西安电子科技大学 综合业务网理论及关键技术国家重点实验室,西安 710071
作者简介:李钊(1981-),男,副教授,博士.研究方向:宽带无线通信.E-mail:zli@xidian.edu.cn
基金:国家自然科学基金项目(61102057); 新一代宽带无线移动通信网重大专项项目(2012ZX03003005-005); 高等学校引智计划基金项目(B08038); 中央高校基本科研业务费项目(K5051301014)
中图分类号:TN929.5
文献标志码:A
文章编号:1671-5497(2016)05-1651-09
Priority queue based two-layer centralized spectrum sharing in cooperative cognitive radio networks
0 引 言随着无线通信技术的快速发展, 频谱资源短缺的问题日益凸显。根据美国联邦通信委员会(Federal communications commission, FCC)的调查报告显示, 3 GHz以下的频谱使用效率在15%~85%内, 而3~6 GHz的频谱利用率不足0.5%, 各种无线系统总的频谱利用率在10%以下[1]。相对于有限的频谱, 低频谱利用率造成严重的资源浪费。如何解决这一矛盾成为当前无线通信领域研究的热点, 认知无线电(Cognitive radio, CR)作为一项具有良好前景的动态频谱共享技术, 近年来受到了广泛关注[2, 3]。
在实际的认知通信中, 主用户发射机 可能距离其目的节点 较远, 或者收发端之间的链路被建筑物阻挡以及信号经历深度衰落等, 从而导致链路质量无法支持 至 的直接通信。该情况下, 主用户(Primary user, PU)可以招募符合条件的认知用户(Secondary user, SU)作为中继辅助其完成通信。作为对SU提供协助的回报, PU许可SU使用一部分通信资源, 如时隙、频道等, 以完成认知传输。上述场景称为协作认知无线网络(Cooperative cognitive radio networks, CCRN)[4], 通过设计相应的协作传输机制, 可以改善主用户的通信质量, 同时使认知用户获得通信机会。典型的时域CCRN方案[5, 6, 7, 8, 9]将通信过程划分为3个阶段。第1阶段: 将待传数据广播给参与协作的认知用户; 第2阶段:SU将信息转发给 第3阶段作为认知用户参与协作的回报, 用于SU的数据传输。相比于传统CR中SU检测频谱空洞并进行动态借用的方式, 上述机制通过在主次级用户之间建立协作关系, 避免了次级传输对授权通信的干扰; 同时, 认知用户能够以合法的方式(回报机制)获得通信机会。随着研究的深入, 通过多维信号处理手段, 如引入多输入多输出(Multi-input multi-output, MIMO)技术, CCRN的频谱利用效率还可以得到进一步提高[10]。
