



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
适用于商用系统环境的低开销确定性重放技术
[应欢1, 2  , 王东辉
, 王东辉1 , 武成岗3 , 王喆2, 3 , 唐博文4 , 李建军3 ]
, 王东辉, 武成岗|
|


作者简介:应欢 (1988-),女,博士研究生.研究方向:并行程序,动态优化.E-mail:yinghuan1022@126.com
针对现有确定性重放技术中存在运行时开销大和安全隐患等问题,提出了一种低开销的确定性重放技术。该技术在已有的硬件平台和系统环境下,利用页保护捕获并记录并行程序对共享内存的访问顺序。深入研究了该技术引入的性能开销,针对性地提出了私有锁、私有堆、主动抢占等优化策略。采用PARSEC测试集进行性能评估,实验结果显示该系统引入的开销较小。
Deterministic replay plays an important role in debugging parallel programs. In parallel program design, recording share memory access has become a light spot, according to great non-determinism brought by multithreading memory interleaving. Previous research focused on fine grained instrumentation of memory access instruction, or kernel modification, or special hardware extension to record shared memory communication. However, these methods have the problems of runtime overhead cost and awful potential safety hazard. This paper proposes an efficient deterministic replay technique employing page-protection mechanism on commodity hardware platforms and operating system. Furthermore, this work deeply analyzes the runtime overhead incurred by the proposed technique, and puts forward several optimization strategies of private-lock mechanism, private heap memory pool and initiative page-preemption algorithm to promote the performance. Our prototype UPLAY is implemented on Linux. Performance evaluation shows that the record slowdown is only 9.26X and is much smaller than prior user-level replay system.
