




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于花环网络的偏转直通片上网络框架结构
[舒浩1  , 史江义
, 史江义1 , 马佩军1 , 潘伟涛2 , 杨林安1 ]
, 史江义, 马佩军|
|


作者简介:舒浩(1989-),男,博士研究生.研究方向:片上网络,VLSI设计.E-mail:sky-jeffery@163.com
为了实现高效率的片上网络数据传输,提出了一种偏转直通片上网络框架结构。在基于交叉开关的集中式互连和基于传统片上网络的分布式互连之间进行了权衡,提出了一种基于花环网络的混合网络拓扑结构和偏转直通路由算法。该框架可以打破传统路由算法固有的缺陷,通过缩短路由路径长度提升路由效率。实验表明:与传统XY路由及拥塞感知自适应路由相比,偏转直通片上网络框架以10%的额外硬件面积开销平均提升网络饱和吞吐率84%,降低网络功耗27.3%。
To achieve high-efficient data transmission, an efficient shoot-through framework architecture for network-on-chip is built, which makes trade-off between the centralized bus-based interconnection and the distributed NoC-based interconnection. Then, a torus-based hybrid network topology and shoot-through routing algorithm are proposed. The proposed framework breaks the inherent feature of conventional routing schemes that could remarkably reduce the length of routing path so as to improve the routing efficiency. Experimental results show that, compared with typical XY and congestion-aware adaptive routings, shoot-through framework with 10% more area overheads can improve the network saturation throughput by 84% and reduce the power consumption by 27.3% in average.
