
{kind=link}
{kind=link}
{kind=link}
基于全局与局部形状特征融合的形状识别算法
[王生生1  , 郭湑
, 郭湑2 , 张家晨1 , 王光耀1 , 赵欣1 ]
, 郭湑|
|


作者简介:王生生(1974-),男,教授,博士生导师.研究方向:机器视觉,时空推理.E-mail:wss@jlu.edu.cn
经典的全局形状识别算法虽然高效,但在处理形变方面存在不足。局部形状识别算法拥有良好的检索率,但在辨别力方面的效果却有待提高。为解决上述问题,本文提出一种基于特征点分类的融合框架,该框架不仅融合了全局与局部算法的优势,还弥补了二者的不足。一些经典的形状识别算法采用提取特征点的方式来构建形状特征直方图,本文在此基础上,将提取到的特征点进一步分类,针对不同类别的特征点集合采用不同的形状识别算法进行描述,并将匹配结果进行融合,充分发挥了全局与局部算法的优势。实验结果表明,本文提出的框架能够有效结合不同算法实现形状的识别并获得更好的效果。
Although the classical global shape recognition algorithm is efficient, it is not good enough to deal with the deformation. The local shape recognition algorithm has a good retrieval rate, however, the discriminability still needs improvement. To solve these problems, a fusion framework based on the classification of characteristic points is proposed, which not only takes the advantages of global and local shape recognition algorithms, but also makes up for the lacks of the two algorithms. Some classic shape recognition algorithms build the shape feature histogram by extracting the characteristic points. Based on this, these points are further classified that different shape recognition algorithms are applied to different kinds of points. The matching results are then fused to make full used of the advantages of the global and local shape feature descriptors. Experiment results show that the proposed framework can effectively combine different algorithms to achieve the shape recognition and get better results.
形状作为一副图像的重要特征, 其匹配与识别在人类的感知行为中扮演重要的角色。近些年来有很多形状识别的算法被提出来, 并得到了广泛的应用[1, 2, 3, 4]。这些算法可分为全局算法和局部算法[5], 全局算法将形状视为一个整体, 并对其进行编码或建立特征描述模型, 例如Morphological Representations算法[6], Tree-unions算法[7], CBSM算法[8]。而局部算法将形状描述为一组局部特征的集合, 例如SC算法[9], IDSC算法[10], Height Functions算法[11]。目前, 人们开始将具有不同特性的形状识别算法进行融合, 来获得更好的效果[12, 13, 14]。BSM算法, 即模糊形状模型(Blurred shape model)[15], 它是一种对形状轮廓上的特征点进行编码建模的全局算法。BSM采用了一种刚性网格结构, 通过计算轮廓上的特征点与其周围网格重心点的空间关系来描述形状特征。