{kind=link}
{kind=link}
{kind=link}
基于信道补偿的说话人识别算法
[申铉京1, 2  , 翟玉杰
, 翟玉杰1, 2 , 卢禹彤3 , 王玉1, 2, 4 , 陈海鹏1, 2 ]
, 翟玉杰]
|
|


作者简介:申铉京(1958-),男,教授,博士生导师.研究方向:图像处理及模式识别,多媒体信息安全,智能控制技术.E-mail:xjshen@jlu.edu.cn
现有说话人识别算法普遍受信道因素的干扰,为了提高算法的准确率,在特征级利用特征弯折算法对语音特征参数进行处理,在模型级利用因子分析技术对说话人混合高斯模型(GMM)进行信道处理。对端点进行检测后,利用特征弯折算法对语音特征参数梅尔倒谱系数(MFCC)进行处理,去除线性信道和背景噪声的影响,并建立说话人GMM。然后利用因子分析技术拟合说话人特征空间与信道空间的差异,去除信道因子的影响。最后提取高斯超向量并通过支持向量机(SVM)得到识别结果。实验结果证明了信道补偿算法与GMM-SVM相结合能获得更好的识别率,并能保证算法的鲁棒性。
Channel interference factor for the identification results is prevalent among the existing speaker recognition algorithm. In order to improve the accuracy of the system, in this paper, feature warping is used to compensate the channel factor of Mel-Frequency Cepstral Coefficient (MFCC) features. Then, factor analysis technique is applied to deal with the channel factors of the speaker's Gaussian Mixture Model (GMM). In the endpoint detection phase of speech of this recognition system, the GMM for speech modeling is built to accurately determine the beginning and end points of the speech segment, and then the features after feature warping are used to establish speaker GMM. Using factor analysis technique to fit the differences between the speaker characteristics space and the channel space, the algorithm removes channel factor from GMM, and then extracts GMM super-vectors as input of the Support Vector Machine (SVM) to obtain recognition results. Experimental results show that the combination of channel compensation technique and SVM can obtain better recognition rate, and ensure the robustness of the system.
