

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于奇异谱分析和CKF-LSSVM的短时交通流量预测
[商强1 , 杨兆升1, 2, 3 , 张伟1, 2, 4  , 邴其春
, 邴其春1 , 周熙阳1 ]
, 邴其春|
|


作者简介:商强(1987-),男,博士研究生.研究方向:智能交通系统理论与技术.
为了提高短时交通流预测的精度,提出了基于奇异谱分析和组合核函数最小二乘支持向量机(CKF-LSSVM)的短时交通流预测模型。首先,采用奇异谱分析方法,滤除交通流序列的噪声成分。然后,使用降噪后的交通流数据训练CKF-LSSVM,并通过粒子群优化算法确定模型参数。最后,以厦门市的实测数据为基础,对预测模型进行实验验证和对比分析。结果表明:本文所构建模型具有较好的预测效果,能够有效提高短时交通流预测精度。
In order to improve the accuracy of short-time traffic flow prediction, a short-term traffic flow prediction model based on singular spectrum analysis and Combined Kernel Function (CKF) Least Square Support Vector Machine (LSSVM) is proposed. Singular spectrum analysis technology is used to filter out the noise of traffic time series. Then, the processed traffic flow data are used to train the CKF-LSSVM, and the parameters of the model are determined by particle swarm optimization algorithm. Finally, validation and comparative analysis of the model are carried out using the measured in Xiamen, China. Experimental results indicate that the proposed model has good prediction performance and can effectively improve the accuracy of short-time traffic flow prediction.
