
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
支持高效路径查询的数据空间索引方法
[王念滨 , 祝官文, 周连科, 王红卫]
, 祝官文, 周连科, 王红卫]
, 祝官文, 周连科, 王红卫]
|
|


作者简介:王念滨(1967-), 男,教授, 博士生导师.研究方向:数据空间,深度学习,并行计算, 机器学习等.E-mail:wangnianbin@hrbeu.edu.cn
首先,通过索引连接例子,分析了影响效率的因素。在扩展倒排索引基础上,构建了B-树索引,以支持大规模数据的高效查找。然后,构建了二级索引,以减少索引连接中的大量重复判断。最后,提出了路径查询算法。实验结果表明:该索引方法能够有效地解决索引连接问题和显著地改善数据空间路径查询效率。
A novel dataspace index method for efficient processing of path query is proposed. First, an example of joining the extended inverted index was illustrated to find the reason of inefficiency. Then, based on the extended inverted index, a B-tree index was built to efficiently search massive data. Furthermore, a secondary index was constructed in order to significantly reduce the number of repetitive comparisons with respect to index join process. Finally, a path query algorithm was presented based on the proposed dataspace index method. Experimental results show that the proposed method can not only efficiently deal with the problem of index join, but also significantly improve the performance of the path query in the dataspace.
在大数据时代, 各行业所获得的数据呈现海量、类型多样、价值密度低等特征[1], 传统的数据管理系统已无法满足当今用户的需求, 为此, Franklin等提出了数据空间概念[2]。其宗旨是为用户提供尽力而为(Best-effort)的服务, 而索引是实现该目标的基础, 因此研究一种高效的数据空间索引技术具有重要意义。
