
{kind=link}
{kind=link}
{kind=link}
基于语谱图行投影的特定人二字汉语词汇识别
[梁士利1  , 魏莹
, 魏莹1 , 潘迪1 , 张玲2 , 许廷发3 , 王双维1 ]
, 魏莹]
|
|


作者简介:梁士利(1968-),男,副教授,博士.研究方向:信号处理.E-mail:lsl@nenu.edu.cn
将图像处理技术应用到语音识别领域,在图像特征提取过程中,首先对语谱图进行等宽度分带行投影和二进宽度分带行投影,分别作为窄带语谱图的第1个特征集合和第2个特征集合,同时将语谱图进行再次图像傅里叶变换之后进行等宽度行投影,作为第3个特征集合。将上述3个特征集构造为特定人二字汉语词汇识别的特征向量,以支持向量机为分类器进行特定人二字汉语词汇整体识别。采用1000个语音样本进行仿真实验,结果表明,该方法对特定人二字汉语词汇的识别率可达92.8%,为汉语词汇的识别提供了新的思路。
In the process of image feature extraction, the image processing technique is applied to the speech recognition. First, equal width zoning line projection and binary width zoning line projection are carried out to the spectrogram, which are taken as the spectrogram of the first characteristic set and the second characteristic set, respectively. Meanwhile, equal width zoning line projection is carried out again to the spectrogram after Fourier transform, treating as the third feature set. Then, the above three feature sets are used as feature vectors to Support Vector Machine (SVM) as a classifier for the overall recognition of specific two words Chinese vocabulary. 1000 voice samples are used in simulation experiment. The results show that the correct recognition rate of this method is 92.8%, and it provides a new way of thinking of Chinese vocabulary overall recognition.
语音识别(Speech recognition)[1]主要是指让机器听懂人说的话, 即在各种情况下, 准确地识别出语音的内容。当今, 语音识别在人机交互中起着重要的作用, 同时也是语音信号处理中非常重要的应用技术。语音识别研究开始于20世纪50年代, 贝尔实验室的研究人员发明了语音信号的语谱图, 它是频谱能量随着时间变化的二维图, 从而使我们看到了“ 语音” [2]。1995年, 潘凌云等[3]将语谱图应用到语音识别中的语音音素分割中, 这个方法作为语音识别系统的一部分, 已经在一个语音分析系统中使用。近年来, 采用“ 构建支持向量机(SSVM)” 的方法进行中等大词汇量语音识别[4]; 基于谱图模式匹配的“ 唱歌声音识别” [5]; 语言分析和代表性的工具“ 言语艺术” [6]的发展; 应用一套新的ORF核函数支持向量机(SVM)的语音识别[7]; “ 将GMM-PCA-SVM模型用于自动说话人” 的识别[8]等, 这些为语音识别提供了一个全新的视角。研究人员从语音信号的可视化特征— — 语谱图中提取熵序列作为语音识别系统的特征参数, 开辟了语音信号处理与图像信号处理相结合的新领域[9]。与此同时, Asahi[10]将带噪的语音信号通过对其相应的语谱图进行图像处理, 提高了语音识别的鲁棒性。“ 语谱图Radon变换和离散余弦变换” 的说话人分离技术[11]; 语谱图用于低信噪比环境中的“ 语音端点检测” [12]; 使用“ log-gabor过滤器和多分类支持向量机(SVM’ s)” 的环境声音谱图的分类[13]; 将谱图的“ 纹理图像” 作为特征的语音情感识别[14]; 许森等[15]以语谱图纹理方位的数学形态学为特征的汉语韵母声调识别等, 这些让我们对语谱图的广泛应用有了更加深刻的认识。2014年, Zhang等[16]提出了基于投影特征的烫印图像识别算法, 通过改变投影自适应阈值, 进行图像识别。