短时交通流预测是智能交通系统(ITS)研究的重要组成部分。实时、准确的短时交通流预测能够直接应用于ITS子系统中[1], 如先进的交通管理系统(ATMS)和先进的出行者信息系统(ATIS)。因此, 短时交通流预测受到了广泛的关注。已有文献提出了大量的短时交通流预测模型和方法, 大致可以分为3类:①基于交通流模拟的预测方法, 通过模拟交通流运行状态, 预测其未来的发展趋势。宏观交通流模拟是将交通流比拟成水流, 借鉴流体动力学的相关理论分析交通流。微观交通流模拟则考虑的是单车行为以及路网中车与车之间的相互作用[2, 3]。②基于统计学的预测模型。通过数据集的回归拟合和参数的选择优化, 以实现交通预测。例如:局部线性回归模型、ARMA模型和Kalman滤波模型[4, 5, 6]。③基于数据挖掘的预测方法。这类方法一般没有固定的形式, 而是以数据驱动, 通过智能算法寻找历史数据的变化趋势, 进而预测未来数据。例如人工神经网络和支持向量机[7, 8]。与前两类方法相比, 基于数据挖掘的预测方法没有对模型做出诸多假设(例如假设观测时间序列是平稳的, 残差服从正态分布, 预先给定模型的结构), 因而具有更好的适用性。最小二乘支持向量机(Least squares support vector machine, LSSVM)是支持向量机的一种改进形式, 学习速度更快[9]。然而, 在数据采集和传输过程中, 不可避免地受到交通检测器自身软(硬)件故障、外界环境异常(如电磁干扰)等因素的影响, 导致采集数据中含有噪声成分。如果将观测数据直接用于LSSVM的训练, 则一定程度上降低了模型的泛化能力。奇异谱分析(Singular spectrum analysis, SSA)是一种有效的降噪方法, 已在水文预测、电力负荷预测和天气预测等方面有了相关应用[10]。文献[11]使用多种方法处理GPS坐标数据, 结果表明SSA降噪效果优于小波和经验模态分解方法。