Dong和Halevy[3]首次研究了数据空间索引问题, 提出一种混合倒排索引技术以支持结构感知的查询。该技术通过统一索引数据空间中异构数据来支持结构感知的查询, 但容易导致数据空间访问效率低。为此, 基于对两个真实数据场景的观察, Song和Chen[4]提出了一种基于划分的混合索引技术, 该技术包含水平划分和垂直划分两种策略。Wang等[5]提出了一种紧凑索引技术, 提高了在个人数据空间中的查询质量。Zhong等[6]提出了一种MVP索引, 解决了大图环境下已知项的高效检索问题。针对星型SPARQL连接查询中大量的计算开销问题, Du等[7]提出了一种基于实体模式的索引划分方法。Dittrich等[8]提出了一种朴素(NAIVE)的索引方法。以上成果均无法高效地支持路径查询。
本文基于iDM模型, 提出了一种基于辅助索引的数据空间索引方法(EIBH), 该方法主要结合EIL索引、B-树索引和二级索引来解决路径查询效率低的问题。
iDM[8]模型本质上是一种图模型。每个资源视图
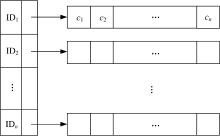
针对iDM模型, 本课题组已提出过一种高效的数据空间索引方法(EIL)[9], 以支持数据空间的高效访问。EIL方法主要是通过扩展倒排列表来索引资源视图的各个组件。具体来说:①对
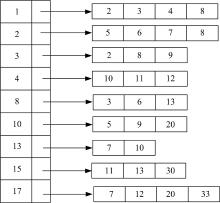
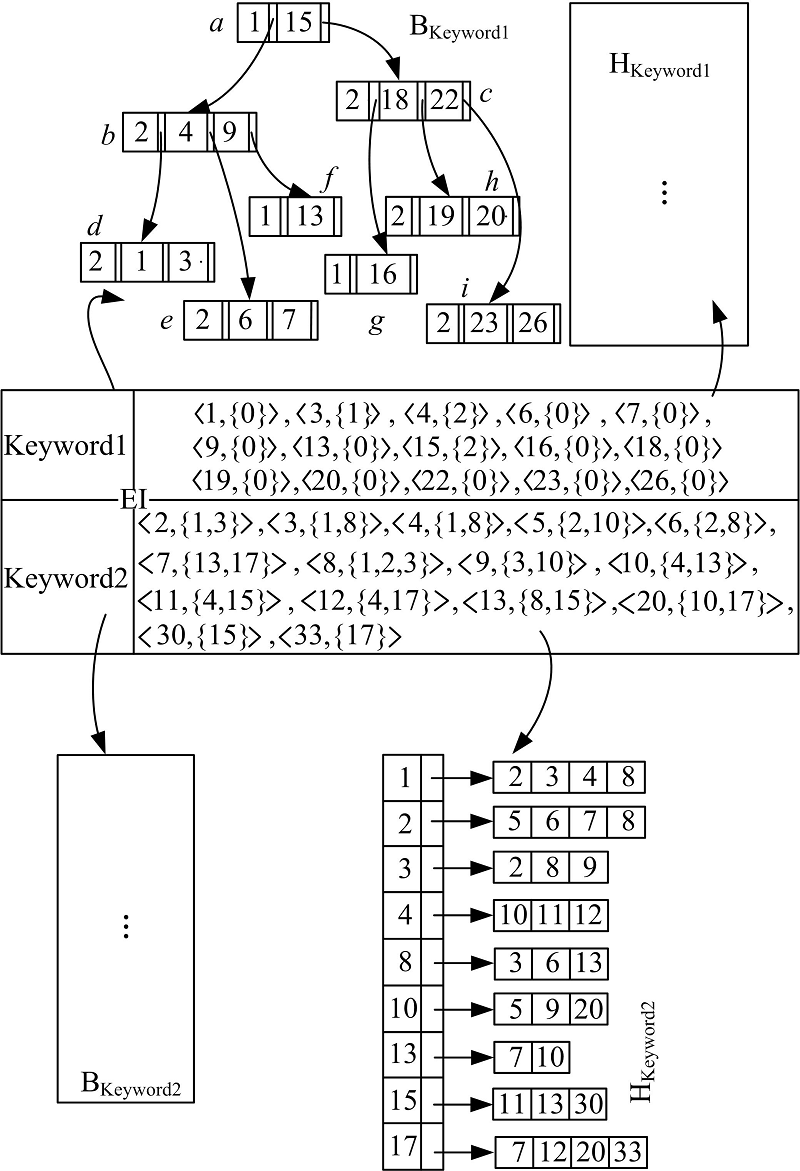
由于是讨论两个索引链表的连接操作, 因此只给出了只有两个关键字和对应链表的例子[9](见表1)。为了方便表示, 本文将索引进行了倒置。
| 表1 包含两个关键字的扩展倒排链表 Table 1 Extended inverted list including term Keyword1 and Keyword2 |
根据文献[9], 对于路径查询Keyword1/Keyword2, 处理它需要一步步判断LKeyword2中的节点的父资源视图是否在LKeyword1中。例如, 为了判断< 2, {1, 3}> 中的1或3是否与LKeyword1中的某个节点的RSid相等, 将其与LKeyword1进行比较。通过比较发现, 1出现在L的节点< 1, {0}> 的
为了解决索引连接中存在大量比较操作导致搜索效率低的问题, 引入了经典的B-树结构[10]作为辅助索引, 以提高查找效率。
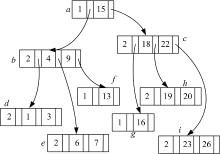
针对关键字Keyword1对应的索引链表LKeyword1, 构建了相应的B-树索引, 并记为BKeyword1。其中, 它是一颗4阶B-树, 如图1所示。
 | 图1 LKeyword1对应的B-树索引例子Fig.1 An example of B-tree index with respect to LKeyword1 |
下面具体描述在B-树中查找关键字过程。例如, 在图1的B-树上查找关键字19的过程如下:首先从根a开始, a中包含一个关键字15, 由于19大于15, 通过指针找到节点c, 节点c中包括关键字18和22, 由于18< 19< 22, 通过指针找到节点h, h中包含了关键字19, 因此, 可以知道BKeyword1包含关键字19。
注意, 由于构建的扩展倒排索引中可能存在扩展关键字[9], 这里只对普通关键字建立B-树索引, 不对扩展关键字建立B-树索引。