目前, 多核处理器(Chip multi-processor, CMP)及多核片上系统(Multi-processor system-on-Chip, MPSoC)已经成为公认的数字芯片设计技术。单芯片上可集成数十个不同功能的IP核[1, 2]。同时, 片内集成IP核的数目也在持续增长。因此, 片上系统设计对片内互连技术提出了更为严苛的性能和开销等方面的要求[3, 4, 5, 6]。在这种背景下, 传统基于总线的互连技术由于其功耗、扩展性、可靠性等方面的问题已经不再适用于多核/众核芯片的设计。为了解决多核互连通信问题, 片上网络应运而生。经过十多年的研究, 其已成为主流的片内多核互连技术[7, 8, 9]。
网络拥塞是片上网络设计中影响网络性能的关键因素。无论是时间维度上还是空间维度上发生的拥塞, 都会严重地限制网络性能。因此, 许多研究者提出了拥塞感知的路由算法以减轻网络拥塞程度, 进而提升网络性能[10, 11, 12, 13]。在这些设计中, 先入先出缓冲(First input first output buffer)利用率、链路状态和端口拥塞情况等通常作为拥塞信息参与到拥塞感知自适应路由算法的设计中。同时, 基于本地及区域拥塞信息的自适应路由机制也被引入到这些路由算法之中。与传统路由算法相比, 这些拥塞感知路由算法可以提升网络性能。但是, 片上网络固有的路由特性使得这些算法对网络性能及路由效率的提升十分有限。
在网络拓扑结构设计方面, Ogras等[14]首先将长连线引入到片上网络的设计中, 提出了一个基于长连线和标准二维网格拓扑的混合网络架构。该架构可以有效地提升网络性能并降低网络拥塞概率。基于这种架构, 研究者提出了许多相关的片上网络设计[15, 16, 17]。这些设计在传统的二维网格或花环拓扑结构上引入了额外的长连线数据链路, 以完成长距离报文的传输, 同时可以降低网络拥塞的概率。
在网络开销方面, 拥塞感知自适应路由算法引入了额外的状态信息; 而基于长连线的片上网络也引入了额外的数据链路, 这些都使得路由计算变得更为复杂。与传统的片上网络相比, 无论是采用拥塞感知自适应路由算法的片上网络还是基于长连线的片上网络, 都会增加硬件电路面积开销和功耗。
基于以上研究, 本文提出了一种高效的偏转直通片上网络框架结构(Shoot-through framework architecture, STFA)。在基于交叉开关的集中式互连和基于传统片上网络的分布式互连架构之间进行了权衡, 提出了一种基于花环的混合网络拓扑结构(Torus-based hybrid network-on-chip, THNoC)和偏转直通路由(Shoot-Through routing, STR)算法。在传输过程中, 报文最多只需要两跳即可到达目的节点。与前述路由算法相比, STFA可以有效缩减路由路径的长度, 进而缩短报文延迟并降低拥塞发生的概率。在网络开销方面, STFA没有引入自适应路由机制和额外的链路资源。因此, 与传统Torus网络相比, STFA的额外电路面积开销仅为10%。仿真结果表明:与传统XY路由及RCA[10]自适应路由相比, STFA算法平均可提升网络饱和吞吐率84%。在相同负载情况下, STFA算法可降低27.3%的网络整体功耗。
