{kind=link}
{kind=link}
基于层次过滤模型的中文指代消解
[周炫余1 , 刘娟1  , 邵鹏
, 邵鹏1, 2 , 罗飞1 , 刘洋1 ]
, 邵鹏|
|


作者简介:周炫余(1987-),男,博士研究生.研究方向:指代消解,自然语言处理.E-mail:zhouxuanyu@whu.edu.cn
针对现有的中文指代消解研究大多采用二元分类模型,容易出现消解正确率低的特征覆盖消解正确率高的特征以致模型指代划分错误的问题,提出了一种改进的层次过滤模型用于中文指代消解。该模型结合中文语义知识,在原模型中加入语义匹配层,该层通过引入Web语义知识很好地弥补了中文语义知识库较小的不足,并针对中文的特点对原模型的待消解项识别层进行相应的修改使之更加适合中文指代消解。将上述模型与两类基准系统在ACE2005中文语料上进行5种测评,结果表明,所提出模型的F平均值分别高于两类基准系统约4%和9%。
Most existing Chinese anaphora resolution models determine whether two mentions are coreferent by a binary classifier. This approach can lead to incorrect decisions as lower precision features often overwhelm the precision features. We propose a modified multi-pass sieve model for Chinese anaphora resolution to adapt to Chinese. We add a new semantic-based sieve to the original model for incorporating word sense information. The Web word sense information is imported to solve resource constraints. Furthermore, we modify the mention detection sieve based on the Chinese characters. The proposed model is evaluated on five different testing methods on the ACE2005 corpus. Results show that the proposed model outperforms two other baseline models by 4% and 9% respectively.
指代是自然语言中的一种重要的表达方式, 它使得语言表达简洁连贯, 然而在篇章中大量地使用指代增加了计算机对篇章理解的难度。通常每个篇章存在多个实体(Entity), 而每个实体又存在多个不同的实体表达(Mention), 这样使得篇章变得简洁和通顺。指代关系中, 具体的语言学单元称为先行语, 抽象的语言学单元称为照应语。指代消解的基本任务就是把上述先行语和照应语关联起来的过程。指代消解是自然语言理解的主要基础之一, 同时也是其他自然语言处理技术的关键子任务, 例如:机器翻译[1]、信息抽取[1]、自动文摘[3]等。