本小节通过为索引链表节点中的set of parentid的RSid建立二级索引来消除第1节例子中出现的重复判断操作, 使比较的次数显著降低。下面用H索引来表示二级索引, 如图2所示。
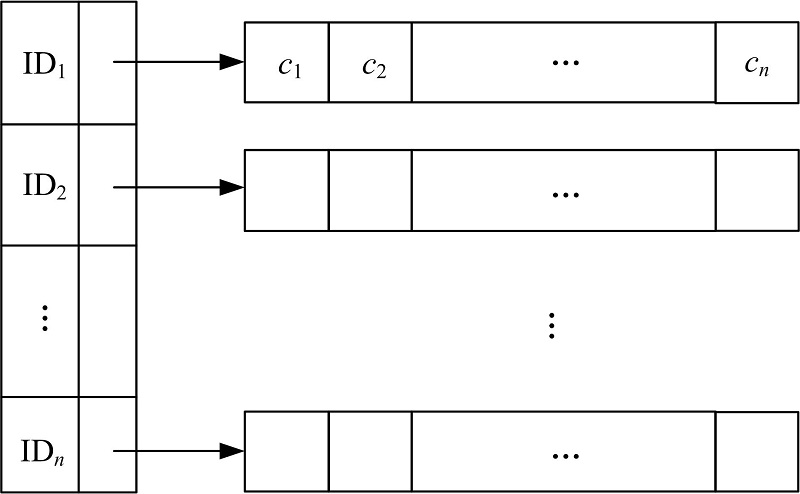 | 图2 二级索引示意图Fig.2 Sketche of the secondary index |
这里建立的二级索引与文献[9]中的扩展倒排索引类似, 但是索引的内容和实现方式存在明显的区别。首先, 二级索引中索引的内容为索引链表节点< RSid, set of parentid> 中的set of parentid中的每一个资源ID; 其次, 二级索引中并不采用链表的形式, 而是直接采用顺序存储结构数组。二级索引包含两个部分:父资源视图ID数组、与父资源视图ID数组中的每一个ID相关的子资源视图ID数组。
下面具体描述二级索引的建立过程。给定一个索引链表节点< RSID, {ID1, ID2, …, IDn}> 。在父资源视图ID数组中加入ID1(如果不存在), 同时在ID1相应的子资源视图数组中加入RSid。依次类推, 分别将ID2, …, IDn加入到父资源视图数组中。
按照上面介绍的构建方法, 为表1中的索引链表LKeyword2构建二级索引HKeyword2。首先将节点< 2, {1, 3}> 加入到二级索引中, 节点< 2, {1, 3}> 的父资源视图有{1, 3}; 然后将父资源视图1加入到二级索引的父资源视图数组中, 同时将2加入到1所对应的资源视图数组中; 接下来将3加入到父资源视图数组中, 将2加入到3所对应的资源视图数组中。按照< 2, {1, 3}> 的构建方法依次将< 3, {1, 8}> , < 4, {1, 8}> 等其余的索引链表节点加入到二级索引中, 最终得到的结果如图3所示。
与B-树索引一样, 构建的扩展倒排索引中可能存在扩展关键字, 只对普通关键字建立二级索引, 不对扩展关键字建立二级索引。
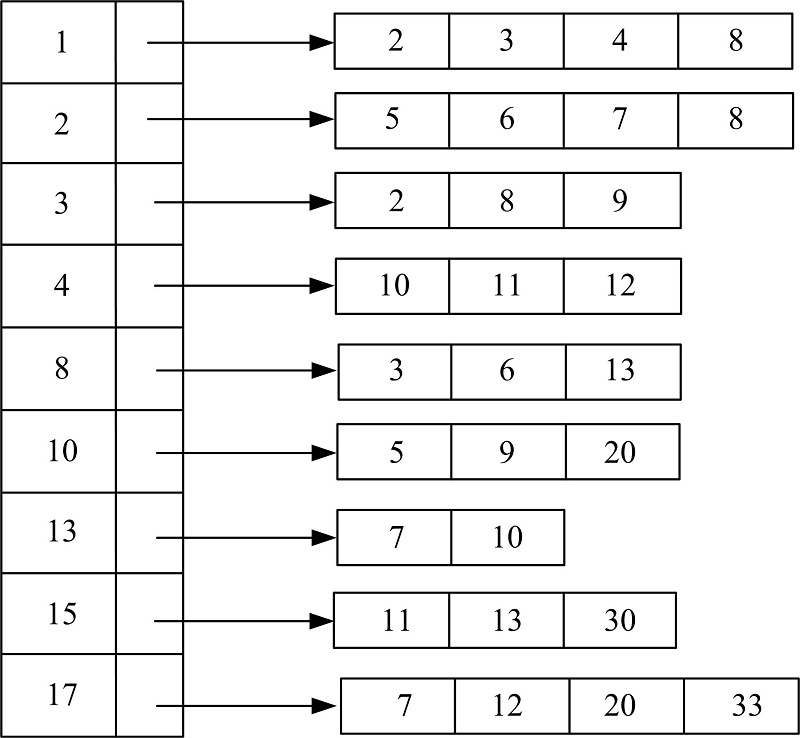 | 图3 LKeyword2对应的二级索引例子Fig.3 Example of secondary index with respect to LKeyword2 |
本节首先定义了路径查询, 然后给出一个基于辅助索引的路径查询算法。
定义1 路径查询形式如下:
例如, 搜索“ section/title/web” , 将返回路径section/title下面包含关键字“ web” 的资源视图; 其中, title是一个资源视图的名称组件, 则web就是这个资源视图内容组件中的关键字。查询“ member/name” , 表示搜索返回所有实验室成员的名字。member是一个资源视图的名称, name即为这个资源视图的属性。
在处理路径查询时, 其主要思想是:首先将其“
算法1 路径查询
输入:EIBH索引, 它由包含EIL、B-树索引和H索引组成; 用户查询Q=“ t1s1t2…sk-1tk” , k≥ 2。
输出:返回资源视图集合。
(1) set up a stack, split the string “ t1s1t2…sk-1tk” into “ t1t2…tk” and Push these keywords from right to left into the Stack.