本文以语谱图矩阵及其再次傅里叶变换矩阵的行分带投影值作为特征集合, 以支持向量机为分类器, 实现了特定人二字汉语词汇识别。实验结果表明, 该方法对于特定人二字汉语词汇的识别率可达92.8%, 这为解决汉语词汇的识别问题提供了一种新的思路。
语谱图(Spectrogram)[17]是表示语音频谱随时间变化的图形, 它采用二维平面来表达三维信息, 其纵轴为频率, 横轴为时间, 任一给定频率成分在给定时刻的强弱用相应点的灰度或色调的浓淡来表示。语谱图是加窗傅里叶变换的可视化表达, 基本傅里叶变换有一个缺点:它不具有时间局部性, 这点可从傅里叶正/反变换的公式中看出:
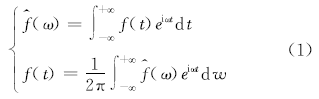
式(1)中的积分区间为(-¥ , +¥ ), 即整个时间轴,
WFT的实现过程如下:
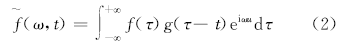
式中:g(τ -t)为分析窗函数, 随着t的不断变化, 由g(τ -t)所确定的窗口在时间轴上移动, 使分析信号f(t)逐步进入被分析的状态, 因此该变换反映了信号f(t)在时刻t、频率为ω 的分量的相对含量。
语谱图在语音分析中具有重要的价值, 被视为可视语言。不同语音的语谱图其形成纹络均有很大区别。语谱图中显示了大量的与语音的特性有关的信息, 它综合了频谱图和时域波形的特性, 明显地显示出语音频谱随时间的变化情况。所以, 语谱图所承载的信息量远远大于单纯时域和单纯频域承载信息量的总和[18]。因此可以考虑用图像处理的方法利用语谱图来进行语音信号的处理。
根据现代汉语常用词表[19]中使用频率较高的汉语普通话常用词语56 008个, 其中单音节词3181个, 双音节词语40 351个, 三音节词语6459个, 四音节词语5855个, 五音节和五音节以上词语162个, 由此可见双音节词语占所有常用词语比例的72%, 在常用词语中起到一个不可估量的作用。因此, 本文选用10个二字汉语词汇进行语音识别, 每个词汇分别用词汇编码代替, 汉语词汇表如表1所示。其中第1行为词汇编码, 第2行为汉语词汇发音, 第3行为汉语词汇含义。
| 表1 汉语词汇表 Table 1 Two words Chinese vocabulary table |
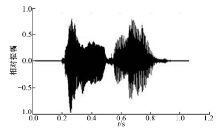
图1为某发音人词汇内容为“ 中国” 的时域波形图。图2为相应的语谱图(带宽43 Hz), 为突出重点, 本图只显示4 kHz以下部分。
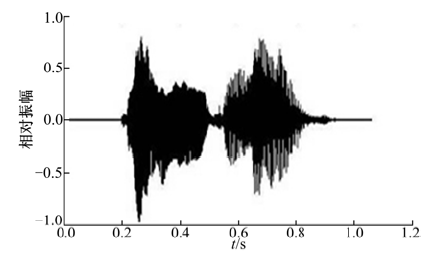 | 图1 词汇“ 中国” 的时域波形图Fig.1 Time domain waveform of “ zhongguo” |
 | 图2 词汇“ 中国” 的语谱图Fig.2 Spectrogram of “ zhongguo” |
用Cool Edit Pro 2.0软件进行语音录制, 采样率为44.1 kHz, 使得语谱图频域表达范围约为0~22 kHz, 单声道, 16 bit量化, 共10人(男、女各5个)词汇的读音样本, 10个词汇均为二字词汇, 重复10遍, 即每个词汇有10个样本, 一个词汇的语音时长约为1.2 s, 将每个词汇的10个样本截取为10个语音帧长分别为1.2 s的音频文件, 10个人的10个词汇共为1000个语音样本文件, 将所有语音样本文件转化为Matlab数据文件, 即语音样本序列。
对每个样本序列进行分帧, 帧长1024点, 重叠率为0, 窗函数采用三角窗(Bartlett), 每个样本分为51帧, 构造出1024行51列时域分帧矩阵。对时域分帧矩阵做FFT, 生成1024行51列时频分析矩阵, 频域分辨率为43 Hz。时频分析矩阵的模矩阵即为样本所对应的语谱图矩阵。由于傅里叶变换具有对称性, 取该矩阵的上半部或下半部作为语谱图即可, 因此, 每一幅语谱图的矩阵为512行51列, 共1000幅灰度图像。上述过程为本文形成了参数可调的Matlab语谱图生成程序, 以备随时调用。