随着多核处理器的流行, 并行编程成为多核平台上最有效的编程方式[1], 是未来软件开发的主流趋势。相比传统的串行程序, 并行程序具有不确定性。因此并行程序在运行过程中产生的错误, 在调试过程中很难重现。在这种情况下, 串行程序中常用的循环调试技术已不再适用, 这使得并行程序的调试变得极为困难。据调查, 调试一个并行程序的错误, 平均需要73天[2]。相比串行程序, 并行程序的开发给程序设计者带来了巨大的困难。为了解决并行程序的不确定性给调试者带来的困难, LeBlanc等[3]首次提出了确定性重放技术:程序在运行过程中, 在日志文件中记录导致程序不确定的因素(结果不确定的系统调用和特殊指令、信号、共享内存的访问等)。当需要进行调试时, 强制程序按照所记录的日志执行, 这样程序就能够反复重现之前的执行, 方便调试人员调试。
目前, 确定性重放技术的研究主要集中在如何高效地记录并行程序对共享内存的访问上[1]。文献[3, 4, 5]通过对访存指令进行插桩(记录该次访存相对于上次访存的顺序), 运行时记录共享内存的访问顺序。这类方法虽然能够实现并行程序的确定性重放, 但是由于每条访存指令都需要执行额外的插桩代码, 因此该类方法运行时开销大。从文献[3, 4, 5]提供的实验数据来看, 这些方法比本地执行性能下降了15~80X。
文献[6]改变了共享内存访问顺序的记录方式, 它不再插桩记录每次的访存操作, 而是利用页保护机制, 通过限定每个线程对内存页的访问权限捕获并记录所有线程对共享内存的访问顺序。SCRIBE利用CREW(Concurrent read exclusive write)协议[7]管理每个线程对共享页面的访问权限。CREW协议规定了任意时刻, 每个共享页面所处的状态:无人访问的公共状态(Public), 多个线程共享的读状态(Shared Read), 单个线程独占的写状态(Owned write)。如果某个线程独占一个内存页, 其页表中相应页表项(Page table entry, PTE)设置为可读写权限; 如果某个线程共享一个内存页, 则其PTE设置为只读权限; 否则PTE设置为无效。为了限定每个线程对同一个内存页拥有不同的访问权限, SCRIBE通过修改操作系统内核, 使每个线程具有私有页表。根据作者提供的数据(对于服务器应用程序, 记录开销小于2.5%)来看, 该方法是目前性能最好的确定性重放技术。然而, 对操作系统内核的修改可能引入以下几个问题[8]:①需要重新修改和编译内核, 可移植性较差。从Linux 2.0版本以后已经发布了47个内核版本, 如果将SCRIBE应用于这些新发布的Linux内核中, 需要针对每种内核版本进行单独修改、编译, 工作量大。②需要具有丰富内核开发经验的并行程序设计者, 对开发者要求严格, 开发周期长。③存在安全隐患。系统设计人员将操作系统划分为用户态和内核态, 其目的是通过内核态的保护机制, 提升系统的安全性。然而, 从2013年1月到2014年11月CVE(Common vulnerabilities and exposures)[9]公布的306个Linux内核漏洞中, 112个来源于Linux内核核心, 194个来源于内核模块或驱动。为了保障系统内核的安全性, 系统厂家和最终用户都不愿为支持某些特定功能而对系统内核进行修改。因此, SCRIBE的应用受到了严重的限制。
为进一步降低记录开销, 部分研究工作探索以牺牲记录信息的准确性为代价来换取性能。它们只记录部分访存操作的顺序, 通过多次重放执行收敛不确定性执行的概率空间, 来重现并行程序的执行, 典型的工作有文献[10-12]。这些方法中, 记录的粒度越粗, 开销就会越小。然而, 这些方法不能重现错误的概率也会越大(对共享内存操作记录不全)。另外, 文献[13-16]试图通过在处理器中添加特殊的硬件来降低记录日志引入的开销, 这些方法虽然取得了较好的效果, 但尚未得到商用处理器的支持。