目前流行的说话人识别方法主要有概率统计方法、辨别分类器方法。概率统计方法包括隐马尔可夫(HMM)方法[1], 高斯混合模型(GMM)[2]; 辨别分类器方法包括人工神经网络(ANN)方法[3], 支持向量机(SVM)方法[4]等。2001年Kasuriya等[5]开发出将HMM与ANN相结合的识别算法, 其识别效果及运算速度均得到提升, 但是仍依赖于文本提示, 信道因素仍然制约着算法性能的进一步提升。2006年Campbell等[6]在高斯模型的基础上引入SVM分类器, 该方法不仅具有GMM的表征能力和SVM优秀的分类性能, 并且引入了新的核函数, 使得分类特征具备了GMM均值、方差、权值的属性。后来提出的多核SVM识别方法使得识别效果得到提高, 但是这些方法并没有考虑信道因素, 会导致语音失真, 使得训练环境与实际环境不匹配, 从而影响实际应用中的方法识别性能。2010年Munteanu等[7]改进的HMM系统取得了不错的识别效果并且识别时间大大降低, 但却需要依赖于文本提示, 训练过程依然需要占用相当大的存储空间, 没有考虑信道因素的影响。Badran等[8]提出的ANN方法, 具有很强的聚类能力和静态分类能力, 可将它用于特征提取和说话人的分类判决, 但由于训练时间较长及动态时间规整能力弱等缺点难以实际应用。
现有的说话人识别算法受到信道因素的影响使得其难以获得理想的识别效果[9], 因此本文利用特征弯折算法和因子分析技术分别对识别过程中的特征级和模型级数据进行信道处理。首先对说话人识别算法进行了详细介绍, 主要包括语音信号端点检测、说话人GMM建立、GMM超向量及支持向量机等。然后利用说话人特征建立全局背景模型(UBM), 使用自适应算法得到说话人GMM。同时, 为了消除信道因素对于识别结果的影响, 引入信道补偿技术, 特征级的特征弯折算法与模型级的因子分析技术分别对说话人语音特征及GMM进行处理。最后提取GMM超向量作为SVM分类器输入得到识别结果。
本文的说话人识别算法是在现有GMM-SVM算法基础上改进而来的, 训练过程中首先利用高斯模型法确定语音段中的有效语音, 提取梅尔倒谱系数(MFCC)特征, 在UBM上自适应得到说话人GMM, 然后提取GMM超向量作为SVM分类器的输入, 建立SVM模型。识别过程中, 通过测试语音得到高斯超向量后作为SVM分类器的输入得出识别结果。本文识别算法框架如图1所示。
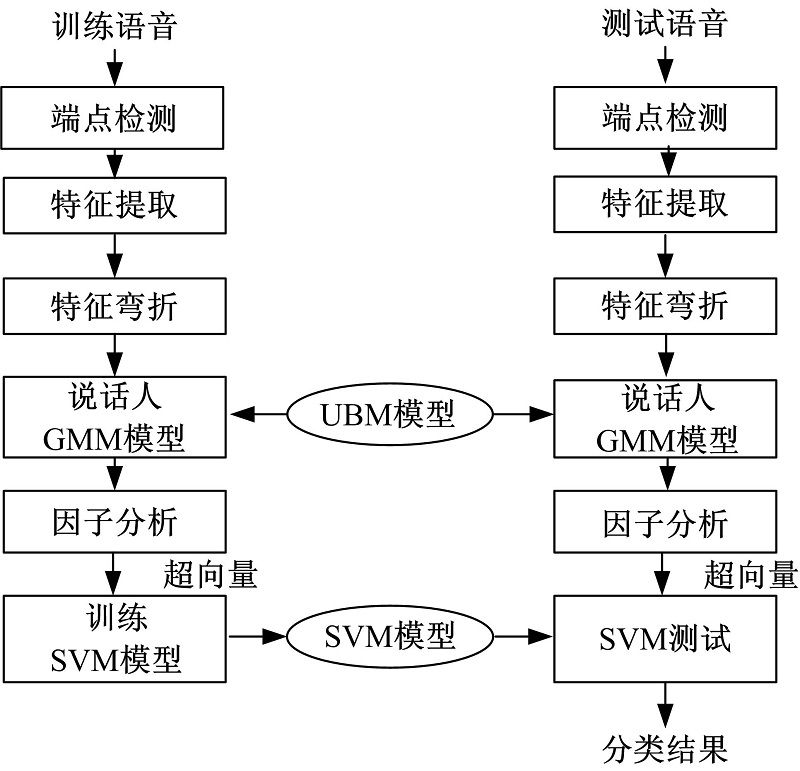 | 图1 引入信道补偿算法后识别过程Fig.1 Identification process with channel compensation algorithms |
GMM是一种多维概率密度函数的线性组合, 从说话人中提取的D维矢量特征x,可以使用包含M个分量的高斯混合分布的概率密度函数来描述[2]:
式中:pi(x)为概率密度函数分量, i=1, 2, …, K; ω i为各分量的权值, 且满足
使用三元组形式表示
在UBM基础上, 通过贝叶斯自适应方法得到说话人模型。自适应过程在UBM模型和说话人模型中提供了严格的耦合, 其中自适应因子为模型更新前后权值、均值、方差联系的桥梁, 维持着模型间数据的平衡[10]。
高斯超向量是将说话人GMM的均值组合成一个超大维度向量, 用以表示说话人。如果每个说话人GMM有M个高斯混合数, 特征选择为N维, 则此向量维度为M× N。
高斯超向量与SVM结合, 弥补了传统SVM分类器对于说话人特征表征能力弱的缺点, 并且发挥了SVM对于数据分类性能强的优势, 提高了说话人识别算法的准确率。
算法利用Jeffery值作为高斯模型的距离参数, 用GMM来描述环境中的噪声, 以确定语音的起止点[11]。定义高斯混合模型由3个独立的高斯分量组成, 根据语音特征与噪声模型匹配值判断是否属于噪声, 并实时更新模型参数。步骤如下:
(1)模型建立
假定语音段开始的时间T内为初始背景噪声, 对于时间段0~T内, 计算各帧均值及方差。使用EM算法进行高斯建模, 得到描述初始背景噪声的高斯混合模型
(2)匹配计算
使用Jeffery值作为距离参数进行比较, 利用当前帧的均值及方差计算Jeffrey值:
令
(3)模型更新
对于噪声帧, 取学习因子常量为
式中:
GMM识别模型与SVM的结合保证了最小化期望风险, 避免了过训练问题, 还可以使用核函数解决非线性问题。在SVM方法中, 核函数至关重要, 它取代了内积, 减小了计算复杂性, 避免了维度灾难[12]。
SVM模型可以理解为一种二分类模型, 通过学习使得特征空间间隔最大化, 从而转化为凸二次规划问题。SVM使用核函数对应于特征变换的内积, 与之对应的决策规则可以表示为:
式中:
由于核函数满足Mercer条件, 核函数可以表示为:
式中:
对于SVM分类器而言, 其依赖于边界最大化方法, 即可分数据集通过在高维空间中确定一个分类超平面使得满足边界最大化。训练集中处于分类边界上的特征点是SVM的支持向量, SVM模型的训练过程就是确定类间支持向量的过程。本文选取以下两类核函数。
线性核函数:
高斯核函数:
实际应用中, 语音采集环境的复杂性及设备的多样性容易导致语音信道失配。背景噪声和信道因素等是影响系统识别率的重要原因。说话人语音信号特征易受到加性噪声及线性信道干扰而引起失配, 针对这一问题本文提出采用特征弯折技术对语音特征数据进行处理。
训练说话人模型GMM的过程中利用特定信道下的大量语音集, 在UBM的基础上自适应得到特定的说话人模型。由于UBM的数据信息主要包含有背景噪声、信道噪声、与特定说话人无关的特征参数分布等, 在其基础上自适应得到的说话模型必然会保留其信道和噪声信息。因此本文又在模型级引入因子分析技术, 从说话人模型分离出说话人空间、信道空间及各自分别对应的特征向量。最终获得与信道无关的说话人模型数据作为支持向量机的训练数据。
特征弯折利用基础分布函数的原理, 把说话人提取的原始特征向量序列变为符合标准分布的规则化特征序列。语音信号在本质上是多模态的, 理想的目标分布也需要是多模态的并且可以代表说话人特征的真实分布。当选择完合适的目标分布后, 开始参数化过程。
特征弯折原理假设各个频谱特征间相互独立, 并且将语音信号进行加窗处理后再进行排列, 最终得到的居中倒谱系数在排序后位置变为
原始音频信号特征序列的中心位置倒谱系数
式中:
特征弯折算法一方面补偿了线性信道内的短时均值干扰; 另一方面试图更加接近特征信号的源分布, 并且限制了噪声影响。作为特征归一化方法应用于说话人识别中, 能够进一步提高其信道鲁棒性, 加强其对于不同应用环境的适应性能, 从而提高说话人识别的准确性。
为了减小信道因素的干扰, 对说话人模型进行补偿, 以达到提高识别准确率的目的, 将因子分析技术与GMM-SVM紧密结合。
通过语音信号得到GMM后使用LFA方法去除信道因素的影响, 补偿测试语音中与说话人身份相关的特征空间。因子分析模型为:
该模型将由说话人
在信道空间估计的过程中, 令
式中:
令
最终获得说话人及信道统计量如下:
实验所使用语音库为TIMIT语音库, 共选取36个人, 其中男、女各18人, 每人10段语音用于UBM模型的训练。SVM分类器是台湾大学林智仁等[14]开发设计的LIBSVM开发包, 并使用线性核及高斯核两种核函数作对比分析。GMM超向量作为SVM的输入向量, 采用one-versus-one的多分类模型, 每两个说话人建立一个二分类的SVM分类器, 如果有K个人, 则共需要K(K-1)/2个子分类器。
本文进行两组对比实验。训练集及测试集均选取76个人的语音。特征参数MFCC是将一维空间中的语音信号变换到频域中, 对人耳听觉特性充分模拟后得到的非线性倒谱域特征, 识别性及抗干扰能力强。第一组实验以12阶MFCC作为初始使用的特征向量, 并分别加入其一阶、二阶差分组成24维(MFCC_D)、36维(MFCC_D_A)特征向量。验证在普通MFCC参数下及加入差分系数后信道补偿算法对识别结果的影响, 以获得更好的识别算法, GMM混合数为512; 第二组实验则采用单一MFCC, 取维度逐渐递增的20~28阶MFCC, GMM混合数为512。分别统计两组实验加入信道补偿算法前、后的识别效果。