与英文指代消解研究相比, 由于中文分词、命名体识别、句法分析等基础自然语言处理技术不完备, 缺少相关语言学知识支持以及缺少足够多的标注语料, 导致中文指代消解研究发展较为缓慢。现有的中文指代消解模型大多借鉴Soon的思想[4], 即在有限的标注语料上训练出二元分类模型用于判断照应语与先行语之间是否存在指代关系, 最后通过聚类算法把存在指代关系的待消解项聚成一条链。尽管该类模型十分经典, 但由于中文标注语料数量的限制, 实体表达对模型存在泛化能力不足, 导致难以适应不同类型的文本消解。另外单个模型的指代消解系统容易出现低正确率的特征覆盖高正确率的特征以致模型的指代划分错误, 例如:{克斯米尔穆斯林分离武装、他们、一个克什米尔穆斯林分离武装主义组织}在上述实体表达集合中, 实体表达对模型很有可能因为单复数特征把“ 克斯米尔穆斯林分离武装” 和“ 他们” 聚成一条指代链。
Raghunathan等[5]首次引入多层过滤的思想应用于英文指代消解中。该模型是按照消解正确率从高到低排列的组合框架, 因此不需训练语料且保证了强特征优先于弱特征, 不会造成弱特征覆盖强特征的现象。Lee等[6]扩展了上述模型, 主要增加了语义层、待消解项识别层、后处理层。然而Lee的语义层主要是通过WordNet、Wikipedia infoboxes、Freebase records获取语义知识。由于中文的复杂性, 各类中文语义学知识库相对于英文来说发展比较缓慢。HowNet、同义词林的规模远不能满足待消解项之间语义相似度的计算。因此Zhang等[7]基于上述原因在Lee的基础上去除了语义分析层并针对中文的词法的特点对Lee等[6]提出的模型进行部分修改, 使之适应于中文指代消解。然而一条指代链中的实体表达都指向同一实体, 语义相似度很高, 因此引入语义知识显得尤为重要。Zhang等[7]在修改的待消解项识别层中, 只是简单地通过词性标注和命名体识别抽取待消解项, 然而ACE2005中文语料中存在着一定数量的嵌套名词短语, 上述方法很难准确识别所有的待消解项, 从而导致指代消解模型精度降低。
因此本文在Zhang等[7]提出的模型基础上对待消解项识别层进行部分修改, 并加入语义匹配层。通过上述的改进使得待消解项识别层更好地识别中文嵌套名词短语, 且在语义匹配层中引入Web语义知识, 很好地弥补了中文语义知识库较小的不足。上述模型采用五种测评方式和两类基准系统在ACE2005中文语料上进行同平台、同语料的测评, 测评结果表明, 所改进的指代消解模型的效果要优于两类基准系统。
本文给出的中文指代消解模型的主要思想是根据中文各类文法知识设定一系列的消解规则层, 按照每层规则的消解精度从高到低进行排序, 每一层的输入以上一层输出的实体聚类体为基础, 结合共享属性得到最终的指代链。该模型的系统框架主要包含4大模块:①预处理模块; ②待消解项模块; ③指代消解模块; ④测评模块。整个系统的框架如图1所示。图中加粗的层次是本文在原模型上进行相应修改的部分。
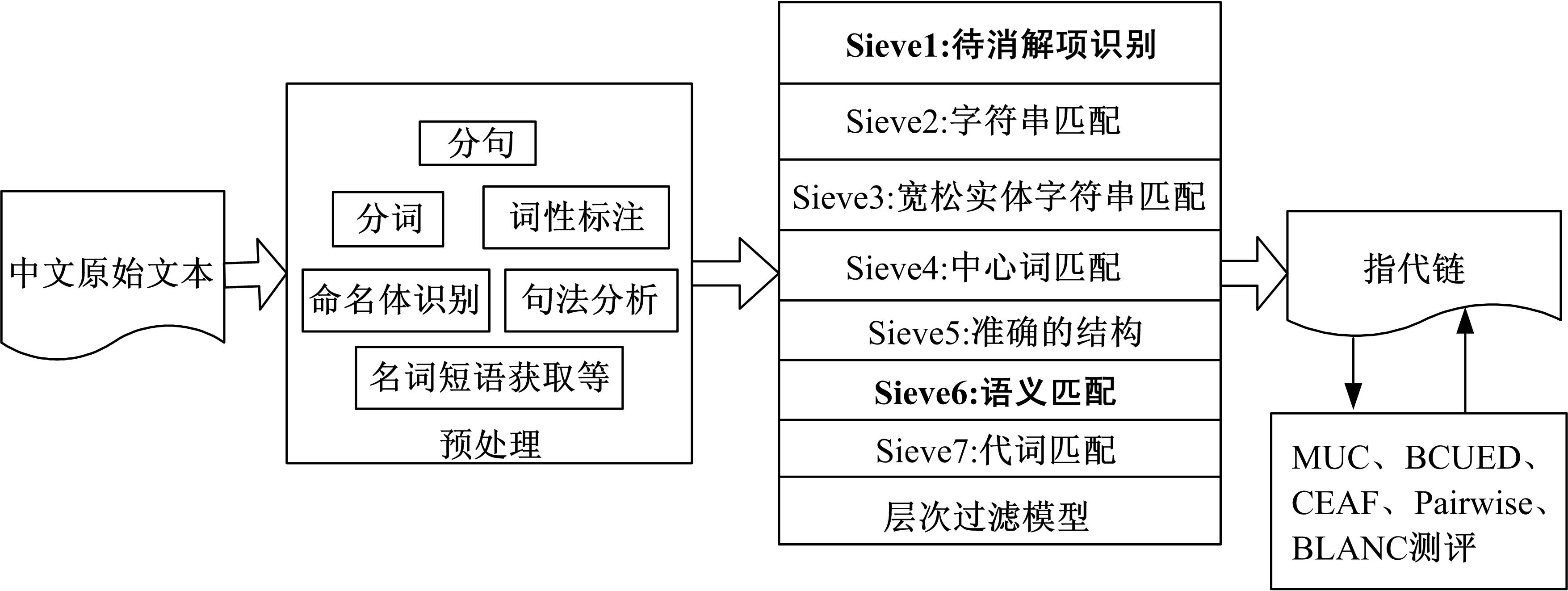 | 图1 基于层次过滤模型的中文指代消解框架图Fig.1 The architecture of multi-mass sieve model for Chinese anaphora resolution |