通常情况下, 传统的片上网络设计采用分布式的路由机制, 网络拓扑结构大部分采用二维网格或花环结构。但是, 从网络全局的角度来看, 各节点最优的选择未必是最佳的路由方案。因此, 在分布式路由机制基础上, 路由算法的改进对网络性能的提升十分有限。本文在基于交叉开关的集中式互连和基于传统片上网络的分布式互连之间进行了权衡, 提出了一种基于花环网络的混合网络拓扑结构(THNoC), 如图1所示。以花环网络为骨架网络, THNoC在每行和每列路由器之间插入了流量控制器(Traffic manager, TM)。其中, 与传统片上网络一样, 路由器主要完成报文的注入、排出以及转发; 另一方面, TM从路由器接收报文并根据同列或同行路由器总体的链路请求情况对链路资源进行分配。根据安装位置的不同, TM可以分为两类:①两行路由器之间的TM称为水平流量控制器; ②两列路由器之间的TM称为垂直流量控制器。在STFA框架中, TM是缩短网络直径和提高路由效率的关键模块。
 | 图1 THNoC拓扑结构Fig.1 THNoC topology |
维序路由是片上网络中应用最为广泛的路由算法。然而, 在基于花环拓扑结构的片上网络中, 维序路由会引起死锁问题。为了解决这个问题, 通常会使用虚通道技术进行死锁还原。与虫孔交换技术相比, 虚通道技术需要更为复杂的调度/路由算法, 会造成更大的面积开销和电路功耗。基于THNoC拓扑, 本文提出了一种偏转直通的确定性路由算法(STR), 可以避免维序路由造成的死锁问题, 进而减少虚通道引起的额外电路开销。
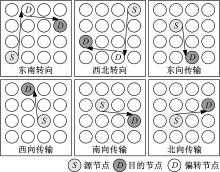
如图2所示, STR算法共包含6种报文路由路径。根据源节点与目的节点的相对位置关系, 报文路由路径可以分为两类:①直接相连, 即源节点和目的节点连接在同一个TM上。在这种情况下, 报文的传输将采用东向传输、西向传输、南向传输和北向传输路由路径; ②间接相连, 即源节点和目的节点无法通过同一个TM相连。此时, 报文的传输将采用东南转向和西北转向路由路径。从图2可以看出, 与传统的路由算法相比, STR算法可以有效地缩短路由路径长度、提高路由效率。同时, STR的路由路径不会在路径依赖关系图上产生链路回环, 因此在STR算法中不会发生死锁问题。另外, 在STR算法的路由路径选择上, 可以看出网络中每个方向上的数据链路在路径集合中出现的次数相等。这样保证了在报文的传输中网络负载均匀地分布在各个方向的数据链路上, 进而提高整体网络链路的利用率, 减少拥塞发生的概率。
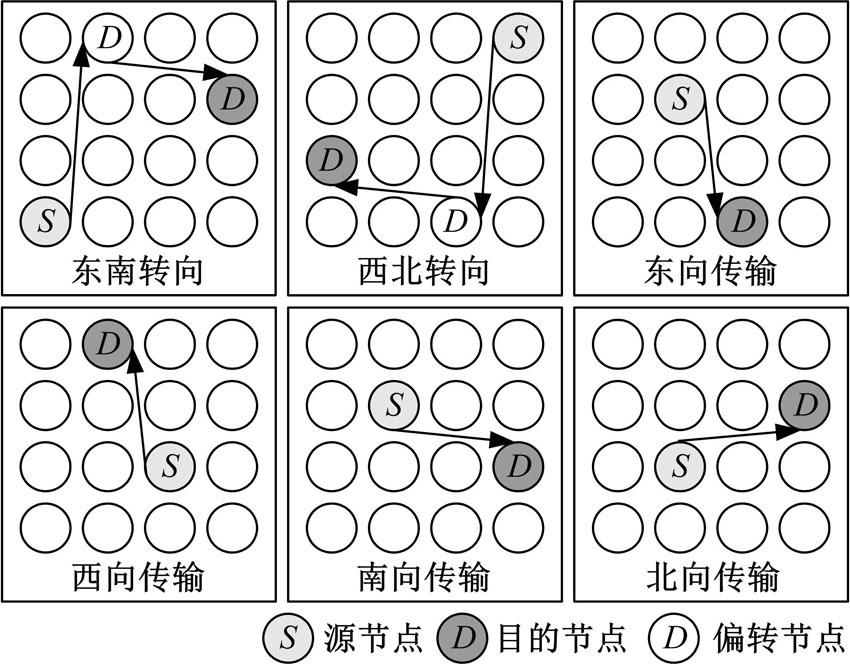 | 图2 STR路由路径集合Fig.2 STR routing path set |
在STR算法中, 报文的传输主要分为以下几个步骤。
(1)报文注入。源节点从本地端口接收报文, 根据与目的节点的关系, 源节点将报文传输至对应的输出端口。若目的节点与源节点通过TM直接相连, 报文将被传输至对应方向上的输出端口; 否则, 根据报文注入原则报文将被传输至东端口或西端口。报文注入原则将在后续部分详细介绍。
(2)TM偏转。TM从源节点接收报文, 若目的节点与TM相连, 报文将被传输至对应的输出端口; 否则, TM将报文传输至偏转节点对应的输出端口。对于采用东南转向路径的报文, 将被传输至目的节点北面一行且与当前TM相连的路由器; 采用西北转向路径的报文, 将被传输至目的节点南面一行且与当前TM相连的路由器。
