

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多管理节点的乐观锁协议
[郝娉婷 , 胡亮, 姜婧妍, 车喜龙]
, 胡亮, 姜婧妍, 车喜龙]
, 胡亮, 姜婧妍, 车喜龙]
|
|


作者简介:郝娉婷(1990-),女,博士研究生.研究方向:分布式计算,计算机网络.E-mail:susan454@sohu.com
针对悲观锁机制并行性不足的缺点,改进了Zookeeper的悲观锁机制并设计了一种乐观锁协议。通过研究分布式锁机制和Zookeeper的工作原理,提出了一种可以降低总执行时间的乐观锁协议,从理论上与三种不同协议进行了对比和分析,在保证数据一致性的同时,得出乐观锁协议为最优化设计,且对该协议的互斥性、死锁性和公平性加以证明。实验结果表明,乐观锁协议使系统性能有较大幅度提升,并且与其他协议相比,在总执行时间、占有带宽等方面均有一定优势。
In order to improve the parallelism of pessimistic lock mechanism, an optimistic lock protocol was designed and applied for modifying the original lock mechanism in Zookeeper. By studying the mechanism of distributed lock and the working principle of Zookeeper, the execution time was decreased by the optimistic lock protocol. Theoretically compared with three other protocols, the optimistic lock protocol is the most optimized. Based on ensuring consistency maintenance, the optimistic lock protocol possesses mutual exclusion, non-deadlock and fairness. Simulation results show that the optimistic lock protocol significantly improves the data access performance, and outperforms the other lock protocols in execution time and bandwidth occupancy.
一个分布式系统[1]是由若干相对独立的计算机组成。在分布式系统中分布式锁具备同步、互斥等功能, 主要负责保证数据的一致性和对数据的协同访问。很多商业系统(如Oracle parallel server、IBM GPFS、Red Hat GFS等)都使用分布式锁进行管理。
分布式锁[2]依据并发控制方法可分为悲观锁和乐观锁。悲观锁对用户申请资源操作全部加锁, 而乐观锁对用户申请资源操作部分加锁。锁的思想在分布式系统中应用广泛。在文件管理方面, 文献[3]采用租约机制调整了分布式并行系统Lustre中锁的粒度; 在数据库方面, 文献[4]针对加锁粒度提出了基于全局目录的分布式数据库加锁管理算法; 在系统存储方面, 文献[5]通过实验对比了乐观锁和悲观锁, 结果表明尽管由于用户的重复尝试会导致冲突率较高, 但乐观协调方式的并行性能仍优于悲观协调方式。
目前实现悲观锁思想的典型应用为Zookee-per[6], 它是Hadoop的一个子项目, Zookeeper采用了基于悲观锁的协调方式并使用Lamport提出Paxos[7, 8, 9]算法作为分布式互斥[10]基础。Zookeeper具有容错性、高效性、扩展性等特点, 它提供简单的接口便于管理组、选举leader、保证数据一致性等。在一些文章中针对Zookeeper也进行了深入的研究。文献[11]改进了Zookeeper的同步机制, 改进后的Zookeeper可以在服务端响应用户提交的一连串操作请求。但是在Zookeeper框架下仍存在并行性不足等缺点。