预处理模块主要包括分句、分词、词性标注、命名实体识别、句法分析以及名词短语的抽取。预处理的好坏直接影响到后面待消解项识别、特征抽取以及指代消解模型的精度。中文自然语言处理与英文自然语言处理的最大区别就是中文需要分词, 然而中文分词一直是一个悬而未决的问题。分词的不准确将导致后续处理出现错误累积, 因此为了测试模型的消解能力将待消解项分为自动生成的实体表达(AutoMention)以及标准的实体表达(GoldMention)两种。在AutoMention中采用的分词工具(http:∥nlp.stanford.edu/software/segmenter.shtm)、词性标注工具(http://nlp.stanford.edu/software/tagger.shtml)、命名体识别工具(http:∥nlp.stanford.edu/software/CRF-NER.shtml)和句法分析树工具(http:∥nlp.stanford.edu/software/lex-parser.shtml)均由斯坦福大学自然语言处理小组所提供, GoldMention为直接从标注语料中读取待消解项。分词后, 分别对分好词的文本进行词性标注以及命名实体识别。在分词结果的基础上, 采用斯坦福大学提供的句法分析树工具进行句法分析, 并根据相应的语言学规则抽取出候选待消解项。
孔芳等[8]详细地分析了中文待消解项识别模块的作用, 并指出待消解项识别层的准确率的高低很大程度上影响着中文指代消解的精度。本文在测评中也发现, 丢失待消解项比错分指代链更影响测评结果。基于上述结论, 在指代消解模块前增加待消解项识别层, 该层主要分为扩充阶段和过滤阶段两大步骤, 如图2所示。
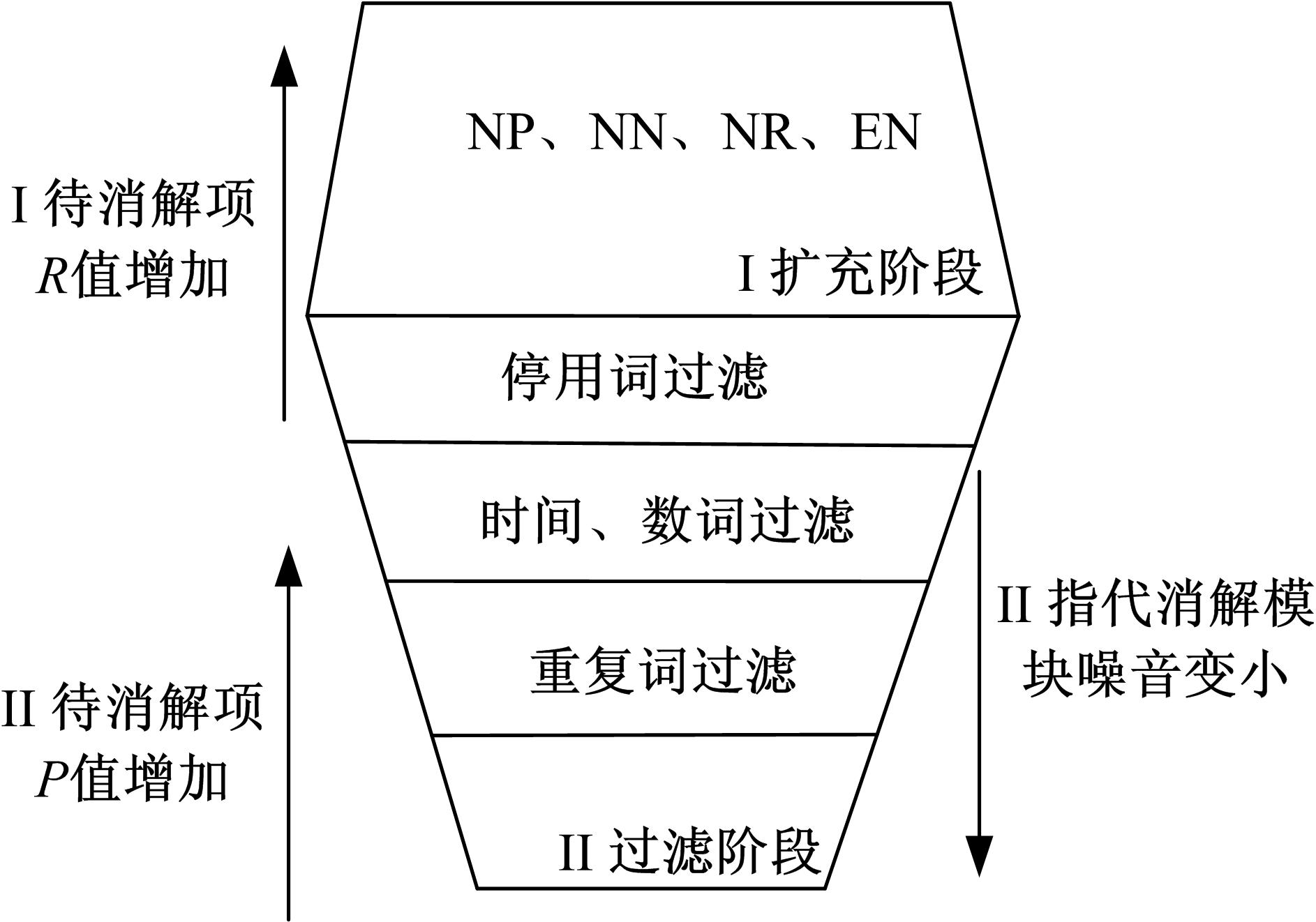 | 图2 待消解项识别层流程图Fig.2 The flowchart of mention detection sieve |
(1)扩充阶段:由于指代消解主要的消解对象是代词、名词短语、嵌套名词短语。因此简单地通过词性标注以及命名体识别很难准确地抽取出所有的待消解项。该阶段通过斯坦福句法分析树对句子进行句法分析, 并选取文本中所有的命名实体以及抽取句法分析树中所有的NP、NN、NR节点作为候选待消解项。当名词的词性标注为EN时, 也将其作为候选先行语, 并通过机器翻译系统(http:∥fanyi.baidu.com/auto/zh/)将其翻译成对应的中文名词短语。
(2)过滤阶段:该阶段主要是在保证召回率不大幅下降的同时尽量使待消解项识别模块的正确率提高。因此主要通过以下几层过滤得到待消解项集合:①停用词过滤。由于扩充阶段抽取的名词短语中包含大量的无意义的抽象名词, 例如:精神、行为、科技、原因、风雨、歪理邪说、校园安全等。这些名词或者名词短语在文本中没有指向任何实体, 因此首先通过设置的一个停用词表删除上述抽象的名词或者名词短语; ②时间、数词、金钱过滤。删除包含百分号、数词、时间的名词或者名词短语, 例如:“ 20%、1000公里、明天、昨天晚上、30万元等” ; ③重复词过滤。如果两个名词或者名词短语之间存在着相同的中心词, 且二者在前文中出现过则二者保留, 否则删除字符串较短的名词或者名词短语。
