
{kind=link}
{kind=link}
{kind=link}
基于半监督学习的朴素贝叶斯分类新算法
[董立岩1  , 隋鹏
, 隋鹏1 , 孙鹏1 , 李永丽2 ]
, 隋鹏|
|


作者简介:董立岩(1966-),男,教授,博士生导师.研究方向:数据挖掘.E-mail:dongly@jlu.edu.cn
为了在有标签的训练集中保留高质量的样本,首先利用无标签训练集得出置信度高的 k个样本,再结合有标签训练样本,不断迭代直至训练完成。实验结果表明:随着无标记样本比例的不断增加,本文算法预测准确性明显高于朴素贝叶斯分类算法,而且其性能比传统半监督学习方法有所改善。
A novel naive Bayes classification algorithm based on semi-supervised learning is proposed. First, to retain high quality samples in the training sect with class label, the unlabeled training set is sued to obtain k samples of high confidence. Then, these high confidence samples are combined with the labeled-training samples to iterate until the training is complete. The experimental results show that with the increasing proportion of unlabeled samples, the predictive accuracy of the proposed algorithm is significant higher than that of the Na?ve Bayesian classification. In addition, the effectiveness and performance of the algorithm are improved compared with the traditional semi-supervised learning algorithm.
朴素贝叶斯算法因其具有简单、快速和高准确率等特点被广泛应用于分类任务中。但是朴素贝叶斯分类算法存在一定的弊端, 它要求条件属性间满足类条件独立假设, 这在实际应用中是很难满足的。如果实际数据属性间高度相关, 就会导致分类效果大大下降。许多学者提出了一些改进方法, Zhang等[1]根据属性的重要性, 提出了给不同属性赋予不同权值的加权朴素贝叶斯(Weighted naive Bayes, WNB)模型, 并给出了采用爬山算法和Monte Carlo技术确定权值的加权朴素贝叶斯分类方法。Zheng等[2]利用懒惰式学习策略提出了一种懒惰式贝叶斯规则(Lazy Bayesian rule, LBR)学习技术, 该方法在局部朴素贝叶斯规则的归纳中使用懒惰式技术, 虽然大大地提高了分类精确度, 但是效率很低。Wang等[3]提出了一种半懒惰式(Semi-Lazy)的限制性贝叶斯网络分类器的条件概率调整方法, 在某些情况下可以减小错误分类率。Yager[4]利用有序算子, 提出一种新的朴素贝叶斯的扩展算法。当无标记的数据集数量较大时, 有监督的学习不能准确地预测出元组的类别, 而无监督学习由于没有指导所以难以得到较高精度的学习结果[5]。