








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Kinect的深度图像修复方法
[吕朝辉 , 沈萦华, 李精华]
, 沈萦华, 李精华]
, 沈萦华, 李精华]
|
|


作者简介:吕朝辉(1975-),男,教授,博士.研究方向:图像处理和计算机视觉.E-mail:llvch@hotmail.com
提出采用基于权值的联合双边滤波器(WJBF)和深度补偿滤波器(DCF)相结合的方法对深度图像进行修复。首先,通过Kinect获得对齐后的彩色图像和深度图像;然后,利用基于权值的联合双边滤波器处理深度图像中的空洞和噪声;最后,用深度补偿滤波器减少边缘模糊。将本文算法与3种常用的深度图像修复方法进行了定性和定量上的分析和对比,实验结果表明,本文方法具有更好的修复效果。
A method is proposed to inpaint depth map, which combines the Weight Joint Bilateral Filter (WJBF) with Depth Compensation Filter (DCF). First, the color image and the depth map are aligned, and then the holes and noises of the depth map are filtered using WJBF. Finally, the blurs of edges are reduced using DCF. The proposed method is compared with three common depth map enhancement methods from qualitative and quantitative analyses. Experimental results show that the proposed method can achieve better performance.
近年来3D视频和立体成像技术得到了快速发展, 包含场景深度信息的深度图像在机器人导航和目标跟踪系统[1]、三维场景重建[2]和虚拟视点绘制[3]等领域中起到了关键的作用。与彩色图像不同, 深度图像的灰度值表示的是场景与摄像头的距离, 灰度值越大表示离摄像头越近, 反之则越远。当前深度图像的获取主要有两种方式:第一种方式是利用立体匹配算法[4]来获取深度信息, 即用双目相机拍摄场景信息, 得到左右图像, 然后通过计算左右图像的视差, 从而获取深度信息。其优点是深度信息获取效果好, 缺点是计算复杂, 而且费用较高。第二种方式是通过主动设备发射红外线测距来获取深度信息, 当前的设备主要有Time-of-flight(TOF)相机和微软的Kinect, 它们都能够很方便地同时获取彩色图像和对应的深度图像。优点是实时性好, 获取方便; 缺点是产生的深度图像往往会在前景和背景的接触边缘和遮挡处产生空洞, 这是因为在边缘部分物体的反射性往往发生剧烈的变化和遮挡导致反射光线被遮挡, 这两种情况导致设备不能正常接收反射信息, 从而降低了深度图像的质量。但是, 由于Kinect的价格比TOF便宜, 故使用Kinect获取深度图像变得越来越普遍。