(2) Stack pop two items key1 and key2.
(3)Perform a keyword search for key1 and key2 in index EIBH.
If exists, attain Bkey2 and Hkey1.
(4)join Bkey2 and Hkey1, and the result is a set of RSid that his parented exists in Bkey2,
construct a B-tree for the set, denote Btemp.
(5)While (Statck is't empty)
1)get the top item key of Stack;
2)Perform a keyword search for key. If exists, attain Hkey, Else, return null;
3)join Btemp and Hkey, and the result is a set of RSid that his parented exists in Btemp,
4)and use Btemp to represent the new B-tree that construct from the new set;
(6)the final Btemp includes all the resource view ids satisfying the user query
(7)Return all resource view ids in Btemp.
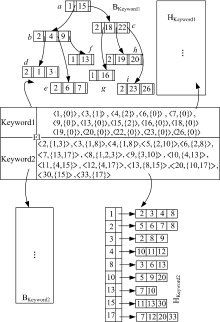
下面以表1中的例子来演示路径查询“ Keyword1/Keyword2” 的处理过程。图4给出了表1对应的数据空间索引EIBH例子。它共包含扩展倒排索引EIL、结合B-树索引和二级索引的混合辅助索引两大部分。
下面以表1中使用的例子来演示路径查询“ Keyword1/Keyword2” 的处理过程。图4给出了表1对应的数据空间索引EIBH例子。它共包含扩展倒排索引EIL、结合B-树索引和二级索引的混合辅助索引两大部分。
例如, 对于关键字Keywod1来说, 为其建立了BKeyword1索引和HKeyword1索引。由于空间限制, 后面讨论中不涉及HKeyword1索引, 因此, 没有给出HKeyword1索引的详细内容。同样, 没有给出BKeyword2的详细内容。
对于查询:Keyword1/Keyword2, 此查询的目的是查找资源视图组件名称为Keyword2且其父资源视图组件名称为Keyword1的资源视图, 或资源视图组件名称为Keyword1且其元组组件中包含属性Keyword2的资源视图。
下面分析如何使用辅助索引处理这个查询。
Step1 建立一个栈Stack, 用来存储关键字。
Step2 首先将路径查询Keywrod1/Keyword2进行分解, 得到关键字Keyword1和Keyword2, 将关键字Keyword2和Keyword1依次压入栈中; 注意, 路径表达式中关键字的进栈顺序是从右到左。