因此, 半监督学习(Semi-supervised study)显得尤为重要。半监督学习的研究从Shahshahani和Landgrebe的工作开始[6], 它结合了监督学习和无监督学习的优点[7], 可以根据数据固有的特性, 既不丢失完整的有标记的数据信息, 又能够利用大量不完整数据(无类标号数据)的信息进行学习, 因此具有更好的应用前景, 而且处理的问题也更具普遍性。但是在传统的半监督学习贝叶斯分类过程中, 将预测后的元组添加到训练集中可能会在迭代的过程中强化错误, 从而降低准确率。因此本文提出一种新型半监督朴素贝叶斯算法(Novel semi-supervised naive Bayes, NSNB), 它可以提取高置信度的无类标号样本, 将它们依次添加到训练集中, 进而可以对测试集中的元组所属的类别做出准确的预测。该方法比传统半监督朴素贝叶斯(Semi-supervised naive Bayes, SNB)算法以及朴素贝叶斯(Naive Bayes, NB)算法有更高的预测准确率, 比传统的半监督贝叶斯分类算法有更快的训练速度。
朴素贝叶斯分类器(Naive Bayes classifier, NBC)是贝叶斯分类器中应用最广泛的模型之一。该模型描述如下:设训练集中包含m个类C={C1, C2, …, Cm}, n个条件属性X={X1, X2, …, Xn}。假设所有的条件属性X都作为类变量C的子节点。当且仅当:P(Ci|X)> P(Cj|X)(1≤ i, j≤ m, i≠ j)成立, 将给定的一个待分类样本X={x1, x2, …, xn}分配给类Ci (1≤ i≤ m)。根据贝叶斯定理, Ci类的后验概率为:
如果事先不清楚类在训练集上的概率, 可以假定每个类别概率相等, 即
根据朴素贝叶斯分类算法的条件属性相互独立的假设, 有P
概率
式中:
朴素贝叶斯分类算法对待具有不同数据特点的数据集合, 分类性能的差别不大, 稳定性较强[9]。对于数据缺损的情况, 该算法会通过预处理来提高数据的完整性。朴素贝叶斯分类算法从训练集中得到类先验概率和特征项的类条件概率来预测后验概率, 再根据公式得出需要被分类的实例的类情况。有限的训练数据集的分布难以完全代表总体情况的分布, 所以计算得到的先验概率的可信度有待修正。如果训练集没有良好的数据完备性, 那么预测的测试数据的类别标签的准确性就有可能下降。
半监督学习同时使用大量的无类标号的数据以及有类标号的数据来进行模式识别工作[10]。
由于传统的朴素贝叶斯分类算法使用有类标号的训练集来预测测试集中数据的类别, 所以这里将式(3)记为:
本文使用基于半监督学习的半监督朴素贝叶斯算法, 所以将式(4)修改为:
式中:
当使用半监督学习时, 将会要求尽量少的人员来参与工作, 同时, 又能够带来比较高的准确性, 因此, 半监督学习越来越受到人们的重视。目前, 人们正在理论和实践上对半监督学习进行分析[13, 14]。本文改进了半监督自我训练模型, 并结合朴素贝叶斯分类算法, 给出一种新型的分类方法。
