



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
支持大规模流数据处理的弹性在线MapReduce模型及拓扑协议
[魏晓辉1, 2  , 李翔
, 李翔1 , 李洪亮1, 2 , 李聪1 , 庄园1 , 于洪梅1 ]
, 李翔, 李聪|
|


作者简介:魏晓辉(1972-),男,教授,博士生导师.研究方向:分布式计算,集群计算和网络安全.E-mail:weixh@jlu.edu.cn
针对现阶段大规模流数据在线处理的广泛需求,本文提出了弹性在线MapReduce流数据处理模型及相关的动态拓扑结构协议。该模型兼容现有MapReduce模型,采用内存计算模式,并具有动态的作业拓扑结构,支持大规模流数据处理作业在运行过程中的弹性调整,从而满足流数据的时效性、动态性和突发性等特殊要求。在弹性在线MapReduce模型的基础上建立了流数据处理作业动态拓扑结构管理机制,设计了作业在线初始化协议和在线调整协议。为进一步提高系统灵活性和整合资源,提出了作业间的操作共享概念,设计了作业共享协议。通过协议分析,本文提出的在线初始化协议、在线动态调整协议及作业共享协议的最大复杂度均为 O( n);在数据流量发生突发性变化时,系统具有良好的可伸缩性。
To meet the rapid growing requirements of large-scale data online processing, this paper proposes a Flexible Online MapReduce model and related dynamic topology protocols for streaming data processing. This model is compatible with existing MapReduce application, adopts in-memory computing, and possesses a dynamic job topology. It can support flexible adjustments of large-scale stream data in runtime to meet the requirements of real-time processing, dynamic flow and burst of data. Based on Flexible Online MapReduce model, the system architecture is designed to facilitate the model and a series of protocols are introduced, including Online Topology Initialization Protocol (OTIP), and Online Dynamic Adjusting Protocol (ODAP) for stream data job. To further integrate the system resources, the concept of operation sharing is introduced and Job Sharing Protocol (JSP) is designed. Protocol analyses illustrate that the communicating complexity of the protocol is O( n), and the system is able to adapt to the burst of stream data.
MapReduce[1]是由Google提出的大数据处理编程模型, 以其易用性及高效性成为应对大规模数据处理的普适工具, 广泛应用于大规模数据集的并行运算。尤其是以Hadoop[2]为代表的开源MapReduce数据处理平台, 在静态数据分析领域取得了很大的成功。但是静态的作业结构和离线的数据传输方式并不能很好地适应流数据处理作业结构多变性及应用实时性要求, 为了更加适应数据的灵活性, 很多研究人员对MapReduce提出了改进。
针对流数据结构的多变性要求, 微软发布的Dryad[3]系统允许用户将作业表示成为一个有向无环(DAG)图, 其核心数据模型由Vertex计算节点和Channel数据通道两部分组成。文献[4, 5]也均采用多层MapReduce结构来减小数据访问延迟以提高系统实时性。类似这种workflow[6]形式的作业描述, 文献[7, 8]讨论了作业间共享部分操作及中间处理结果的方法, 在节省系统资源的同时提高计算效率。