本文提出一种基于SSA和组合核函数最小二乘支持向量机(Combined kernel function least squares support vector machine, CKF-LSSVM)的短时交通流预测模型(SSA-CKF-LSSVM)。首先, 通过SSA将交通流序列分解和重构, 得到原序列的趋势成分、振荡成分和噪声成分。然后, 使用除去噪声成分的交通流数据训练CKF-LSSVM, 并通过粒子群优化算法确定模型参数组合。最后, 利用实测交通流数据, 将新建模型与其他模型的预测效果进行对比。
将长度为N的一维时间序列T=(x1, x2, …, xN)转化为一系列的L维向量:Xi=(xi, xi+1, …, xi+L-1)T。其中, L(1< L< N)称为窗口长度(Window length)。由K个向量Xi(i=1, …, K=N-L+1)构成轨迹矩阵X(L× K):
将X进行奇异值分解:
式中:S为矩阵X的奇异值, 等价于矩阵XXT特征值的平方根; U为X的左奇异向量, 等价于矩阵XXT的特征向量; V为矩阵X的右奇异向量, 等价于XTX的特征向量。
将时间序列T的元素由奇异谱分析展开:
式中:i=1, …, K; j=1, …, M; Ekj=U为XXT的特征向量, E称为时间经验正交函数; aik为通过式(4)求得的时间主成分:
xi的第k个主成分记作
根据式(6)选择对应较大奇异值的m个成分相加, 所得到
因此, 重构过程很大程度上滤除那些对应较小奇异值的噪声成分。
设D=(xi, yi), i=1, …, N为样本集, xi∈ Rm为输入; yi∈ R为相应输出。回归函数为:
式中:φ (· )为非线性函数; ω 为权向量; b为偏置量。
LSSVM回归的优化目标函数为:
式中:ei为误差变量; μ 和ζ 为可变参数; EW=
为了求解上述优化问题, 因此构建Lagrange函数:
式中:α i为Lagrange乘子, 由KKT条件可得:
式中:惩罚系数γ =ζ /μ 。消除ω 和ei后, 原优化问题变为:
式中:Ω ij=φ (xi)Tφ (xj)=K(xi, xj); l=[1, …, 1]T; α =[α 1, …, α N]T; Y=[y1, …, yN]T。
通过式(11)求出α 和b, 那么LSSVM回归模型为:
式中:K
多项式核函数为:
式中:q为参数。
RBF核函数在实际应用中最为广泛, 是一种典型局部核函数, 学习能力较强, 泛化能力较弱; 而全局核函数与之相反[12]。多项式核函数是常用的全局核函数。这两种核函数的有机组合能够提高LSSVM模型预测精度。因此, 本文模型采用多项式函数(Kpoly)和RBF核函数(KRBF)的线性组合核函数Kcom, 即:
式中:ρ 为参数。
组合核函数LSSVM参数包括:惩罚系数γ 、RBF核函数参数σ 、多项式核函数参数q和组合核函数系数ρ 。通过粒子群寻优算法(Particle swarm optimization, PSO)确定模型参数组合。PSO是一种启发式全局寻优算法, 其基本原理是:假设d维搜索空间中的第i个微粒的速度vi=(vi1, vi2, …, vid), 位置xi=(xi1, xi2, …, xid)。通过评价各微粒的适应度, 确定t时刻每个微粒所经过的最佳位置pi=(pi1, pi2, …, pid)和种群中已找到的最优位置pg=(pg1, pg2, …, pgd)。根据式(16)更新微粒的速度, 根据式(17)更微粒的位置:
式中:w为惯性权值; c1和c2为加速因子; rand为0到1之间的随机数, 通过设置微粒的速度区间
惯性权值w代表粒子前一次迭代速度对当前迭代速度的影响, 较大的w全局搜索能力较好, 而较小的w局部搜索能力较好。不断调整惯性权值, 符合算法进化特性。因此, 使用线性递减的惯性权值公式:
式中:wstart为起始惯性权值; wend为终止惯性权值; T为当前迭代次数; Tmax为最大迭代次数。
SSA-CKF-LSSVM模型构建和优化流程为:
Step1 采用奇异谱分析, 滤除原交通流时间序列的噪声成分。
Step1.1 嵌入:确定延迟窗口长度L。
Step1.2 奇异值分解:获得L个奇异值。
Step1.3 分组:将奇异值从大到小排序, 后面的奇异值较小, 且变化不大, 对应噪声成分。
Step1.4 对角平均:根据奇异值分组, 重构降噪交通流量序列。
Step2 使用降噪后数据, 构建训练样本集。
Step3 粒子群算法优化模型参数。
Step3.1 模型参数初始化, 粒子群参数初始化。
Step3.2 确定适应度函数。
Step3.3 计算并比较适应度, 更新微粒速度和位置。
Step3.4 满足停止条件, 输出模型参数。
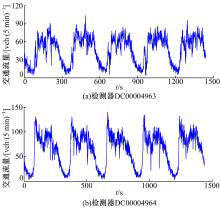
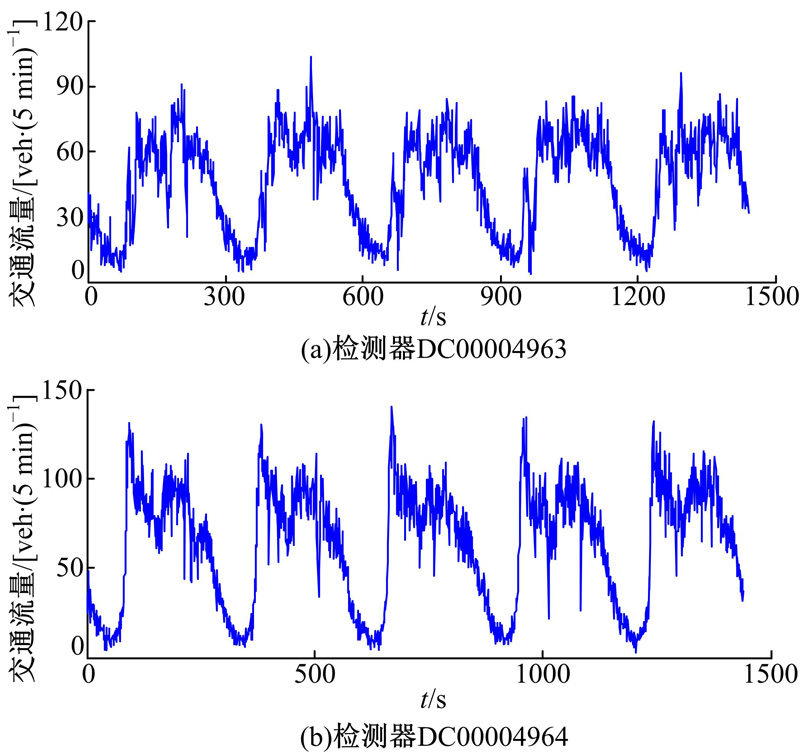 | 图1 交通流量时间序列Fig.1 Traffic flow time series |