为了使程序开发人员能较方便地调试并行程序, 需要一个适用于商用系统环境(不需要额外硬件支持、不需要修改操作系统内核, 就可以在现有商用处理器、操作系统上直接运行)的低开销确定性重放系统。对此, 本文提出一种低开销确定性重放技术, 该技术同样利用页保护捕获并记录共享内存的访问的顺序, 且无需修改操作系统内核。在当前操作系统中, 同一个进程中的各个线程共享同一个页表。为了使不同线程对同一个内存页具有不同的访问权限, 将多线程程序转化成多进程程序, 利用进程的私有页表特性来控制每个线程对共享内存的访问权限。为了进一步降低性能开销, 本文进行了深入的分析, 并给出了相应的优化策略。基于该技术, 本文实现了一个原型系统— — UPLAY, 并采用PARSEC测试集进行性能评估。实验结果表明:相比其他用户态下的确定性重放技术, UPLAY的性能开销较低。
现代操作系统设计广泛采用虚拟存储技术。该技术通过采用页表机制(为每个进程维护一张页表)使得每个进程具有完整独立的虚拟地址空间。该页表不仅记录了进程虚拟页(虚拟地址)到物理页(物理地址)的映射关系, 还记录了每个虚拟页的访问权限。如果程序运行时所请求的页面访问权限与页表中记录的权限不一致, 就会触发页保护异常。因此通过取消某一虚拟页的访问权限(设置为不可读、不可写, 并且不可执行), 就能捕获该进程对该虚拟页的访问。
页保护机制广泛应用于分布式共享内存、数据竞争检测等领域[17]。UPLAY利用页保护机制来监测和控制并行程序中线程对共享内存的访问顺序。通过把所有线程共享内存区域设置为不可访问权限, UPLAY能够监测到这些线程对共享内存的访问, 最终将这些访问顺序记录下来。相比记录所有访存指令的顺序, 以页为粒度的记录方式减少了所需要记录的信息。然而, 对于并行程序而言, 所有线程使用同一张页表。如果为一个线程将某个内存页的访问权限设置为可读不可写状态, 那么其他线程也只读访问该内存页。SCRIBE[6]通过修改操作系统内核解决了上述问题, 使得每个线程私有一张页表。
为了避免修改内核, 本文希望在已有的系统环境下, 支持每个线程能够对同一个内存页设置不同的访问权限。由于进程间的地址空间独立, UPLAY利用进程的私有页表特性, 将并行程序中的每个线程由进程替换(在下文中, “ 线程” 特指UPLAY中并行程序中被替换成进程的线程)。
在现代操作系统中, 同一进程创建的多个线程间共享虚拟地址空间、文件描述符等资源。UPLAY通过截获并行程序中的线程创建、回收函数, 将创建、回收线程变为创建、回收进程, 并使得进程间共享文件描述符表、文件描述符等, 将多线程程序变为多进程程序, 所有的“ 线程” 具有独立页表。
在写时复制(Copy-on-write, COW)技术中, 进程创建时父子进程共享地址空间, 当进程中出现写操作时才为子进程分配新的物理页。因此, 线程变进程后, 原线程间共享内存被破坏。UPLAY利用进程间的共享内存机制, 将不同进程的虚拟页映射到相同的物理页, 模拟原并行程序通过共享内存进行数据交互。
并行程序在执行过程中, 对共享内存的访问具有不确定性。共享内存对并行程序中的每个线程来说都是一种共享资源。如果在执行过程中每个线程能够按照某种约定按序获取该共享资源, 并且把这种顺序记录下来, 就能消除这种不确定性。并行程序对共享内存这种共享资源的操作包括获取和释放。由于用户态下, 系统对并行程序的控制能力有限, UPLAY通过截获并行程序的执行流进行共享资源的分配。
1.1.1 页面异常处理
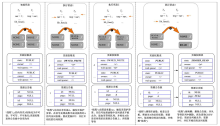
UPLAY利用CREW协议[7]控制“ 线程” 对共享页面的访问请求, 并采用全局页面权限表(Page permission table, PPT)管理每个共享页面的状态信息, 包括当前状态(共享读、独占写、公共状态), 当前持有者(当前状态为共享读, 则持有者为多个读者; 当前状态为独占写, 则持有者只有一个写者; 当前状态为公共状态, 则持有者为空), 等待队列(无法立即获得该页面的访问权限的“ 线程” 添加至等待队列)。
