{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
支持大规模流数据在线处理的自适应检查点机制
[魏晓辉 , 刘智亮, 庄园, 李洪亮, 李翔]
, 刘智亮, 庄园, 李洪亮, 李翔]
, 刘智亮, 庄园, 李洪亮, 李翔]
|
|


作者简介:魏晓辉(1972-),男,教授,博士生导师.研究方向:分布式计算、集群计算和网络安全.E-mail:weixh@jlu.edu.cn
提出了一种支持流数据处理、在线动态调节周期的检查点机制。首先,面向突发性流场景,建立恢复时间计算模型,机制为节点故障提供最大恢复时间保障。其次,针对数据流实时变化的特点,提出检查点实时性代价量化模型。最后,设计流量高峰避让协议,基于检查点实时性代价判断,动态选取最佳检查点时机。对比实验结果表明:与传统检查点方法相比,该机制在灵活性和实时性方面具有明显优势,能够满足流数据处理高可靠性和实时性容错的要求。
A novel checkpoint mechanism is presented that can support stream data processing and online dynamic adjustment of the checkpoint period. First, for the data flow burst, we propose a recovery time model to provide guarantee for the recovery time. Then, depending on the real-time variation of workload, we provide a real-time cost model for checkpoint. Finally, the peak traffic avoidance protocol can dynamically choose the best checkpoint time by updating the real-time cost of checkpoint periodically. Experiments show that, compared with existing methods, our self-adaptive mechanism has obvious advantages in flexibility and real time, and it is able to meet the requirements of high reliability and real-time fault tolerance in stream data processing.
近期, 在互联网、金融、电信、医疗和交通等行业中, 对海量、高速的流数据进行实时处理和分析的需求激增。相关工作以早期流处理系统为基础, 发展成分布式流处理系统(S4[1]、Storm[2]、Samza[3]等), 具有较强的实时处理能力。随着分布式系统规模扩展、系统故障率攀升、可靠性问题加剧, 故障容错成为流处理领域中备受关注的问题。
传统的容错方法有检查点、副本以及记录/重演等方法。流处理系统的故障容错多基于传统方法的组合和扩展, 可分为活跃副本、被动副本和上游备份。伴随流数据在上、下游处理节点之间传输, 容错过程涉及节点的计算状态和数据状态的备份。由于活跃副本产生昂贵的资源开销, 检查点和上游备份方法结合是目前较为高效的容错方法:检查点定期保存操作节点状态; 上游备份维护数据队列, 下游节点检查点操作执行完毕后, 通知上游完成一次数据修剪[4]。
现有分布式流处理系统的检查点机制研究多基于传统分布式系统检查点方法, 难以满足流处理实时性要求。与静态数据相比, 流数据具有持续更新、时效性、突发性的特点。传统的检查点方案虽简单易行, 但是检查点时间间隔较为固定。由于缺乏系统的理论模型, 流数据来源和流速难以预测和判断, 尚无法定量分析检查点操作对流数据实时性的影响, 遇到流量高峰时执行检查点操作会严重影响处理实时性。因此, 固定周期的检查点操作并不适用于目前的流数据处理平台, 亦无法满足对延迟开销和恢复时间的合理均衡, 需进一步优化周期调整策略。
