

{kind=link}
{kind=link}
{kind=link}
{kind=link}
改进粒子群优化BP神经网络的目标威胁估计
[黄璇1, 2  , 郭立红
, 郭立红1 , 李姜2 , 于洋2 ]
, 郭立红, 李姜|
|


作者简介:黄璇(1988-),男,博士研究生.研究方向:多源引导信息融合.E-mail:huangxuan@ceprei.biz
为了提高目标威胁估计精度,提出一种运用改进粒子群算法优化BP神经网络的方法。为了避免陷入局部极值,将变异过程引入粒子群算法中,并对相关参数进行优化,形成改进粒子群算法,对BP神经网络的初始权值和阈值进行优化。利用样本数量不同的训练集对网络进行训练,并用60组测试集数据对网络进行验证。实验结果表明,改进粒子群优化BP神经网络目标威胁估计算法具有更高的预测精度,在训练样本数量较小时能够获得较好的预测能力,可以有效地完成目标威胁估计。
An algorithm for target threat assessment based on Back Propagation (BP) neural network optimized by Modified Particle Swarm Optimization (MPSO) is proposed to improve the prediction accuracy of target threat. In this MPSO algorithm, mutation operator and optimization for several parameters are introduced in PSO to avoid the particle plunging into the local optimization. The MPSO algorithm is employed to optimize the initial weights and thresholds of the BP neural network. Then the BP neural network optimized by MPSO is trained by training sets of different sample sizes. 60 sets of target threat data are adopted to test the performance of MPSO-BP in target threat prediction. Experimental results show that the prediction accuracy of target threat assessment algorithm based on MPSO-BP is higher than that based on some traditional algorithms, which proves the efficiency of the proposed algorithm in solving target threat assessment problem in spite of the small sample size of training set.
对敌方目标进行威胁估计, 主要是对其杀伤能力和威胁程度进行估计。威胁估计在信息融合模型中处于第3级, 对于估计作战事件出现的严重程度有重要作用, 为决策和指挥提供支持。目前常用的目标威胁估计方法包括Bayes推理[1]、直觉模糊集[2]、层次分析法[3]、Vague集[4]、支持向量机等[5, 6]。
近年来, 智能技术, 特别是神经网络技术在控制[7, 8]、图像处理[9]等领域得到了广泛应用。文献[10]成功地将BP(Back propagation)神经网络应用于目标威胁估计之中。但是, 神经网络容易陷入局部极值, 特别是对于处理小样本、高维度问题, 其收敛速度会变慢, 网络性能也会变差。此外, 一旦初始权值和阈值选取不恰当, 将使其难以收敛, 无法获得较好的预测效果。
粒子群优化(Particle swarm optimization, PSO)算法是一种较新的群智能优化算法, 可以对各种连续和离散问题的参数进行寻优操作, 具有精度高、收敛快的特点, 在目标跟踪[11]、参数辨识[12]、信号处理[13]等领域有较好的应用。然而PSO算法也具有容易陷入局部最优解的缺点, 导致经过寻优获得的参数在处理BP网络小样本训练问题时可能还不如未经优化的网络。