尽管上述方案能够实现主次级用户对通信资源的高效共享, 但仍然存在一些问题。首先, 主次级用户的数据发送被限制在传输周期的特定阶段, 业务到达的随机性可能导致某阶段的一部分甚至全部时间空闲, 造成资源浪费。其次, 现有的协作传输机制仅研究授权用户与参与协作的认知节点间的资源共享, 没有涉及未参与协作的认知节点的资源分配, 一方面参与协作的认知节点数量及其业务传输需求是随机且有限的, 作为回报的信道接入权限可能未得到协作认知节点的充分利用, 另一方面, 系统中大量未参与协作但有通信需求的认知节点无法接入空闲的频谱。对于该场景, 若每个认知节点采用传统的频谱感知和机会接入, 则可能产生冲突, 导致通信失败。因此, 如何实现CCRN中包括授权用户、协作认知用户(Cooperative SU, CSU)和非协作认知用户(Non-cooperative SU, NCSU)在内的多种类型节点的动态频谱共享是需要解决的问题。
此外, 现有工作中对频谱共享机制的性能分析主要针对吞吐量[5, 6, 7, 8, 9]。而在实际网络中, 时延也是需要考察的关键参数。在关于认知网络时延分析的工作中, 文献[11]将认知网络中主用户的业务建模成两状态交替的马尔科夫过程, 该模型适用于语音业务, 若应用于业务随机性较强的通信网络则会产生较大误差。文献[12]将业务分组到达节点的行为建模为泊松过程, 设计了协作频谱共享方法, 并运用具有优先级的M/G/1排队模型对时延性能进行分析, 但在所讨论的方案中, CSU在协助PU传输后与其他SU共同竞争信道, 没有获得应有的回报, 对于CSU而言并不公平。
综上所述, 针对已有频谱共享方案中主次级用户的传输时间分配相对固定, 以及协作认知场景中未充分考虑非协作认知节点的资源分配等问题, 本文提出了一种时隙型的基于优先级队列的两级中心频谱共享机制。主用户作为第一级中心负责中继节点的选择, CSU作为第二级中心, 在中转授权业务的同时还负责其他NCSU的有序接入。通过数据协作和管理协作, 实现多种类型节点的动态、高效频谱共享。
1 系统模型本文研究的协作认知无线网络(CCRN)包括一对授权用户( 和 )和若干认知用户对 。在 和 之间不存在直接通信链路。每个认知节点具有唯一的标识(ID)。所有节点的通信(包括信号发送与接收)半径相等, 遵循严格的时隙同步结构, 节点的分组到达服从独立泊松分布。时隙长度设定为一个分组的传输时间[13], 分组只能在时隙起始处进行发送, 所有节点的数据分组大小相同。控制信令通过独立的低速率信道传输。所有节点采用半双工通信模式, 网络的拓扑结构相对稳定, 信道具有准静态特征[13]。在 和 的重叠覆盖区域内存在一些认知节点, 它们满足成为中继的基本条件, 即对 和 均可达。 按照一定规则[14]从候选认知节点中选取一个作为中继协助其通信, 记为 。假设在 的覆盖范围内NCSU个数为 。 除了协助授权通信, 还负责协调这 个节点的通信。因此, PU拥有最高优先级, 次之, NCSU的优先级最低。考虑到 可以由认知发射节点( )或接收节点( )担任, 以下对这两种情况分别进行讨论。
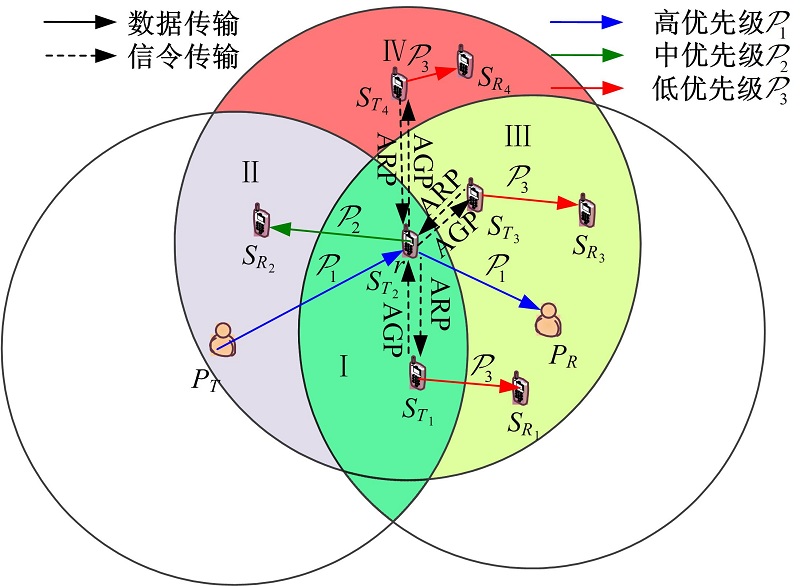
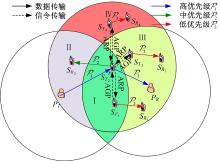