本文的核心工作是将乐观锁的思想运用到分布式集群管理中, 对Zookeeper悲观锁机制进行改进并且设计一种基于多管理节点的乐观锁协议, 该协议在开销较低的基础上增强了锁机制的性能, 提高了分布式系统协调能力和管理的效率。
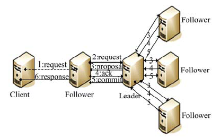
Zookeeper提供了一种典型的分布式协调服务, 以锁[12]的方式管理集群内操作的先后顺序, 保证内容的一致性等, 如图1所示。
 | 图1 Zookeeper工作过程Fig.1 Distributed workflow in Zookeeper |
“ 下载-修改-上传” 作为计算机领域中的原子操作, 具有普遍研究意义。所以借此操作说明两种锁机制的区别, 并以此作为实验的基准测试。
Zookeeper使用了基于悲观锁的协调方式。当资源Ri被用户Ui占有时, Zookeeper不能接受用户Uj(i¹ j)对Ri的请求, 该请求将被挂起在等待队列, 直到Uj获得Ri。Zookeeper采用层次化目录结构, 每个路径下的Dnode有唯一标识, 本文以(Ri, “ read-modify-write” , SeqID)为语义表示Dnode, L为当前目录下的节点列表。当Ui提出对Ri的请求时, Zookeeper执行悲观锁机制, 如表1所示。
| 表1 悲观锁算法 Table 1 Pessimistic lock algorithm |
| 表2 乐观锁算法 Table 2 Optimistic lock algorithm |
乐观锁机制结合条件存储操作使资源处于无锁状态。系统通过比较Ui请求Ri时的版本号与系统内资源的版本号, 判别请求是否提交成功。乐观锁机制以这样的方式保证了数据的有序性和一致性, 合理地避免了悲观锁机制的长时间等待。
Ui先执行对Ri的修改。同时Uj( 
本文针对悲观锁机制并行性不足的问题, 采用乐观锁的思想改进了Zookeeper, 并设计了基于多管理节点的O-C协议(Optimistic coordin-ation)。
本协议设定以下前提条件:①主要针对资源冲突小的情况; ②不考虑意外终止情况。协议中涉及到的变量定义见表3。协议工作的流程如图2所示, Coordination Server决定用户是否获得请求资源的锁; Data Server负责存储资源。
| 表3 变量说明 Table 3 Description of variables |
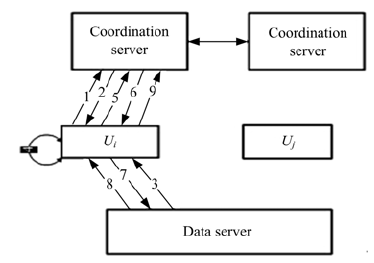 | 图2 协议交互流程Fig.2 The coordination between each part in O-C protocol |
协议具体步骤如下所示。
第1步 Ui建立到Coordination server的连接。
第2步 Ui向Coordination server提交下载申请, Coordination server将版本号Vs返回给Ui。
第3步 Ui开始从Data server下载资源Ri并在自己的Dnode上用版本号Vs对资源进行标记。(下载时间为t1)
第4步 Ui修改Ri。(修改数据所用时间为t2)
第5步 Ui以版本号Vu作为参数向Coordination server提交上传申请, Coordination server查询锁记录表检测是否有Uj(j¹ i)正在写相同资源。Coordination server比较Ui提交的版本号Vu与当前版本号Vs是否相等。最后Coordination S-erver将SameFlagi(Uj)和VersionMatch返回给Ui。
第6步 若SameFlagi(Uj)=1且VersionMatch=1, 则Ui上传申请被Coordination server驳回, Ui等待t3时间后重新执行第5步。因为Ri未过期, Ui重新执行第5步。
若SameFlagi(Uj)=1且VersionMatch=0, 则Ui申请被Coordination server驳回, Ui等待t4时间后重新执行第2步。因为Ri已过期, Ui重新执行第5步不可能成功。
若SameFlagi(Uj)=0且VersionMatch=1, 则Ui申请被批准, Coordination server将Ri及Ui作为一个锁独立项添加进锁记录表。