使用半监督学习和朴素贝叶斯结合的方法对大量未知类标号的数据进行分类, 半监督学习基本原理是基于少量的带类标注的训练样本建立初始分类器, 每次学习过程中分类器可以主动在未带类标注的候选样本集中选择最能体现分类器性能的样本, 并将这些样本以一定的方式加入到有类标号训练集中进一步训练分类器。传统的方法是将从无类标号候选集样本中预测所得的类标签连同样本数据一起添加到有类标号训练样本集当中, 从而提供更多的训练样本, 提高对测试集预测的准确率, 但是如果预测结果错误, 则会导致在循环的迭代中把大量带有错误类标注的元组添加到有类标号训练样本集中, 从而降低训练样本的正确率, 进而降低预测的正确率。本文使用NSNB算法通过选择无类标号样本集中预测准确程度比较高的样本, 将此类样本添加到有类标号训练集中, 使得有类标号训练样本集中保存的是高质量的样本, 进而能够高准确率地预测候选样本中的数据的类标号。利用NSNB算法生成数据的类标号的过程如图1所示, 其中TopK表示从无类标号数据集中选取的置信度高的
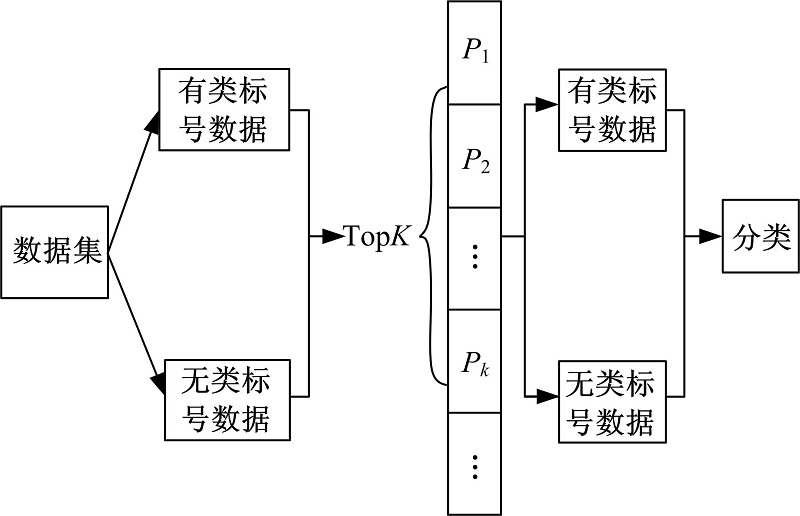 | 图1 数据类标号生成过程Fig.1 Process of generating class of data |
输入:有类标号的训练集L; 无类标号的数据集U以及其中任一个样本
输出:U中数据的预测类别C; 分类准确率R。
方法:
Step1 统计训练集L的类标号集合, 记为C{C1, C2, …, Cn}。
Step2 从U中任取一个样本
Step3 计算
Step4 令confidencei为P(Ci|
Step5 |C|=|C|-1, 如果|C|不为零, 返回到Step3。
Step6 返回所有confidencei中数值最大的作为
Step7 |U|=|U|-1, 如果|U|不为零, 返回到Step2。
Step8 对Tlist中的
Step9 从Tlist中取出前K个样本
Step10 利用新得到的L来预测测试集中的样本的所属类别C, 并计算预测准确率R。
从算法中可以看出, 当K值越小, 也就是被加入到训练集L中的数据越少, 训练性能越高, 此时NSNB算法接近于NB算法; 当K值越大, 也就是被加入到训练集L中的数据越多, 训练性能越低, 此时NSNB算法接近于SNB算法。为了兼顾训练准确率和训练性能, 本文根据不同数据集手动选取适合各个数据集的K值。
(1)如果对测试集中数据预测得比较准确, 则应该取较大的K值, 也就是将尽可能多的、准确的从训练集U中得到的预测结果及数据添加到训练集L中。
(2)如果对测试集中数据预测得不是很准确, 则应该取较小的
(3)通过计算
为了证明NSNB算法的有效性, 在UCI[15]机器学习资源库中选取了比较有代表性的5个数据集进行了实验。5个数据集的基本信息如表1所示, 对于每个数据集, 比较新型半监督朴素贝叶斯(NSNB)算法, 传统半监督朴素贝叶斯(SNB)算法以及朴素贝叶斯(NB)算法3种算法的分类的准确率和所用时间。
| 表1 实验中所用数据集的描述 Table 1 Description of dataset used in experiment |
由于ID一类的属性对于分类是无用的, 而且还会降低预测的准确率, 因而对部分实验数据集进行预处理, 例如实验前删除Adult数据集第3个属性fnlwgt。
本文选用的Micro-precision标准[16]的计算公式如下:
式中:
重复进行多次实验, 采用平均正确率来衡量分类的正确率:
式中: T为重复实验的次数, 本文中T=10。
测试数据集中有类标号和无类标号数据比例不同对聚类效果的影响。有类标号数据量与无类标号数据量的比例
| 表2 三种算法的准确率对比(γ =1:5) Table 2 Contrast of accuracy rate of three algorithms |