1.1 认知发射节点作为中继如图1所示, 以认知发射节点 被选作中继为例, 记为 区域Ⅰ 中的SU能够检测到 的发送, 并可作为中继, 该区域NCSU发射(如 )会干扰 接收来自 的信号和 接收来自 的中转信号。区域Ⅱ 中的SU能够检测到 的发送, 并位于 的覆盖范围内, 该区域的SU发射会对 接收来自 的信号造成干扰。区域Ⅲ 中的SU无法直接检测到 的发送, 其通信(如 )会干扰 接收 的信息以及 向 中转授权数据。区域Ⅳ 中的NCSU会对 接收来自 的信号产生干扰。 作为第一级中心从区域Ⅱ 中选取协作认知节点 , 作为第二级中心对其覆盖区域内的非协作认知节点进行管理和协调, 以避免SU对授权通信的干扰。
根据图1, 信息传输包括数据和控制两部分。数据传输包括4种类型: 以及 信令传输包括NCSU发送接入请求分组(Access request packet, ARP)和CSU反馈接入许可分组(Access grant packet, AGP)。分组传输的优先级由高到低分别用 和 表示。需要注意的是, 和 分别代表主用户业务传输的两个阶段, 二者的先后顺序固定且连续发生, 而对于其余两种数据传输, 由于不同节点业务到达的随机性, 按照本文设计的频谱共享机制, 不同类型的数据传输能够按照优先级灵活地接入信道, 即不一定按照图中所示顺序进行。
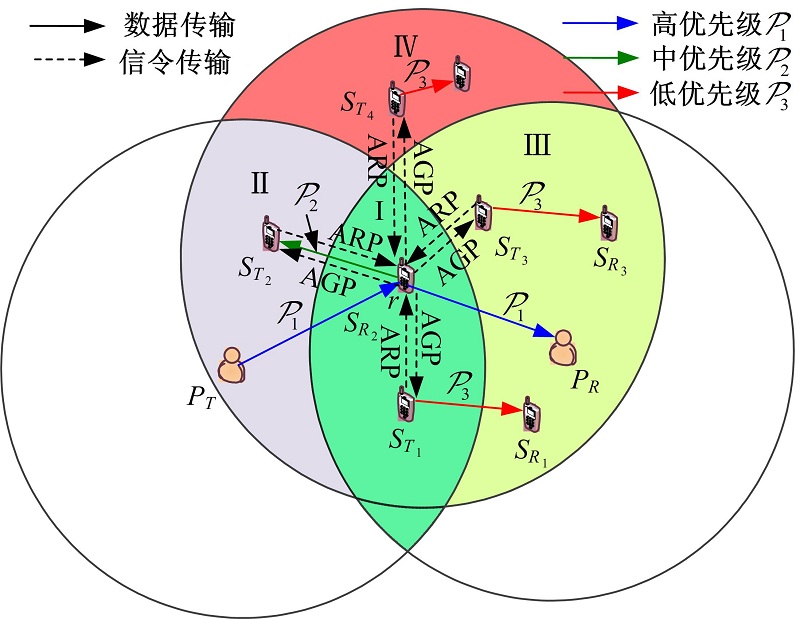
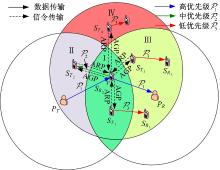
1.2 认知接收节点作为中继图2对认知接收节点作为中继的情况进行了示意。关于不同区域的讨论与图1相同。以 为中继为例, 作为协助授权业务传输的回报, 与 对应的发送端 将获得信道接入机会。此外, 作为第二级中心, 负责其通信范围内未参与协作但有数据传输需求的SU的接入控制, 情况与1.1节的 类似。在该场景中也包括4种类型的数据传输: 、 、 以及 。其中, 和 严格依序进行, 不同类型的数据传输的次序由信道忙闲、优先级和业务到达情况综合决定。
2 基于优先级队列的两级中心频谱共享(PQTL-CSS)2.1 协作认知节点的选取和更新2.1.1 CSU的选取
本文设计的PQTL-CSS规定由主用户发射机发起中继选择过程。首先, 向周围的认知节点广播中继招募请求分组(Relay recruit request packet, RRRP), 该分组包含目的节点 的信息。收到该请求并且愿意担任中继的SU发出协作呼叫请求分组(Cooperative call request packet, CCRP), 在其通信范围内寻找 当 收到来自中继认知节点(可能是多个)的呼叫请求后, 进行广播响应(Broadcast response, BR)。能够收到 的中继招募请求和 应答的SU具备成为中继的条件, 这些节点将其与 和 交互过程中检测到的信道状态信息, 连同 的响应封装在中继应答分组中上报给 最后, 根据获得的与候选CSU有关的链路状态, 按照端到端数据速率最大的准则[13], 即 确定协作节点 其中 表示候选中继节点, 和 分别为第1跳和第2跳的可达数据速率。
