





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于统计特征的图像篡改评价模型
[申铉京1, 2  , 范子龙
, 范子龙1, 2 , 吕颖达3 , 陈海鹏1, 2 ]
, 范子龙]
|
|


作者简介:申铉京(1958-),男,教授,博士生导师.研究方向:图像处理与模式识别,多媒体信息安全,智能控制技术.E-mail:xjshen@jlu.edu.cn
为了实现图像篡改手段的定性分析,构造了基于图像统计特征的篡改评价模型。该模型提取图像的LTP三值模式特征、LBP纹理特征和WLD局部特征,利用SVM分类器,实现对自然图像、计算机生成图像、复制-粘贴图像、拼接篡改图像、重获图像的多分类。实验结果表明,该模型能够在盲环境下实现图像的有效分类,客观分析图像篡改手段,综合正确检测率为85%。
In order to qualitatively analyze different tampering means of digital images, a tampering evaluation model based on image statistical features is proposed. First, the Local Ternary Pattern (LTP) features, Local Binary Pattern (LBP) features and Weber Local Descriptor (WLD) features ternary are extracted from the image. Then, SVM is used to classify the nature images, computer generated images, copy-pasted images, spliced images and recaptured images. Experimental results show that the proposed model can effectively classify the tampering images in the blind environment, objectively identify the image tampering method, and the comprehensive correct detection rate can reach 85%.
数字图像篡改手段繁多, 其中主流的篡改手段包括复制-粘贴、拼接篡改、计算机生成图像、重获图像等。相关学者针对不同篡改手段, 从图像特征入手, 提出了相应的盲鉴别方法[1, 2, 3, 4]。然而, 目前仍然处于零散技术的研究阶段[5]。现阶段对图像进行真伪检测时, 需要人为预先估计出图像的篡改手段, 这种主观评判具有一定的偶然性。2009年, 胡东辉等首次提出了盲环境下数字图像可信性评估模型[6], 设计了基于图像生命周期特征的可信性判断模型和基于模糊层次分析法的可信性综合度量模型, 并验证了所提出的数字图像可信性综合度量模型的有效性, 通过该模型能够给出图像的可信值。该模型虽然给出了图像的综合可信度, 但未给出图像的相应篡改手段。孟宪哲从图像篡改是否属于恶意修改行为的角度, 初步规划了一个图像真实性评价模型[7]。该模型首先检测图像是否存在修改行为, 如果存在, 将结合图像内容、修改效果、构图关系对这种修改行为进行分析, 如果修改行为改变了图像内容, 则认为该图像不真实, 再进一步进行篡改检测和定位。如果修改行为只是为了使图像表达更加清晰而没有改变其内容, 则认为该图像是真实的。目前, 对能够定性分析图像篡改手段的评价模型的研究仍处于初级阶段, 模型的总体性能和实用性仍存在较大的完善空间, 需进一步研究满足应用化要求的篡改评价模型。
针对以上问题, 本文提出了一种基于图像统计特征的篡改评价模型, 通过该模型能够客观得出伪造图像的篡改手段。