(3)路由转发。偏转节点路由器从TM接收报文后, 根据路由路径的不同将报文转发至对应的输出端口。从西端口接收的报文, 将被转发至南端口; 从东端口接收的报文, 将被转发至北端口。
(4)报文到达。TM从偏转节点或源节点接收报文。此时, 这些报文的目的节点均与该TM相连。根据目的节点坐标不同, TM将报文传输至对应的输出端口, 报文在网络中的传输完成。
为了均衡网络负载分布和提高链路资源的利用率, 针对源节点与目的节点间接相连的情况, 提出了报文注入原则。根据节点坐标的不同, 源路由器为报文选择对应的路由路径。在STR算法中, 设每个节点的坐标为(x, y)。当满足(x+y)%2=0时, 节点将选择东南转向路径传输报文, 即节点作为源节点会将报文从东端口注入到网络中; 否则, 报文将按照西北转向路径进行传输, 即报文会被源节点从西端口注入到网络。
根据上述的网络拓扑及路由算法, STFA中路由器的结构如图3所示。
 | 图3 路由器结构Fig.3 Router architecture |
由于STR算法对路由路径的转向进行了限制, 进而避免了报文传输过程中的死锁问题。因此, STFA的路由器不需要使用虚通道技术, 采用了虫孔交换技术。同时, 由于STR路由路径集合的限制使得路由器中的仲裁逻辑也少于传统的路由器。东、西输入端口接收报文时, 若路由器为目的节点, 则报文将被传输至本地端口; 否则, 根据东南转向和西北转向路由路径, 报文将被传输至北、南输出端口。南、北输入端口接收报文时, 根据STR路由路径集合可知, 本路由器即为目的节点, 因此报文将被传输至本地输出端口。在输出端口方面, 东、西端口只接收本地输入端口注入的报文。南、北及本地输出端口则会接收两个方向以上的报文, 这些输出端口的控制模块使用了轮询机制对各输入端口的报文进行转发。STFA中的路由器采用了3级流水结构, 当报文到达路由器时, 首先暂存在输入端口的缓冲FIFO中。随后, 路由计算模块对报文进行路由计算并将报文请求信息传输至对应输出端口。最后, 端口控制模块根据报文请求信息进行端口授权并对报文进行传输。
在STFA中, 水平流量控制器与垂直流量控制器的结构相似。由于流量控制器主要完成链路分配及报文传输, 其各端口没有加入缓冲FIFO。在路由器的设计中, 缓冲FIFO会占路由器整体电路面积的80%以上。因此, 流量控制器的电路面积远远小于路由器的面积。图4为4× 4网络中流量控制器的结构, 其主要由端口和链路分配器组成。各端口分别与相邻的路由器连接。两个链路分配器分别负责一个方向上的报文传输。链路分配器由仲裁单元和交叉开关构成。从端口接收请求信息后, 仲裁单元进行链路分配, 进而交叉开关将报文传输至下一路由器。由STR路由路径集合可知, 在不同类型的流量控制器中, 仲裁单元的分配算法不同。在水平流量控制器中, 链路分配器_0将报文传输至目的节点相邻北面一行的输出端口, 链路控制器_1将报文传输至目的节点相邻南面一行的输出端口; 在垂直流量控制器中, 链路分配器_0和链路分配器_1均将报文传输至与目的节点对应的输出端口。