为消除由于音量不同造成的各个样本幅度差异, 对每个图像矩阵均进行归一化处理。
语谱图矩阵的每一行代表着某一频率通道幅度特性随时间的变化, 行投影则反映了某频率通道在整个语音时长过程中的总体特征。如果简单的对语谱图矩阵进行行投影, 可以得到512个频率通道的投影值。但这种频域上过于细化的投影方式, 不仅对语义识别没有益处, 反而会降低识别系统的容错能力。因此, 本文采取了等宽度分带投影方式, 由于512行分成10带不是整数, 还余2行, 且高频部分信息量很少可忽略, 所以从第3行开始分, 即语谱图矩阵每51行作为一个带进行行投影, 每个矩阵可以得到10个带的投影值, 构成一个10行列向量。将每个词汇的10个样本等分带行投影所构成的10个列向量构造一个矩阵, 10个词汇形成10个10行10列的小矩阵, 即行等宽度分带投影矩阵。对每个词汇投影矩阵值的各个行求平均值和方差, 并对不同词汇语谱图矩阵对应带投影值的两两U检验发现, U检验公式如式(3)所示:
式中:
其中X1 、X2 分别为待比较的两个不同词汇对应投影带平均值; S1 、S2 分别为待比较的两个不同词汇对应投影带方差; N1 、N2分别为待比较的两个不同词汇对应投影带样本数量。
U检验结果表明, 只有分带投影矩阵的第7行数据具有显著性差异, 所以采用分带投影矩阵的第7行值作为特征数据集合。其中部分数据U检验结果表如表2和表3所示。为便于数据之间的比较, 设定数据值U> 1.96时, 取值为1; U< 1.96时, 取值为0, 得出相应投影值是否可作为识别特征值的U检验真值表如表4和表5所示。
| 表2 U检验结果(第7行特征值) Table 2 U test result(Line 7 eigenvalues) |
| 表3 U检验结果(第1行特征值) Table 3 U test result(Line 1 eigenvalues) |
| 表4 U检验真值(第7行特征值) Table 4 U test value of true(Line 7 eigenvalues) |
| 表5 U检验真值(第1行特征值) Table 5 U test value of true(Line 1 eigenvalues) |
从表2和表3中得出, 表2下三角所占1个数的概率为90%, 表3下三角所占1个数的概率为60%, 第7行和第1行的所占1个数的概率发现, 第7行的数据值具有显著性差异, 所以将第7行作为特征向量, 来进行特定人的语义识别。
从语谱图灰度图像中也发现图像的大量信息集中分布在图像的中下部分, 这一点符合人类语言信息主要分布在低频段的特征。为了便于特定人的二字词汇的语义识别更加准确, 同时又能将灰度图像的中下部分的信息更清楚地显示, 采取了二进宽度分带方法, 从第1行开始二进分, 即将每个语谱图矩阵的1~256行(带宽256行)、257~384行(带宽128行)、385~448行(带宽64行)、449~480行(带宽32行)、481~496行(带宽16行)、497~504行(带宽8行)、505~512行(带宽8行)分为7个带, 不将最后8行再分带, 是因为最后一个带的频率范围在0~200 Hz, 而人类所能听到的频率在100 Hz以上, 所以最后8行相当于只有4行是有效的, 因此不用将8行再分。将这7个带进行带投影, 构造每个词汇的7行10列二进宽度分带投影矩阵。通过对10个词汇之间对应带投影值的两两
经大量实验表明, 上述5个特征值构造出的5维特征向量的识别效果并不好。考虑到语谱图虽然反映的就是语音的时频特征, 但其可视化形式为图像, 属于二维空域信号, 基于图像处理思路, 仍可以对其进行图像频谱分析。为此, 本文对语谱图图像进行再次傅里叶变换, 傅里叶变换后语谱图的图像低频部分被分到了图像的中间部分, 将变换后的语谱图图像频域矩阵进行相应的行等宽度分带投影, 形成10个10行10列的语谱图频域的行投影矩阵。通过U检验发现, 每个矩阵的第6行到第9行适合作为特征数据集合。
加上前5个特征量, 特征量变为9个, 将这9个特征量构造为9维特征向量, 用来进行特定人的二字词汇的语义识别, 会使系统的识别率大大提高。