Step3 使用Stack的pop功能, 弹出栈顶的两个元素, 记为Keyword1和Keyword2。接下来搜索扩展倒排列表EI中的关键字列, 得到Keyword1对应的BKeyword1, Keyword2和对应的HKeyword2。
Step4 创建一个临时B-树, 记为Btemp。
Step5 连接HKeyword2和BKeyword1, 顺序读取HKeyword2中的每一个ID, 对于读取的每一个ID, 通过搜索BKeyword1判断是否存在, 如果存在, 则将与ID相对应的子资源视图数组中的资源视图ID插入到Btemp中; 这一步详细过程如下:
读取1, 搜索BKeyword1, 存在, 则将2, 3, 4, 8逐个插入到Btemp中;
读取2, 搜索BKeyword1, 不存在;
读取3, 搜索BKeyword1, 存在, 则将2, 8, 9逐个插入到Btemp中;
读取4, 搜索BKeyword1, 存在, 则将10, 11, 12逐个插入到Btemp中;
读取8, 搜索BKeyword1, 不存在;
读取10, 搜索BKeyword1, 不存在;
读取13, 搜索BKeyword1, 存在, 则将7, 10逐个插入到Btemp中;
读取15, 搜索BKeyword1, 存在, 则将11, 13, 30逐个插入到Btemp中;
读取17, 搜索BKeyword1, 不存在。
Step6 如果栈不为空, 弹出一个栈顶元素key, 搜索EI中的关键字列, 得到key对应的Hkey, 接着执行Step7; 如果栈为空, 跳转到Step9。
Step7 创建一颗Bnew的新B-树, 连接Hkey和Btemp, 顺序读取Hkey中的每一个ID, 对于读取的每一个ID, 通过搜索Btemp判断是否存在, 如果存在, 则将与ID相对应的子资源视图数组中的资源视图ID插入到Bnew中; H中的每一个ID都判断完后, 删除旧的Btemp, 将Bnew改为Btemp。
Step8 重复Step6。
Step9 遍历Btemp, 得到满足条件的资源视图编号(2, 3, 4, 8, 9, 10, 11, 12, 7, 13, 30), 输出每个资源视图编号对应的资源视图。
由于数据空间目前缺乏标准的数据集, 因此, 实验中使用的数据集主要是从个人电脑真实数据构建而来。这些数据以文件或文件夹的形式存在于文件系统中。抽取的主要文件类型包括Word文档、PDF文件、XML文件与Excel文件等。针对每一种类型的数据, 通过一个转换器来从数据源中抽取内容并转换为资源视图。抽取得到资源视图主要包括两种类型:一类是从文件或文件的元数据信息中抽取得到的资源视图, 称之为基资源视图; 另一类是从文件的存储内容中抽取得到的资源视图, 称之为派生资源视图, 在本次试验中, 只从Word、PDF、XML和Excel这4种类型的文件内容抽取派生资源视图。
表2为资源视图集合信息情况。从71 822个文件与426个文件夹中抽取得到72 248个基资源视图; 从3154个PDF档和1 425个Word文档中抽取得到218 326个派生资源视图; 从7176个XML文档得到91 875个派生资源视图; 从67个Excel文档抽取得到6573个派生资源视图。从表2可以看出, 派生资源视图占据了绝大多数。