其改进算法有CBSM算法[8], 设计了圆形刚性网格结构, 为BSM算法提供了旋转不变性; SBSM算法[16], 在添加旋转不变性的同时, 将二维形状识别推广到了三维, 并取得了良好的效果。SC算法, 即形状上下文算法(Shape context)[9], 作为一种局部算法, 在获取形状特征点的基础上, 考察点集上指定特征点与该点集上其他特征点的空间位置分布关系, 并构建特征直方图。然后通过两个特征直方图之间的对比, 成功地将形状的匹配问题转化为寻找两个特征点点集的对应点问题。其改进众多, 比较经典的有IDSC算法[10]和Height Functions算法[11], 分别用内距离和高度函数来替换欧式距离, 提高了检索率。
经过多年的发展, 全局算法和局部算法都取得了不小的突破, 然而对于全局算法, 其特征描述模型特征维度较低, 当形状发生轻微的不规则形变时, 会将发生形变的形状判断为另一个类别。与此同时, 局部算法虽然提取了更多的特征细节, 却仍然避免不了误匹配的情况, 具体表现为将两个不同类别的形状判断为同一类别。而一个理想的形状识别算法需要将相同的形状识别为相同的, 将不同的形状识别为不同的, 即具有良好的类内相似、类外相异特点。所谓类内相似是指检索时, 能将原本属于同一个类的形状归为一类, 而与之相对的类外相异, 是指能将原本属于不同类别的形状成功区分开, 类内相似反映了算法对轻微形变的包容能力, 而类外相异代表了算法对形状的辨别能力。当类内相似的效果较差时, 会将原本相同的对象识别为不同的对象, 而类外相异的效果较差时, 会将原本不同的对象识别为相同的对象。全局算法能够做到类外相异, 但是类内相似效果较差。局部算法的类内相似效果良好, 但类外相异效果在达到一定的检索率后便会成为瓶颈。因此通过融合这两类算法的方式来弥补它们自身的不足便成为了一种可行的办法。
人们在对形状识别算法进行改进的同时, 也对形状特征的提取进行了探索。例如, 轮廓特征点从早期的随机选取, 到指定方向顺序, 再到用角点作为特征点。对此, 本文提出一对新的概念— — 类特征点与形变特征点。基于类特征点和形变特征点, 融合全局和局部算法优势本文提出一个全新框架。对于全局算法, 采用原始的BSM算法, 这是因为BSM算法改进众多, 无论采用哪种改进都会对测试结果产生影响, 无法真正地评估出融合框架的效果。同样地, 对于局部算法, 采用原始的SC算法。因为二者是多种全局和局部改进算法的基础, 若能将二者进行融合并取得良好的效果, 将为多种基于这两种算法的改进算法提供参考价值。
图像上的少数特殊点能在保留图像图形重要特征的同时, 有效地减少信息的数据量, 提高计算的速度, 有利于图像的可靠匹配, 角点便是这类点的代表。但角点是二维图像变化剧烈的点或是图像边缘曲线上曲率极大值的点, 所以在生成角点的同时, 会忽略很多信息含量很高的点, 额外引入一些在数学计算上特殊的点, 而非具有实际意义的点。基于此, 本文提出了一种新型的“ 特殊” 点— — 类特征点。
类特征点不是通过单幅形状计算得到, 而是通过统计的方式得到。将数据库中同一类的一组形状提取轮廓特征点, 用特征点匹配的方式进行交叉匹配, 记录每个形状上匹配成功次数超过一定阈值的特征点, 把这些点作为该形状的类特征点。具体算法如下:
算法1 类特征点
给定一个带类标签的数据库D:
1.对于D中每一个形状
2.对于数据库D中每个具有同一类标签的形状集P={S1, S2, …, Sn}进行交叉匹配(本文采用SC中的特征点匹配算法)。
3.对于每对进行匹配的形状Si, Sj(∀ i, j∈ [1, 2, …, n], i≠ j)
For each point x∈ Si
If x获得匹配
c=c+1
End_If
End_For
4.根据阈值θ 的不同, 便可以将特征点分为类特征点(c> θ ), 非类特征点(c≤ θ )
通过算法1可提取数据库中每个形状的类特征点, 效果见图1, 其中十字是形状轮廓点, 圆圈是训练得到的类特征点。从效果图中可以看出, 这些类特征点很好地还原了形状本身, 相对于角点具有更好的代表性。
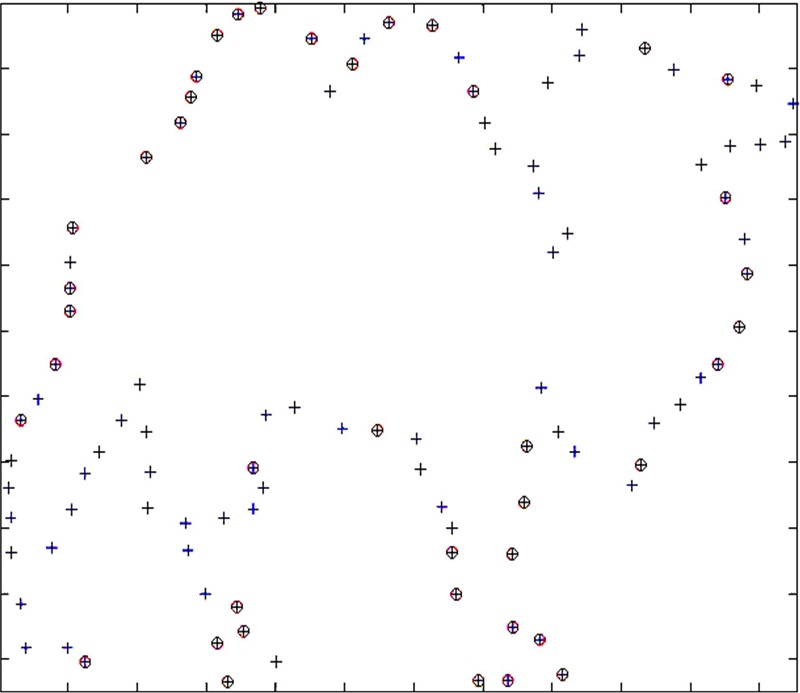 | 图1 类特征点效果图Fig.1 Example of class-points |
类特征点的提出不仅为形状找到了一种比角点更可靠的特殊点, 而且对本文接下来提出的融合框架起到核心作用。在类特征点参与下, 本文将在形状匹配的过程中提取出另一种非常重要的特征点— — 形变特征点。