数据来源于厦门市莲前西路的地磁检测器, 检测器统计时间间隔为5 min, 采集连续5个工作日(2015年1月5日~2015年1月9日)的交通流量数据。编号为DC00004963的检测器和编号为DC00004964的检测器分别采集由西向东和由东向西的交通流量数据, 所得交通流量时间序列如图1所示。前4天交通流量用于SSA-CKF-LSSVM模型的构建, 第5天交通流量用于模型预测效果的验证和对比分析。
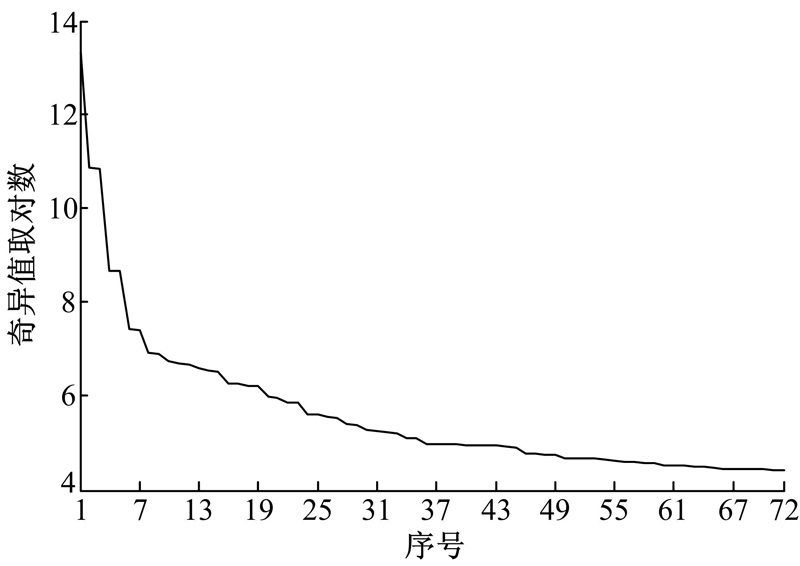 | 图2 交通流量序列的奇异谱Fig.2 Singular spectrum of traffic flow time series |
下面将以DC00004963号检测器数据为例详细说明模型构建和优化的过程。
在奇异谱分析中, 窗口长度L是唯一需要确定的参数。此处L取288, 即一天交通流量序列的长度。所得L个奇异值按从大到小顺序排列称为奇异谱。前72个(总共288个)奇异值按从大到小顺序排列的曲线如图2所示。从第36个奇异值开始, 后面奇异值变化缓慢, 因此36~288个奇异值对应着噪声成分。最大奇异值对应着趋势成分, 2~35个奇异值对应着振荡成分, 例如(2, 3)、(4, 5)、(6, 7)和(8, 9)等, 它们成对存在, 奇异值大小相同或相近, 也说明它们对应着振荡成分。
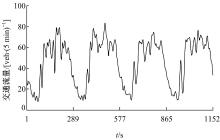
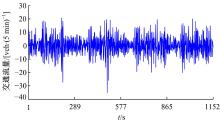
图3为前9个奇异值(特征三元组)对应的重构序列及其贡献率。第1~35个奇异值对应重构的序列如图4所示, 累积贡献率为98.390%。图5为第36~288个奇异值对应的重构序列, 即噪声序列。由图3~图5可知:第1个奇异值对应的重构序列为趋势成分, 贡献率为81.104%; 第2~35个奇异值对应的重构序列为振荡成分, 累积贡献率为17.286%; 第36~288个奇异值对应的重构序列为噪声成分, 具有较高的频率, 累积贡献率仅为1.610%。
 | 图3 前9个奇异值对应的重构序列及其贡献率Fig.3 Reconstructed traffic series of first 9 singular value |