针对流数据的实时性要求, 一些研究工作开始尝试内存处理方式, 基于事件(Event)[9]对数据进行网络传输, 如Strom[10], S4[11]等。这种方式普遍支持连续流数据的持续快速处理, 但对现有数据处理工具及应用的兼容和继承难度较大。
HOP(Hadoop online prototype)[12]将MapReduce模型同内存计算模式相结合, 也可以称为Hadoop的管道版本。M3R和C-MR[13]等均采用内存计算技术提高数据访问性能, 但大多采用静态作业拓扑结构, 缺乏依据数据流量对作业拓扑结构弹性调整的能力, 这与流数据持续更新、流量和位置实时变化的特点不匹配, 数据流量的突变可能导致系统性能急剧下降。
上述研究成果普遍采用了静态拓扑结构描述作业, 并对流数据进行实时网络传输和在线处理。相对于静态数据处理平台, 这种方式显著提高了流数据处理过程的实时性, 但同时也存在以下几个方面的不足:首先, 流数据从本质上是动态的、持续的, 采用静态的拓扑结构作业模型与流数据本身就是矛盾的, 这也是静态拓扑结构不能适应大规模流数据处理的根本原因。其次, 流数据的产生是随机的, 同时也伴随着很强的突发性和周期性, 而静态拓扑结构采用静态的计算资源分配并不能适用这一突发性特点。
本文充分考虑了大规模流数据所具有的时效性、持续性、突发性等特点, 以工作流图的形式描述流处理作业的拓扑结构关系, 通过兼容MapReduce内存计算任务扩展工作流图的各个节点。实现了一种灵活的、能够可动态拓展的在线流数据处理模型— — 弹性在线MapReduce模型。
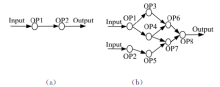
首先考虑一种最简单的传统流数据处理方式, 如图1(a)所示, 输入流经过两个操作, 获取输出结果, 这种模式结构简单, 很难满足多样化的流数据处理要求。
 | 图1 流数据处理模型图Fig.1 Diagram of development of the streaming data processing model |
考虑到流数据处理结构上灵活性和通用性的需求, 将上述简单的模型扩展为较复杂的workflow工作流模型。该模型用DAG图
弹性在线MapReduce处理模型如图2所示, 以兼容MapReudce的在线处理任务代替了workflow模型中的处理节点, 使其在流数据处理过程中具有动态调整及并行计算的能力。
 | 图2 弹性在线MapReduce流数据处理模型图Fig.2 Diagram of flexible online MapReduce streaming data |
“ 弹性” 和“ 在线” 分别代表了模型具有可依据流量动态弹性调整和内存计算处理方式两个特点。模型的内存计算处理方式是面向流数据应用实时性的处理需求。模型采用事件(Event)的方式在线进行数据传输, 并在内存中完成中间结果缓存, 数据运算等过程。这种在线的流数据处理方式对比传统MapReduce离线数据处理平台更能适应流数据处理的特点。模型的动态弹性调整则面向流数据的突发性特点。由于流数据的产生过程是随机的, 所以在很多应用场景中数据流量体现出周期性的波动。当数据流量发生变化时, 模型利用自身Step操作的弹性在不改变作业整体拓扑结构的情况下调整操作内部计算任务的并行程度, 实现模型的适应性调整。
基于1.2节对流数据处理模型的描述, 本节提出了弹性在线MapReduce流数据处理作业模型, 并依据对数据处理模型的结构化定义, 将作业中的节点分为三个层次进行抽象, 分别是作业管理层、操作层和计算任务层。
作业层面:将一个流处理应用作业Job(J)抽象为由特定的操作, 根据一定的拓扑关系组织而成的workflow模型。具体定义为一个以数据处理的拓扑结构Topology(T)为主体架构, 以数据的操作Step(S)为基础模块的流数据处理过程。
操作层面:数据操作Step逻辑上表示Topology中一个操作节点, 从输入流得到数据并对流数据进行一种预定的处理产生输出流, 再将其发送至后继节点。一个Step是由Mapper Task(MT)/Reducer Task(RT)组成。
计算任务层面:计算任务Task是将一个Step并行化的处理单元。属于同一个操作中的计算单元执行同样的操作任务, 根据流量动态调整, 适应流数据的突发性变化, 进而实现弹性在线workflow的作业模型。