基于改进的层次过滤的中文指代消解模型一共有6层, 如表1所示。以下将主要介绍各个层次过滤模块。
| 表1 中文指代消解模型中的层次顺序 Table 1 Sequence of sieves for Chinese anaphora resolution |
(1)字符串匹配层(String match sieve):篇章中, 当实体表达字符串完全相同时被认为是描述同一实体。因此当照应语mj与先行语mk的字符串完全匹配, 则判断二者可以聚成一条指代链。
例如:“ 布什总统” 与“ 布什总统” , 这两个字符串是完全匹配, 则认为二者存在指代关系。从最终的测评结果可知, MentionWise测评以及BLANC测评的准确率可以达到90.7%和90.3%。
(2)宽松字符串匹配层(Relaxed string match):如果照应语mj与先行语mk之间满足以下关系时可以聚成一条指代链。
实体表达宽松字符串匹配:当照应语
宽松字符串匹配:当照应语
(3)中心词匹配(Head match sieve):如果照应语
严格中心词匹配:当照应语
宽松中心词匹配:当照应语
(4)准确的结构匹配(Precise constructs sieve):当照应语
同位语:当照应语
缩略语:当照应语
(5)语义匹配层(Semantic match sieves):语义匹配层是通过语义相似度来描述先行语与照应语之间是否存在指代关系。本层通过中文本地语义知识库HowNet以及Web语义知识两个方面来衡量照应语与先行语之间的语义相似性。当照应语
基于HowNet语义相似度计算:通过刘群等[9]提出的基于Hownet词义相似度计算方法来计算两个名词短语之间的相似性, 具体公式如式(1)所示:
基于Hownet的语义相似度的计算归根到底是计算两个词的概念相似度。而在知网中通过计算两个词的义元相似度来衡量两个概念的相似度。对于两个词语x和y,其相似度记为Sim(x,y)其中d为x和y的义元在义元其中d为x和y的义元在义元层次体系中的距离。其中α表示相似度为0.5的义元距离,该参数是一个可调节的参数。当Sim(x,y)值大于阈值0.5时可以聚成一条指代链, 例如:中国和中华人民共和国之间的相似度为1.0。
基于Web语义相似度计算:由于HowNet语义知识库的大小存在一定的局限性, 因此通过引入Web语义知识来解决上述问题。Web语义知识通过搜索引擎索引待消解项, 通过索引出的网页信息来计算待消解项之间的语义相似度[10], 具体公式如式(2)所示:
式中:
(6)代词层(Pronouns Sieves):前面几个层次主要关注的是名词或者名词短语消解, 本层主要从以下几个方面考虑代词消解。当代词和名词短语聚类体满足下述关系时, 则二者聚成一条指代链。
单复数一致:单复数属性分为单数和复数两种类型。名词短语中含有“ 们、一大群、许多、每个” 等词, 或者表示并列关系的名词短语归入复数类别, 其余的归入单数类别。
性别一致:性别属性分为男性、女性以及中性三种类型。该类属性通过以下规则判断性别属性。若名词前后存在性别指示词时, 则通过该类词判断名词性别, 例如:先生、女士、阁下、同志等。若存在代词信息时, 则通过该类信息判断性别, 例如:他、她、它等。若名词为人名时, 通过收集的中文人名性别列表, 统计出人名最后一个字为何种性别的概率值, 并以此判断人名性别。