目前的图像修复方法大致可以分为两类, 一类是通过彩色图像作为引导对待修复图像进行修复[5, 6, 7, 8], 但是该类方法通常没有充分考虑到物体边缘处深度不连续处空洞的修复, 并且往往会产生过平滑现象; 另一类是基于图像的几何模型完成修复, 属于偏微分方程的图像修复算法[9, 10, 11], 利用热扩散方程将待修补区域周围的信息传播到待修补的区域, 这类方法对小区域的结构和简单的问题具有较好的图像修复效果, 但是对存在大区域丢失的图像或纹理复杂的图像, 该方法的修复结果模糊, 效果不佳。因此, 本文提出利用基于权值的联合双边滤波器与深度补偿滤波器相结合的方法对深度图像进行修复, 并从定性和定量两方面与3种常用的修复方法进行对比。
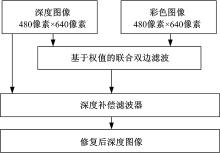
首先通过Kinect获得对齐的彩色图像和深度图像, 如图1(a)和图1(b)所示, 然后采用基于权值的联合双边滤波器修复原始深度图像中的空洞和噪声, 最后利用深度补偿滤波器减少深度图像中前景和背景交界处的模糊, 本文的算法框架如图2所示。
 | 图1 Kinect实时采集的数据Fig.1 Real-time Kinect data |
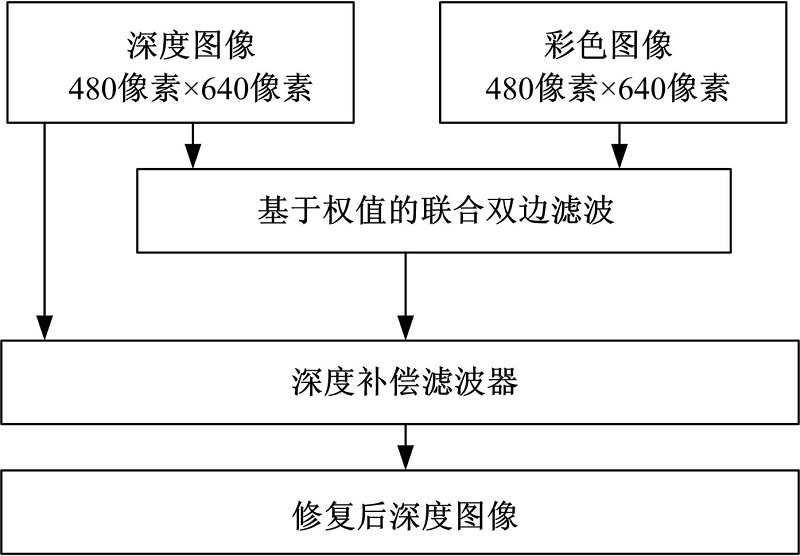 | 图2 本文算法框架Fig.2 Algorithm framework |
Camplani等[12]提出了联合双边滤波器方法, 本文在其基础上增加一个权值, 同时考虑彩色图像中的像素和深度图像中空洞点周围的有效像素对空洞点像素的影响。采用公式如下:
从式(1)可以看出, 如果
在权值图
式中:
空洞点的灰度值在某一个范围内, 可以求出该范围的阈值
原始深度图像的灰度直方图如图3所示, 从图中可以看出, 灰度值在0到75之间几乎没有像素点, 故本文中阈值
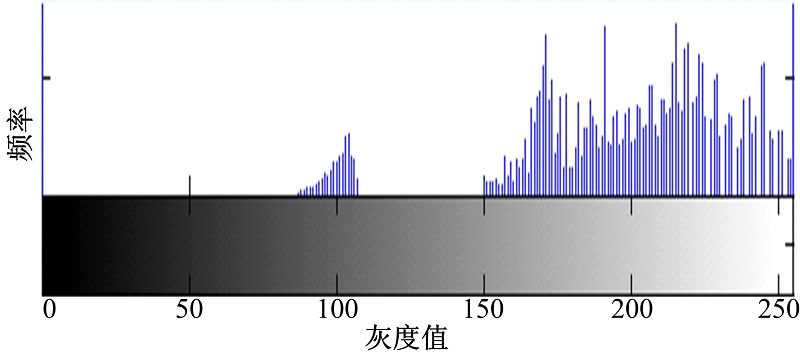 | 图3 原始深度图的灰度直方图Fig.3 Histogram for the original depth map |
图4给出了针对图1中图像的权值图和WJBF方法的修复结果。
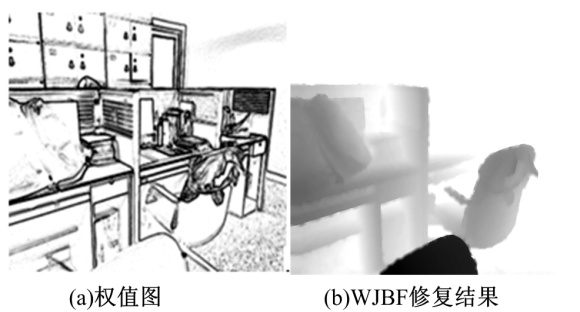 | 图4 权值图和WJBF修复结果Fig.4 Weight map and inpainting result by WJBF |
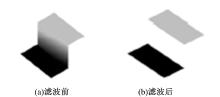
在平滑区域和前景边界周围, 由于前景深度值和背景深度值区别很小或者相差很大, 会产生轻微的模糊。另外, 在深度图像边界上通常既含有前景区域的深度值, 又含有背景区域的深度值。在修复的过程中采用的是平均值, 尽管深度图像上的空洞像素点能够被修复, 但是会导致深度图像中一些不存在的像素点出现。本文将造成的边界模糊假想为一个斜坡, 如图5(a)所示, 这种斜坡通常在实际环境中是不存在的, 这种斜坡应该被消除, 消除后如图5(b)所示。
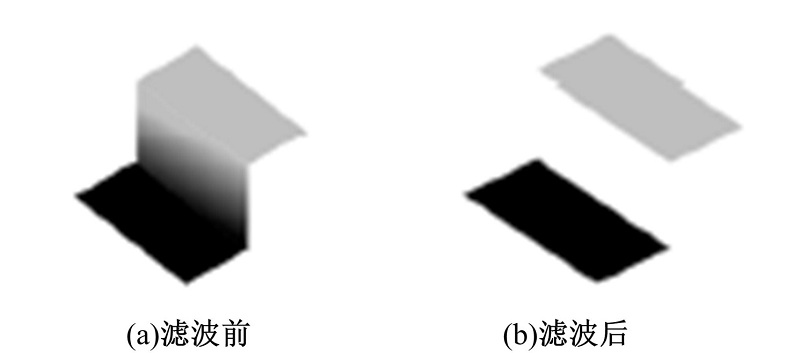 | 图5 深度补偿滤波器滤波Fig.5 DCF filter |
由于原始深度图像没有进行任何处理, 所以其边缘附近的像素点没有混合前景和背景深度值。因此, 可以用设计的滤波器将边缘上的模糊点用原始深度图像上的有效像素点的深度值与该边缘最近的深度值来替代, 从而进一步将边缘上的模糊移除。本文采用深度补偿滤波器进行处理, 公式如下:
式中:
将点
 | 图6 WJBF和DCFF修复结果Fig.6 Inpainting result by WJBF and DCF |
本文算法在VS2010平台上用C++实现, PC机性能参数为Intel i7920, 2.67 GHz, 四核处理器, 6 GB内存。为了验证本文算法的有效性, 通过与Izadi等[2]的双边滤波(BF)方法、Camplani等[12]的联合双边滤波(JBF)方法和He等[5]的导向滤波(GF)方法进行定性和定量对比。实验中基于深度图质量进行3个参数(
