{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于语音存在概率的噪声功率谱估计
[赵彦平 , 赵晓晖, 王波]
, 赵晓晖, 王波]
, 赵晓晖, 王波]
|
|


作者简介:赵彦平(1978-),女,讲师,博士研究生.研究方向:语音信号处理.E-mail:zhaoyp@jlu.edu.cn
在幅度平方谱模型下,利用语音和噪声信号的幅度平方谱服从指数分布,结合由后验信噪比不确定性决定的后验语音存在概率来更新噪声功率谱估计,很好地抑制了噪声且避免了语音信号失真。仿真实验结果表明:本文方法能够准确跟踪噪声功率谱、快速跟踪噪声功率谱变化,可以在一定程度上提高增强后语音信号的质量。
Using the magnitude-square spectrum model and the exponential probability densities of the magnitude-square spectrum of the clean speech and noise. The new method updates the noise power spectrum estimation using the posteriori speech presence probability by incorporating a posteriori signal to noise ratio uncertainty. It can suppress effectively the background noise without introducing speech distortion. The simulation results reveal that the new method is characterized by tracking noise power spectrum accurately and following quickly abrupt changes in the noise spectrum. The quality of enhanced speech signal is improved in a certain extent.following quickly abrupt changes in the noise spectrum. The quality of the enhanced speech signal is improved in a certain extent.
大多数语音增强方法都要对噪声进行估计[1, 2], 这意味着噪声估计的准确程度决定着语音增强系统的性能。噪声估计过高会导致信号失真; 噪声估计过低会产生音乐噪声。传统方法常利用带噪语音信号起始段没有语音的部分或根据语音活动性检测(Voice activity detectors, VAD)结果确定的噪声部分进行噪声功率谱估计, 但这种方法只适用于平稳噪声。对于非平稳噪声, 该方法不能跟踪噪声功率谱的快速变化, 导致语音增强系统性能降低。