通过上述定义, 将流处理作业描述为:
J= { S0, S1, S2, …… , Sn, T};
Sk={ MTk, RTk};
MT={ m1, m2, …… , ms };
RT={ r1, r2, …… , rd};
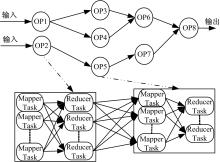
基于对弹性在线workflow作业模型的描述, 在流处理作业之间的操作有重叠场景时, 可以考虑使用作业共享模型。例如J1∩ J2={OPk1, OPk2, ……}≠ ⌀, J1和J2有i个共同的操作OPki(i≠ 0), 如图3所示J1={OP1, OP2, OP3, OP4, OP5, OP6}, J2={OP1, OP2, OP4, OP7, OP8, OP9}, J1∩ J2={OP1, OP2, OP4}。
 | 图3 作业间操作共享示意图Fig.3 Diagram of operation sharing between Jobs |
针对这种作业间的关系, 本文提出了作业间共享操作的解决方案。通过导出已建立的流处理作业中间结果的方式, 实现作业间的操作共享, 达到节省系统计算资源、提高系统利用率的目的。
依据上述内容对弹性在线MapReduce模型的描述和层次定义, 本文实现了基于弹性在线MapReduce模型的大规模流数据处理系统。
对应于模型中定义的三个层次, 本文将系统分为三层, 分别实现对各层次实体(作业、操作以及计算任务)的管理功能。
作业管理层(Job management layer, JML):从Job层面管理系统, 设置流处理作业队列Job Queue。依据优先调度算法, 选择调度Job。递交给操作管理层的服务接口。
操作管理层(Step management layer, SML):从Step层面管理系统, 接受作业管理层调度的Job作业, 并将作业解析为有拓扑结构的Step操作集合。将可并行化Step操作递交给任务管理层接口。
任务管理层(Task management layer, TML):从Task层面管理系统, 接受操作管理层提交的Step操作, 生产并管理M/R并行计算任务, 完成Step操作并行化工作。
本文提出了一个虚拟交换节点(Virtual Switch Node, VSN)的概念, 作为系统的传输控制机构, 在系统中负责动态管理拓扑结构中的数据流连接。虚拟交换节点实质上是作业中各通信实体之间通信机构的抽象。由于不同Task之间建立流连接与Step之间分发路径选择非常繁琐, 把这些映射独立出来, 由VSN来调整相应的数据分区机制, 管理Step之间的分发路径。
根据VSN转发层次不同, 主要将VSN分为两个模块:逻辑选路模块(Logical route module, LRM)负责维护流作业中操作之间的拓扑关系, 实现拓扑结构中Step之间逻辑路径链接, 并保存这些逻辑路径的状态信息; 数据分发模块(Data distribute module, DDM)负责集中管理Task之间的映射关系, 将Task处理的流数据依据相应
分区算法发送到后继Task节点上进行规约处理。
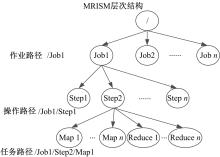
拓扑机构信息同步机构MRISM(MapReduce information synchronous mechanism)为系统中作业各层次处理单元信息的全局组织, 结构如图4所示。
 | 图4 MRISM数据组织结构图Fig.4 Structure map of data organization of MRISM |
MRISM在作业运行阶段存储流处理作业中各执行单元的初始配置、上下文环境、执行情况等信息, 并与计算单元实时同步节点运行时状态, 保证全局信息一致性。
系统通信模型的形式化描述如下:
System={JML, SML, TML}; 三层结构中各层的管理模块分别是Job Manager(JM)、Step Manager(SM)和Task Manager(TM)。
JML={Q, Scheduler, JM}:作业管理层中Queue(Q)队列和Scheduler调度算法用于实现队列的优化调度。
SML={Monitor, SM, VSN_LRM}:操作管理层中监视器(Monitor), 负责记录、维护Job的拓扑信息, 通过VSN_LRM管理操作之间的映射关系;