 | 图7 不同窗口尺寸修复结果Fig.7 Results of different window size |
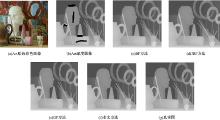
从定性分析上看, 本文采用2幅Berkeley 3-D Object数据库中的室内环境下的彩色图和对应深度图像进行实验对比。数据库里面的所有数据都是由Kinect采集并且每幅图像的分辨率均为480像素× 640像素。图8和图9为各种方法对深度图像的修复结果, 图10给出了图8中各方法针对局部标记区域的放大效果。通过对比可以发现, BF方法和JBF方法都会造成图像模糊, 并且修复深度图像周围会有毛刺, GF方法修复结果会在物体的边缘引起过平滑, 而本文的方法修复之后图像更加清晰, 并且在物体的表面光滑。
 | 图8 第一组Berkeley 的Kinect数据处理结果Fig.8 Results of Kinect data1 for Berkeley |
 | 图9 第二组Berkeley的Kinect数据处理结果Fig.9 Results of Kinect data2 for Berkeley |
 | 图10 图8中标记区域的局部放大图Fig.10 Zoomed image of marked region in Fig.8 |
本文选择Middlebury 2005数据库中的数据进行定量分析, 数据库里含有9幅彩色图像和对应的通过结构光获取的深度图像。从中选取Art和Moebius两幅图像作为测试对象, 将数据库提供的深度图像作为真实图, 为了能够进行定量分析, 在深度图像中人工添加一些噪声和空洞。本次实验中, 添加高斯噪声(均值为0, 标准差为3)到实际的深度图像中, 同时在该深度图像添加黑色的区域, 该区域表示没有深度值。本文将添加噪声和空洞后的深度图像作为待修复图像, 如图11(b)和图12(b)所示。各种方法的均方误差RMSE和峰值信噪比PSNR的结果如表1和表2所示, 通过表中数据对比分析可以看出, 本文方法具有更好的修复结果。
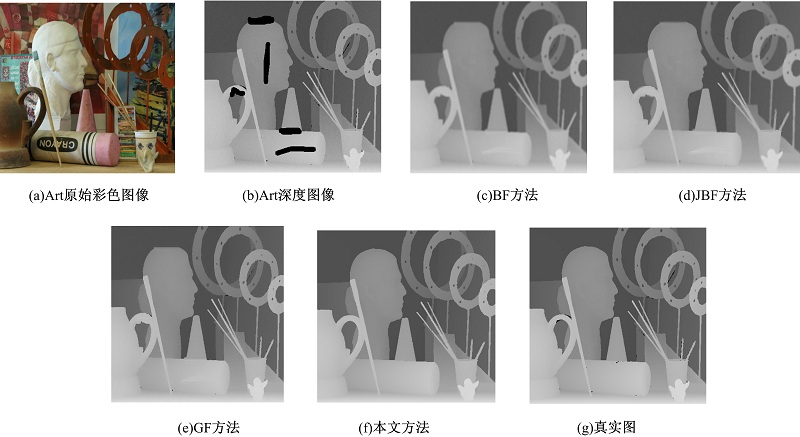 | 图11 第一组Middlebury的Kinect数据处理结果Fig.11 Results of Kinect data1 for Middlebury |
 | 图12 第二组Middlebury的Kinect数据处理结果Fig.12 Results of Kinect data2 for Middlebury |
| 表1 Art的RMSE值和PSNR值 Table 1 RMSE and PSNR for Art |
| 表2 Moebius的RMSE值和PSNR值 Table 2 RMSE and PSNR for Moebius |
提出了结合基于权值的联合双边滤波器与深度补偿滤波器的深度图修复方法, 完成了对Kinect深度图像的修复。实验中从定性和定量上进行了分析, 从定性上看, 经过本文方法修复之后的深度图像更加清晰, 并且边界处更光滑, 显示出较好的修复效果。从定量上看, 通过向实际深度图像中人工添加噪声和空洞, 从均方误差和峰值信噪比方面进行了对比分析。实验结果表明, 本文提出的方法可以对原始深度图像进行很好的修复。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|