每个“ 线程” 在执行前, 将共享内存的所有虚拟页的访问权限设置为不可访问(不可读, 不可写且不可执行)。“ 线程” 在后期执行访问这些页面时, 如果请求访问类型与相应页表项中记录的权限不一致, 就会触发页保护异常。通过注册SIGSEGV信号处理函数, 该异常会被UPLAY捕获。
在信号处理函数中, UPLAY结合“ 线程” 的请求访问类型, 查询CREW协议, 线程请求访问共享页面的算法如图2所示。如果该“ 线程” 能够获得该页面的访问权限, 则更新页面权限表(修改被访问页面的当前状态和持有者), 设置该页面的访问权限, 然后返回继续执行(如图1的执行状态1所示); 否则, 添加至该页面的等待队列, 并将自己的访问请求注册在资源公告板上(如图1的执行状态2所示)。当持有该页面访问权限的“ 线程” 释放权限, 并唤醒阻塞“ 线程” , 阻塞“ 线程” 擦除资源公告板上的注册项, 将自己从等待队列中删除。该“ 线程” 会再次查询CREW协议, 请求获得对该页面的访问权限(如图1的执行状态3所示)。
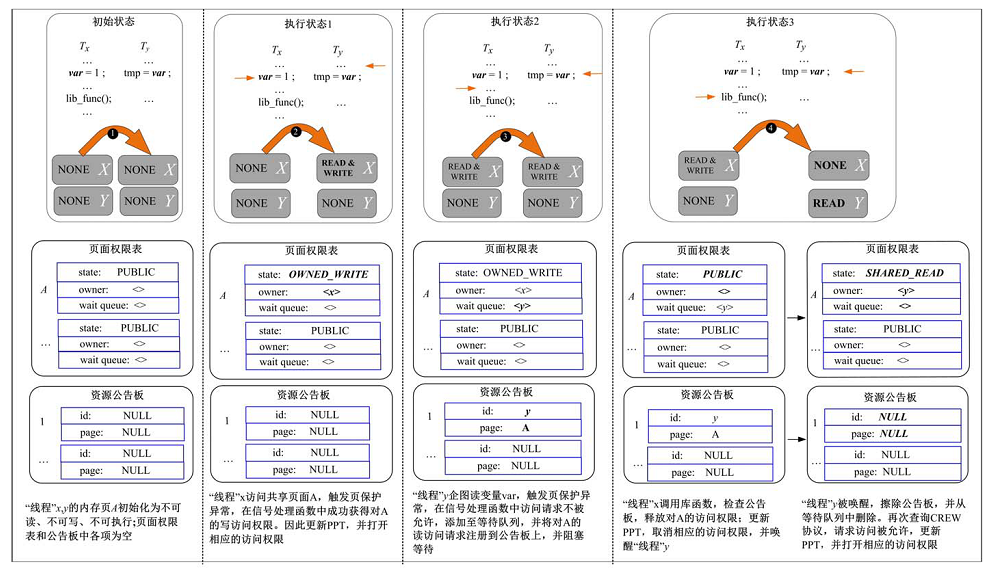 | 图1 UPLAY处理“ 线程” 的页面访问请求示意图Fig.1 An overview of “ thread” request page permission base on UPLAY |
 | 图2 “ 线程” 请求访问权限的算法Fig.2 Request page permission algorithm |
1.1.2 页面访问权限的释放
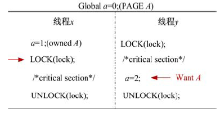
当两个“ 线程” 互相请求访问对方持有的共享页面时, 这两个“ 线程” 会陷入无限的阻塞等待, 如图3所示, 因此必须让持有页面访问权限的“ 线程” 在确定的时机主动释放共享页面。UPLAY以库函数作为页面访问权限的释放点:“ 线程” 调用库函数时先主动释放持有的共享页面, 再执行库函数的功能。释放页面的访问权限有两种方式:按需释放和完全释放两种方式。
 | 图3 “ 线程” 间死锁示例Fig.3 Example of deadlock |
(1)按需释放
UPLAY采用基于资源公告板(Resource bulletin board, RBB)的按需释放策略。当“ 线程” 的执行流被UPLAY截获时(包括库函数调用和页保护异常处理), 调用“ 线程” 扫描资源公告板, 如果自己正持有其他“ 线程” 等待请求的共享页面的访问权限, 则释放, 并唤醒阻塞等待的“ 线程” (如图1的执行状态3所示)。
(2)完全释放
相比内核态下实现的系统[6], 用户态下的系统对应用程序的控制能力有限。UPLAY只能在几种情况下截获“ 线程” 的执行流, 一旦将控制权交回, 将无法跟踪“ 线程” 的执行, 直到“ 线程” 的执行再次被UPLAY截获。
并行程序中的同步操作规定了各线程执行的先后顺序, 被用来协调各线程的执行。如图4所示, 线程
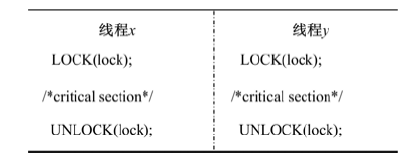 | 图4 同步操作Fig.4 Synchronization operation |
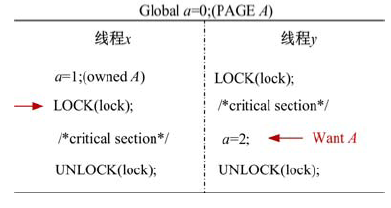 | 图5 阻塞型函数执行的死锁示例Fig.5 Execution of blocking function incurs deadlock |
“ 线程” 对共享页面所有权的获得与释放, 体现在对页面权限表的更新。全局页面权限表锁保证每个“ 线程” 按序操作页面权限表。因此, UPLAY在记录阶段确定“ 线程” 对页面权限表锁的抢占顺序, 在重放时, 根据日志文件中记录信息, 就能复现并行程序对共享内存的访问顺序。