TML={TM, MRISM, Slave, VSN_DDM}:Step Manager(SM)管理Step操作及其并行化生成的M/R计算任务信息, Slave为集群主机, 通过VSN_DDM管理Task计算任务之间的数据发送分区。系统模型及模块间的通信交互流程如图5所示。
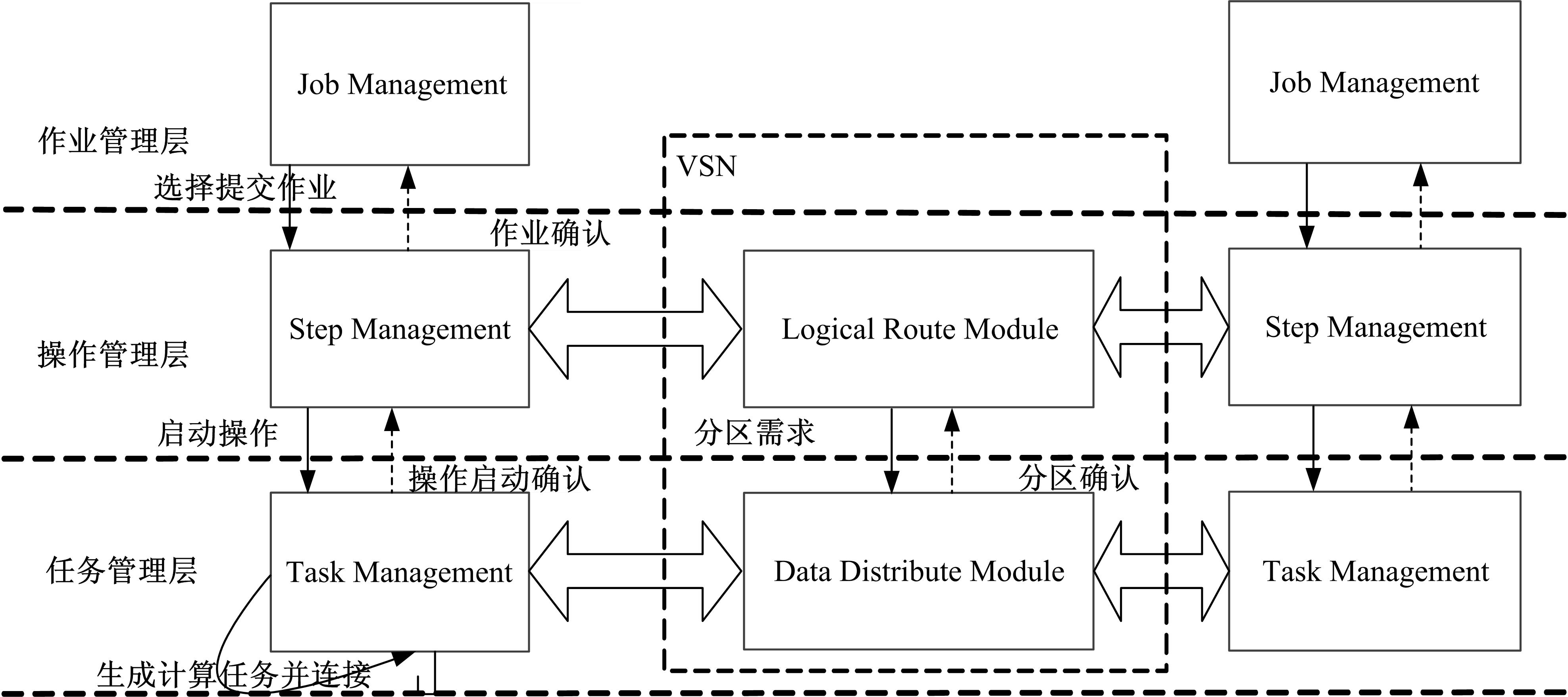 | 图5 系统模块交互图Fig.5 Diagram of system interaction process |
在线拓扑结构初始化协议(Online topology initialize protocol, OTIP)描述动态拓扑管理机制中从用户提交流数据处理请求到系统根据作业所配置的拓扑结构建立和连接弹性在线MapReduce流数据处理作业的整个过程。
从语法语义方面定义在线拓扑初始化协议数据格式:
作业初始化请求:
JOB_INIT_REQUEST={JobID, OPi_Info, Topology_Info }
操作初始化请求:
STEP_INIT_REQUEST= {S_Path, StepConf}
任务初始化请求:
TASK_INIT_REQUEST= {T_Path, TaskConf}
全局同步的信息单元:
S_MRIU_INFO= {S_Path, OPID, MapNum, ReduceNum, Share_Count, Share_List }
T_MRIU_INFO= {T_Path, Type, ServerAddress, StatuInfo}
操作连接请求及信息:
STEP_LINK_REQUEST={ Edge∈ Topology }
STEP_LINK_INFO={ Destination_Stepi_Info}
从时序角度定义协议规程如下:首先是作业提交阶段, JM向SM提交作业初始化请求, SM将请求中的拓扑信息发送给Monitor进行解析, 返回给SM的作业拓扑中有操作配置、逻辑路径等信息。然后, SM将拓扑结构中的操作配置发送给TM, 进入Step并行化阶段。TM在并行化过程中负责解析Step配置, 将Step请求的Task及相关配置发送到Slave上, 开始Task计算任务对Step进行并行化。Slave完成Task的启动工作后向TM返回ACK, TM所管理Step的所有Task全部完成时向SM做ACK应答, 作业节点的初始化过程结束, 进入作业连接阶段。最后, SM向所有VSN发送Step连接请求。VSN依据请求中拓扑图中边的信息建立Step之间的逻辑路径, 然后VSN从MRISM同步Step服务端口, 建立数据连接。
具体实现算法如下:
OTIP (Online topology initialize protocol)
BEGINE
T1 JM submits JOB_INIT_REQUEST to SM.
T2 SM sends Topology_Info to Monitor.
T3 SM receives the analysis results Topology.
T4 SM submits STEP_INIT_REQUEST to TM, and wait.
T5 TM sends S_MRIU_INFO to MRISM, and submits TASK_INIT_REQUEST to Slave.
T6 Slave sends the T_MRIU_INFO to MRISM.
T7 When Slave finishes the Task initial, response TASK_INIT_ACK.
T8 If all TASK_INIT_ACK of Step has been received from Slave, TM returns STEP_INIT_ACK to SM.
T9 SM submits STEP_LINK_REQUEST to VSN, and wait.
T10 Initiate VSNs to establish the streams based on the Topology.〗
basis of Edge in STEP_LINK_REQUEST.
T10.2 VSN_DDM request the STEP_LINK_INFO from MRISM by logical stream in VSN_LRM.
T10.3 VSN_DDM establishes data stream between Tasks.
T11 VSN returns STEP_LINK_ACK to SM.
T12 SM returns JOB_INIT_ACK to JM.