若SameFlagi(Uj)=0且VersionMatch=0, 则Ui申请被Coordination server驳回, Ui等待t4时间后重新执行第2步。因为Ri已过期, Ui重新执行第5步不可能成功。
第7步 Data server对原Ri资源重命名, 然后Ui上传修改后的Ri到Data server, 并上传更新成功的标记, 标记文件留在对应资源附近。此时原Ri暂不删除。(上传时间为t5)
第8步 为保证上传过程的正确性, Ui确认更新成功后再删除标记文件和原Ri。若更新成功, Ui得到的返回值为0, 同时, Coordination server生成新的版本号
第9步 Ui断开到Coordination server的连接。(执行时间为t6)
下面将对O-C协议进行详细分析, 协议分析中涉及到的符号说明见表4。
| 表4 主要符号说明 Table 4 Description of major symbols |
针对单个用户的情况, 采用O-C协议对所用时间进行分析:
式中:
用户在申请上传资源和下载资源时, 可能会遇到驳回情况, 当该用户最后一个进行操作时, 驳回次数达到上限。
针对多个用户的情况, 采用O-C协议从总时间、失败次数、带宽等方面进行分析:
(1)总时间Tm
依据式(1)得Tm如下
当每个用户的上传和下载请求针对同一资源时, 所有用户请求都是串行执行的, 系统花费总时间将达到最大值。当每个用户的上传和下载针对不同资源时, 系统花费总时间将达到最小值。
(2)请求失败的总次数F
(3)带宽
设定当n个用户同时执行下载或上传任务时, 带宽占用率为100%。当Br=100%时, 表示参与此过程的所有用户都进行下载操作; 当Br=1/n时, 表示只有某一个用户在进行下载操作。
4.用户与系统交互次数Co
依据式(6)可得:
在资源未过期而上传申请失败的情况下, 每个用户尝试的次数也是不确定的。由于用户进行每次操作的时间不同, 系统处理用户的操作请求时间也是不确定的, 所以每次用户申请资源时的等待次数也是不同的。结合式(7)得:
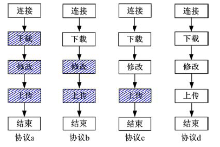
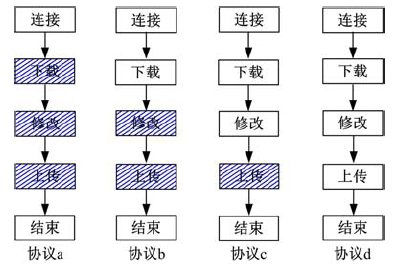
过渡协议按照“ 下载-修改-上传” 逐渐去锁的过程进行演化, 如图3所示, 图中阴影部分表示协议加锁的阶段。协议a表示完全的悲观锁, 协议b、c和d表示3种不同粒度的乐观锁, 其中协议c是本文提出的O-C协议。下面对4种过渡协议进行详细分析。Tm(x)表示多用户情况下采用x协议所用总时间, F(x)表示多用户情况下采用x协议系统中请求失败的总次数, 其中x=a、b、c、d。
 | 图3 过渡协议Fig.3 The transition among four types of protocols |
2.2.1 协议a
协议a为悲观锁协议。时间为Tm(a), 失败次数为F(a)≤ n, 带宽为Br=1/n, Bw=1/n, 协议a与系统的交互次数Co为n≤ Co≤ 2n+1。
2.2.2 协议b
协议b为在下载阶段解锁的乐观锁协议。Ui在修改资源时系统需要判别Ui是否获得锁, 若系统判别Ui没有获得锁则Ui继续等待或被系统驳回; 若系统判别Ui获得锁则Ui可执行对资源的操作。协议b将下载阶段解锁使Tm(b)< Tm(a)。协议b带宽为1/n≤ Br≤ 100%, Bw=1/n。协议b与系统的交互次数Co满足不等式(n-1)× (1+t5/t3)+n≤ Co≤ (n-1)× (1+`t5/t3+t5/t4)+n。
2.2.3 协议c
协议c为O-C协议。与协议b相比, 由于用户修改阶段彼此独立, 不需要设定锁机制, 使Tm(c)≤ Tm(b), 因此协议c在设计上更为合理。与协议a相比, 协议c将下载和修改阶段解锁使Tm(c)< Tm(a), 但是在资源冲突多的情况下会使Tm(c)增加。协议c带宽为1/n≤ Br≤ 100%, Bw=1/n。协议c与系统的交互次数Co满足不等式(n-1)× (1+t5/t3+n≤ Co≤ (n-1)× (1+t5/t3+t5/t4)+n。
2.2.4 协议d