确定性重放技术的性能是它能否被用户接受的重要因素。本节以PARSEC[18]测试集为例, 从锁、页保护异常、线程变进程这几个方面引入的开销来分析UPLAY的性能, 并给出相应地优化策略。
本文分别统计了PARSEC测试集在记录阶段, 抢占全局页面权限表锁和全局资源公告板锁的时间比, 处理页保护异常的时间比以及其中由完全释放引起的比列和由数据伪共享引起的比例, 性能统计数据如表1所示。
| 表1 PARSEC测试程序性能分析 Table 1 Performance analysis for PARSEC |
当多个共享页面访问权限在“ 线程” 间频繁转移时, 各“ 线程” 会频繁操作页面权限表, 导致“ 线程” 抢占全局页面权限表锁更加激烈。类似地, “ 线程” 通过抢占全局资源公告板锁来按序注册、删除、扫描资源公告板。由表1可知, PARSEC测试集(除vips, x264, blackscholes以外)抢占页面权限表锁平均时间比重为8.5%(8线程), 抢占资源公告板锁平均时间比重为19.9%。并且随着“ 线程” 数目的增加, 抢占资源公告板锁的竞争更加激烈。
为了提高并行程序的并行度, 降低“ 线程” 抢占全局锁引入的开销, UPLAY为页面权限表中的每一个表项分配私有锁, 并根据“ 线程” 创建的顺序为每个“ 线程” 在资源公告板上分配一个特定项, 每个公告板项带有私有锁。“ 线程” 间通过抢占这两种私有锁来按序操作页面权限表和资源公告板, 从而降低“ 线程” 抢占锁的开销。
页保护异常是利用页保护机制捕获并行程序访问共享内容的性能开销主要来源[19], 减少页保护异常的次数是提升系统性能的关键因素之一。在UPLAY系统中, 触发页保护异常有两种情况:①“ 线程” 首次访问共享页面(共享页面初始状态为不可访问); ②“ 线程” 释放某个页面的访问权限后再次访问。前者是页保护机制本身引入, UPLAY系统无法避免。后者是可以通过减少异常发生次数来优化。通过性能统计我们发现, 完全释放和数据伪共享是触发第二种页保护异常的主要来源。
2.2.1 完全释放引入的页保护异常
共享内存管理中, 完全释放避免了线程调用阻塞型函数期间与其他线程产生死锁。然而, 根据程序的局部性原理, 线程在调用库函数时持有的共享页面, 极有可能被再次访问。如果完全释放所有共享页面, 线程的后期访问仍会触发页保护异常。从表1中的统计数据可知, PARSEC测试集(除blacksholes, x264外)处理页保护异常的时间占程序运行时间的48.5%, 并且完全释放是引起页保护异常的主要因素。
为了低开销地避免执行阻塞型函数期间可能引入的死锁问题, 本文提出了一种主动抢占优化策略。“ 线程” 调用阻塞型函数之前, 将自己的睡眠状态写入线程状态板(线程状态板上标识每个“ 线程” 是否处于睡眠状态); 在“ 线程” 执行阻塞型函数的过程中, 如果其他“ 线程” 请求访问该“ 线程” 持有的共享页面, 则主动抢占该页面的访问权限, 并更新该页面的状态。一旦调用“ 线程” 结束执行阻塞型库函数, 则移除被抢占的共享页面的访问权限。
2.2.2 数据伪共享引入的页保护异常
页保护机制引入的另一个问题是数据伪共享[17, 20]。当两个“ 线程” 连续交替地访问同一个页内的不同的共享对象时, 伴随着页保护异常的多次触发, 该页面的访问权限需要在这两个“ 线程” 间频繁转移。从表1中可以看出, 除x264, blackscholes, 其他测试程序处理页保护异常的平均时间比为48.5%, 其中由数据伪共享引入页保护异常(本文只统计了堆区引起的页保护异常)的平均时间比为10.07%。facesim、raytrace、bodytrack、swaptions、canneal、streamcluster由数据伪共享引起的性能开销尤为严重。