END
3.2.1 在线并行化调整协议(Online parallel adjust protocol)
突发性的特点和实时性的要求是流数据处理面向的两大主要问题。在线并行化调整协议主要面向流数据突发性的特点, 当数据流量发生突发性改变时, 系统使用该协议调整操作的并发程度, 一方面实现流数据处理过程中的弹性, 使模型具有可伸缩的特点; 另一方面流处理作业拓扑结构中关键路径上的适应性调整可提高模型整体性能, 降低系统延时, 提高实时性。
协议规定, 各Step对节点的适应性调整过程均分为两个阶段进行:①调整Step节点并行化程度, 在Step内部增加或删除Task并行计算任务; ②Task的增删过程将触发相关VSN的变化, 相应改变数据流的连接。
从语法、语义层面定义协议通信数据格式:
Step调整请求:
STEP_ADJUST_REQUEST= {S_Path, TaskType, ModifyType}
Task调整请求:
TASK_ADJUST_REQUEST= {T_Path, ModifyType, TaskConf}
拓扑更新通知:
UPDATE_NOTICE= {S_Path, Chang_Info}
数据流更新报文:
STREAM_REFRESH_MESSAGE={T_Path, Chang_Info}
本节以增加并行化程度为例, 分析协议规程:首先, Task调整阶段, SM将Step请求发送给相应的TM, TM依据请求类型选择Slave启动Task用以扩展Step操作。Slave完成启动及初始化配置工作后向MRISM同步新添加的Task信息, 回应ACK, 完成Task调整阶段。然后, 在Stream调整阶段可由MRISM中Step信息变化触发。在成功添加了节点后, MRISM会通知所有监听该变化Step的VSN, 并发布更新后的Step服务端口。VSN依据更新的Step的路径信息, 发现相关的StreamID, 从而更新这条逻辑路径的映射关系。
具体算法实现如下:
OPAP(Online parallel adjust protocol)
BEGINE
PHASE_1 BEGINE
T1 SM submits STEP_ADJUST_REQUEST to TM.
T2 TM submits TASK_ADJUST_REQUEST to Slave, and wait.
T3 Slave completes to add Task, and sends T_MRIU_UPDATE to MRISM.
T4 Slave responds TASK_ADJUST_ACK to TM.
T5 If all the TASK_ADJUST_ACK has been received, TM responds STEP_ADJUST_ACK to SM.
PHASE_1 END
PHASE_2 BEGINE
T1 When MRISM detects the change of Topology information, sends the message of UPDATE_NOTICE to VSN. Notify the related change.
T2 Refreshes the VSN_DDM to Change Data Stream between Task.
T2.1 VSN_LRM finds the SteamID of logical Stream about changing Step, and sends STREAM_REFRESH_MESSAGE to VSN_DDM.
T2.2 VSN_DDM refreshes the Data Stream between Tasks by Chang_Info in STREAM_REFRESH_MESSAGE.
T3 VSN returns the UPDATE_ACK to MRISM.
T4 MRISM returns the STREAM_REFRESH_ACK to SM.
PHASE_2 END
END
3.2.2 在线拓扑调整协议(Online topology adjust protocol)
协议描述拓扑结构中Step之间逻辑连接变更过程, 为Step操作的中间结果导出或作业共享等过程中拓扑结构的调整提供支持。协议数据格式如下:
逻辑路径变更请求:ROUTE_ADJUEST_REQUEST={Source_Step_ID, Destination_Step_ID, AdjustType, StreamID}
从时序角度分析协议规程:
当SM接收到作业的拓扑调整命令, 拓扑结构开始动态调整协议; 随后由SM向VSN发送逻辑路径变更请求; 接着, VSN_LRM依据变更请求添加改变的逻辑路径; 最后VSN_DDM参考变更请求更新Task之间的数据流连接。
具体实现算法如下:
OTAP(Online topology adjust protocol)
BEGINE
T1 SM receives the TOPOLOGY_ADJUST_COMMAND from JM.
T2 SM submits ROUTE_ADJUST_REQUEST to VSN.
T3 Add route between Step in VSN.
T3.1 VSN_LRM establishes logical stream to successor step and register the StreamID on the basis of ROUTE_ADJUST_REQUEST.
T3.2 VSN_DDM request the STEP_LINK_INFO from MRISM by logical stream in VSN_LRM
T3.3 VSN_DDM update data stream between Tasks.
T4 VSN returns ROUTE_ADJUST_ACK to SM.
T5 SM returns TOPOLOGY_ADJUST_ACK to JM.
END
在流数据处理模型中, 将流数据作业在Step层面定义为DAG图的形式, 如图3中表示的两个作业, 存在共享Step操作和中间结果的条件。作业共享协议描述作业共享实现过程, 以达到节省计算资源、提高系统利用率的目的。
从语法语义方面定义作业共享协议数据格式:
作业共享请求:JOB_SHARE_REQUEST= {S_ Path, D_ Path, S_Path1, S_Path2 ……}
作业共享协议在执行过程中, 涉及到了MRISM中S_MRIU_INFO的共享信息字段, 如共享计数器Share_Count和共享作业队列Share_List。从时序的角度定义作业共享协议规程如下:JM提交共享作业请求, 在MRISM中找到共享源作业信息。将源作业中的共享操作添加到共享目的作业路径下, 同时记录该共享过程, 将共享操作的共享计数器参数Share_Count加1, 向共享操作的共享作业队列参数Share_List中追加本次作业共享路径D_ Path。
具体实现算法如下:
JSP(Job share protocol)
BEGINE
T1 JM submits JOB_SHARE_REQUEST to MRISM.