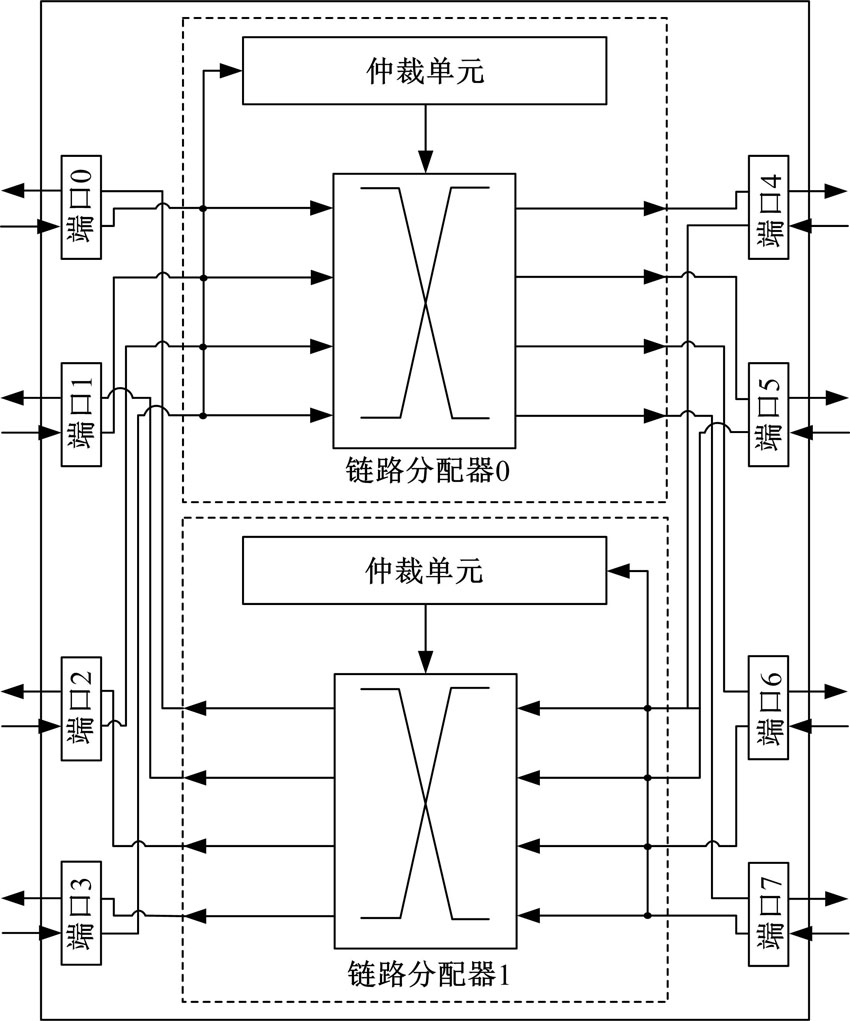 | 图4 流量控制器结构Fig.4 TM architecture |
本文开发了一个基于Verilog HDL的片上网络仿真器, 分别对STFA、XY以及RCA[10]路由进行了性能评估。评估指标包括:网络延迟和网络饱和吞吐率。仿真器的参数配置如表1所示, 其中, 报文长度为均匀分布; 仿真周期为一个时钟周期。由于STFA将长连线引入了设计中, 因此报文在路由器之间传输需要更长链路延迟。为了保证STFA的工作频率不受长连线延迟的影响, 与XY及RCA相比, STFA中报文的单跳延迟需要额外增加1个时钟周期。在网络开销方面, 也对STFA和XY算法的电路面积和功耗进行了评估。
| 表1 仿真器的参数配置 Table 1 Simulator configuration parameters |
图5为不同片上网络设计在4× 4网络及8× 8网络中的传输延迟曲线, STFA在这些合成通信模型中均实现了最好的延迟性能。各路由的网络饱和吞吐率如表2和表3所示。在4× 4网络中, 与传统XY路由以及RCA自适应路由相比, STFA将网络饱和吞吐率分别平均提升了108%和65%。其中, 在transpose、shuffle、butterfly及bit reverse四种非均匀分布中, STFA的饱和吞吐率达到了网络理论最大吞吐率(1 flits/(cycle· IP)), 这表明STFA在这些分布中可以完全避免拥塞的产生。在8× 8网络中, STFA对网络饱和吞吐率分别平均提升了116%和49.3%。在random分布下, 网络负载均匀地分布在各个节点上。此时, 网络规模的增大对STFA吞吐性能影响微乎其微, 这是因为STFA克服了传统路由方法固有的缺陷, 将数据流均匀地分布在各个节点上, 避免了在网络中心形成拥塞区域。因此, STFA在random方式下随着网络规模的增大性能退化最少。在其他通信模型下, 网络负载分布不均匀, 同时STFA属于确定性路由算法, 因此随着网络规模的增大, STFA的网络性能下降比较明显。但是, STFA与RCA相比仍能有效地提升网络性能, 这表明了STFA可以有效地提升路由效率及缓解网络拥塞。
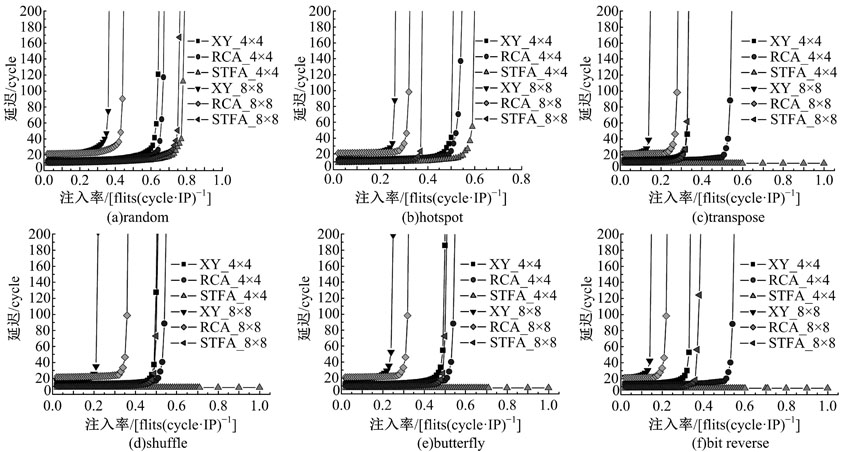 | 图5 网络延迟曲线Fig.5 Curves of network latency |
| 表2 4× 4网络饱和吞吐率 Table 2 4× 4 network saturation throughput flits/(cycle· IP) |
| 表3 8× 8网络饱和吞吐率 Table 3 8× 8 network saturation throughput flits/(cycle· IP) |