针对计算机生成、拼接、复制-粘贴和重获等常用的篡改手段, 需要设计能够定性分析篡改手段的评价模型。以上篡改手段分别具有如下特征。
(1)计算机生成图像:由计算机软件通过有限步的图像处理生成的虚拟图像, 虽然与现实世界中的事物有所对应, 但并不是真实的自然图像。计算机软件创造的计算机生成图像, 多由几何图像和一些复杂的多边形模拟构成, 光线上是通过光线反射模拟, 利用制作经验和自身的资源模拟得到的, 可能会存在不一致的光线和错误的阴影。
(2)拼接篡改图像:指由两幅不同的图像合成一幅图像, 在合成过程中会在边缘处留下明显的边缘信息, 并且破坏原始图像的像素分布, 以及像素之间的相关性, 同时也会改变图像的局部纹理特性。
(3)复制-粘贴图像:指在同幅图像上, 把某个区域通过粘贴操作复制到另外一个区域上, 目的是增加图像中相同事物的数量, 或者隐藏某一个事物, 这类篡改图像人们肉眼无法辨别。在篡改过程中整幅图像在颜色和亮度上的变换微乎其微, 主要是在一幅图像上产生相似块, 通过寻找图像中的相似块来检测图像是否存在复制-粘贴篡改。
(4)重获图像:也称为翻拍图像, 是指已经存在的真实图像通过相机进行翻拍, 达到以假乱真的目的, 如“ 华南虎” 照片。这类篡改图像在翻拍过程中, 图像的纹理特性产生变化, 同时会引入一些噪声。针对这类篡改通过分析图像的纹理特征和噪声信息就能够进行检测。
通过以上篡改手段的特征分析, 本文提取图像的LTP(Local ternary pattern)三值模式特征、LBP(Local binary patterns)纹理特征和韦伯局部特征(Weber local descriptor, WLD), 并在此基础上构建篡改评价模型。模型框架如图1所示。
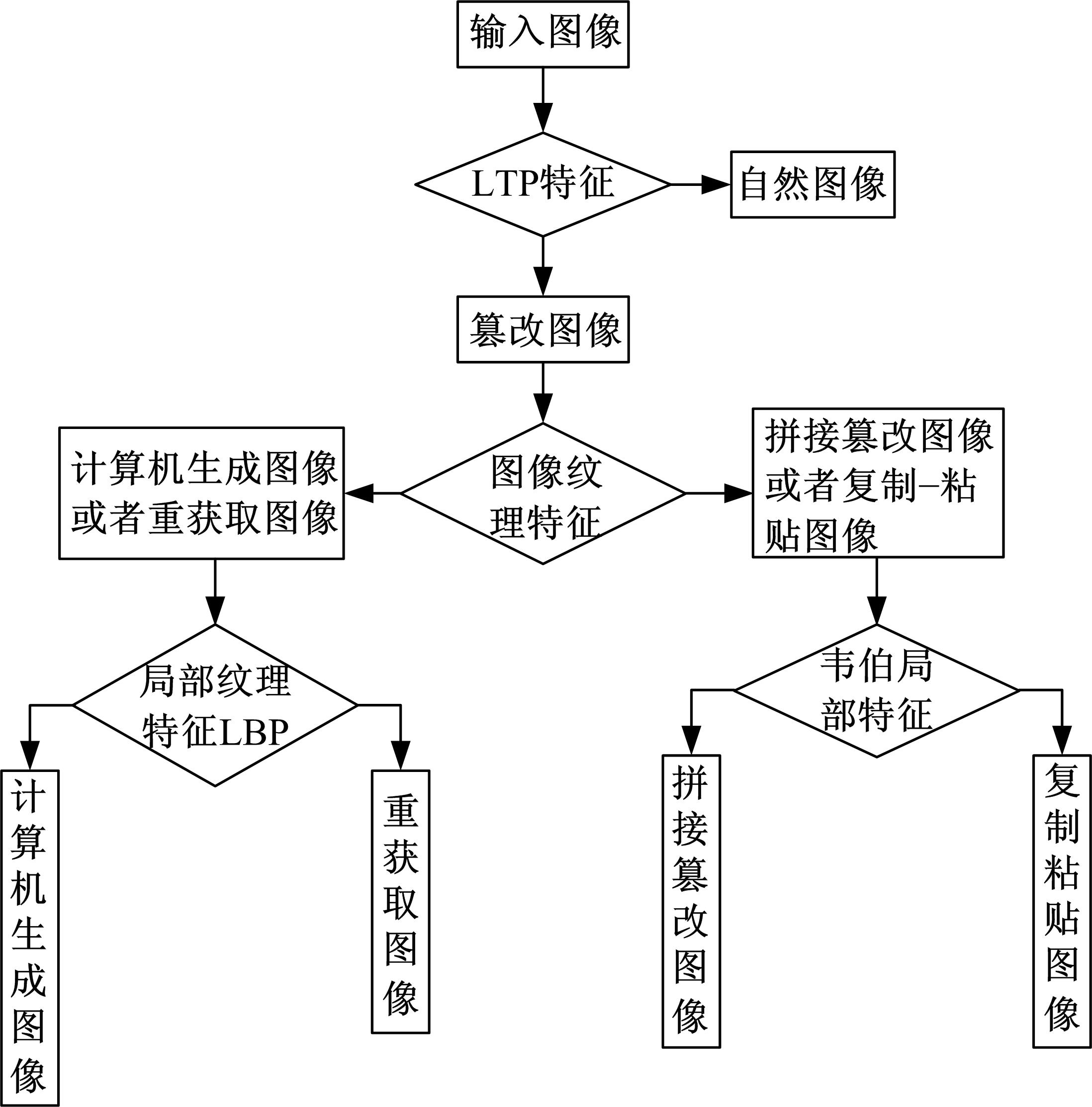 | 图1 篡改模型框架结构Fig.1 The frame structure of tampering model |