文献[3]提出了一种基于最优滤波和最小统计的噪声功率谱估计(Minimum statistics, MS)。文献[4]提出了最小控制递归平均(Minima controlled recursive averaging, MCRA)方法。文献[5]提出了改进的最小控制递归平均(Improved minima controlled recursive averaging, IMCRA)方法。上述三种方法[3, 4, 5]虽然都能对非平稳噪声进行估计, 但它们对噪声功率谱的突然变化不能做出迅速的反应, 跟踪噪声变化都有一定的延迟时间。文献[6]提出了一种低复杂度、低时延的无偏噪声功率谱估计方法。该方法用语音存在概率代替VAD, 无需偏差补偿。与传统的基于最小均方误差的噪声功率谱估计方法相比, 该方法减少了噪声功率谱的过估计。但是该方法假设语音信号不存在和存在的先验概率都为固定值0.5, 使得这两个概率的比值对计算后验概率没有贡献。
针对这一问题, 本文利用结合后验信噪比不确定的后验语音存在概率来更新噪声功率谱的估计。利用该方法得到的噪声功率谱估计的最大值与利用文献[6]方法得到的最大值接近, 但提高了低估计值, 所以既很好地估计了噪声又避免了过高估计导致的信号失真。同时该方法能快速跟踪噪声功率谱的变化, 对平稳噪声和非平稳噪声都具有良好的估计效果。
用大写字母表示随机变量, 对应的小写字母表示时域观测值, 带尖号(“ ^” )的字母表示估计值, 如:
假设语音信号和噪声信号是零均值且相互独立的, 有:
式中:
语音和噪声的功率谱分别定义为
基于最小均方误差(Minimum mean-square error, MMSE)的噪声功率谱估计方法假设语音和噪声的谱系数均服从复高斯分布:
在语音存在概率不确定条件下, 噪声功率谱的MMSE估计为[6]:
式中:
基于语音、噪声谱系数服从复高斯分布的假设和贝叶斯理论, 得到后验语音存在概率为:
式中:似然函数
式中:
将式(7)(8)代入式(6)得到后验语音存在概率为:
由式(9)得到后验信噪比估计
而且很容易满足
在语音不存在的条件下有:
将式(11)(12)代人式(5), 得:
式中:
最终噪声功率谱估计为:
式中:
带噪语音信号的功率谱可表示为[1]:
式中:
虽然式(15)具有统计意义, 但为简化噪声抑制方法, 可以用幅度平方谱近似表示功率谱, 有:
与基于MMSE的噪声功率谱估计方法假设一致, 本文仍然假设纯净语音和噪声的谱系数服从复高斯分布, 所以纯净语音幅度平方谱
利用贝叶斯理论得到纯净语音幅度平方谱的后验概率密度为:
式中: x2∈[0,|y|2];Φ的定义为:
而且:
利用文献[11]的方法求后验语音存在概率
与基于MMSE的噪声功率谱估计方法一样, 用
式中:
假设的概率计算公式为:
将式(19)代入式(24)得:
式中:
在幅度平方谱的模型下, 式(13)可表示为:
式中:
最终得到新的噪声功率谱估计为:
式中:
文献[6]方法与本文方法的不同主要在于计算后验语音存在概率方法的不同。式(9)中, 先验概率
实际上, 当
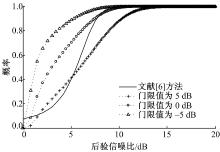