| 表3 三种算法的准确率对比(γ =1:10) Table 3 Contrast of accuracy rate of three algorithms |
| 表4 三种算法的准确率对比(γ =1:50) Table 4 Contrast of accuracy rate of three algorithms |
| 表5 三种算法的准确率对比(γ =1:100) Table 5 Contrast of accuracy rate of three algorithms |
实验所得准确率是通过多次计算取平均值得出的, 对于大部分数据集该值的浮动都比较小, 但有个别数据集通过多次计算所得的准确率浮动较大。从表2~表5中数据可以看出, 当数据集中有类标号的数据量较多时, NSNB算法与NB算法的准确率比较接近, 随着无类标号的数据量的增加, NSNB算法的准确率就明显高于SNB算法和NB算法, 当数据集中γ =1:50时, NSNB算法的准确率比NB算法的准确率提高20%以上, 所以对于有大量未知类标号的数据来说NSNB算法是比较有优势的。三种算法在5个数据集上的平均预测准确率如图2所示。
 | 图2 三种算法在数据集上预测平均准确率对比曲线Fig.2 Average prediction accuracy rate contrast curve of three kinds of algorithms in dataset |
从4种比例的分割中还可以看出:对于大部分数据集来说, NSNB算法的准确率要优于SNB算法, 但也有部分数据集中SNB算法要优于NSNB算法, 这是由于从此类数据集中得出的分类大多数都是准确率较高的预测, 而本文选择的
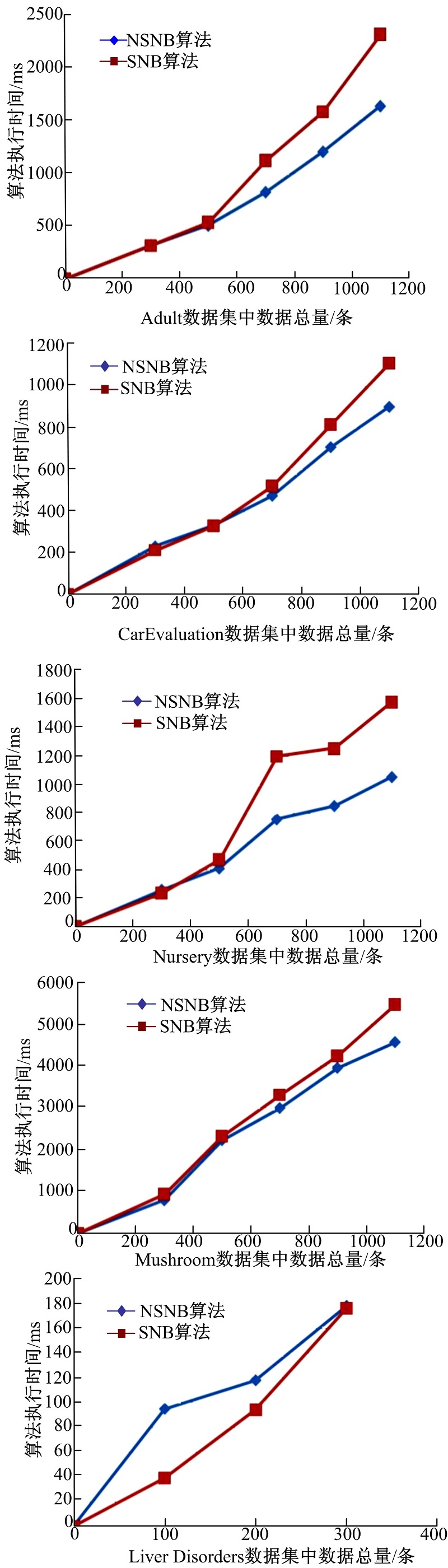 | 图3 五个数据集上算法NSNB和SNB的时间对比Fig.3 Contrast of NSNB and SNB consuming time in 5 kinds of datasets |
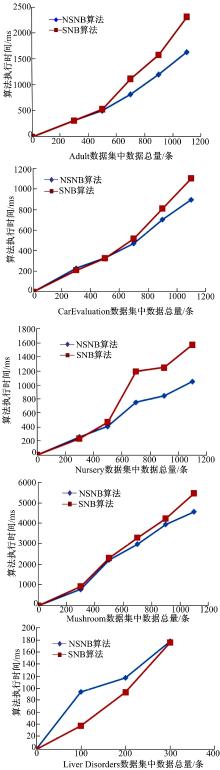
对比NSNB算法和SNB算法的运行时间, 本文以有类标号和无类标号数据比例为1:10为例分别计算两种算法在5个数据集上针对不同数据量的算法执行时间, 结果如图3所示。
实验结果证明:对于大部分数据集, 随着数据量的逐渐增加NSNB算法耗时小于SNB算法, 而且数据量越大NSNB算法的优势越明显。这是由于在NSNB算法第9步中筛选掉了大量不太可能正确的记录, 使得训练集不会迅速地增加, 从而节省了训练时间。但是从图3中可以看出, Liver Disorders数据集本身数据量比较少, 在300条数据记录内, NSNB算法优势无法凸显, 从其他四个数据集也可看出300条数据记录内, NSNB算法与SNB算法所用时间基本持平。其原因为:当数据量较少时, NSNB算法仍然需要生成数据置信度列表, 而SNB算法无需从无类标号数据集填入大量数据到有类标号训练数据集中, 所以会出现在个别数据集上SNB算法略显优势的情况。
在数据特征独立性假设的基础上, 讨论了朴素贝叶斯分类器的原理, 朴素贝叶斯算法需要对已知类别的大量数据进行训练, 但实际中又很难得到较为完备的训练数据, 所以本文在小型的有类标的训练集中, 利用NSNB算法自动增加高质量的训练量, 以强化朴素贝叶斯分类器的预测准确率。研究发现, NSNB算法分类精度较高, 而且还能提高分类器的性能。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|