协议d为在“ 下载-修改-上传” 阶段解锁的乐观锁协议。若Ui在上传后系统判别上传数据无效, Ui重新执行下载-修改-上传过程, 会增加Ui的执行周期, 导致Tm(d)增加且F(d)减少。但在采用协议d的情况下会使系统中资源的副本数量大量增加, 同时由于上传阶段的解锁, 每个用户都可以将自己的资源进行上传, 导致对系统的上传带宽有一定要求。协议d带宽为1/n≤ Br≤ 100%, Bw=1/n。协议d与系统的交互次数Co满足不等式(n-1)× (1+`t5/t3)+n≤ Co≤ (n-1)× (1+t5/t3+t5/t4)+n。
综合以上几点因素对4种过渡协议进行分析和比较, 本文确定协议的重点评测值包括Tm和F, Co与F存在正关联。带宽为协议辅助测评值, 带宽与每段时间内多用户请求任务的总时间有关。若系统运行的带宽受到实际情况的限制, 系统可对协议进行一定的调整。
本节从协议的互斥性、无死锁和公平性3个角度证明协议的正确性。证明中涉及到的定义[13]如下所示。
本文中Ui请求Ri的优先级定义为Pr(Ri)。
定义1 并发(Concurrent):
Ri和Rj是并发的当且仅当Ri在Rj的生存周期内产生或者Rj在Ri的生存周期内产生。
定义2 并发集(Cset):
Cseti= {Rj|
定义3 并发集首(Cheaderi):
Cheaderi:Ri:Pr(Ri)> Pr(Rj) ∀ Ri, Rj∈ Csetk, i≠ j。
定义4 并发集尾(Ctaileri):
Ctaileri:Ri:Pr(Ri)< Pr(Rj) ∀ Ri, Rj∈ Csetk, i≠ j。
定义5 前驱(Pred):
Pred:Pred(Ri, Csetk)= Rj iff Ri, Rj ∈ Csetk∧ Pr(Ri)< Pr(Rj)∧ ¬ (∃Rk∈ S| (Pr (Ri)< Pr (Rk)< Pr(Rj)))。
定义6.后继(Succ):
Succ:Succ(Ri, Csetk)= Rj iff Ri, Rj∈ Csetk∧ Pr(Ri)> Pr(Rj)∧ ¬ (∃Rk∈ S|(Pr(Ri)> Pr(Rk)> Pr(Rj)))。
对互斥性、无死锁和公平性的证明如下所示。
(1)证明用户互斥进入临界区
证明:采用反证法。
假设Ui和Uj占有相同资源Ri, 即∃i∃j(i≠ j)and(SameFlagi(Ui)=1), and(SameFlagi(Uj)=1)。则:
Pre(Ri, Csetk)=Pre(Rj, Csetk)
Succ(Ri, Csetk)=Succ(Rj, Csetk)
综上得出Dnodei=Dnodej且Ui和Uj的请求排列于并发集同一位置。依据协议第5步和第6步可知不存在多个用户同时获得对同一资源的锁, 若SameFlagi(Ui)=1, 则SameFlagi(Uj)=0。假设不成立, 得证该协议具有互斥性。
(2)证明用户无死锁:
证明:用户Ui在请求资源Ri时有两种情况:SameFlagi(Ui)=1或SameFlagi(Ui)=0。当用户间请求的资源无交集时, 系统不存在用户既占有又申请锁的死锁条件。当用户间请求的资源存在交集时, 即SameFlagi(Ui)=1, SameFlagj(Uj)=1, 表示Ui请求Rj, Uj请求Ri。分别对请求向未获得的资源进行下载操作和上传操作进行讨论。若Ui需要下载Rj, 根据乐观锁协议在“ 下载-修改-上传” 过程中不对下载过程加锁的特点, Ui会顺利执行完毕。若Ui需要上传Rj, 在协议中, 针对同一资源只有一个用户上传, Ui等待Uj上传完成再进行操作。综上得出该协议不会在运行过程中使系统产生死锁。
(3)公平性
证明:假设Ui请求资源的时间戳为Ti, Uj请求资源的时间戳为Tj且Ti< Tj, Ui请求Ri, Uj请求Rj, 依据协议第5步和第6步, 用户按照FIFS的分配原则获得资源, 因此SameFlagi(Ui)=1。所以该协议具有公平性。
O-C协议满足互斥性且不会出现用户抢不到锁的情况, 系统通过FIFS的原则决定用户的请求顺序, 从而使O-C协议的正确性得到保证。
仿真实验中将Zookeeper运行在分布式Server集群上, 以“ 下载-修改-上传” 作为基本操作。按照第三节对4种协议的比较, 协议c在设计上比协议b更合理, 协议d占用带宽和系统存储空间较大且较于协议c无明显优势, 依据分析结果选取两种典型协议, 即标准的悲观锁协议(协议a)和O-C协议(协议c)进行性能的对比。图4~图9中横坐标为实验次数, 纵坐标为每次结果执行50次后, 相应得出的平均结果。且在本实验中用户数目固定, 用户请求开始下载的时间、修改时间以及完成时间皆服从随机分布。实验环境为:Ubuntu11.04操作系统; Intel Core 2 Duo CPU 2.93 GHz。数据采用实验结果性能评价公式定义如下。