本次语音样本即10人的10个词汇的读音样本, 10个词汇均为二字词汇, 重复10遍, 即每个词汇有10个样本, 一共1000个样本。将10人的10个二字词汇的每前5遍词汇的语音数据作为训练集, 即前500个语音数据作为训练集, 后500个语音数据作为测试集。为方便后续的数据处理并保证程序运行时收敛加快, 防止出现奇异样本数据(指的是相对于其他输入样本特别大或特别小的样本矢量), 对1000个语音数据进行归一化的预处理, 使所有数据得到统一。
支持向量机(Supported vector machine, SVM)方法是建立在统计学习理论的VC维理论和结构风险最小原理基础上的, 对特定训练样本的学习精度和无错误地识别任意样本的能力之间寻求最佳折衷, 以期获得最好的推广能力。其中LIBSVM是台湾大学林智仁(Lin Chih-Jen)教授等[20]开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包, 它不但提供了编译好的、可在Windows系统上执行的文件, 还提供了源代码, 方便改进、修改以及在其他操作系统上应用; 该软件对SVM所涉及的参数调节相对比较少, 提供了很多的默认参数, 利用这些默认参数可以解决很多问题。该软件可以解决C-SVM、ν -SVM、ε -SVR和ν -SVR等问题, 包括基于一对一算法的多类模式识别问题。
在本文中, 将处理后的9维特征数据送到开放源码的支持向量机工具LIBSVM中去训练和检测, 采用线性核函数。在训练阶段, 将准备好的前500个语音训练样本的特征数据存入数据库, 作为支持向量机(SVM)的训练模板, 对其进行训练。在检测阶段, 将后500个语音检测样本的特征数据放入到训练好的网络中, 对相应的特定人的二字词汇进行语义识别。
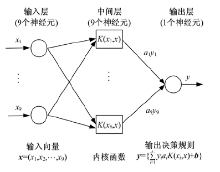
图3为本文所使用的支持向量机结构示意图, 包括输入层、中间层和输出层。首先通过非线性变换将输入空间变换到一个高维空间, 然后在这个新空间中求取最优线性分类面, 在本文中, 这种非线性变换是通过中间层定义的线性核函数来实现的, 其输出层是若干中间层节点的线性组合, 而每一个中间层节点对应于输入样本与一个支持向量的内积。
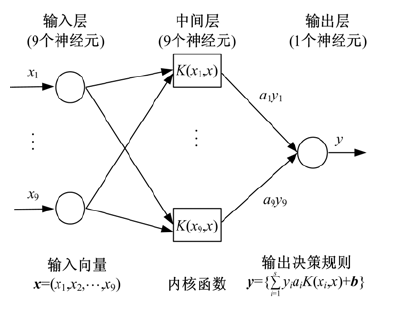 | 图3 支持向量机(SVM)结构示意图Fig.3 Structure diagram of support vector machine(SVM) |
文中支持向量机的参数是:采用支持向量机(SVM)来实现10人的10个词汇的语音识别, 由于特征向量的维数是9维, 因此输入维度是9维, 中间层内积核函数维度是9维, 本文是对10人的10个词汇的语音识别, 所以采用基数词1~10的编码方式, 即输出维度是1维, 这种方式对特定人的二字词汇的语义识别效果最佳。
从语谱图矩阵的行等宽度分带投影和二进行宽度分带投影, 以及语谱图傅里叶变换矩阵的行投影, 得出1000组数据, 每组数据由9维特征向量组合, 取500组作为训练样本, 500组作为检测样本。由于数据样本量太大, 本文只选择一个人的“ 没有” 和“ 自己” 的特征值予以显示。表6为训练样本特征值。表7为检测样本特征值。
| 表6 训练样本特征值(“ 没有” 和“ 自己” 的特征值) Table 6 Characteristic value of training samples(“ meiyou” and“ ziji” characteristic value) |
| 表7 检测样本特征值(“ 没有” 和“ 自己” 的特征值) Table 7 Characteristic value of test samples(“ meiyou” and“ ziji” characteristic value) |
通过前500组数据对多分类支持向量机进行反复训练, 得到最佳识别系统。将后500组数据放入训练好的系统中进行检测, 对10人的二字词汇的语义识别正确率可达92.8%。
语谱图矩阵及其再次傅里叶变换矩阵的行分带投影的方法实现了特定人的二字词汇的语义识别。实验结果表明, 以语谱图矩阵及其再次傅里叶变换矩阵的行分带投影值作为特征集合, 以支持向量机(SVM)作为分类器, 对特定人的二字词汇的语义识别提供了一种有效的新方法。后续可以通过扩大语音数据库样本容量来提高二字词汇语义识别的精度和准确性。另外, 该方法仅实现二字词汇的语音识别, 对于多字词汇量语音的识别还有待进一步研究。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|