2.1.2 CSU的更新
本文假设网络拓扑相对稳定, 并且信道具有准静态特征, 因此中继更新的频率较低, 与其对应的操作所产生的时延可以忽略。 可以对现有的中继节点进行更新, 即 周期性地发起中继选择过程, 该时长的选取依赖于信道的变化。当 发现存在更好的中继时, 通知当前的中继节点( )解除协作关系, 然后与新的中继( )建立联系。另一方面, 当前的CSU也可以主动解除与PU的协作关系, 需主动向 发出解除协作关系的请求, 应答后随即发起新的中继选择过程。
需要注意的是, 随着CSU的更新, 其管理的NCSU也随之变化, 因此需要将 所维护的管理信息转交给 另一方面, 还需收集其管理范围内NCSU的信息, 从而实现次级管理节点和管理数据的更新。本文设计的PQTL-CSS规定 在解除协作关系前, 将其维护的NCSU的通信管理记录发送给 , 再由 将这些信息转发给新选定的 在完成管理数据的交接后, 旧的协作节点退出。接下来, 广播发送Hello分组, 其覆盖范围内的NCSU收到该分组后, 在返回的应答分组(ACK)中加入节点的编号(ID)、节点维护的自身通信记录, 次级管理中心根据这些记录可以实现NCSU的公平、有序接入(详见2.2.3节)等信息。 将收到的各NCSU的通信记录和从 获得的信息进行比较, 对管理数据库中没有的节点条目进行增加, 对具有相同ID的节点记录进行更新。为了控制CSU维护的管理数据库规模, 同时考虑到NCSU可能动态的进入或离开次级中心的管理, 可以为每一条用户管理记录增加一个生存时间, 每次记录更新触发生存时间的重置, 对超过生存时间的记录进行删除。为了简单, 本文假设所有NCSU上报的个人记录是真实可信的, 即不存在欺骗或恶意的NCSU。
2.2 不同优先级的数据传输控制2.2.1 PU的数据传输
主用户具有最高的优先级 , 在每个时隙的起始时刻只要 有分组到达, 便立即发送。授权分组的传输包括 和 两个阶段, 占用两个时隙, 其中 可以是认知发射机(图1中 也可以是认知接收机(图2中
2.2.2 CSU的数据传输
协作认知节点 首先对 的分组进行转发, 然后根据授权业务对信道的占用情况, 尝试自身数据的传输。由于主用户的优先级最高, 在每次发送(认知发射机作为 )或接收(认知接收机作为 )分组前, 先对信道进行检测, 当检测到信道空闲时才进行自身的数据传输。相比于NCSU, CSU具有更高的优先级 当CSU为认知发射机时, 其检测到信道空闲后即可发送数据。当CSU为认知接收机时, 与其对应的发射节点 有分组到达时, 需先向CSU发送一个接入请求分组(ARP)。若CSU检测到信道空闲, 并且收到来自 的ARP, 则向相应的 发送一个接入许可分组(AGP), 参与数据协作的认知节点随即开始自身数据传输。假设上述过程带来的时延相比于数据分组的传输足够小。
2.2.3 NCSU的数据传输
实际中有通信需求的SU可能较多, 如果不能得到合理的协调, 多对SU之间的通信将会相互冲突。在本文研究的系统中, NCSU具有最低的优先级 它们将在中继节点的协调下完成信道接入。为了实现空闲频谱的充分利用, 同时保证NCSU访问通信资源的公平性, 本文设计一种基于请求许可差的接入协议。