T2 MRISM searches the J_MRIU_INFO of S_Path.
T3 Search the shared step’ s S_MRIU_INFO in the children of J_MRIU_INFO.
T4 MRISM appends the S_MRIU_INFOs as children to J_MRIU_INFO of D_Path.
T5 Increase the Share_Count of the S_MRIU_INFO.
T6 Append the D_Path to Share_List of S_MRIU_INFO.
T7 MRISM return the JOB_SHARE_ACK to JM.
T8 JM calls Job Initialize Protocol to Initial and link the remaining Step.
T9 JM calls Topology Adjust Protocol to change the shared Step’ s route.
END
假设在规模有限的集群环境中运行流处理作业, 集群中Slave计算节点个数为H。流数据处理作业拓扑结构中共有操作节点个数为M, Step之间逻辑路径个数为E, 初始化并行程度为K, 即每个Step初始由K个Task任务并行化, 则这些节点并行化过程中共生成并行M/R计算任务的个数为K× M。
在线拓扑初始化协议OTIP中, T4阶段启动M个Step, SM向TM发送N个STEP_INIT_REQUEST, 复杂度为O(N); T5发送全局同步信息的数量为N, 并初始化Task计算任务, 通信复杂度为O(N)+O(KN); T6、T8为Task同步和确认的过程, 通信复杂度为O(K× N)。
在建立数据流连接的过程中, 作业的逻辑路径表示为拓扑结构中的边, 且数量为E, Step并行度为
在线动态调整协议中, 对操作节点并行化程度调整的通信复杂度为O(1)。另外, 由于VSN的引入, 相应的数据流连接和逻辑路径的变更只通过更新相关的VSN即可实现, 通信复杂度为O(1), 综上动态调整过程的在线并行化调整协议及在线拓扑调整协议可以在常数时间完成, 与系统规模无关, 即