生命度:根据待消解项是否属性有生命, 把待消解项分成了有生命的和无生命两大类。
NER标签:根据斯坦福NER标注, 把实体表达分为组织、地点、人名、杂项4大类型。
实验采用的测评数据为ACE2005中文语料, 该语料包含三个子语料, 分别是BNEWS(网络对话)、NWIRE(新闻广播)、Weblogs(博客)。表2为ACE2005中文语料统计表格, 在BNEWS、NWIRE、Weblogs子语料中分别随机抽取80篇、80篇、40篇作为模型测评语料。
| 表2 ACE2005中文语料统计表 Table 2 Statistical table of ACE2005 Chinese corpus |
将Zhang等[7]提出的中文层次过滤模型以及Soon等[4]提出的实体表达对模型作为实验对比的基准系统。
(1)中文层次过滤模型。文献[7]将该系统分为待消解项层、篇章处理层、准确字符串层、宽松字符串层、准确的结构层、中心词匹配层、合适的中心词匹配层、代词层。
(2)实体表达对模型。该模型的主要思想是把每个照应语
式中: Pc (COREF|
在ACE2005三个子语料中随机抽取200篇作为测试语料。中文原始文本经过预处理后, 待消解项识别层的测评结果如表3所示。其中P(Precision)值代表正确率, 它反映的是指代消解模型的准确程度; R(Recall)值代表召回率, 它反映的是指代消解模型的完备性; F值反映了指代消解模型的准确度和完备性的综合评估值。ACE2005语料中存在一定数量的嵌套名词短语, 例如:“ 负责策划这次艺术节活动的台北市文化局” 、“ 南京西路建成圆环” 等。本文在句法分析树上抽取待消解项, 而不是简单地基于词性标注以及命名体识别抽取待消解项。测评结果表明, 本文所提出的待消解项识别层在ACE2005三种语料上F平均值达到79.6%, 要高于Zhang所提出的待消解项层约7%, 如表3所示。
| 表3 待消解项识别层性能表 Table 3 The results of mention detection sieve |
指代消解阶段的测评结果采用5种国际上最常使用的测评方式进行, 分别为MUC[11]、BCUBED[12]、CEAFE[13]、MentionWise[14]、BLANC[15]。根据上述5种测评方法得出F值的平均值来比较模型的优劣, 即表4和表5中的Avg_F值。该值为模型在5种不同角度测评的平均值, 体现了模型的总体性能。Base1、Base2分别表示Zhang所提出的中文层次过滤模型以及Soon提出的实体表达对模型; our表示改进的层次过滤模型。具体实验结果如表4所示。
| 表4 模型与baseline系统的对比实验结果(%) Table 4 Comparison of our model with the baseline models |
| 表5 模型中各层叠加的测评结果(%) Table 5 Results of sieves accumulation in the model |