该模型的工作流程为:①提取输入图像的LTP三值模式特征, 判断图像是否为自然图像。②如果该图像是自然图像, 那么输出结果。③如果该图像是篡改图像, 提取图像的纹理特征, 并根据特征强弱, 将其分为两类:一类是计算机生成图像和重获取图像, 另外一类是拼接图像和复制-粘贴图像。④如果该图像属于第一类, 则提取LBP局部纹理特征, 判断其是计算机生成图像还是重获图像。⑤如果该图像属于第二类, 则提取韦伯局部特征, 进行拼接篡改和复制-粘贴篡改的分类。
LTP是图像的局部三值模式, 能够很好地描述图像纹理特征[8]。
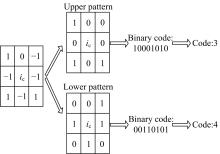
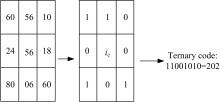
为了更好地体现图像局部纹理特性, LTP引入了一个宽度为t的邻域范围。在计算相邻像素值s(x)与中心像素值ic 的差值过程中,如果相对中心值变化量在t范围内则量化为0;大于t的量化为1;小于t的量化为-1, 如式(1)所示:
对经式(1)计算后的三值模式进行分解, 如图2所示, 即把1和-1值进行分类, 再分别统计1值的个数, 存储在一个二维矩阵中, 最后统计直方图特征, 并作为最终的特征值。
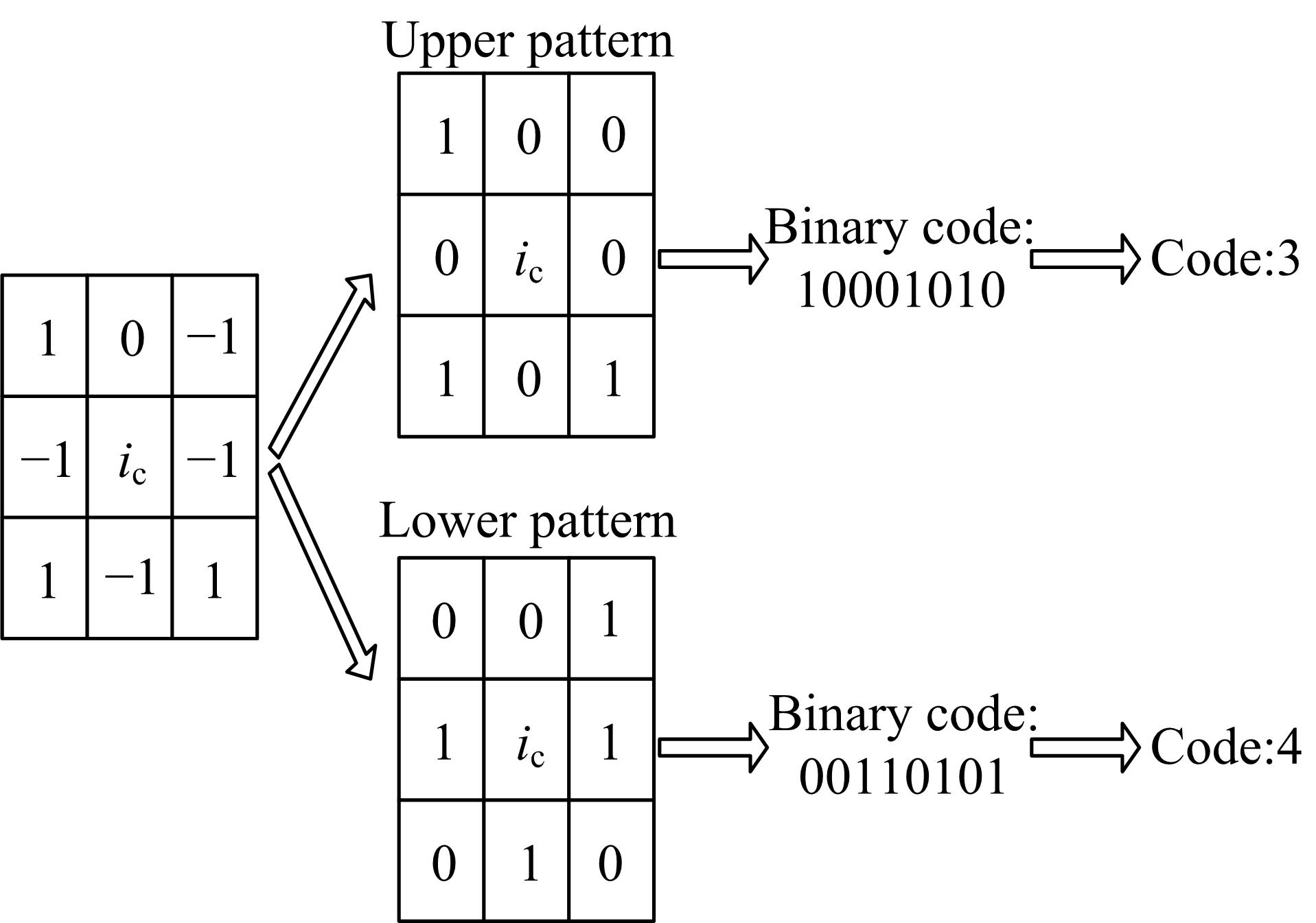 | 图2 LTP分解示意图Fig.2 The schematic diagram of decomposing LTP |
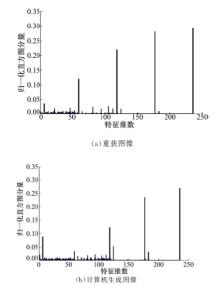
由于自然图像和篡改图像的形成过程存在差异, 导致图像在纹理特征上存在明显的差别。本文通过实验对比分析了1000幅自然图像和1400幅篡改图像的LTP特征直方图, 统计规律发现, 篡改图像的LTP直方图比自然图像的LTP直方图变化更平缓、层次更清晰。图3为一幅自然图像与篡改图像的LTP直方图特征对比的实例。图3(a)(b)中横轴表示图像提取的LTP特征维数; 纵轴表示每一维特征对应的归一化直方图分量。