假设位于 覆盖范围内的NCSU个数为 每个节点具有唯一的ID, 记为 作为次级中心, 负责NCSU的接入控制。当NCSU有分组到达时, 先向 发送ARP, 若 检测到信道空闲并且自己也无数据发送, 则向该节点返回AGP, 获得许可的NCSU可以接入信道。控制分组ARP和AGP与IEEE 802.11中的RTS与CTS类似, 都属于短帧, 并且通过专用的低速率认知控制信道传送, 该控制信道可以通过规划一小部分专用频段来实现[15]。由于控制分组相比于数据分组长度很短, 因此控制分组的碰撞概率很低。并且考虑到控制分组碰撞出现在控制信道, 可以通过重发来弥补。因此, 本文忽略控制分组碰撞导致的时延增加。
为了保证NCSU访问信道的公平性, 每个认知节点维护1个变量 表示节点 发送ARP的次数与收到的AGP次数的差值, 该值越大表明用户的体验越差。本文假设全体NCSU具有相同的业务强度。为了实现由CSU控制的中心式调度, 维护所有SU的 NCSU更新 的过程为, 节点 发送一个ARP, 加1; 节点 从 处获得一个AGP, 减1。 更新 的规则与之类似, 当 收到来自节点 的ARP, 则与该节点对应的 加1, 当 向节点 返回一个AGP, 则 减1。此外, 规定NCSU向 请求信道时, 将 一起封装在ARP中发送, 将收到的信息与自身维护的信息进行比较, 对于用户上报值与 维护值的差异超过门限 的用户请求予以拒绝, 并从有效请求中选择 最大的用户, 将当前空闲时隙分配给该用户。 的引入能够防止信道差错或自私、恶意用户谎报 导致的通信资源分配错误, 但为了简化分析, 本文假设信道可靠且用户可信。若几个用户同时具有最大 则在这些用户中随机选择一个。 根据调度结果更新被调度用户的 收到AGP的SU也做相应更新。
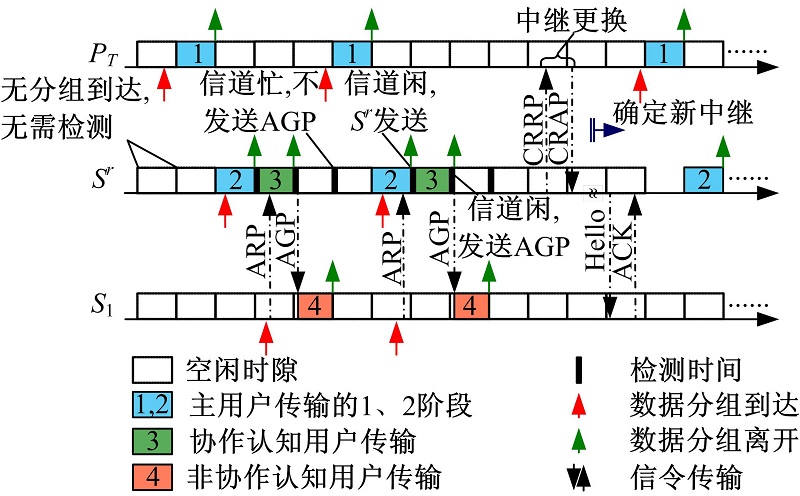
2.2.4 PQTL-CSS协议工作示例
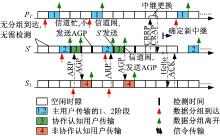
本节对所提协作频谱共享机制的工作过程进行说明, 对不同优先级的节点数据传输以及CSU的切换等操作进行了示意。如图3所示, 假设 已经与 建立了协作关系。首先, 有分组到达, 该分组在下一个时隙起始时刻发送给协作节点 即 接下来, 向 转发主用户分组, 即 图中以认知发射节点作为中继(对应图1中的 )为例进行叙述, 当认知接收节点作为中继时(对应图2中的 )情况与之类似, 区别仅在于认知接收机在使用空闲时隙进行通信前, 与其对应的 会向它发送APR进行接入请求, 而认知接收节点在检测到信道空闲后返回AGP来通知 可以开始数据发送。
在 中转主用户业务的过程中, 其自身也可能有分组到达。当中继工作完成后, 对信道进行检测, 若主用户没有新的数据中转要求, 即信道空闲, 进行自身数据的传输。在这一过程中, 若NCSU(如 )有分组到达, 它向 发送ARP。当 的分组传输结束, 并且检测到信道空闲, 向 返回AGP, 在下一个时隙发送自己的分组。