| 表2 资源视图集 Table 2 Set of resource views |
对于构建好的索引, 本文通过产生一些不同深度的路径查询来测试响应时间。在本实验中, 最小路径长度为2, 最大路径长度为8。对于不同内容的考察, 产生不同深度的路径查询; 对于查询中的关键字和结构信息, 则随机地从资源视图集中抽取。对于每一个查询配置, 随机产生30个查询, 每一个执行5次。将其平均时间作为查询的最终执行时间。
本文采用的基准测试方法为NAIVE方法和EIL方法。这主要是因为它们都是基于iDM数据模型且它们都支持路径查询。从两个方面来评估本文提出的EIBH索引方法性能:①EIBH索引的构建效率及路径查询响应时间; ②与基准测试方法进行查询处理效率比较。
(1)EIBH索引效率评估
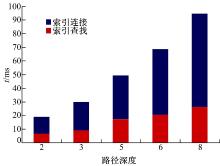
对于抽取的资源视图集, 构建EIBH索引的时间为14.1 min, 且索引大小为82.4 MB。图5为采用EIBH索引处理深度分别为2、3、5、6和8的路径查询的响应时间。
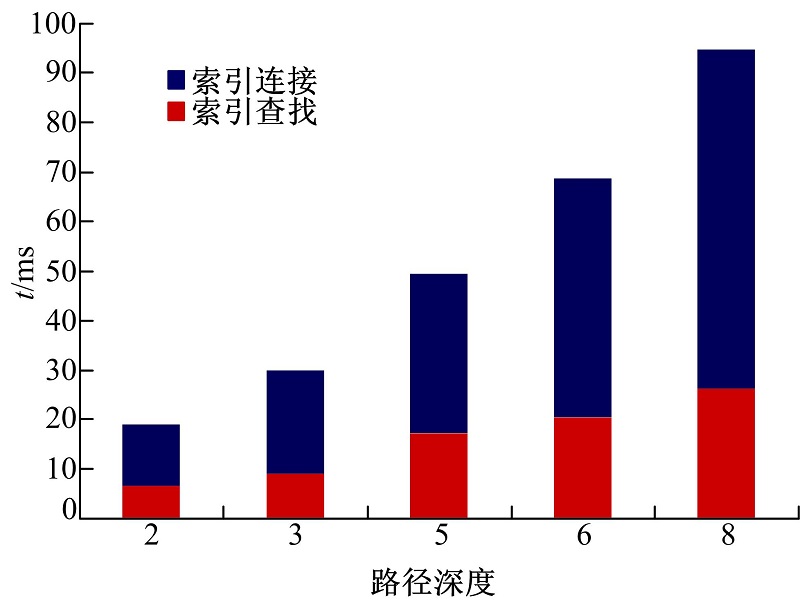 | 图5 EIBH索引下路径查询处理响应时间Fig.5 Path query response time for the EIBH index |
图5中的路径查询响应时间由索引查找时间和索引连接时间两部分构成。从图5中可以看出:①EIBH索引方法具有良好的查询处理效率。例如, 深度为2、3、5、6和8的查找和连接时间分别为6.7、9.2、17.3、20.5、26.2 ms和、12.3、20.9、32.3、48.2、68.6 ms; ②EIBH索引方法对不同深度的查询都具有良好的适应能力。例如, 随着路径深度的增加, 连接时间并没有呈现倍数级的增长趋势, 这说明通过二级索引, 可以避免大量的重复比较操作。
(2)不同索引方法的查询性能对比
图6为EIBH索引、EIL索引和NAIVE索引方法在处理不同深度的路径查询的查询响应时间。从图6中可以看出:深度为2的路径查询的处理时间分别为19.3、28.4和41.7 ms; 深度为5的路径查询的处理时间分别为38.4、60.2和70.8 ms; 深度为8的处理时间分别为52.7、75.3和90.6 ms。说明, 相比于EIL和NAIVE索引方法, EIBH索引方法可以从整体上减少不同深度的路径查询的响应时间。这是因为引入B-树和二级混合辅助索引方法极大地提高了路径查询中索引连接效率。
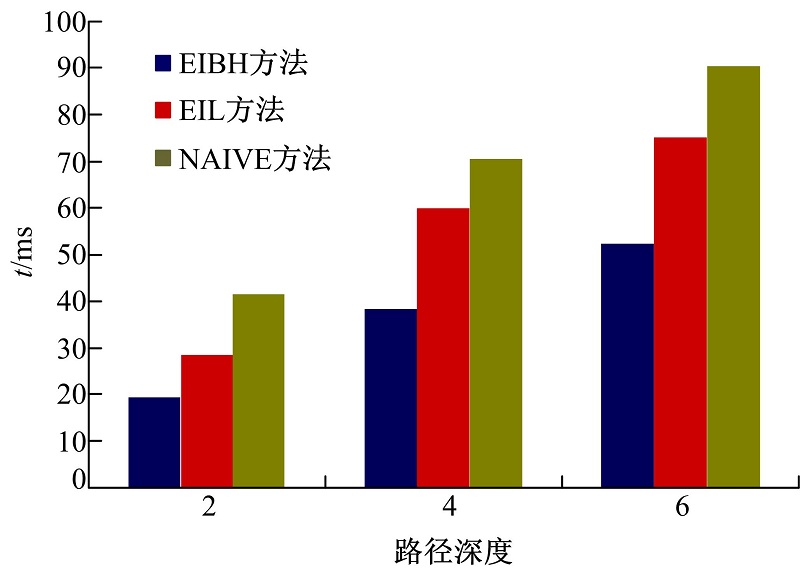 | 图6 EIBH、EIL、NAIVE下路径查询响应时间对比Fig.6 Comparision of path query response time for EIBH, EIL, NAIVE |
研究了基于辅助索引的数据空间索引方法, 以支持高效路径查询。针对索引连接存在的问题, 构建了结合B-树索引和二级索引的混合辅助索引。实验结果表明该方法是切实有效的, 且明显优于已有的方法。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|