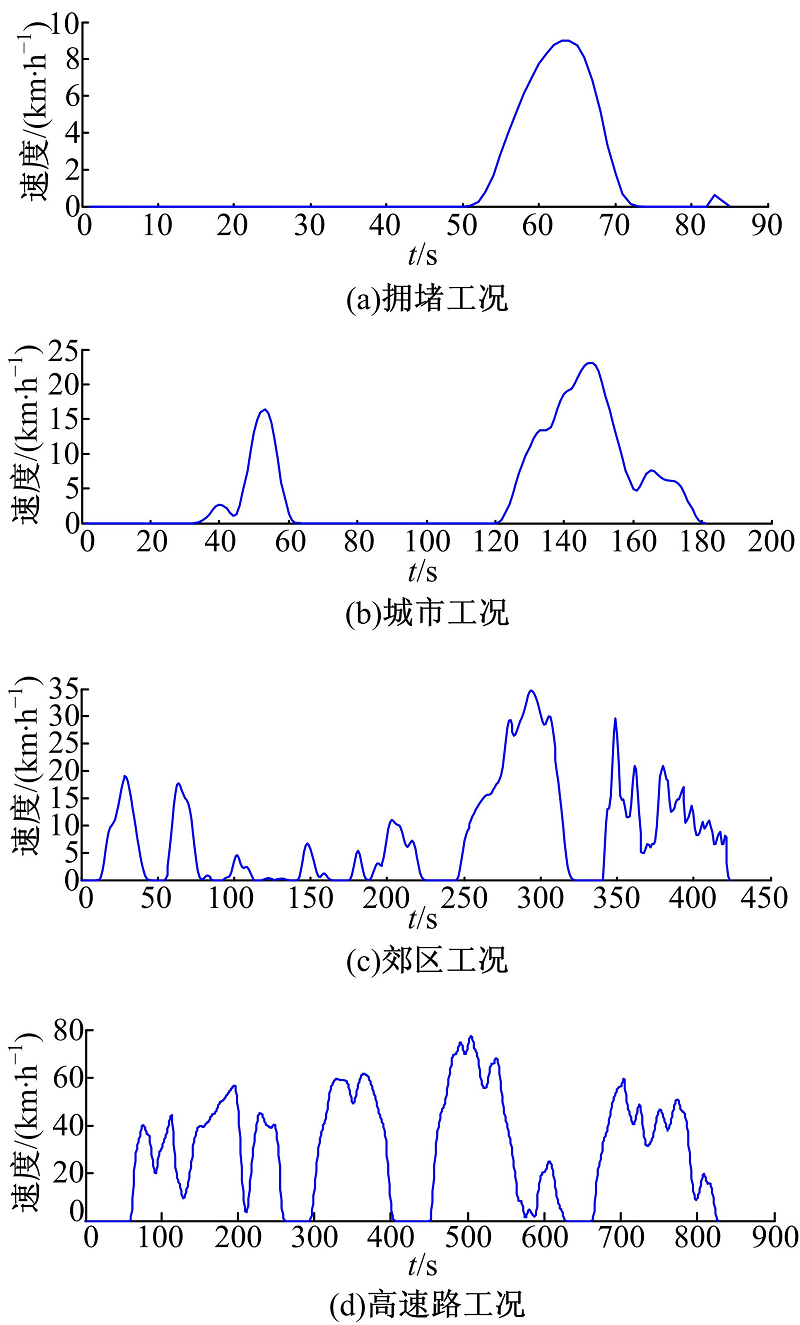 | 图6 四种簇的代表工况块Fig.6 Representative micro-trips of four clusters |
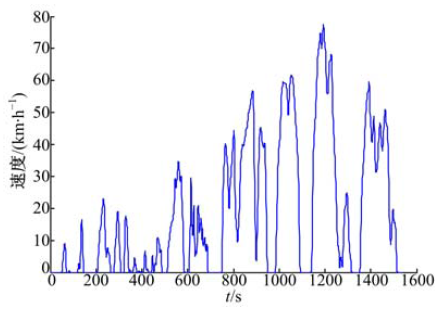 | 图7 某城市循环工况Fig.7 Driving cycle of a sample city |
首先验证拟合的循环工况是否符合要求.将通过基础实验所采集的全部工况数据和拟合后的某城市循环工况(CHCQ), 以及CHCQ工况的转毂台架实验结果进行对比分析, 以验证某城市循环工况是否能够反映整个工况数据的特点.首先, 将基础实验所采集的全部工况与CHCQ工况的特征参数进行对比, 特征参数分别为平均车速, 平均正加速度, 平均负加速度, 巡航时间比, 如表3所示.由于偶然性作用比较大或与4.1节中特征参数相关性高, 将其他特征参数(最高车速, 最大正加速度, 最小负加速度等)进行对比的意义不大.将试验用车采集基础工况数据时的油耗与转毂台架CHCQ工况下的油耗进行对比, 两者的百公里油耗分别10.38和10.26, 误差为1.16%.几种重要特征参数以及百公里油耗的误差均在5.0%以内, 表明所拟合出的某城市循环工况能够较好地反映该市城市交通状况, 符合设计要求.
| 表3 循环工况与基础实验全部工况参数对比 Table 3 Reduced parameter between the final driving cycle and driving cycle of base experiment |
将某城市循环工况同一些典型工况(EUDC, ECE, FTP-15)的特征参数进行对比, 结果如表4所示.与上述3种循环工况对比, 该城市循环工况最高车速, 平均加速度和平均车速相对较低, 巡航时间比高, 最大加速度和平均负加速度大, 最小加速度和平均正加速度小, 其主要原因在于该城市属于内陆山地型城市, 道路曲折, 坡道陡而多.
| 表4 几种循环工况特征参数对比表 Table 4 Driving features comparison of several driving cycles |
通过转毂实验台和废气分析仪对4种工况的排放和油耗数据进行采集, 其中采集的污染物为一氧化碳(CO), 碳氢化合物(HC), 氮氧化合物(NOx).将实验室所采集到的油耗和排放数据进行对比, 结果如表5所示.该城市循环工况的百公里油耗相对较高, 污染物的排放高, 其原因在于该城市工况启停次数多, 车速变化大, 使得油耗和污染物排放相对较高.
| 表5 四种工况油耗以及污染物排放对比 Table 5 Comparison about fuel consumption and pollutant emissions of four different driving cycles |
(1)通过实车实验采集某城市汽车运行工况数据, 并进行数据处理.将工况数据划分为工况块, 运用平均速度, 行驶距离和巡航时间比3个特征参数对工况块进行K-均值聚类分析, 根据距离聚类中心越近越能代表簇特征的原则选取工况块合成最终循环工况.该方法选取特征参数少, 运算简单, 精度高, 有较强的适用性.
(2)将该城市循环工况与其他典型循环工况进行对比, 得到该城市道路典型的特征为:平均速度低, 巡航时间比高, 最高车速低, 启停次数多, 最大加速度大, 最小加速度小, 平均正加速度小, 平均负减速度大, 使汽车的油耗排放相对较高, 这些特征很好地反映了该城市的交通特点.
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|