将预测值作为模型输出, 预测值前两小时的交通流量序列作为模型输入, 以此实现交通流量的单步预测, 即使用历史数据滚动预测下一时刻交通流量。使用前4天SSA降噪交通流量数据构建训练集, 包括了1128组输入-输出关系。
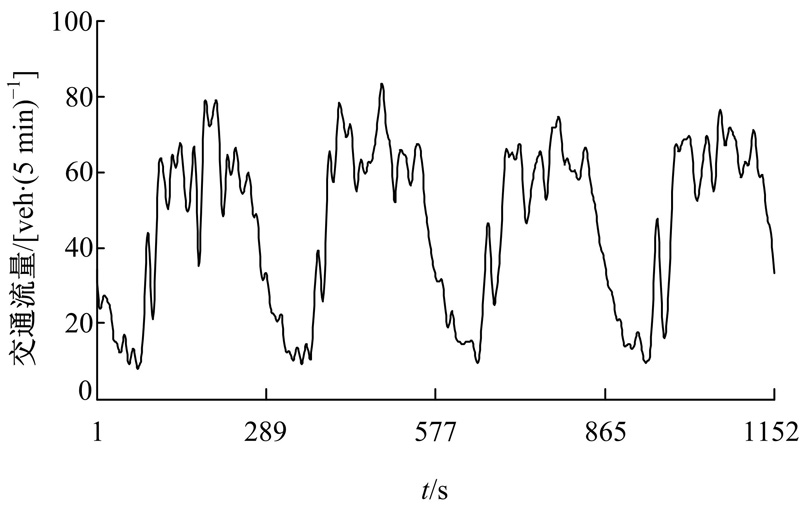 | 图4 重构交通流量序列Fig.4 Reconstructed traffic time series |
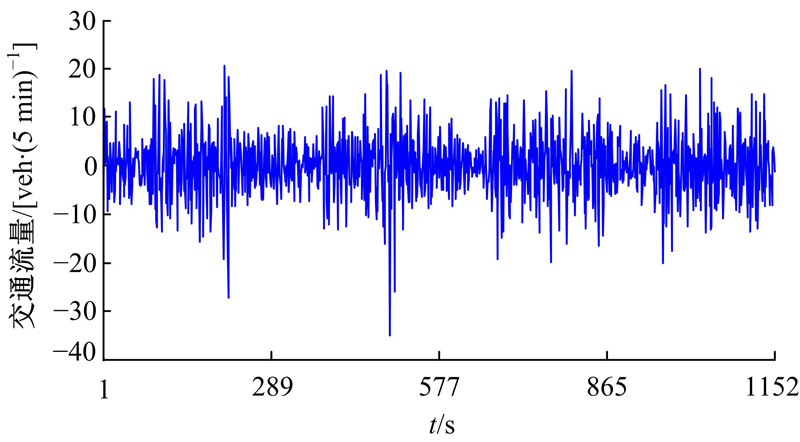 | 图5 噪声序列Fig.5 Noisy time series |
采用PSO算法优化模型参数, 包括惩罚系数γ 、RBF核函数参数σ 、多项式核函数参数q和组合核函数系数ρ , 共计4个参数, 即粒子群维数d=4。 设置种群数量为20; 加速因子c1=1.5; c2=1.7; 最大迭代次数为Tmax=100; 最大速度vmax=2; 起始惯性权重wstart=0.9; 终止惯性权重wend=0.4。模型参数:γ ∈ (0, 1000], σ ∈ (0, 100], ρ ∈ [0, 1], q∈
式中:
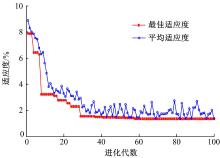
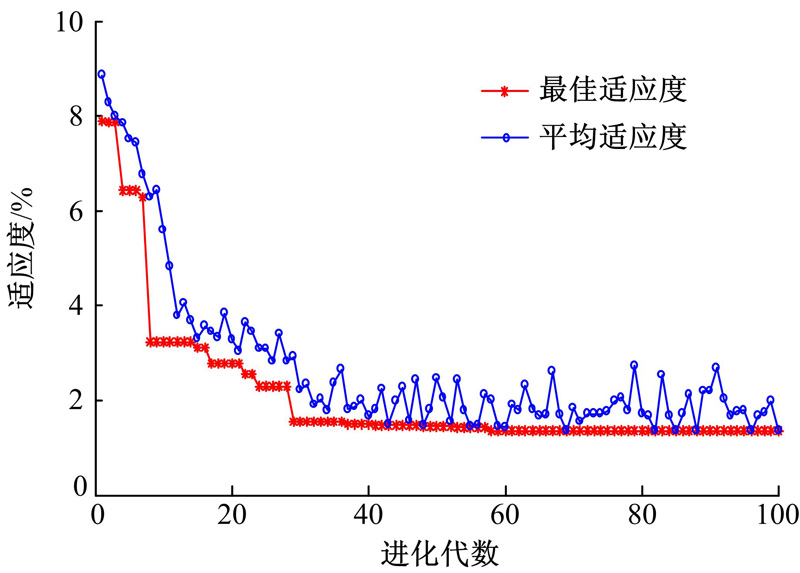 | 图6 PSO寻优适应度曲线Fig.6 Fitness curve of PSO |
为了更具有统计意义, 采用5折交叉验证, 完成模型训练和参数优化。图6为适应度变化曲线, 模型的优化参数组合:γ =76.63, σ =8.57, ρ =0.83, q=3。
为了更好地分析SSA-CKF-LSSVM模型的预测效果, 引入ARMA模型、CKF-LSSVM模型和SSA-BPNN模型作对比。其中, ARMA模型使用前提是预测平稳时间序列。对于非平稳序时间序列, 须要通过差分将其转化为平稳时间序列。其他几个模型均属于智能学习模型, 需要较多的训练样本。使用原始交通流量数据构建ARMA模型和CKF-LSSVM模型。使用SSA降噪后交通流量数据构建SSA-BPNN模型。其中, CKF-LSSVM模型参数的优化同样使用PSO算法。预测效果评价指标包括:平均绝对误差(MAE)、平均相对百分比误差(MAPE)、均方误差(MSE)和均等系数(EC), 计算公式如下:
MAE、MAPE、MSE越小, 说明预测误差越小, 预测效果越好。均等系数EC越接近于1, 说明预测值与实际值之间拟合度越好, 实际值与预测值之间有着更为相似的演化趋势。