作业共享协议中, T1向全局同步机制发送共享请求, 通信复杂度为O(1); T2至T7过程在MRISM中完成, 没有节点间通信过程, 时间复杂度为O(1); T8过程调用在线拓扑初始化协议时间复杂度为T(OTIP)=O(M)+O(E); T9过程假设有S个Step以共享方式连入作业, 通信复杂度为S× T(TAP), 复杂度最大为O(M), 所以, T(JSP)=O(M)+O(E)。
综上分析, 在线拓扑动态建立过程中, 协议通信复杂度与流处理作业中并行计算任务Task的数量呈线性关系, 动态调整协议的复杂度与系统规模无关, 而作业共享协议的通信复杂度与拓扑结构中节点和边的规模呈线性关系。
4.2.1 测试环境
测试过程中使用吉林大学高性能计算中心8个技术节点。具体配置如下:操作系统为Redhat Linux version 2.6.32-358.el6.x86_64; CPU为16核Intel(R) Xeon(R) E5-2670, 主频2.60 GHz, 共计128个处理核心。内存为32 G, 共计256 G内存。网络环境为计算节点之间使用千兆以太网互相连接。
4.2.2 测试实验
测试用例为5个Step操作组成的流数据处理作业, 连接为如图6所示的工作流程图。
 | 图6 系统测试用例拓扑机构Fig.6 Topology structure of test case |
| 表1 系统动态调整响应时间表 Table 1 The system response time for dynamic adjustment |
(1)测试1
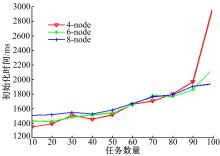
由协议分析过程可以看出, 当规模一定时, 在线拓扑初始化协议对比其他协议具有较高的通信复杂度。测试1旨在验证作业规模与在线拓扑初始化协议通信复杂度之间的关系。
分别用4节点、6节点、8节点初始化图6中拓扑结构的作业, 用来对比计算资源对协议执行时间的影响。在实验过程中通过不断增加作业规模, 得到作业初始化时间与系统规模之间的关系。
从实验结果(图7)可以看出, 当Task数量很少时, 多个计算节点系统并没有体现出明显的优势, 这是因为此时系统的计算资源相对充足, 协议通信开销对集群的运行时间的影响比较明显。当初始化计算任务数量逐渐增加时, 协议运行时间随作业规模变化呈近似线性变化。计算资源越充足, 这种线性关系表现的越平稳。
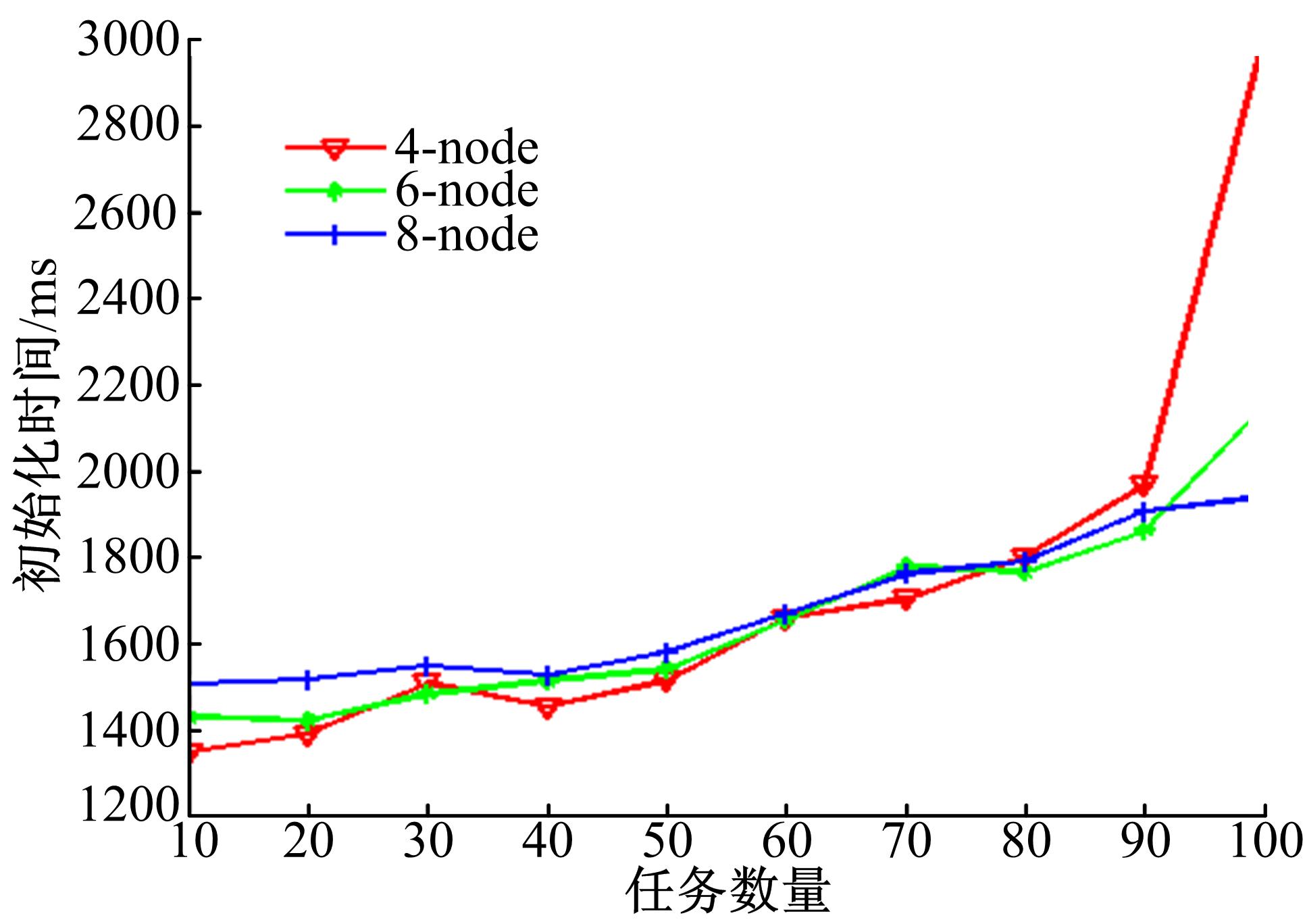 | 图7 不同数量节点上作业初始化时间与作业规模的关系Fig.7 Job initialize time varies with number of task in different case |