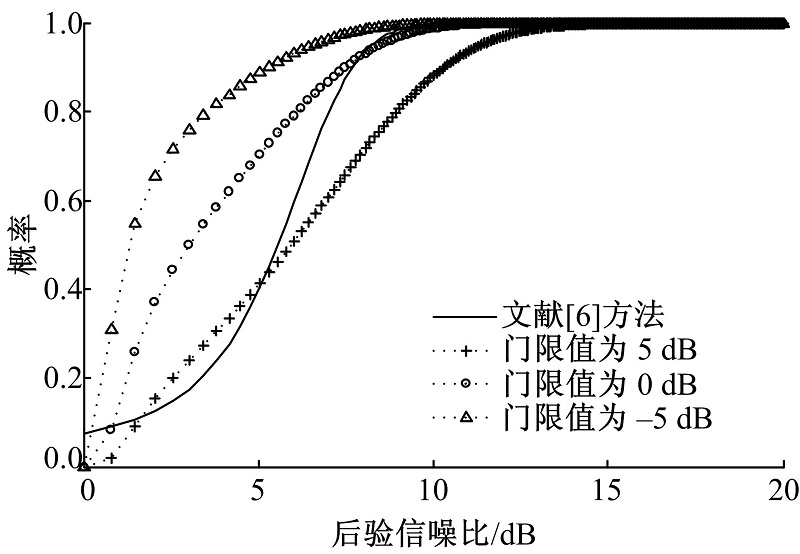 | 图1 语音存在概率对比Fig.1 Comparison of speech presence probability |
同样当语音存在时, 先验信噪比可用最大似然估计得到。式(25)中, 有
为了验证本文方法的性能, 对本文方法和文献[4]提出的MCRA方法、文献[6]提出的固定先验概率噪声功率谱估计方法进行了对比。文献[6]方法中为避免由于噪声功率谱估计过低引起的后验语音存在概率估计更新的停滞, 采用下面的方法进行处理。首先对
然后通过
本文方法也应用了此方法对后验语音存在概率进行了处理。实验中取
仿真实验中纯净语音来自TIMIT语音库[7], 噪声来自Noisex92噪声库[8], 噪声采样频率转换为16 kHz, 实验中帧长为512点, 50%帧重叠, 加汉宁窗。
为了对比不同方法对噪声功率谱的估计能力, 随机在语音库中选取一段语音, 分别加入白噪声和Babble噪声, 信噪比均为5 dB,
仿真结果如图2~图4所示。
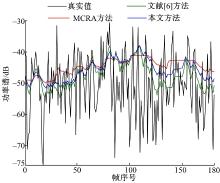
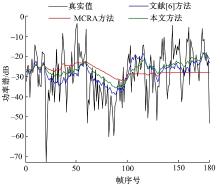
图2为白噪声背景下, 信噪比为5 dB, 频率为312 Hz时三种方法的估计结果对比图。从图2可以看出, 三种方法对白噪声都有很好的跟踪能力。噪声功率谱较大时, 三种方法估计效果近似; 噪声功率谱较小时, 本文方法估计效果介于MCRA方法和文献[6]方法之间。图3是Babble噪声背景下, 信噪比为5 dB, 频率为312 Hz时三种方法的估计结果对比图。从图3可以看出, 对于非平稳噪声, 功率谱波动较大, 本文方法和文献[6]方法都能很好地跟踪噪声变化, 而MCRA方法估计能力较差, 曲线较平坦。
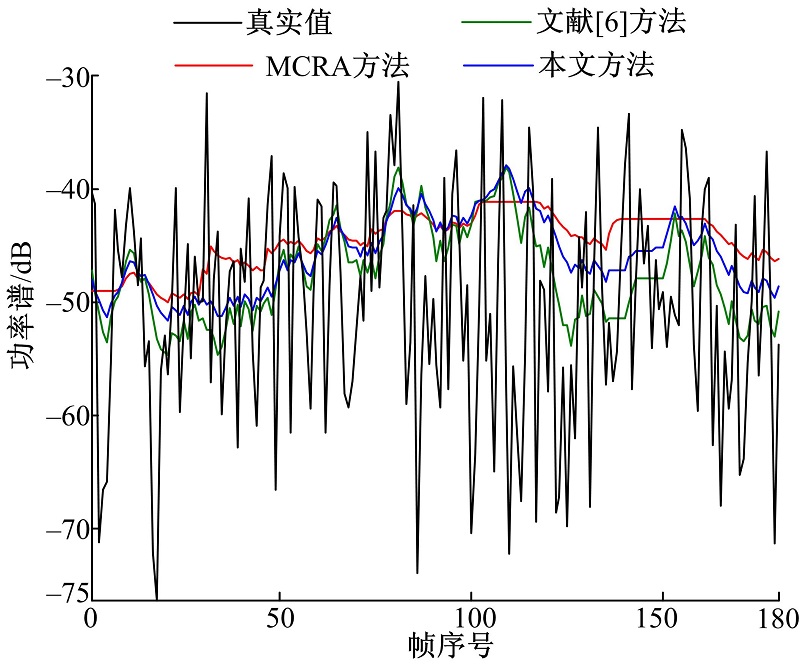 | 图2 白噪声功率谱估计对比Fig.2 Comparison of the estimation of the noise power spectrum for white noise |
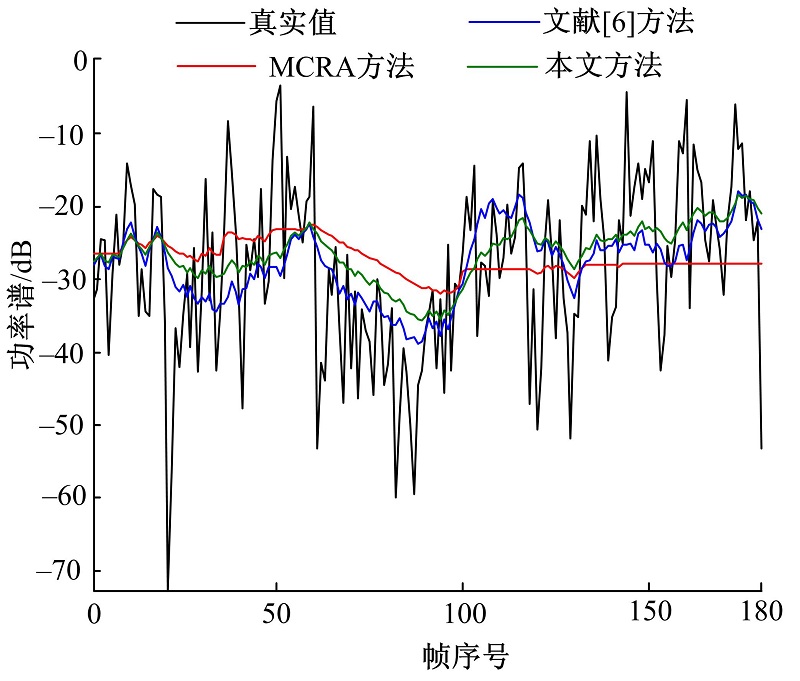 | 图3 Babble噪声功率谱估计对比Fig.3 Comparison of the estimation of the noise power spectrum for babble noise |
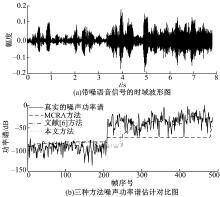
图4为不同噪声组合背景下, 三种噪声功率谱估计方法性能对比。图4(a)中前3.3 s加入Volvo汽车噪声, 信噪比为5 dB; 后4.4 s加入Babble噪声, 信噪比为0 dB, 频率都为1 kHz。图4(b)为三种方法噪声功率谱估计对比图。从图4(b)中可以看出, 对于Volvo汽车噪声, 三种方法都能较准确地估计噪声的功率谱, 而对于Babble噪声, MCRA方法随噪声功率谱变化能力较差, 本文方法和文献[6]方法能较快地跟踪噪声的变化, 而且本文方法跟踪能力较好一些。
