


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于设备噪声估计的录音设备源识别
[邹领 , 贺前华, 邝细超, 李洪滔, 蔡梓文]
, 贺前华, 邝细超, 李洪滔, 蔡梓文]
, 贺前华, 邝细超, 李洪滔, 蔡梓文]
|
|


作者简介:邹领(1981-),男,博士研究生.研究方向:数字多媒体取证,语音及音频信号处理.E-mail:zou.ling@mail.scut.edu.cn
针对录音设备源识别问题,首先分析了语音录音的产生过程,在此基础上提出了一种基于设备噪声估计的录音设备指纹,为了获取充分的设备噪声,使用了一个包含两种噪声估计算法的设备噪声估计器。为了验证提出的设备指纹的有效性,同时考虑了5种分类方法来进行录音设备源识别,并在两个录音库上进行了实验。其中一个包含22个录音设备,该22个设备分别来自4类常用的录音设备,另一个音库包含21个手机的语音录音。实验结果证明了本文方法的有效性。
To resolve this problem, first, the procedure of the speed recording is analyzed and a recording device fingerprint based on device noise is proposed. Then, a noise estimator including two noise estimation algorithms is applied to acquire sufficient device noise. Finally, to evaluate the effectiveness of the proposed device fingerprint, five classification techniques are utilized to identify the source recording device. Experiments are carried out on two corpora. One corpus comprises speech recordings obtained by 22 recording devices coming from four types of common recording devices, and the other corpus consists of speech recordings from 21 cell phones. Experiment results verify the effectiveness of the proposed method.
随着多媒体设备的普及, 法庭上使用音视频和图像作为证据的情况也越来越多, 而各种多媒体编辑软件的普及使得对多媒体文件进行篡改和编辑变得容易。因此, 在一个多媒体证据能作为有效的法庭证据之前, 必须对它的真伪进行鉴定。而作为数字音频取证方法之一的录音设备源识别[1, 2], 在过去的几年一直受到关注。
已有的录音设备源识别研究主要集中在:麦克风识别[3, 4, 5, 6, 7, 8, 9, 10]、电话话筒识别[11-
针对上述这些问题, 本文提出一种基于设备噪声估计的录音设备识别方法。证明了在噪声信号中含有可对录音设备识别的信息, 从而通过对语音录音中的噪声信号而不是对整个录音信号进行处理来减轻强语音信号的干扰, 有利于提取设备固有指纹。同时, 为了使得提取的录音设备指纹更加充分, 本文的设备噪声估计同时采用两种噪声估计方法。
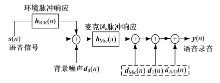
一个简化的数字语音录音模型如图1所示[1]。其中,

其中:
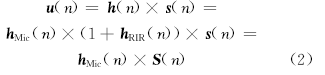
 | 图1 数字语音录音系统简化示意图Fig.1 Simplified digital speech recording diagram |
包含了直接的语音信号和录音环境的声学特征(通过
式中:
由式(3)可见, 噪声分量
式(3)在频域的表达式为:
式中:
假设背景噪声和设备噪声的幅度及相位独立, 且麦克风脉冲响应和设备噪声是平稳的或跟背景噪声信号相比变化缓慢, 那么有:
式中:
设x=
特别地, 当无背景噪声, 即
本文提出的基于噪声估计的录音设备源识别系统框图如图2所示。首先, 将一段语音信号分成短时帧; 其次, 逐帧进行噪声谱估计; 再次, 对每一帧估计出的噪声谱求对数后取均值, 得到平均噪声对数谱, 将其用于表征录音设备的特征。