表1为使用12阶的MFCC及加入一阶差分、二阶差分后的识别结果。从实验结果可以看出:当引入特征参数的一阶差分(MFCC_D)及二阶差分(MFCC_D_A)后算法识别率均逐步提高, 当引入信道补偿后在线性核及高斯核的SVM下识别率均得到提高。未引入信道补偿前(GMM-SVM)加入特征参数一阶差分, 算法识别率提高不明显。引入信道补偿后(FC-SVM)算法识别率明显提高。二阶差分使得算法识别率下降, 特征增加使得高斯模型建模维度增加, 以及加入二阶差分系数导致身份信息的丢失, 使得区分性变差、干扰性增加, 信道补偿算法无法去除二阶差分带来的特征干扰, 识别率下降, 相对于没有引入信道补偿算法的识别率均有所提高。
| 表1 使用信道补偿前后算法识别率 Table 1 Recognition rate before and after using channel compensation % |
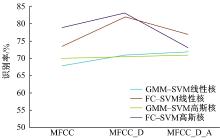
通过图2对实验结果进行分析, 未引入信道补偿前特征参数维度增加, 算法识别率变化不大, 引入信道补偿之后算法的识别率得到提高。
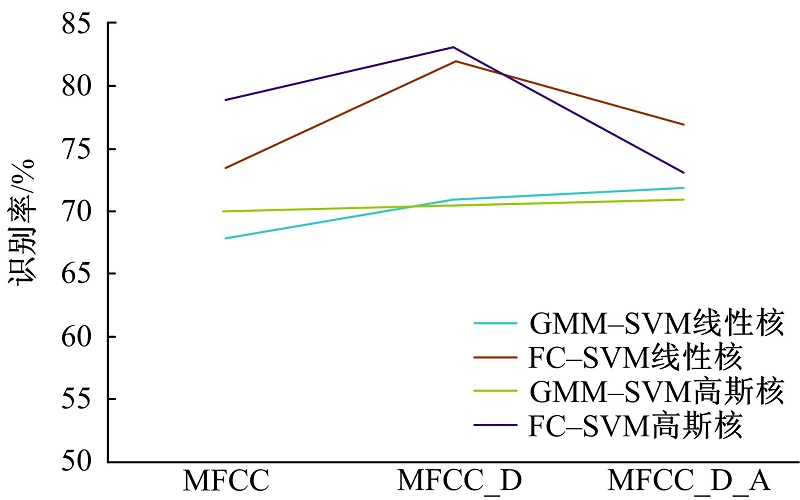 | 图2 信道补偿对比图Fig.2 Comparison chart of channel compensation |
表2为使用单一MFCC作为训练模型的特征参数, 并逐渐增加特征参数维度, 信道补偿对于系统性能的影响。由表2可以看出:当特征参数维度逐渐增加时算法识别率提升, 当维度达到24维以后识别率趋于稳定, 逐渐增加特征维度后其识别率不再提高甚至有所降低。一方面由于MFCC不同维度下的系数所能代表的说话人的能力不同, 并且分类器在高纬度数据时其分类效果受到影响, 另一方面在建立模型时其所提供的不同说话人之间的区分度信息不相同, MFCC在低维系数时鲁棒性较好, 高频系数时鲁棒性降低。引入信道补偿算法后, 在线性核及高斯核下其识别率均比未引入信道补偿算法前得到提升。
| 表2 单一特征使用信道补偿前后算法识别率 Table 2 Recognition rate using single feature before and after using channel compensation % |
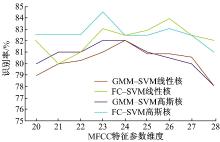
使用图3对表2结果进行统计分析, 发现使用信道补偿后算法识别率优于改进前并且趋于稳定。参数维度的继续增加使得识别率逐步降低, 是由于MFCC参数在低频系数时具有较好的鲁棒性, 高频系数时不具有较高的分辨率。
从实验结果可知, 改进后的算法性能得到明显提升, 这是由于一方面利用了GMM超向量的特征表征能力, 一方面又利用SVM模型对于说话人分类效果的改善, 在此基础上加入因子分析, 增强了说话人自身特征在GMM的区分性, 减弱了信道因素的影响, 提升了识别算法对于信道影响的鲁棒性。
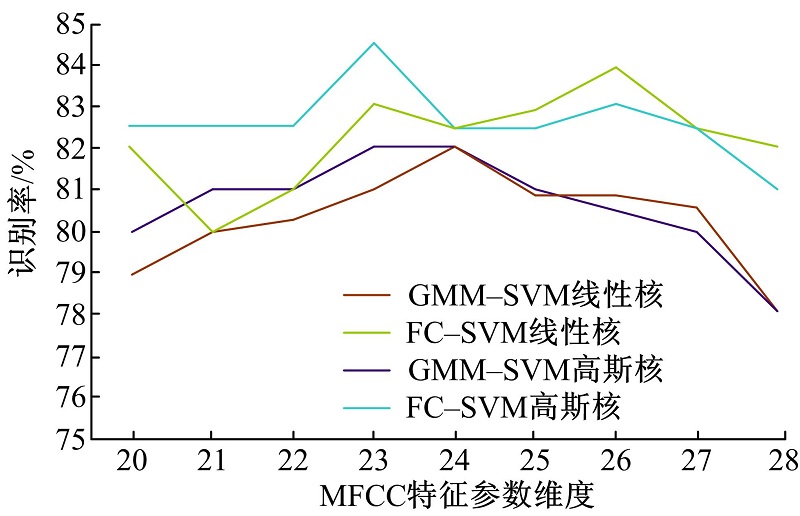 | 图3 识别率对比Fig.3 Comparison of recognition rate |
在特征级利用特征弯折有效地降低了信道因素及背景噪声的干扰, 减小了信号畸变对建立说话人模型的影响。在模型级利用因子分析技术进行跨信道处理, 通过对已有高斯超向量中的信道因子进行估计和消除, 降低了信道空间对说话人识别的影响, 提升了识别性能, 相对于传统的GMM-SVM说话人识别算法具有更好的鲁棒性。实验中随着特征维度的增加, 识别率逐渐提高, 当达到一定维度后识别效果下降, MFCC高维数据影响了识别效果, 不同维度数据对说话人模型的区分性贡献不同, 高频系数的表征能力较弱。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|