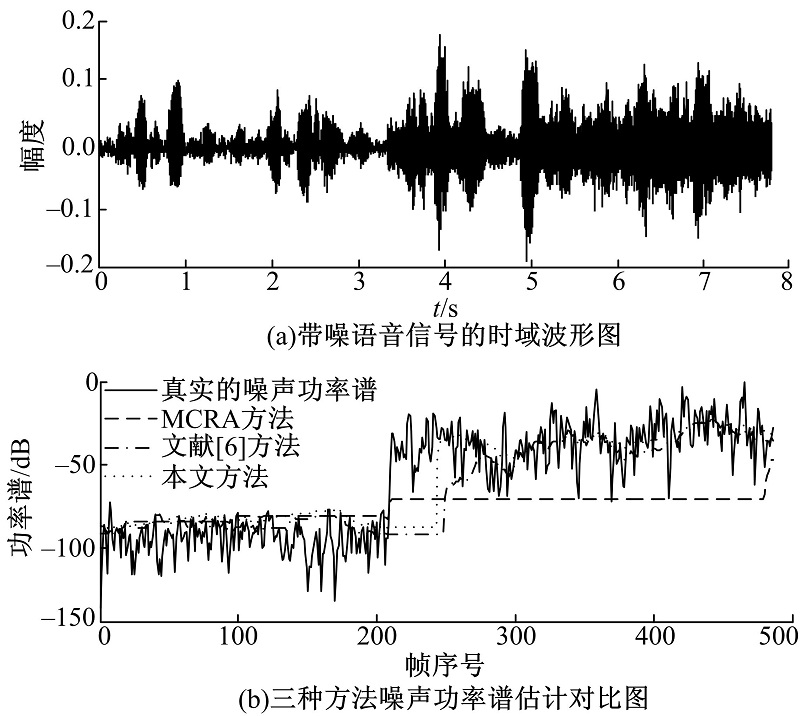 | 图4 不同噪声功率谱估计对比Fig.4 Comparison of estimation of the different noise power spectrum |
噪声功率谱估计方法可以与大多数语音增强方法相结合来提高语音增强系统的性能。本文从TIMIT语音库中随机选取200个句子, 分别加白噪声、Babble噪声、Volvo汽车噪声和F16机舱噪声, 在0、5、10和15 dB信噪比条件下进行测试。语音增强方法采用的是文献[1]中的MMSE-SPZC方法。利用语音质量客观评价方法中对数似然比(Log likelihood ratio, LLR)、分段信噪比(Segmental SNR, SegSNR)、加权谱包络(Weighted spectral slope, WSS)和语音质量感知评价(Perceptual evaluation of speech quality, PESQ)4个参数对方法的估计效果进行评价[10]。这4个参数从不同角度衡量增强后语音的质量, LLR和WSS值越小表示系统性能越好; 而SegSNR和PESQ值越大表示系统性能越好, 实验结果如表1~表4所示。
| 表1 LLR对比 Table 1 Comparison of the LLR |
| 表2 SegSNR对比 Table 2 Comparison of the SegSNR |
从表1可以看出, 对于LLR, 在白噪声和Volvo汽车噪声背景下, 无论何种信噪比, 本文方法都能取得较好的估计效果。对于Babble噪声和F16机舱噪声, 文献[6]方法优于本文方法。表2对比了SegSNR, 在白噪声和F16机舱噪声背景下, 本文方法优势明显; 在Babble噪声背景下, 本文方法在低信噪比时性能较好。从表3可以看出, 对于WSS, 本文方法在白噪声、Volvo汽车噪声和F16机舱噪声背景下估计性能较优; 在Babble噪声背景下, 低信噪比时估计效果较好。表4对比了PESQ, 可以看出在白噪声、Babble噪声和F16机舱噪声背景下, 本文方法估计性能较好; 在Volvo汽车噪声条件下, 文献[6]方法略好于本文方法。综合来看, 与其他算法相比, 本文方法在大多数噪声条件下都能取得较好的估计性能, 提高了增强后语音信号的质量。
| 表3 WSS对比 Table 3 Comparison of the WSS |
| 表4 PESQ对比 Table 4 Comparison of the PESQ |
基于幅度平方谱语音模型, 提出了一种基于后验信噪比不确定的后验语音存在概率的噪声功率谱估计方法。该方法对平稳的白噪声具有较好的估计性能, 对非平稳的Babble噪声也有较好的跟踪能力, 并且能对噪声的突然变化做出快速反应。语音增强实验验证了低信噪比时, 本文方法可以在一定程度上提高增强后语音信号的质量; 高信噪比时本文方法性能与文献[6]方法近似。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|