 | 图2 基于设备噪声估计的录音设备源识别系统Fig.2 Source recording device recognition system based on device noise estimation |
考虑到单一的噪声估计方法的局限性, 在尝试了一些噪声估计算法后, 本文采用了两种噪声估计算法并进行组合, 具体为文献[28, 29]中的基于语音活动检测(Voice activity detection, VAD)的噪声估计算法(见图2中算法1)和连续频谱最小值跟踪算法(见图2中算法2)[30]。用这两种噪声估计方法得到的噪声估计分别求平均对数谱,
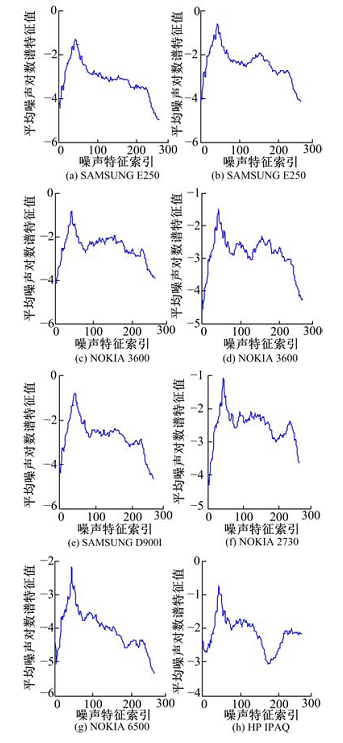 | 图3 本文音库中8个设备的同一句录音的平均噪声对数谱图Fig.3 Average noise log spectrum of 8 device |
然后合并作为最终的设备特征。设
组合后的
图3给出了本文22个设备音库中的8个设备同一句录音的平均噪声对数谱(采用文献[30]中算法估计噪声), 其中包括两组同一品牌同一型号的设备。可以发现, 不同设备(甚至同一品牌同一型号的设备)的平均噪声对数谱差异明显。此外, 由于组合的噪声特征维度较高(若FFT点数取512时, 两种噪声特征合并后的维度为512), 因此本文采用LDA[31]降维算法来降低组合特征的维度。设
图4为对本文22个设备音库中的8个录音设备的录音文件上提取降维后的21维噪声特征向量的第5个分量(
 | 图4 本文所提特征的第5个分量在8个设备同样语音录音上的直方图Fig.4 Histogram of c5 component of proposed feature on 8 devices and same recorded speech signal |
实验使用的音库有两个:MOBIPHONE音库和自制音库。MOBIPHONE音库(一个包含21个手机的音库)信息详见文献[20]。自制音库包含有22个常用录音设备, 分别是手机、平板电脑、录音笔和MP3。具体品牌、型号及本文编号如表1所示。该音库的录制方式为:从TIMIT音库中随机挑选出24个人的语音, 每个人有10段句子, 每段长约3 s。在实验室环境下通过一个扬声器依次播放这些TIMIT句子并分别用上述的22个设备进行录音, 得到的设备录音文件最后都统一转换成8 kHz采样率16 bits的wav文件。这样, 每个设备含有240个录音文件。
| 表1 实验所用音库所包含设备的具体信息和设备编号 Table 1 Specific information and device numbers of experimental corpus |
每一个设备录音库中一半用来训练, 另一半用来测试。语音短时帧的帧长取32 ms, 取50%的帧移, 分帧采用汉明窗, 短时傅里叶变换取512点, 得到噪声特征后, 在本文22个设备的音库上实验用LDA降到21维, 在MOBIPHONE音库上降到20维。本文在5种分类方法上进行了实验, 分别为:支持向量机(Support vector machine, SVM)、多层感知器(Multilayer perceptron, MLP)、朴素贝叶斯(Naive Bayes)、K最近邻(K-nearest neighbour, KNN)和旋转森林(Rotation forest), 这些分类方法都通过知名的WEKA数据挖掘软件[32]来实现。实验中采样正确识别率来作为衡量性能的指标。
首先, 将本文的噪声特征以及其他录音设备源识别文献中使用过的几种特征(包括MFCCs均值[19], 基于MFCCs扩展的GLDS kernel超向量特征[21]和SSF[19])在本文音库和MOBIPHONE音库上进行实验, 分类算法采用3.2节所述的5种分类器, 取得的识别率如表2所示。在4种特征中, 绝大多数情况下, 本文提出的特征在两个库上都取得了相对最好的识别率, 验证了本文特征的有效性。
| 表2 不同特征在本文设备音库和MOBIPHONE音库上的识别率 Table 2 Recognition rates of various features on corpus of this paper and MOBIPHONE corpus % |
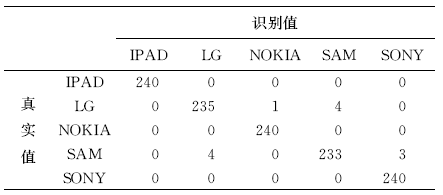