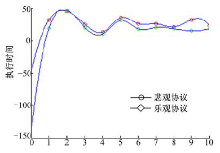
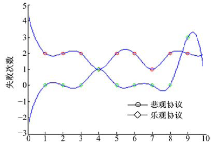
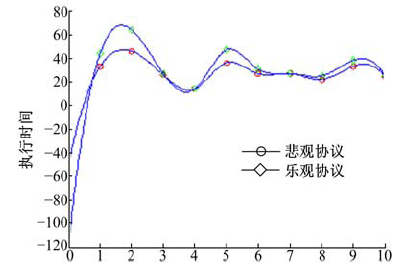 | 图4 多用户请求单一资源时的执行时间Fig.4 The execution time |
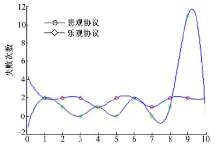
 | 图5 多用户请求单一资源时的失败次数Fig.5 The failure time |
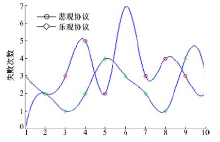
 | 图6 多用户请求多资源时的执行时间Fig.6 The execution time |
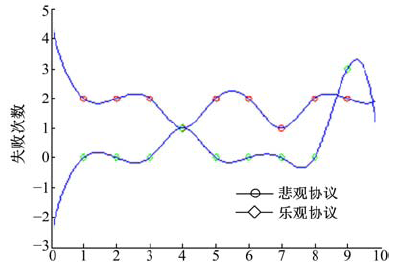 | 图7 多用户请求多资源时的失败次数Fig.7 The failure time |
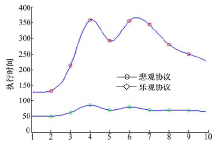
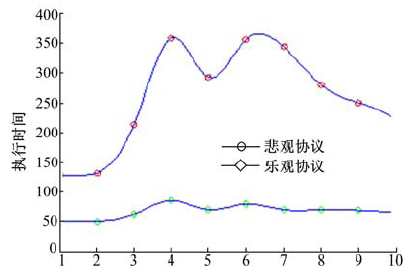 | 图8 多用户请求单一资源时的执行时间Fig.8 The execution time |
 | 图9 多用户请求单一资源时的失败次数Fig.9 The failure time |
At为系统采用悲观锁协议和O-C协议处理任务的总时间比值:
Af为系统采用O-C协议和悲观锁协议处理任务的失败次数比值:
A为总体改进性能评测值:
若0≤ A< 1, 表示O-C协议相比于悲观锁协议性能较好; 若A≥ 1, 表示O-C协议相比于悲观锁协议性能较差。
针对多用户请求单一资源的情况实验结果见图4和图5。系统采用悲观锁协议的失败次数方差较小, O-C协议在用户冲突较多的情况下, 用户提出的请求被驳回的概率高, 用户需要重新执行, 所以情况变为系统中用户的请求被串行执行, 即只有上一个请求该资源的用户执行完“ 下载-修改-上传” 过程, 下一个用户才能开始执行, O-C协议退化成悲观锁协议, 同时由于O-C协议的内容中增加了用户再次发出请求的等待时间, 使系统执行的总时间和用户访问的次数增加。
针对多用户请求多资源的情况, 实验结果见图6和图7。此时系统在采用O-C协议时用户冲突小。多数情况下, O-C协议的失败次数较系统采用悲观协议有一定减少, 系统执行总时间也明显减少, O-C协议相较于悲观锁协议有明显优势。
针对在仅“ 下载” 与“ 下载-修改-上传” 比例为2:1的条件下多用户请求单一资源的情况, 实验结果见图8和图9。O-C协议在这种情况下, 由于用户间的冲突相较于多用户请求多资源的情况有所提高, 导致Af均值有一定增加, 但O-C在系统执行任务的总时间上仍有明显优势, 使At均值较高, 所以A< 1, 系统采用O-C协议较采用悲观锁协议性能更好。
综合以上3种实验的结果可知, 系统采用O-C协议协调时, 用户等待请求执行的平均时间与总时间的比值约为1.53%左右。说明在实际情况中, 用户等待的时间较短, 只有小概率用户出现长时间等待, 系统出现用户"饿死"情况的概率较低, 同时O-C以小幅度增加的失败次数为代价, 换来系统执行总时时间的较大幅度减少, 从而提高系统整体协调处理任务的性能。
本协议扩大了乐观锁的应用范围, 使其不仅可以应用在数据库等方面, 也可将其应用到不同的分布式环境下。实验结果表明在多用户请求多资源以及存在仅“ 下载” 的情况下, 总时间有较大幅度的减少, 其失败次数也未骤增。再次验证O-C协议在性能上的明显优势。采用O-C协议的系统以较低的代价换取性能的提高, 且系统不会因为带宽等限制因素而影响传输效率。未来将主要针对参数t3、t4进行深入研究, 以达到减少冲突率并提高性能的目的。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|