由于网络拓扑和通信过程的动态特性, 中继有可能需要更换。更新过程可以由 或当前中继节点( )发起。图中以CSU主动请求解除协作关系为例进行示意。 首先向 发送一个协作释放请求分组(Cooperative release request packet, CRRP), 并将自身维护的关于各SU的 信息一起发给 收到CRRP后返回一个协作释放确认分组(Cooperative release acknowledgement packet, CRAP), 于是 不再提供中继服务。同时, 发起新的中继选择过程。当新的中继节点( )确定后, 广播Hello分组, 收到Hello分组的SU返回ACK分组, 收到NCSU的ACK后, 按照2.2.3所述规则更新管理信息。接下来, 中转授权数据, 完成自身传输, 并负责其他SU的有序接入。
3 时延性能分析对于多个NCSU, 仅研究其整体的平均等待时延。假设各认知用户的分组到达相互独立且服从泊松分布。令PU、CSU和NCSU的分组到达率分别为 和 时隙用 表示, 且 忽略节点的处理时延。对于PU, 其分组传输包括两个阶段, 均需要 的时间, 总的服务时间为 对于CSU, 在忽略频谱检测时间的情况下, 每个分组的服务时间为 对于NCSU, 其分组服务时间也为 需要注意的是, 采用本文设计的机制, CSU负责信道检测和NCSU的接入控制, NCSU不进行频谱检测。在时隙的起始时刻, 若所有节点均没有分组发送需求, 则该时隙空闲。若多个节点同时有分组需要发送, 则根据优先级的高低进行协调。此外, 当高优先级的分组到达时, 若系统中有分组正在传输, 则高优先级用户不能够抢占信道, 需要等到当前分组发送完毕。因此, 本文研究的通信系统可建模为非抢占型多优先级且有休假的排队系统。
3.1 PU的平均等待时延主用户分组的平均等待时间 包括分组进入PU队列时当前分组(时隙被占用)或休假期(时隙空闲)的平均剩余时间 与其他已经在队列中等候的PU分组的服务时间之和。由于将时隙空闲作为休假, 休假期的长度为
使用 表示PU队列的平均长度, 可以得到:
式中: 为PU分组的服务时间。对于 , 当PU分组到达时, 它可能遇到两种情况:一种是PU的其它分组正在传输, 服务时间为 , 其平均剩余服务时间用 表示; 另一种是服务时间为 的SU(包括CSU和NCSU)分组传输或信道的休假期, 其平均剩余服务/休假时间用 表示。假设主用户的信道利用率为 , 有 可以得到PU分组到达后遇到其他PU分组正在传输的概率为 。平均剩余时间[16]为 其中 和 分别表示主用户服务时间的二阶矩、认知用户服务时间或者休假期长度的一阶矩和二阶矩, 可以得到 根据Little定理, 平均队列长度为 可以计算,
3.2 CSU的平均等待时延CSU分组的平均等待时延 包括以下几个部分:当前正在接受服务的分组或休假期的平均剩余时间 CSU分组到达时PU队列中高优先级分组的平均剩余服务时间 和CSU队列中分组的平均剩余服务时间长度 以及CSU分组在等待过程中到达的PU分组带来的等待时延 可以得到下式:
上式中 和 分别表示PU和CSU队列长度。对于 当CSU分组到达时, 可能有其它用户(包括PU或CSU)的分组在接受服务, 或者此时处于信道的休假期, 其中PU的分组服务时间为 其他情况均为 新到达的CSU分组遇到PU分组传输的概率和没有遇到PU分组传输的概率分别为 和 与3.1节 的分析相同, 可以得到
利用Little定理, 容易得到 和 的计算如下,
3.3 NCSU的平均等待时延NCSU的平均等待时间包括:当前正在接受服务的分组或休假期的平均剩余时间 NCSU分组到达时PU队列中分组的平均剩余服务时间 CSU队列中分组的平均剩余服务时间 和NCSU队列中分组的平均剩余服务时间 以及在NCSU分组等待过程中到达的高优先级分组带来的等待时延。可以得到的NCSU分组的平均等待时延表达式如下:
式中: 表示NCSU的队列长度。式(5)等号右端最后两项则分别表示NCSU分组等待时间内到达的PU和CSU分组导致的新增等待时间。根据Little定理, 的分析与 类似, NCSU分组到达时可能遇到两种情况:一是服务时间为 的PU分组传输, 二是CSU分组或NCSU分组传输服务, 以及休假期, 二者的时长均为 可以得到 的计算由式(6)给出:
4 仿真结果在模拟仿真中, 参照理论部分进行了一定的简化, 包括假设中继节点已经确定, 忽略检测时延和中继切换开销等。对于多个NCSU, 其分组到达服从泊松分布, 相互独立且强度相同, 本文将这些独立泊松源等效为一个合成泊松源, 对其整体时延性能进行仿真, 对于一个NCSU, 其等待时延为整体等待时延对NCSU个数取平均。PU和CSU的分组到达率分别为 和 NCSU合成的分组到达率为∑ λ ncs∈ [0, 1], 单位均为分组/时隙。等待时延的单位为时隙个数, 即对时隙长度进行了归一化, 在具体实现时可设置毫秒级的时隙大小。模拟仿真中根据不同类型节点的优先级协调其分组传输, 通过记录分组进入队列和开始接受服务的时间, 计算出每个分组的等待时延, 并通过多次仿真获得统计平均值。
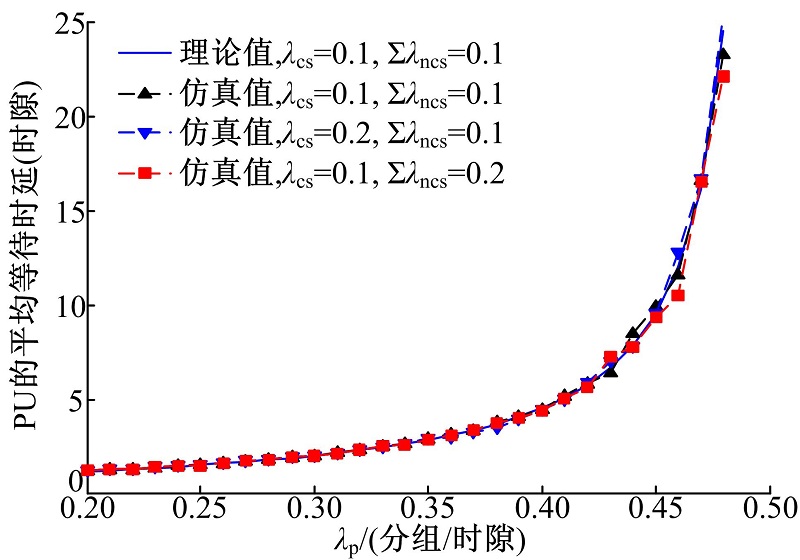
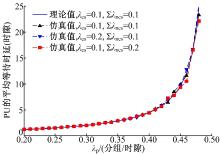
图4给出PU的等待时延随其分组到达率 的关系。根据式(4), PU的等待时延与 和∑ λ ncs无关。并且由图可见, PU的等待时延随着 的增加而增大, 由于所提机制能够保证PU的最高优先级, 授权传输不受认知业务的影响, 模拟仿真与理论计算结果拟合准确。
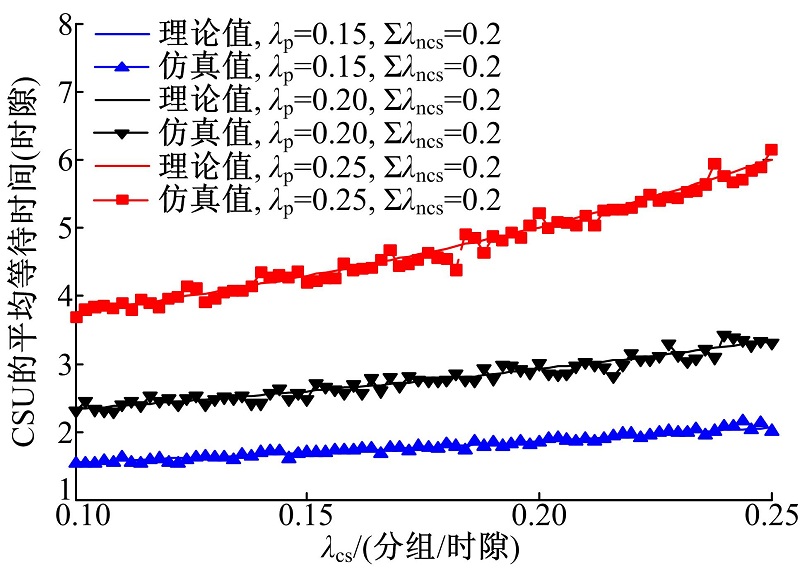
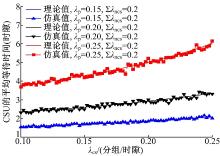
图5给出∑ λ ncs=0.2分组/时隙, 取不同值时, CSU的平均等待时延随 变化的情况。由图可见, CSU的等待时延随着 的增加而增大, 理论计算与仿真模拟结果拟合准确。由于主用户具有最高的优先级, 对于确定的∑ λ ncs, CSU的等待时延随着 的增加而增大。