在8× 8网络中, 对网络的无阻塞延迟进行了评估。测试中, 网络注入率设为0.02 flits/(cycle· IP)。此时, 所有的片上网络设计中均不会出现网络拥塞。在没有网络拥塞发生的情况下, 报文的传输延迟与网络路由路径的长度成正比。如表4所示, 在6种通信模型下, 与XY和RCA相比, STFA可以将网络无阻塞延迟平均分别降低51.2%和53.3%。因此, 实验数据说明了STFA可以有效地缩短路由路径长度, 进而提高了路由效率。另外, 从理论上计算, 与XY及RCA相比, STFA可以减少2/3以上的节点跳数。而实际上, 传输延迟在STFA中只减少了约50%。这是由于在报文传输中STFA需要额外的时钟周期以解决长连线延迟。
| 表4 网络无阻塞延迟 Table 4 Network non-blocking latency |
在网络开销方面, 使用Verilog硬件描述语言分别对XY路由和STFA框架进行了RTL级实现, 并对各算法的电路面积及功耗进行了评估。网络规模为8× 8, 电路综合使用了SMIC 65 nm工艺库, 工作频率设定为1 GHz。同时, 各算法的参数配置如表1所示。表5为XY和STFA的面积开销。从表4可以看出, STFA引入的TM只占到路由器电路面积的10%左右。另一方面, STFA路由器的面积开销小于XY路由器。但是, STFA整个网络的电路面积比XY增加了10%。这是由于STFA采用了基于长连线的拓扑, 因此STFA需要更多的连线面积开销。
| 表5 网络硬件开销 Table 5 Network hardware overheads |
图6为网络的功耗。网络功耗的评估使用了random分布, 注入率设定为0.2 flits/(cycle· IP)。由于STFA有效地缩短了路由路径长度并提升了路由效率, 因此STFA中路由器的功耗要远远小于XY中路由器的功耗。其中, 路由器功耗来源包括:缓冲FIFO、仲裁器和交叉开关3个部分。另外, 从图6中可以看出:STFA降低的数据链路功耗没有其他模块显著, 这是因为STFA尽管没有增加数据链路的数目, 但是其使用了更多的长连线数据链路。单条长连线数据链路的功耗要大于花环网络中的数据链路。从总体上看, 与XY路由算法相比, STFA可以降低27.3%的网络功耗。
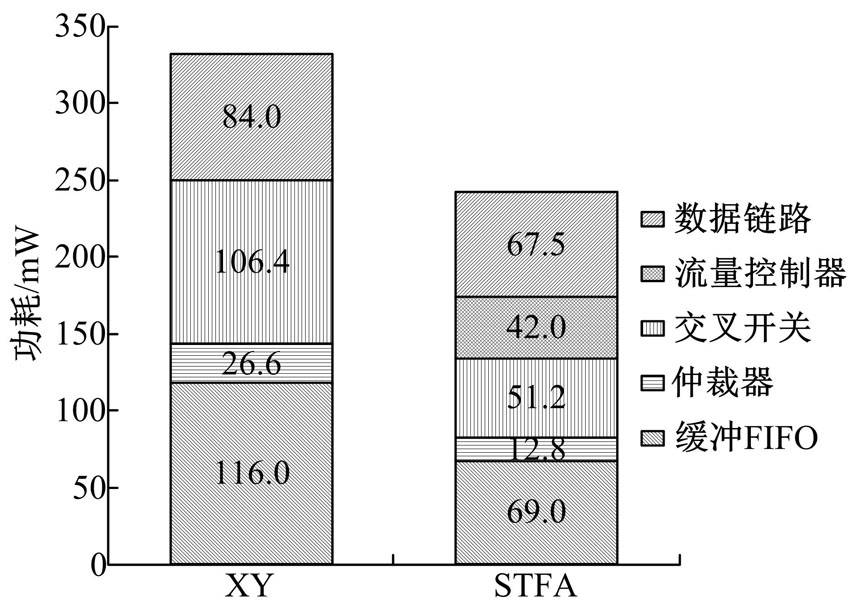 | 图6 网络功耗Fig.6 Network power consumption |
在基于交叉开关的集中式互连和基于传统片上网络的分布式互连之间进行了权衡, 提出了一种基于花环网络的混合网络拓扑结构, 并提出了一种偏转直通的路由算法。该片上网络框架结构打破了传统路由算法固有的缺陷, 缩短了路由路径长度、提升了路由效率, 同时可以有效减少网络拥塞的概率。实验结果表明:与传统XY路由及自适应RCA路由相比, STFA以10%的额外硬件面积开销平均提升网络饱和吞吐率84%, 降低网络功耗27.3%。由于STR属于确定性路由算法, 所以在大规模网络中仍会受到网络拥塞的影响进而限制网络性能的提升, 在后续的工作中, 会将自适应路由机制及拥塞控制机制引入到STFA框架中。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|