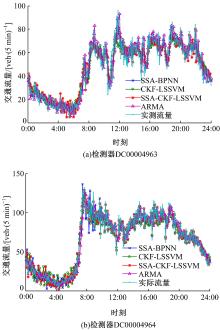
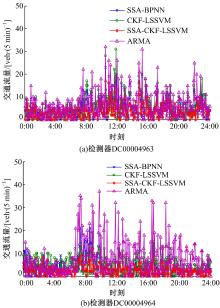
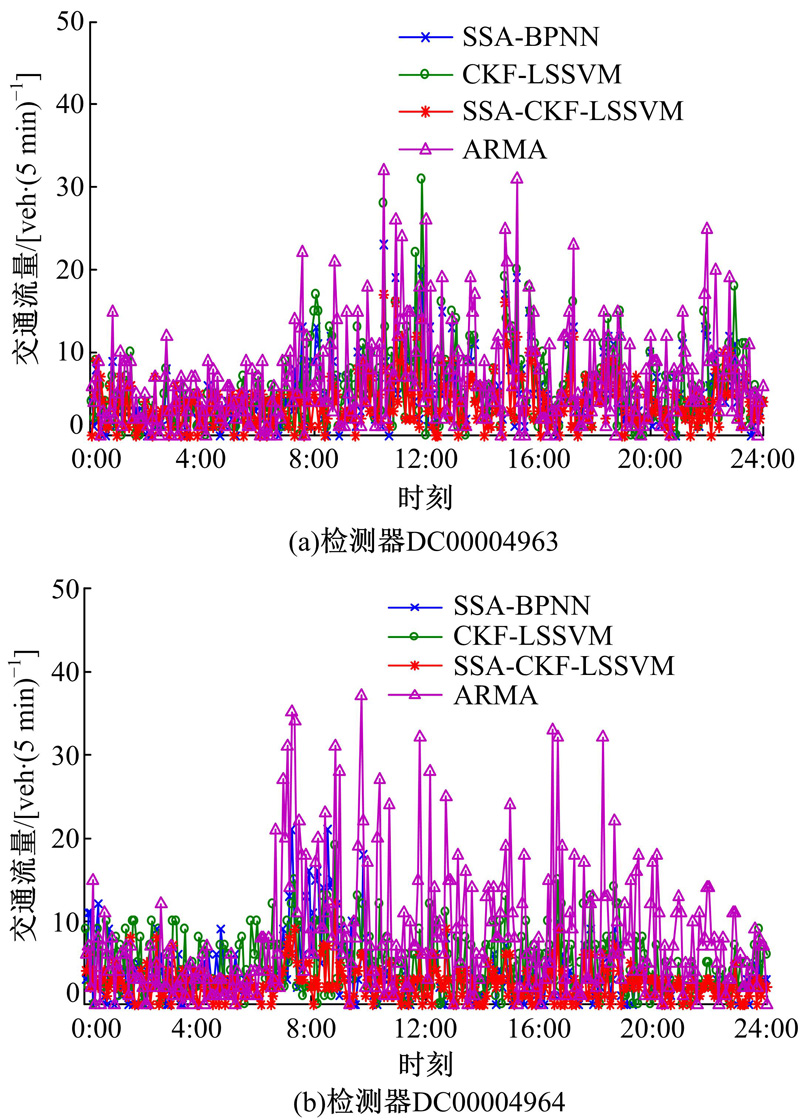
各模型预测效果曲线如图7所示, 绝对误差曲线如图8所示, 预测性能的评价指标值如表1所示。由图7可知, SSA-CKF-LSSVM模型预测曲线与实测曲线的拟合效果最佳; 模型的EC值为0.96(均值), 最接近于1, 同样说明拟合效果最佳; 而ARMA模型EC值仅为0.87(均值), 这是因为该预测模型具有一定的滞后性。由图8可知, SSA-CKF-LSSVM模型的绝对误差波动范围最小, 表明该模型预测稳定性较好, 特别是在交通流变化相对剧烈时(如7:00~9:00时段)。由表1可知, SSA-CKF-LSSVM模型的三项误差(MAE、MAPE、MSE)均低于其他模型。综上, 基于奇异谱分析和组合核函数LSSVM的预测模型预测性能良好, 能提高短时交通流量的预测精度。
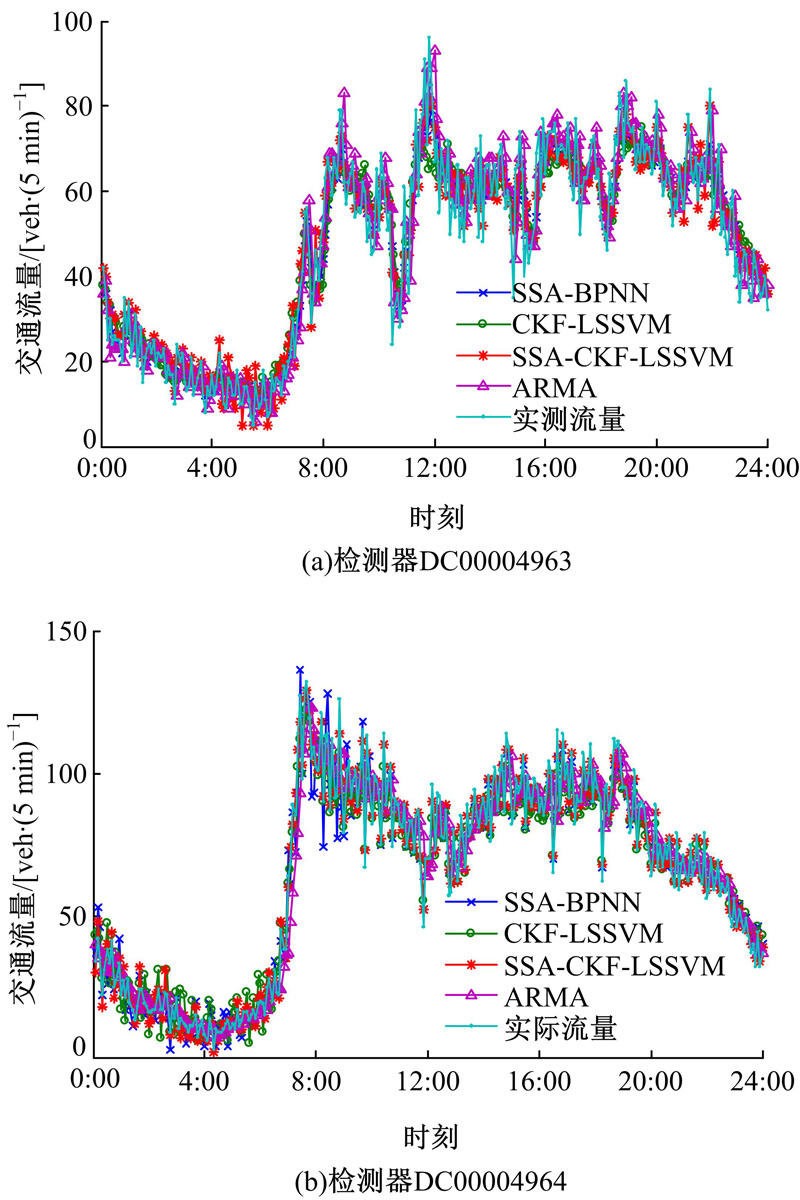 | 图7 各模型交通流量的预测效果Fig.7 Effect of traffic flow prediction models |
 | 图8 各模型预测的绝对误差Fig.8 Absolute error of traffic flow prediction models |
| 表1 各预测模型的评价指标值 Table 1 Performance comparison of prediction models |
针对交通流数据含有噪声成分, 短时交通流预测精度不高的问题, 提出了基于奇异谱分析和组合核函数最小二乘支持向量机的短时交通预测模型(SSA-CKF-LSSVM)。运用奇异谱分析方法, 将交通流时间序列分解和重构, 消除了原序列的噪声成分。使用降噪后的交通流数据对组合核函数最小二乘支持向量机进行训练, 并通过PSO算法确定模型参数。以厦门市莲前西路的实测交通流数据为例, 验证了新建模型的预测效果并与其他3种模型的预测结果进行对比分析, 结果表明新建模型预测性能良好, 能够有效提高交通流预测精度。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|