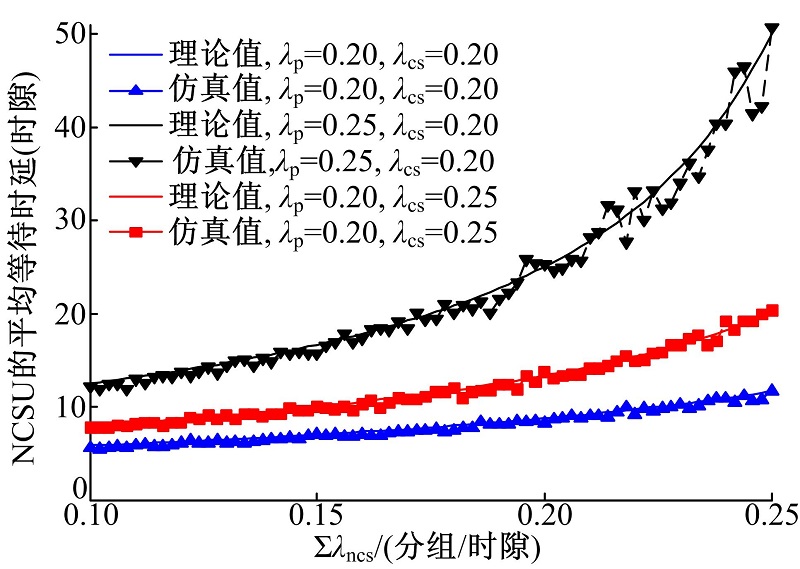
图6给出 和 取不同值时NCSU的等待时延随∑ λ ncs变化的情况。由图可见, 给定 和 , NCSU的等待时延随着∑ λ ncs的增加而增大。由于NCSU的优先级最低, 和 增大都会使NCSU时延增大, 并且由于PU的服务时间更长(两个时隙), 提高 对NCSU的时延影响更大。
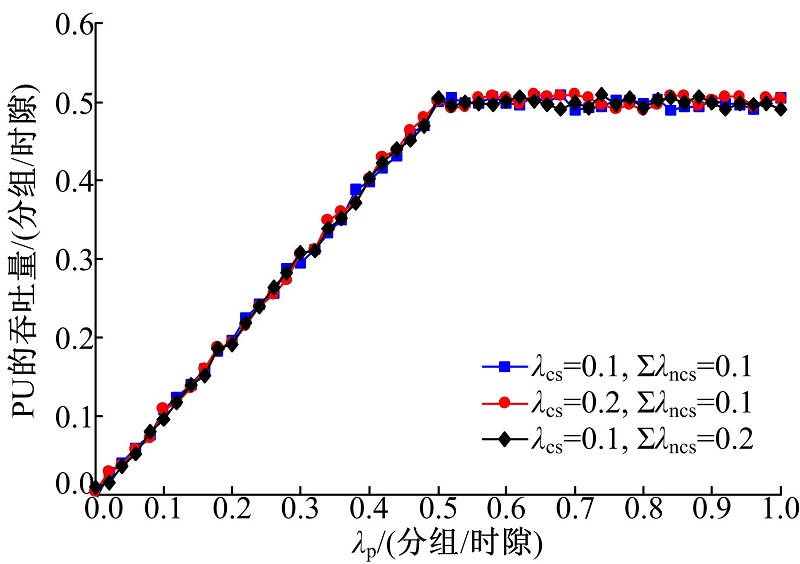
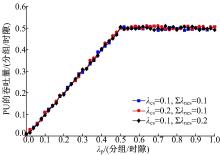
图7给出了PU的吞吐量与其分组到达率 的关系。可以看到, PU的吞吐量随着 的增加而增大, 当 达到0.5分组/时隙时饱和。这是由于一个时隙能够服务的PU分组数最多为0.5, 因此PU的吞吐量达到0.5分组/时隙后不再增加。由于所提机制能够保证PU的最高优先级, 认知业务分组的到达率不影响PU的吞吐量。
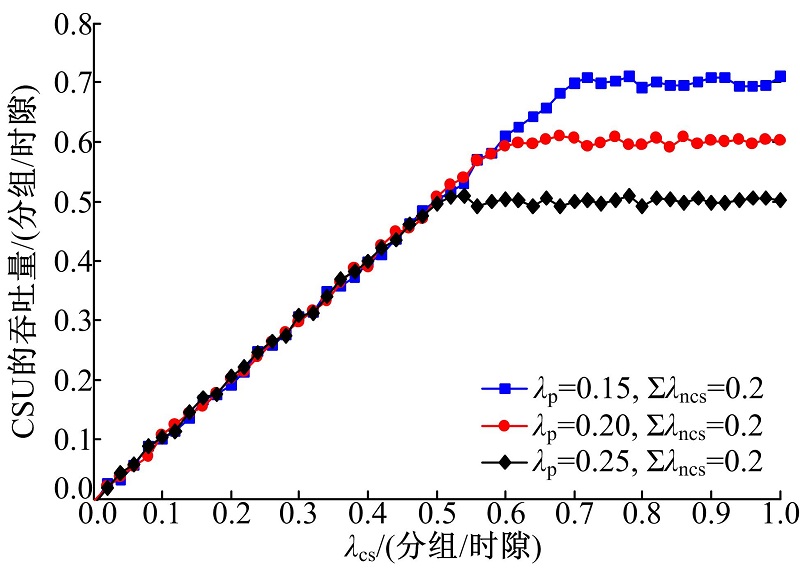
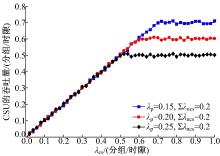
图8给出∑ λ ncs=0.2分组/时隙, 取不同值时, CSU的吞吐量随 变化的情况。由图可见, CSU的吞吐量先随着 的增加而增大, 直至达到饱和。由于PU的分组具有最高优先级, 并且其传输需占用2个时隙, 因此CSU的吞吐量上限为 所以, 当 为0.15分组/时隙、0.2分组/时隙和0.25分组/时隙时, CSU的可达吞吐量分别为0.7分组/时隙、0.6分组/时隙和0.5分组/时隙。由于PU具有最高优先级, CSU的吞吐量随着 的增加而减小。
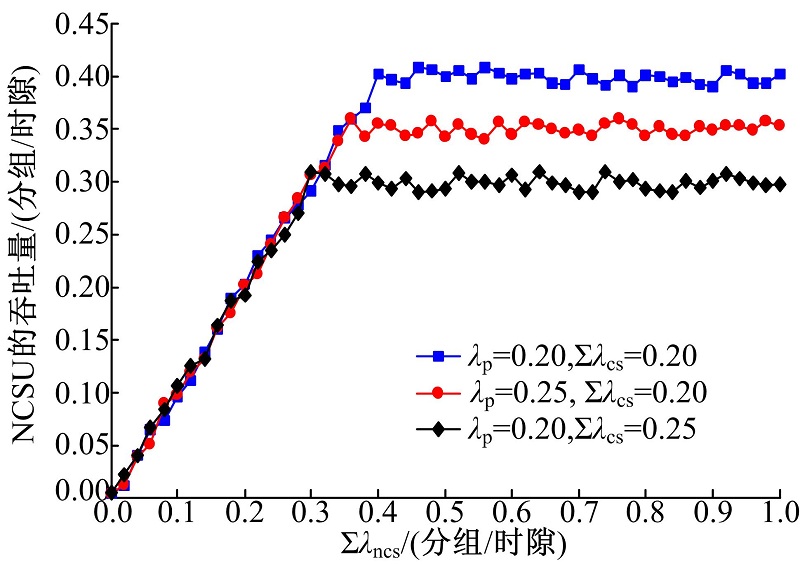
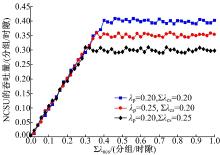
图9给出NCSU的吞吐量与∑ λ ncs的关系。可以看到, NCSU的吞吐量随着∑ λ ncs的增加而增大, 直至达到饱和。由于NCSU的分组优先级最低, 其吞吐量上限为 给定∑ λ ncs, 和 的增加都会使NCSU的吞吐量降低, 并且由于PU分组的服务时间更长, 因此提高 对NCSU的吞吐量影响更大。
5 结束语本文在协作认知无线网络中设计基于优先级队列的两级中心协作频谱共享方案(PQTL-CSS), 通过招募认知用户作为中继, 协助完成授权通信, 并将传统的数据协作拓展至管理协作, 形成由主用户和协作认知节点构成的两级中心管理结构。采用非抢占型多优先级且有休假的排队系统对网络中不同类型节点传输分组进行建模, 研究了用户的时延和吞吐量性能。所提机制能够保障主用户最高优先级, 以较高优先级的接入权限作为对协作认知节点的回报, 能够在业务随机性较强的情况下, 实现动态、高效的频谱共享。
The authors have declared that no competing interests exist.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 , 饶正发, 蔡沈锦]
, 饶正发, 蔡沈锦]