目前, 只考虑堆数据伪共享对UPLAY性能的影响, 通过线程私有堆来减少发生在堆区的页保护异常的次数。UPLAY分配一大块进程间共享的内存区域作为并行程序的堆区, 称为超级堆, 并把超级堆预先分成多个子堆。“ 线程” 首次调用动态内存分配函数时, UPLAY会为其分配一个子堆, 作为该“ 线程” 的私有堆。后期的动态内存分配直接从该“ 线程” 的私有堆中分配。
尽管Linux下进程较为轻量级, 进程的创建和回收仍然比线程耗时[21]。当应用程序频繁地执行线程创建和回收操作时, 在UPLAY技术下, 会变成频繁地创建进程和回收进程。如PARSEC测试集中的x264创建、回收256个线程, 每个线程的生命周期很短。
针对这类程序频繁创建、回收进程引入的开销, 本文设立了进程池。当某个“ 线程” 执行结束时, 该“ 线程” 所对应的进程并不退出, 而是循环等待下一个执行任务; 主“ 线程” 所对应的进程也不会回收子进程。在创建新的“ 线程” 时, 如果当前存在活跃进程等待新任务执行, 则直接将新的任务分派给等待的活跃进程, 形成一个新的“ 线程” 。因此, 并行程序只会创建出数个活跃“ 线程” , 所有任务都由这些活跃“ 线程” 完成, 当程序执行结束退出时, 这些活跃“ 线程” 也会相应退出。
为了验证有效性, 在Linux平台上实现了UPLAY原型系统。平台配置参数为:Intel® Xeon® E7-4807 1.87 GHz处理器, 16 G的主存和18M的三级缓存。操作系统为64位Debian 4.3.5, 内核版本是2.6.32, glibc库版本为2.11.3。
本文选用PARSEC测试集(2.1版本)评估UPLAY系统的性能。PARSEC测试集是普林斯顿大学提供的并行基准测试程序集[18], 覆盖多个科技领域(如计算机视觉、金融、搜索等), 具有实际应用的特征。作为多核处理器上共享内存竞争最具代表性的应用程序[19], 近年来广泛应用于并行程序研究的学术领域。
目前UPLAY尚未支持使用ad-hoc同步的并行程序, 因此实验结果不包括fluidanimate。在未来的工作中, 可以借助已有的ad-hoc同步操作识别技术, 添加对采用ad-hoc同步操作的并行程序的支持。
首先对比SCRIBE, 评估UPLAY的性能。图6给出了在SCRIBE与UPLAY系统下, PARSEC测试集性能下降比例(每个测试程序执行20次)。在本实验平台下, SCRIBE无法运行streamcluster。
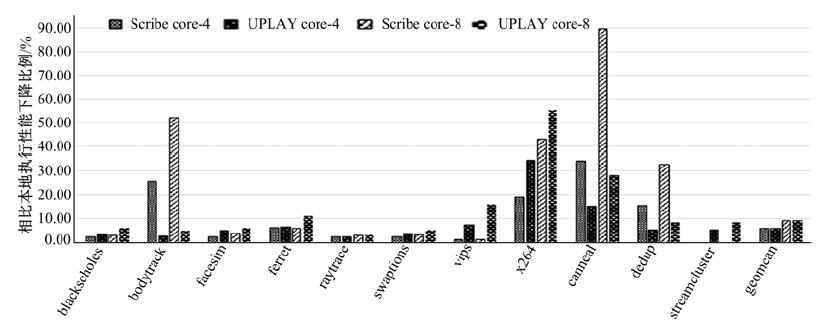 | 图6 SCRIBE与UPLAY记录性能比较Fig.6 Record Slowdown for SCRIBE and UPLAY |
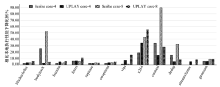
对比本地执行, SCRIBE记录阶段4、8线程的平均降速比为5.50X, 9.07X, UPLAY 4、8线程的平均降速比为5.64X, 9.26X。文献[6]针对实际的系统应用程序进行测试, 引入的性能开销很小。然而, 这些应用程序中共享内存竞争访问情况较少, 作者并没有提供针对共享内存竞争激烈、同步操作频繁的应用程序的测试数据。由图6可以看出, UPLAY的平均性能与SCRIBE相当, 并且避免了修改操作系统内核。相比其他用户态下的确定性重放技术[4, 5, 19](15X-80X的性能开销), UPLAY能够低开销地实现确定性重放。
我们依次添加私有锁、私有堆、主动抢占以及进程池四种优化策略, PARSEC程序(8线程)在这些优化策略下性能的提升效果如图7所示。
3.2.1 私有锁优化
如图7所示, 添加私有锁优化后, PARSEC测试程序平均性能提升5.93%。其中, vips、x264、blackscholes的性能提升并不明显。这是因为这3个程序抢占全局锁的时间开销较小。