其次, 为了验证本文特征对同一个品牌的录音设备的区分能力, 在包含5个NOKIA录音设备的子集上(称为NOKIA子集)上进行实验, 实验结果如表3所示。本文所提的特征跟其他几种特征相比取得了略高的识别率, 这表明了其具有区分同一品牌甚至同一品牌同一型号设备的能力。同时对比表2和表3发现, 所有特征对同一品牌设备子集的识别率低于对整个22个设备的识别率。这是因为同一品牌设备子集里的设备的相似度程度较高所以较难区分。分类器采用SVM时, 本文所提出的特征在NOKIA子集上的混淆矩阵如表4所示。可以看出, D6和D7由于是品牌和型号完全一样的设备(NOKIA 3600), 这两个设备互相混淆的程度最大, 从而被识别错的概率最高。
| 表3 不同特征在NOKIA子集上的识别率 Table 3 Recognition rates of various features on NOKIA subset % |
第三, 为了验证特征对不同品牌设备的区分能力。从本文22个设备音库中挑选了5个品牌(包括IPAD、LG、NOKIA、SAMSUNG和SONY), 其中每个品牌挑选出两种设备作为该类的代表。对5个品牌的识别的结果如表5所示。
| 表4 噪声特征在NOKIA子集上的混淆矩阵 (SVM作为分类器) Table 4 Confusion matrix of noise feature on NOKIA subset(SVM utilized as classifier) |
| 表5 不同特征在5个品牌设备库上的识别率 Table 5 Recognition rates of various features on 5 brands devices corpus % |
几种特征都取得了较高的识别率。这是因为对不同品牌的设备更容易区分。这一点通过对比表5和表3也可以发现, 对这5种分类器, 所有特征对不同品牌设备的识别率都明显高于该特征对同一品牌设备的识别率。分类器采用SVM时, 本文所提特征在5个品牌设备上进行识别的混淆矩阵如表6所示。
| 表6 噪声特征在5个品牌设备库上的混淆矩阵 (SVM作为分类器) Table 6 Confusion matrix of noise feature on 5 brands devices corpus(SVM utilized as classifier) |
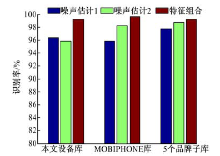
第四, 为了验证两种噪声估计方法所得到的噪声特征分别对设备源识别的贡献, 依次只采用一种噪声估计算法并在本文22个设备音库、MOBIPHONE音库以及5个品牌设备子库上进行了实验, 分类器采用SVM, 分别得到两种噪声估计算法所得到的噪声特征下的识别率以及二者组合后的识别率, 结果如图5所示。在本文的22个设备录音库上, 只采用噪声估计算法1比只采用噪声估计算法2所得到的噪声特征的识别率略高,
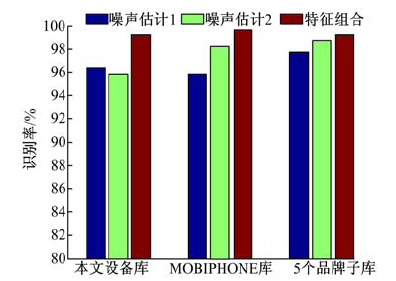 | 图5 两种噪声特征和二者组合后的特征的识别率柱状图(SVM作为分类器)Fig.5 Effectiveness of various noise features on various corpus(SVM utilized as classifier) |
且二者组合后最高。在MOBIPHONE音库上分别采用两种噪声估计算法所得到的噪声特征分别取得了95.99%和98.21%的识别率, 二者组合后的特征取得了99.09%的识别率, 而在5个品牌设备子库上只采用噪声估计算法2比只采用噪声估计算法1所得到的噪声特征的识别率微高且二者组合后最高。说明这两种噪声估计方法得到的噪声特征在性能上是接近的, 并具有一定的互补性。
经过对数字语音录音过程的分析发现在语音录音的噪声信号中包含有录音设备源识别所需要的信息。基于此, 提出了一种基于噪声估计的录音设备源识别方法。通过录音设备源识别实验以及与其他几种常用的录音设备源识别特征包括MFCCs均值特征、基于MFCCs的GLDS kernel超向量特征以及SSF特征做比较证明了该方法的有效性, 可以作为一种可选的录音设备源识别的方法。这4种特征对不同品牌设备的区分能力都高于对同一品牌设备的区分能力。实验发现本文所采用的两种噪声估计方法得到的噪声特征识别性能接近且组合后性能更好。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|