流处理作业同时具有数据状态和计算状态, 内存计算模式导致其持久化难度增加。节点的故障恢复时间取决于多种因素, 如上游备份队列长度和节点状态大小。由于流速动态变化, 伴随突发性流传递, 显然传统检查点方法难以为故障恢复提供时间保证, 上游节点可能因数据备份量过多导致容错负载过重而发生数据溢出, 用户更难以接受高流量负载下的故障恢复时间。
为控制对处理实时性造成的影响, 故障容错的开销和延迟均受到严格限制:既要保持较低的状态维护开销, 又要满足快速从故障中恢复运行的要求。针对以上问题, 本文提出一种可以在数据处理过程中自适应调整检查点周期的容错机制, 并进行了实验验证, 结果证明了本文检查点机制的灵活性和有效性。
随着分布式系统规模扩展, 系统故障率攀升, 可靠性问题加剧。由于流处理多不对数据进行持久化存储, 且目前大多数基于分布式流处理的应用平台都是有状态的, 分布式流处理系统迫切需要完善的故障容错支撑。因此, 相关工作开始密切关注分布式流处理系统的故障容错问题。
应用领域中, 针对应用要求, 活跃备份策略会导致实际应用产生较高的资源开销, 目前Spark Streaming[5]、TimeStream[6]、MillWheel[7]等具有代表性的分布式流处理平台均采用被动备份的容错策略, 定期执行检查点操作保存处理状态。但就发展情况而言, 这些流处理平台还存在一些不足:例如Spark Streaming虽然可通过并行恢复降低恢复时间, 但处理延迟问题依旧存在。
近期, 相关工作开始关注故障容错对处理实时性的影响。FTOps[8]以实时性作为约束条件, 通过对容错开销建模, 依据节点属性按需分配不同故障容错方案, 但其受限于特定的节点操作类型且不具备容错策略动态调整能力。相关研究也逐渐倾向于改善检查点操作对流数据处理延迟的影响。Sebepou等[9]提出将处理状态进行拆分的方法, 分别对拆分后的状态定期执行检查点操作, 增量式更新状态备份, 但该方法的有效性仅在聚合操作上进行了验证, 对现有分布式应用兼容性难度较大。还有一些研究讨论了不同检查点操作对流数据处理延迟的影响, 例如Castro等[10]在流速为1000 tuples/s时研究了不同检查点间隔对查询单词效率的影响, 指出了检查点间隔和恢复时间之间需要根据故障概率和性能指标进行权衡。目前, 相关工作并未针对流量动态变化场景开展研究, 且检查点周期的设置都不够灵活。因此, 本文提出的机制可更广泛地适用于流式计算场景, 能够有效减小处理延迟, 实现数据处理过程中对检查点周期的弹性调节。
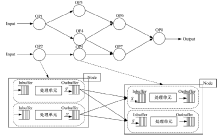
本节首先给出流数据处理的形式化模型。流数据在处理结构上具有灵活性、通用性的需求, 如图1所示, 将简单的模型扩展为较复杂的Jobflow工作流模型。该模型用DAG图G=(V, E)的形式表述流数据作业结构, 图中节点V表示数据操作, 边E流链接。
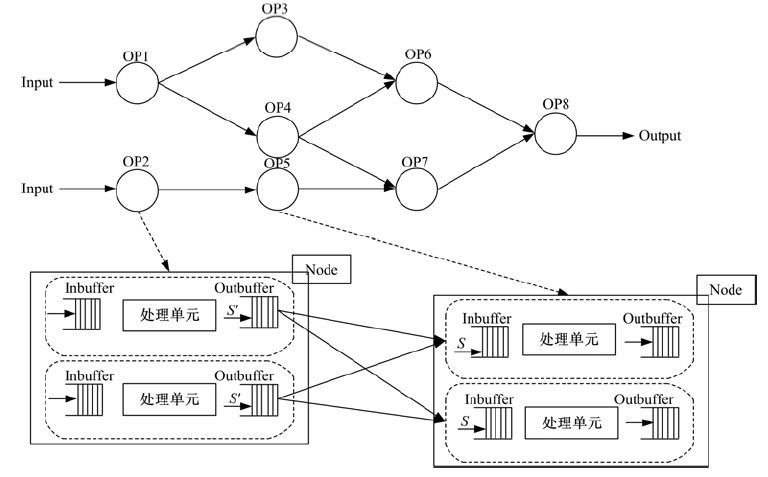 | 图1 流数据处理模型Fig.1 Streaming data processing model |
节点兼容并行计算模式。一次Jobflow被部署到每个节点上, 一个节点上可配置多个操作实例。模型结构参考图1, 针对单个节点, S对应一个数据输入流,
在线流数据处理方式相比传统MapReduce等离线数据处理平台更能适应流数据处理的特点, 由于每个处理单元可能具有多个前驱和多个后继, 容错场景趋向复杂。
数据流S实现节点间事件序列E的传送:E={τ 1, τ 2, τ 3, …}, τ ∈ S代表数据流中的一个元组/事件, 它是数据类型event的一种抽象表示形式;
本文采用被动副本的方式为系统提供节点级故障容错, 容错方案涉及计算状态和数据状态两部分。数据状态备份依托上、下游节点数据处理关系, 检查点操作实现运行状态的一致性更新。
2.3.1 数据状态维护
考虑每个处理单元可具有多个前驱和后继, 针对不同后继实现数据精准备份和过期备份按序删除, 引入数据矩阵表TableI和TableO, 描述如下:
(1)TableI:{
(2)TableO:{
伴随一次检查点备份操作, 处理单元依据TableI中
2.3.2 检查点状态备份