 | 图3 篡改图像和自然图像的特征直方图对比Fig.3 The comparison of tampered images and natural images features histogram |
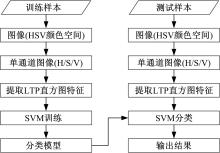
因此, 本文采用具有高效性的LTP局部纹理特征的直方图差异性, 结合SVM分类器, 对自然图像和篡改图像进行分类。分类流程如图4所示。
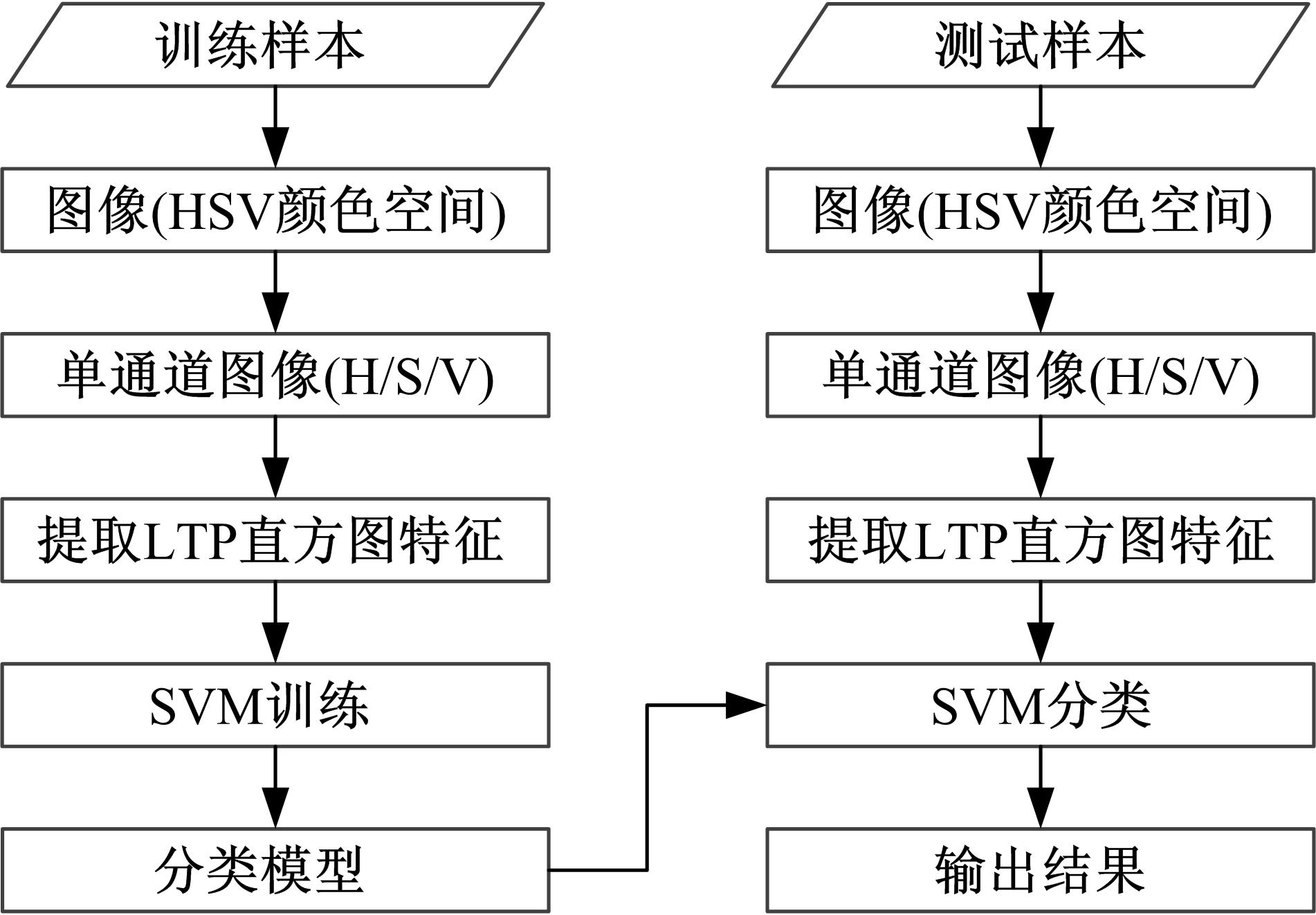 | 图4 LTP特征分类流程图Fig.4 The flow chart of extracting LTP feature classify |
在图像的HSV颜色空间提取LTP直方图特征, 每个通道分为18维高频模式和低频模式直方图特征, 三个通道共54维特征。
LBP是一个很好的局部纹理描述算子[9], 定义如式(2)所示:
式中:
选取
 | 图5 LBP算子计算过程Fig.5 The process of calculating LBP operator |
在特征提取过程中, 采用一致模式的LBP, 这种标准的LBP算子所得到的二进制编码序列中, 最多包含一个0到1和一个1到0的变换。对这种一致模式的编码, 当最近邻区域内取8个像素时, 可以得出59种不同的统一模式编码, 从几何学的角度出发, 统一模式反映了亮斑、污点、边缘和拐角等信息, 这些信息对图像来说都是非常重要的特征, 而且符合人类认识图像的生理机理。重获图像和计算机生成图像的特征直方图如图6所示, 图6(a)(b)中横轴表示图像提取的统一模式LBP的特征维数; 纵轴表示每一维特征对应的归一化直方图分量。根据直方图特征, 利用SVM分类器对其进行分类。
 | 图6 重获图像和计算机生成图像特征直方图对比Fig.6 The comparison of recaptured images and computer generated images features histogram |