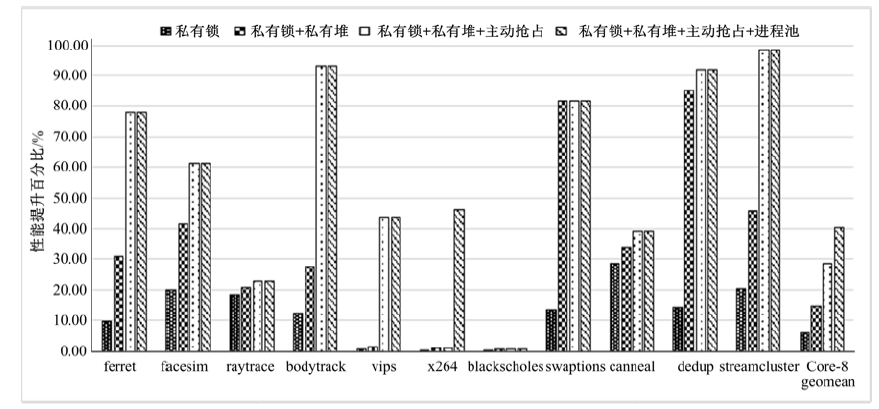 | 图7 UPLAY优化策略效果Fig.7 Speedup with different optimization for UPLAY |
3.2.2 私有堆优化
线程私有堆优化使测试程序平均性能提升了14.73%。其中, ferret、facesim、bodytrack、swaptions、dedup、streamcluster的性能提升非常明显。从表1的统计数据可知, 这些测试程序处理页保护异常的平均时间比为53.73%, 其中由数据伪共享引起的时间开销比为13.43%, 因此私有堆优化对这些测试程序的效果很好。由于x264、vips、blackscholes处理页保护异常的时间比重和数据伪共享引起的页保护异常的比例非常小, 私有堆优化没有明显改善这3个程序的性能。在添加线程私有堆优化后, raytrace, canneal的性能并没有明显提升。虽然从表1来看, 这两个程序处理页保护异常的时间比重和由数据伪共享引入的页保护异常的比例很高, 但是, 这两个测试程序的数据伪共享主要发生在主线程分配的堆区。目前UPLAY未能对由主线程的堆区域的数据伪共享实施优化, 这也是今后的工作内容。
3.2.3 主动抢占优化
从图7可以看出, 主动抢占优化策略对于测试程序的平均性能提升了28.78%。尤其是ferret、facesim、bodytrack、vips、canneal、dedup、streamcluster的性能提升比较明显, 这与表1中这些测试程序的统计数据一致。blacksholes、swaptions、x264并没有性能提升, 这是因为blacksholes、swaptions(创建子线程以后)中没有采用显式同步操作, 不存在完全释放, 而x264处理页保护异常的时间比很低。另外, raytrace处理页保护异常的时间比为44.34%, 但是由完全释放引入的时间比仅为3.914%, 因此在添加主动抢占优化后, raytrace的性能仅提升了2.22%。
3.2.4 进程池优化
进程池优化仅对x264这类频繁创建、回收线程的并行程序有效。从图7可以看出, 添加进程池优化后, x264的性能提升了45%。
本文通过重载clone函数, 设置参数flags为CLONE_FS|CLONE_FILES|SIGCHLD|CLONE_SETTLS(“ 线程” 间共享文件描述符表和文件描述符), 将多线程程序转化为多进程程序。基于进程间的共享内存机制, 使得“ 线程” 间共享全局数据区和堆区。因此, 从资源占用角度来看, UPLAY引入的额外开销包括两部分:①为新创建的“ 线程” 维护一套独立的页表; ②UPLAY系统为了记录原并行程序对共享内存的访问顺序引入的开销──维护“ 线程” 间共享内存访问顺序的元数据信息和将这些共享内存访问顺序记录在日志文件。前者的开销在SCRIBE[6]中同样存在, 后者的开销存在于任何一种确定性重放技术。另外, 在程序调试阶段, 程序开发人员并不会格外关注由调试工具引入的对原并行程序的影响。因此, 在不修改操作系统内核的前提下, UPLAY将多线程程序转化为多进程程序来降低记录并行程序访问共享内存顺序的开销是可行的。
提出了一种确定性重放技术— — UPLAY, 它能够在商用处理器和系统环境下实现低开销地确定性重放。该技术利用进程的私有页表特征, 基于页保护机制高效地记录并行程序对共享内存的访问顺序。另外, 本文还深入研究了UPLAY性能开销的主要原因, 分别给出了有效的优化策略。实验结果表明, 本文方法比其他用户态下的确定性重放技术引入的开销更小, 并且具有不修改操作系统内核的优势。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|