检查点状态备份记录处理单元当前计算状态和OutBuffer数据状态。作业运行期间, 系统为每个节点进行以下因素的调整和优化:①检查点周期:一个检查点周期完成一次运行状态的一致性更新, 即检查点操作和上游数据备份修剪。检查点周期决定状态备份的频繁程度; ②恢复时间:同检查点周期相关, 检查点周期长可导致恢复时间增长。同时, 流量动态变化对故障恢复时间变化程度有很大影响。
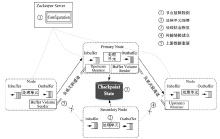
为提高恢复时间计算质量, 节点实时获取上游数据队列信息。如图2所示, 节点间建立了OutBuffer负载信息关联通道。各操作节点添加Buffer Volume Sender和Upstream Monitor模块, 用以协调节点间OutBuffer负载信息的同步和更新, 通过Socket机制进行消息通讯:
(1)Buffer Volume Sender
各数据输出流上分别对应一个Buffer Volume Sender, 其目标为计算OutBuffer对应各个后继的数据负载量。对于给定后继
式中:
处理单元将数据负载量封装到负载信息报文, 发送至后继的Upstream Monitor。
(2)Up Monitor
Up Monitor负责接收来自所有前驱的负载信息报文, 针对有
式中:
2.3.3 节点故障恢复
不同于活跃副本, 将各处理单元内存计算状态以检查点方式记录到外存, 进行持久化存储。节点故障发生时, 其他节点透明接管其数据处理任务, 恢复至故障前状态。故障恢复过程如图2所示, 可分为以下5个步骤:
(1)节点故障检测:系统使用Zookeeper[11]管理全局节点配置信息, 实现集中式的信息管理。依靠Zookeeper故障检测机制, 通过心跳观察系
 | 图2 故障恢复过程Fig.2 Fault recovery steps |
统中节点连接状况, 超过时间阈值
(2)处理单元部署:Zookeeper检测到某节点故障后, 系统立即在其他节点部署新的操作实例, 接管故障节点中各处理单元任务。
(3)处理状态恢复:从外存中读取最新的检查点文件, 通过反序列化操作进行处理单元状态重构。考虑实际故障概率较低, 通过记录检查点状态备份时间
(4)传输链接建立:依据拓扑结构, 重新确定上下游处理单元的分区和连接关系, 初始化数据传输链接配置。
(5)上游数据重演:处理单元状态恢复后, 上游节点依据TableO中event序列号信息重新发送event。数据重演时间
首先, 为快速适应流量变化, 机制分别提供数据准确性保障和恢复时间保障。其次, 介绍检查点实时性代价量化模型, 为检查点周期调整提供依据。最后, 提出高峰避让协议和自适应周期调整算法。
针对突发性流场景, 应避免流量高峰期间因容错负载过重导致节点内存溢出, 本文机制为数据的准确处理提供保证。
内存开销分为以下两个部分:①中间结果保存的内存开销, 通常可忽略该部分; ②数据维护产生的内存开销。伴随突发流的逐级传递, 可对各节点数据备份开销造成不同程度的影响; 下游节点检查点操作和故障停机期间, 会导致上游输出数据大量堆积, 也应该加以考虑。
综合考虑上述因素, 针对有
式中:
作业运行期间, 处理每个dw之前, 将Outbuffer实际数据负载量同数据溢出阈值进行比较:如
节点故障直接影响处理实时性, 用户对故障恢复时间有严格要求。针对突发流场景, 本文机制提供最大恢复时间保障。
故障恢复模型表明, 流量动态变化会对处理单元状态恢复和数据重演时间造成很大影响。在最大恢复时间要求thresrecov约束下, 为处理单元设定上游数据负载阈值
自适应检查点机制通过对恢复时间变化的实时分析, 为控制恢复时间提供支持, 按需修剪数据队列。
检查点期间要求节点中断数据处理过程, 需临时挂起作业, 直接影响处理延迟。不同流量负载下的检查点操作对处理延迟影响程度也不同。
由于检查点期间会继续缓存数据到InBuffer, 需考虑检查点对InBuffer中数据正常处理的影响程度。依据流量变化和数据实时处理情况, 量化检查点实时性代价。下面给出检查点数据覆盖量的定义:
定义 检查点数据覆盖量为某处理单元检查点期间因中断处理过程而影响到的数据量:
式中:
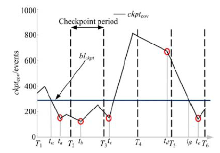
本节提出流量高峰避让协议, 描述检查点在线周期调整过程。基于传统周期性检查点, 协议通过检查点实时性代价判断, 在每个周期内选取最佳检查点时机, 减小数据处理延迟。协议规定, 各处理单元检查点周期的自适应调整过程均分为以下3个过程。
(1)伴随每一轮检查点周期开始, 首先进入高峰避让阶段。处理单元定期更新
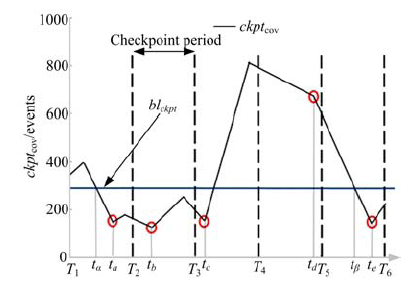 | 图3 高峰避让协议Fig.3 Peak avoidance protocol |
(2)进入检查点选择阶段, 节点选取最佳检查点时机。不同于高峰避让阶段, 更新
(3)高峰避让阶段, 如
从算法角度描述高峰避让协议规程如下:
Peak Avoidance Protocol
Whenever a dw is processed
(1)recov-guarantee()//数据准确性和恢复时间保障
Whenever entering a checkpoint period
(2)repeat//进入高峰避让阶段
(3)coverage-update();
(4)until a Checkpoint is complete
coverage-update()
(5)ckptcov← ckptcov_now; //更新ckptcov
(6)if ckptcov> blckpt then
(7) continue;
(8)else //进入检查点选择阶段
(9) checkpoint-select();
recov-guarantee()
(10)if(SumQSrecov-SumQS<
(11)Checkpoint;
checkpoint-select()
(12)ICR← ICR_now; //更新ICR
(13)if ICR< 0 then
(14)continue;
(15)else if ICR< 0 last until the checkpoint period is over // ICR持续为负至本轮周期结束
(16)Checkpoint;
(17)else //ICR为正, 执行一次检查点操作
(18) Checkpoint。
实验基于流数据处理系统原型SPATE[12](基于Hadoop1.1.2 version和S4实现), 使用吉林大学高性能中心计算8个技术节点。具体配置如下:操作系统为Redhat Linux version 2.6.32-358.el6. x86_64; CPU为16核 Intel(R) Xeon(R) E5-2670主频 2.60 GHz, 共计128个处理核心; 内存为32 G, 共计256 G内存; 计算节点之间使用千兆以太网互相连接。
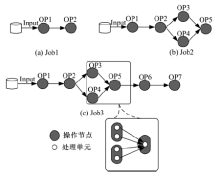
测试用例为图4中3个流数据处理作业, 连接方式如图所示。为便于问题说明, 每个物理节点上部署一个处理单元, 即一个操作实例。
 | 图4 测试用例模型Fig.4 Test case model |
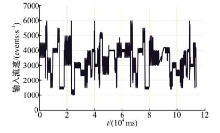
 | 图5 输入数据流速Fig.5 Used input data |
测试数据集为Twitter数据流(Followered user to following uer)子集(已经过隐私处理), 用于Twitter平台下数据分析实验, 分析用户间评论流向。图5表示数据输入速率随时间变化分布情况。流数据随时间变化明显, 于1000~6000 events/s之间不规则变化。实验采用具有该特性的数据流模拟流量变化场景。
用户要求最大故障恢复时间为3 s。检查点周期设定方式分别采用固定周期和自适应调节两种方式, 输入3种参数配置如下:①各操作节点均按照固定周期(9 s)执行检查点操作; ②各操作节点均按照固定周期(14 s)执行检查点操作; ③各操作节点均采用自适应检查点机制, checkpoint period为9 s。
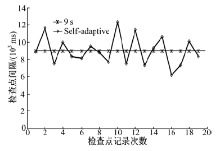
4.2.1 检查点周期对比