因此, 本文在图像的YCbCr颜色空间中分别对源图像及其预测误差图像在Cb和Cr通道分别提取LBP特征, 并对LBP的特征值提取直方图特征, 特征维数为236维。
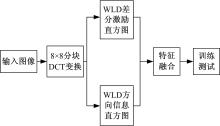
WLD特征是由Chen等根据韦伯定律提出的一种简单而且鲁棒的局部纹理特征。韦伯定律指出激励变化与背景的比值超过一定的阈值才能被人们感知。WLD特征引入了差分激励和方向信息两个比率, 来描述图像中纹理特征的变化情况[10]。韦伯特征的提取流程图如图7所示。
 | 图7 提取WLD特征流程图Fig.7 The flow chart of extracting WLD feature |
为了分类拼接图像和复制粘贴图像, 考虑图像的局部频率分布情况, 并引入韦伯局部特征。对于一个像素点而言, 其中的差分激励就是该像素点与8-邻域像素值之差的总和与该点像素值的比值。它反映了图像的结构信息, 而方向信息实质上描述了图像的梯度方向。WLD的差分激励和方向信息直方图特征, 分别包含了DCT系数的不同信息。差分激励主要反应系数矩阵当前位置的变化幅度的大小; 而方向信息主要反应系数矩阵的当前位置的变化方向, 这两种特征能够很好地来表示图像频率的分布情况。
通过大量实验分析, 在差分激励直方图上, 复制-粘贴图像比拼接图像变化平缓, 在方向信息直方图上复制-贴图像比拼接图像直方图陡峭。图8为拼接图像和复制-粘贴图像WLD特征直方图的实例。图8(a)(b)中横轴表示图像WLD的特征维数; 纵轴表示每一维特征对应的归一化直方图分量。因此, 本文利用WLD特征直方图上的显著差异, 结合SVM分类器, 对拼接图像和复制-粘贴图像进行分类。
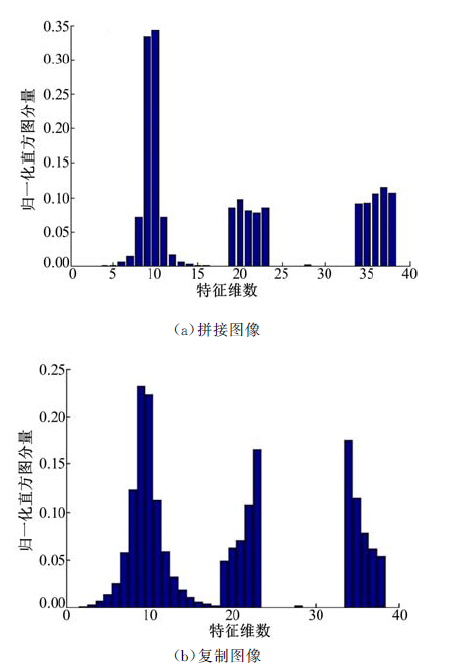 | 图8 拼接图像和复制-粘贴图像的特征直方图对比Fig.8 The comparison of spliced images and copy-paste images features histogram |