从表4可知, 在没有预处理叠加错误的影响下, 基于改进的层次过滤模型和两类基准系统的Avg_F值能分别达到77.1%、72.6%和67.8%。通过自动化处理获取待消解项以及属性信息, 基于改进的层次过滤模型和两类基准系统的Avg_F值分别只有65.1%、61.1%和56.9%。AutoMention和Golden-Mention之间的F平均值存在11%的差距。产生这种差距的原因主要有以下几个方面:①各种基础的中文自然语言处理技术不成熟, 例如:在分词中把实体表达“ 文化局局长” 和“ 龙映台” 分成了“ 文化局/n 长龙/n 映/v 台/q” 。这样的错误在分词过程中比比皆是, 严重影响后续的处理。由于中文的歧义较多, 在词性标注以及命名实体识别时也存在多种不同的错误。经过一系列的基础处理以后, 错误不断叠加扩大, 以至于待消解项识别不准确以及特征抽取出现错误, 最终导致指代消解模型的错误划分。②中心词的选择, 根据中文语言学规则选取名词短语的最后一个名词作为中心词, 这样大部分是对的, 但是在ACE2005语料中也存在大约8%的待消解项的中心词不是最后一个词。③候选待消解项抽取的方法是在句法分析树上抽取出所有包含NP、NN、NR节点作为候选待消解项。这样做虽然最大程度地提高了召回率, 但是也引入大量的非待消解项, 尤其是存在大量重复中心词的名词短语。上述重复性短语给后续的待消解项过滤阶段带来很大的噪音, 进而影响后续的指代消解模型的精度。④在Weblogs语料中存在一定数量的英文的待消解项, 上述待消解项存在词与词之间没有空格导致机器无法正确翻译该词语, 例如:“ councilonfinancialservices” 。另外, 引入的机器翻译系统也存在一定程度的错误翻译, 例如:“ Inter” 被机器翻译系统翻译成“ 国际米兰” 。
为了进行有效的比较, 将Zhang所提出的中文层次过滤模型以及基于SVM实现Soon提出的实体表达对模型做为基准系统。为了保证系统之间的公平比较, 三种系统消解的待消解项完全一致。从表4可以清晰看出, 所提出的系统无论在AutoMention还是在GoldenMention上Avg_F值要分别高于Zhang提出的中文层次过滤模型和Soon提出的实体表达对模型约4%和9%。
为了探讨各层在指代消解模型中的作用, 采用逐层叠加的模式进行分析和探讨各层对模型的贡献, 如表5所示。从表5可以清晰看出, 模型中的各个层次在测评中作用均比较明显。从表4和表5可以得出, 修改的待消解项识别层以及新增加的语义匹配层使得模型的Avg_F值分别增高了4%、0.8%。Web语义知识在一定程度上提高了模型的指代消解精度且很好地弥补了中文语义知识库不全面的缺陷。
提出了一种改进的层次过滤模型用于中文指代消解。该模型修改了待消解项识别层使之适合抽取ACE2005中文语料中所有的待消解项。同时, 在该模型中增加了一个语义匹配层, 该层为了弥补中文语义知识库不全面的缺陷, 在本地语义知识库的基础上引入了Web语义知识。通过5种测评方法对各个过滤层次的贡献度进行了叠加式的测评。测评结果表明, 所修改和增加的层次对模型都有一定的贡献。同时, 通过与两类基准系统进行比较和测评, 表明所改进的层次过滤模型的消解效果要优于两类基准系统。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|