首先初始化图4中Job1作业, 测试记录对象为OP1, 分别采用①③两种检查点参数配置, 观察自适应检查点机制周期动态调整效果。针对节点每次检查点操作, 记录其与前一次检查点操作的间隔时间。从实验结果(见图6)可以看出, Self-Adaptive对应折线呈现连续波动。在固定周期基础上, 本文机制通过高峰避让协议, 使得节点具备了检查点周期调整能力, 流量的动态变化对检查点周期长短的影响比较明显。测试结果显示, 自适应检查点机制在周期调整策略上能够表现出更好的灵活性。
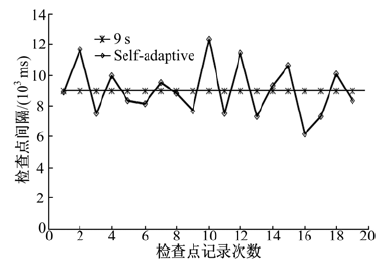 | 图6 检查点周期对比Fig.6 Comparison between checkpoint period |
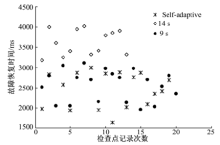
4.2.2 恢复时间对比
针对3种检查点参数配置, 在节点每次执行检查点操作之前, 会记录一次故障恢复时间。测试记录对象同样为OP1, 观察其故障恢复时间变化情况, 实验结果如图7所示。数据显示, 伴随数据输入流速变化, 虽然检查点周期固定为14 s时检查点执行次数最少, 但恢复时间较长; 相对14 s, 周期长度固定为9 s时可明显降低恢复时间, 但在流量高峰期间依旧无法保证最大恢复时间3 s的要求。
 | 图7 故障恢复时间对比Fig.7 Contrast of recovery time |
由实验结果可知:在适应流量变化方面, 自适应检查点机制能够表现出更好的鲁棒性, 减小延迟开销的同时为恢复时间和数据准确性提供可靠保障。
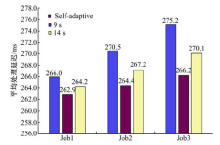
4.2.3 处理延迟对比
由高峰避让协议描述过程可以看出, 自适应检查点机制相比传统方法具有较低的延迟开销, 实验旨在验证机制降低处理延迟的有效性。
测试用例为图4中拓扑结构对应的3个流处理作业, 为每个测试用例分别输入3种检查点参数配置, 测试数据集大小为164 MB, 实验过程中记录event平均端到端处理延迟。
实验结果(见图8)可以体现, 3种检查点参数配置中, 自适应检查点机制的容错开销最小。依据流量变化调整周期长度, 能够在传统固定周期基础上控制最佳检查点时机, 保证各节点每次检查点操作的实时性代价最小。
 | 图8 处理延迟对比Fig.8 Contrast of processing delay |
实验结果同时表明:当操作节点数量很少时, 本文机制并没有体现出明显优势; 然而随着作业规模逐渐扩大, 数据处理链长度增加, 机制在减小延迟开销上的效果趋于显著。这是因为伴随数据流自上而下流动, 各节点采用本文机制能够减小对其上、下游造成的实时性影响。当在处理流程复杂的情况下, 机制进一步减小了延迟开销。
4.2.4 负载通讯开销测试
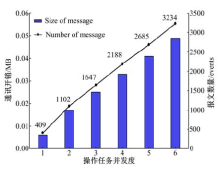
恢复时间预测要求节点间周期性进行负载信息通讯, 实验验证负载通讯开销是否受到操作任务之间的上下游关系影响。测试用例为图4中OP7, 通过改变OP6上操作任务并发度, 观察二者的负载通讯开销变化信息。
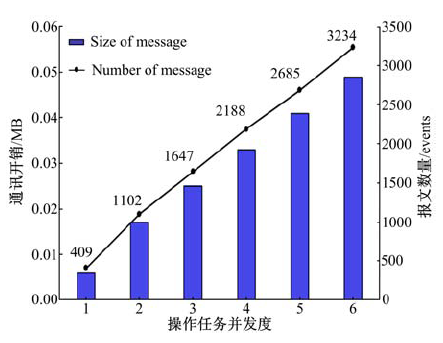 | 图9 通讯开销测试Fig.9 Test of communication |
实际恢复时间预测过程中, 处理单元间进行一次负载通讯产生的开销表示为:C=P• mmessage 。一个dw中包含event的数据量大小表示为:D=dw• mevent (dw≈ 1000~3000events)。当𝑑𝑤=1000、𝑃=100时, 𝐶同𝐷的比值仅为0.009。由此可见, 相比处理数据规模, 实际处理过程中负载通讯产生的资源开销很小。
首先介绍了现阶段流数据处理领域的常用容错策略和研究现状。通过分析流式计算相关特性, 总结了传统检查点机制在流量变化场景中实时性和周期可调整性方面的不足。针对以上问题, 提出了支持动态调节检查点周期的容错机制, 在保证恢复时间的同时减小了数据处理延迟。建立负载关联通道, 实现恢复时间预测。给出检查点实时性代价量化模型, 提出高峰避让协议。最后, 通过实验验证了机制的有效性和合理性。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|