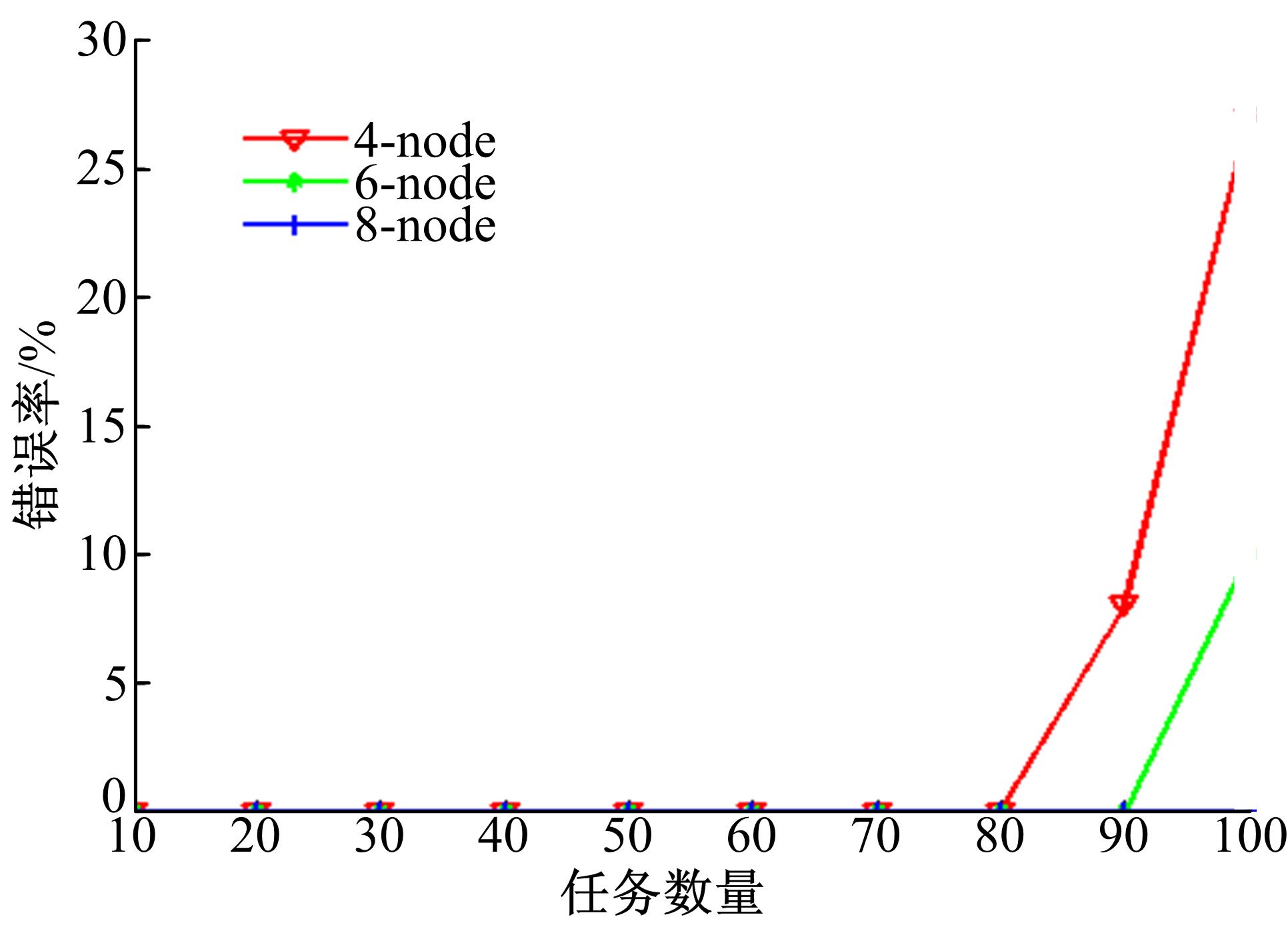 | 图8 不同数量节点上作业出错率与 作业规模的关系Fig.8 Job error rate varies with number of task in different case |
从图8中可以明显地看出系统计算资源的限制作用。当Task计算任务增加到80时, 4节点集群已经开始出现计算任务初始化失败的现象, 对应于图7中运行时间骤增的趋势。而在集群规模较大的(8节点)集群中, 当Task计算任务数量为100时, 任务初始化失败个数依然为0。由此可见, 本文提出的协议在集群规模很大、任务数量很多时, 能够表现出更好的灵活性和稳定性。
(2)测试2
该测试通过改变Task发送端流数据传输速率, 记录接收端从通知MRISM, Step节点监测到改变信息, 扩展数据处理任务, 并最后将其接入系统进行流数据处理的整个过程, 验证基于弹性在线MapReduce模型实现的流数据处理系统的可用性及可扩展性。
测试拓扑结构如图6测试用例, 两个Step用于发送, 每个Step有两个ReduceTask。接收端Step初始阶段只有一个MapTask进行流数据处理。设置接收端Task的数据处理能力为10 Event/s, 每个发送Task的传输速率随时间线性递增, 其表达式为:
式中:ET为等待连接建立后开始发送数据的时间。
实验过程中记录的时间点如下, NotifyTime(NT)表示过载通知时间点; StartTime(ST)表示MapTask启动时间点; LinkTime(LT)表示完成连接时间点, 所以ST(0)、LT(0)分别表示初始化阶段的启动、连接时间, ET=LT(0)。NT(i)、ST(i)、LT(i)分别表示接收Step现有
初始化平均时间:
平均连接时间:
平均调整响应时间:
当
(1)弹性在线MapReduce模型能够很好地适应流数据处理的实时性、可扩展性要求, 适合大规模流数据处理的应用。
(2)本文设计的动态管理协议运行时间、作业规模与作业规模呈线性关系, 且动态调整协议保证了弹性在线MapReduce流数据模型良好的实时性及可扩展性。
(3)作业共享机制可以成为解决有拓扑结构的流处理作业的优化调度问题的新思路。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|