选取WLD特征时, 按照文献[6]中对参数的设置, 本文提取18维的差分激励特征和20维的方向信息特征。并且在对这两种特征进行加权特征融合时, 系数设置为
支持向量机(SVM)是一种有监督的分类和回归方法。在一个
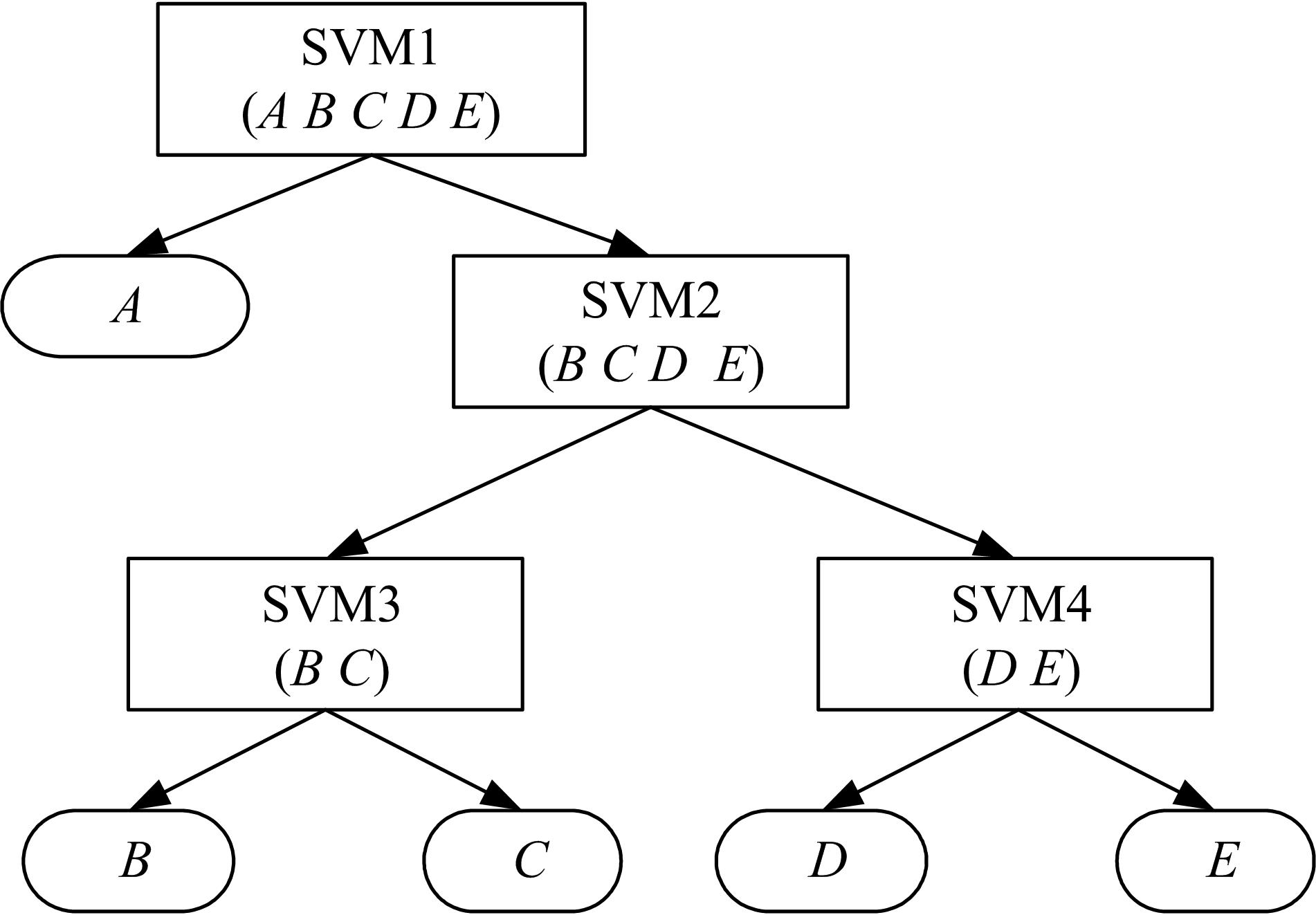 | 图9 二叉树多分类向量机结构图Fig.9 Structure of Binary tree multi-classification SVM |
其中
本文的图像数据库构成为:1000幅自然图像、500幅来自于哥伦比亚大学计算机生成图像库的计算机生成图像[12]、500幅来自哥伦比亚大学拼接图像库[13]的拼接图像, 300幅来自于哥伦比亚大学重获图像库[14]的重获取图像, 以及自己PS的100幅复制-粘贴图像。图10为实验用图像的示例, 其中(a)、(b)、(c)分别为图像库中的计算机生成图像、重获图像和拼接篡改图像, (d)为PS的复制粘贴图像。
仿真实验环境为AMD Athlon(tm) 7750 2.7 GHz CPU, 1 GB内存。编程环境为Microsoft Visual 2008; 编程语言为C++; 采用支持向量机(SVM)作为分类器进行分类, 其中核函数选取RBF核函数, 在交叉验证过程中用网格搜索法自动寻找最优的惩罚因子
式中:
对1000幅自然图像和1400幅篡改图像, 分别取4/5作为样本集, 1/5作为测试集, 提取LTP局部三值模式特征, 采用SVM1进行分类实验, 随机进行20次实验, 取平均值作为最终的检测率。统计结果为:自然图像的检测率为97.0%, 篡改图像的检测率为94.0%, 平均检测率为95.5%, 特征维数为54。