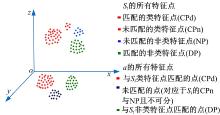
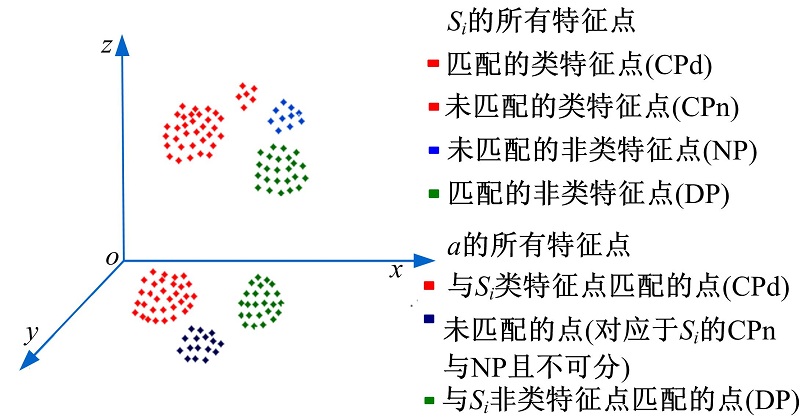
通过上述统计方式, 统计数据库中所有形状, 将其轮廓上的特征点划分为类特征点和非类特征点, 对于常见的检索实验:当待检索的形状
 | 图2 不同种类的点Fig.2 Points of different types |
本文将匹配的非类特征点(DP)称为形变特征点, 因为它代表了形状发生轻微变形的那些区域。从图2中可知, 当前进行匹配的数据库形状
所谓未匹配的点, 即在一次匹配过程中并未获得匹配的对应特征点, 两个形状越是相近, 则未匹配的点越少; 差异越大, 则未匹配的点越多。同时, 这些未匹配点的特征代价也会随着形状间的差异而不同, 形状越是相似, 这些点的特征代价越小, 越是不同, 特征代价越大。
至此, 两个形状上的特征点被划分为对应的三类:匹配的类特征点, 未匹配的点, 形变特征点。
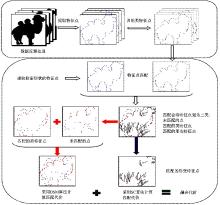
本文提出的融合框架的整体流程如图3所示。匹配类特征点与未匹配的点构成的点集类似形状的刚性结构, 而形变特征点构成的点集类似形状的柔性结构。在匹配的两个形状柔性结构相似的情况下, 刚性结构能更好地表达类外相异性, 而在刚性结构相似的情况下, 柔性结构可以表达类内相似性。若能利用这两种不同结构的特性, 结合全局算法与局部算法的优势, 既能保证效果得到提升, 又能弥补二者的不足。为此, 本文为这两种结构选择了不同的算法来适应它们的特性。对于刚性结构, 采用BSM算法作为一种高效的全局算法, 其刚性网格的结构在处理刚性结构时被证明是有效且高效的手段。而对于柔性结构, SC算法作为一种有着众多改进的经典算法, 其采用的薄板样条模型(TPS)和粗直方图的统计方式, 能够更好地处理形变内容。
 | 图3 融合框架的流程图Fig.3 Flow chart of fusion framework |
在本文提出的框架下, 形变特征点的数量相对稳定, 其特征代价值的大小会刻画类内相似性。而总体数量同样稳定的匹配类特征点和未匹配点, 二者数量之间的此消彼长及特征代价值之间的对应改变会很好地刻画类外相异性。
BSM和SC这两种算法产生的形状特征直方图进行匹配时均可采用卡方系数:
式中:
根据卡方系数, 这两种算法产生的匹配代价可以用如下公式进行计算:
式中:
总的融合代价将根据对应点数的不同采取加权统计的方式(见式(3))进行融合, 根据融合代价值来衡量两个形状的相似性, 代价越低, 越相似。实验证明这种融合方式具有良好的效果和一定的扩展性。
式中:num_PointsMethod_A、num_PointsMethod_B分别为采用方法A和方法B的特征点数量; num_TotalPoints为总的特征点数量; CostA、CostB分别为方法A和方法B产生的匹配代价值。
为验证本文算法框架的有效性, 选取了MPEG-7数据库[17]进行实验。该数据库有1400个样本, 包含70个类别各20个形状。分别利用BSM、SC及本文提出的FBS(Fusion framework of BSM and SC)对MPEG-7中的数据样本进行靶心率测试, 该测试对数据库中的每一个形状进行检索, 计算在前40个最相近的结果中有多少个形状与检索形状是同一类别, 这个比值作为该形状的检索率, 而所有形状的检索率的平均值将代表整个数据库的检索率。
在该测试中, 为了验证本文框架的有效性, 对测试环境做了精简, 消除了一些优化方法对实验结果带来的影响, 仅对每个形状提取100个特征点, 并添加垂直和水平翻转预处理。对于BSM, 采用文献[17]推荐的16× 16个网格, 对于SC采用文献[9]中的朴素形状上下文距离Dsc, 而FBS将基于二者所采用的参数进行融合, 其中阈值
提出一种全新的融合框架, 相对于传统的融合算法采用复杂的数学理论和高维矩阵变换所带来的复杂性和依赖性, 本文所提融合算法具有较低的耦合性、更好的扩展性, 符合人类视觉习惯等特点, 使全局与局部算法能够更好地融合在一起。而全局与局部算法的改进众多, 为了避免各种优化带来的影响, 本文选取了最为基础且被人们广泛接受的两种算法, 并通过对数据集样本进行实验, 证明了本文所提框架能够有效地融合全局与局部形状识别算法。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|