对800幅计算机生成图像和重获取图像、600幅拼接图像和复制粘贴图像, 每次分别选取4/5作为样本集, 1/5作为测试集, 提取LBP纹理特征, 采用SVM2进行分类实验, 随机进行20次实验, 取平均值作为最终的检测率。统计结果为:计算机生成图像和重获取图像的检测率为96.2%, 拼接图像和复制粘贴图像的检测率为93.3%, 平均检测率为94.75%, 特征维数为236。
对500幅计算生成图像和300重获取图像, 每次随机选取4/5作为样本集, 1/5作为测试集, 提取LBP纹理特征, 采用SVM3进行分类实验, 随机进行20次实验, 取平均值作为最终的检测率。统计结果为:计算机生成图像的检测率为96.2%, 重获取图像的检测率为95.4%, 平均检测率为95.8%, 特征维数为236。
对500幅拼接图像和100幅复制粘贴图像, 每次分别随机选取4/5作为样本集, 1/5作为测试集, 提取WLD局部特征, 采用SVM4进行分类实验, 随机进行20次实验, 取平均值作为最终的检测率。统计结果为:拼接图像的检测率为89.8%, 复制-粘贴图像的检测率为87.6%, 平均检测率为88.7%, 特征维数为38。
由以上检测结果可知, 各分类器之间是相互独立的, 由概率论知识可知, 对于二叉树树上的叶子节点的检测率, 应该为所有父亲节点的检测率的乘积。各类图像经过该篡改评价模型分析的最终综合检测结果如表1所示。
| 表1 篡改模型的综合检测率 Table 1 Comprehensive detection rate of the tampering model |
由以上结果可知, 本文提出的篡改评价模型, 能够客观分析图像的篡改手段, 为数字图像盲鉴别技术的系统化奠定基础。
数字图像的篡改手段繁多, 每种篡改手段都有特定的鉴别方法, 但需要人为地猜测幅图像篡改手段, 为了定性分析图像篡改手段, 本文提出了基于统计特征的图像篡改评价模型, 该模型能够客观地给出图像的篡改手段, 为后续的针对特定方法进行更精准的检测奠定基础。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|