为解决PSO算法容易陷入局部极值的问题, 本文对PSO算法的相关参数进行改进, 并引入变异运算, 形成改进的粒子群优化(Modified particle swarm optimization, MPSO)算法, 以此建立改进粒子群优化BP神经网络(BP neural network optimized by modified PSO, MPSO-BP)算法。运用个体粒子代表网络的权值和阈值, 以网络的预测误差作为个体粒子的适应度, 通过MPSO算法对粒子进行寻优, 得到最优解, 并以此来构造BP神经网络。最后, 采集样本数量不同的目标威胁估计训练集对MPSO-BP进行训练, 运用测试集数据验证网络的预测性能, 并与BP、PSO-BP算法的性能进行比较。
PSO算法[14]是一种经典的群智能算法, 由以下4部分构成:①初始化; ②适应度计算; ③极值更新; ④位置和速度更新。
假设在S维空间中, 种群X=(X1, X2, …, Xn)中的每一项代表一个粒子。各项有其相应的位置, 即优化问题的一个可能的解, 用S维向量Xi=
式中:k代表当前处于第k次迭代; ω 为惯性权重; j=1, 2, …, S; c1和c2分别为局部加速因子和全局加速因子; r1和r2为[0, 1]间随机数; ω
粒子根据自身和全局的经验向最优位置搜索移动。迭代时需保证x∈
基本PSO算法使用简单、寻优速度较快, 但同时也存在如下问题:
(1)局部极值问题:算法迭代时, 所有粒子都向当前最优解移动, 种群搜索空间不断缩小, 形成粒子种群快速趋同效应[15], 但是此时的最优位置可能只是某一局部搜索空间里的最优位置, 搜索陷入局部极值之中, 导致早熟收敛, 失去粒子之间所需要保持的多样性。
(2)收敛精度问题:粒子在搜索移动时, 受惯性行为ω
基本PSO算法的这些问题会导致当训练样本数较低时, 对网络进行优化后的预测误差甚至会大于未经过优化的。因此, 为了提高预测精度, 使其能在小样本训练中发挥作用, 需对PSO算法进行改善。
局部极值的产生, 是基本PSO算法在迭代更新时由于粒子对自身和全局环境认知的分配不均而引起的。因此需要在迭代过程中, 对粒子的自身历史能力认知和全局环境认知进行动态分配。基于此, 对基本PSO算法进行如下改进:
(1)对参数的改进
惯性权重ω 用于保持运动的惯性, 调节所搜索区域的大小, 而因子c1和c2则代表了将其推向Pi和Pg的权重。在迭代初期, 粒子应在一个较大的范围内去搜索最优解, 并且粒子移动应以自身认知为主, 保持粒子的多样性, 故此时ω 和c1应较大而c2较小; 而在迭代后期, 粒子应更多地受控于此时的全局最优解, 并在其附近进行精细的局部搜索, 故此时ω 和c1应较小而c2较大。基于此, 本文在每次迭代时对3个参数进行如下操作:
式中:ω 0、ω 1分别为ω 的起始取值和最终取值; c10、c11分别为c1的起始取值和最终取值; c20、c21分别为c2的起始取值和最终取值; k、K分别为迭代次数的当前取值和最大取值。
c1随着迭代次数线性递减, c2则线性递增, 并且初始的c10应大于c20, 终止时的c11小于c21, 即迭代初期侧重于自身认知, 末期侧重于全局认知, 从而保证粒子对自身认知能力和全局认知能力的动态分配。ω 按照余弦函数递减, 既保证了迭代开始阶段能快速搜寻最优解且持续较长时间, 不至于过早地陷入局部搜索, 又能在迭代后期以一个较为平缓的速度变化率去进行精细搜索。
(2)引入变异操作
为进一步扩大搜索空间, 减小出现局部极值的可能, 每次更新之后, 对粒子按照一定的概率p重新初始化, 即:
式中:a为[0, 1]内的一个随机数, 决定粒子朝向最大或最小的方向变异。
变异概率p由式(5)确定:
式中:p0、p1分别为p的起始取值和最终取值, 令p0< p1, 使得p的取值按余弦函数递增。
由于迭代初期的搜索空间较大, 因而变异概率可以较小, 粒子在前述3个参数确定的范围内搜索和移动即可; 而迭代后期由于粒子向最优解移动, 搜索空间范围已经较小, 此时加大变异概率可以进一步防止陷入局部极值。
作为一种高级信息融合过程, 威胁估计是在综合考虑敌方破坏力、运动能力、机动能力等因素的基础上, 对敌方的战术含义和威胁程度或严重性进行估计。按照属性特征划分, 威胁估计因素包括目标速度、航向角等定量因素和目标类型、干扰能力等定性因素。本文选取目标速度(V)、目标航向角(θ )、目标高度(H)、目标距离(R)、目标类型、目标干扰能力6个典型指标, 构建如图1所示的MPSO-BP算法。
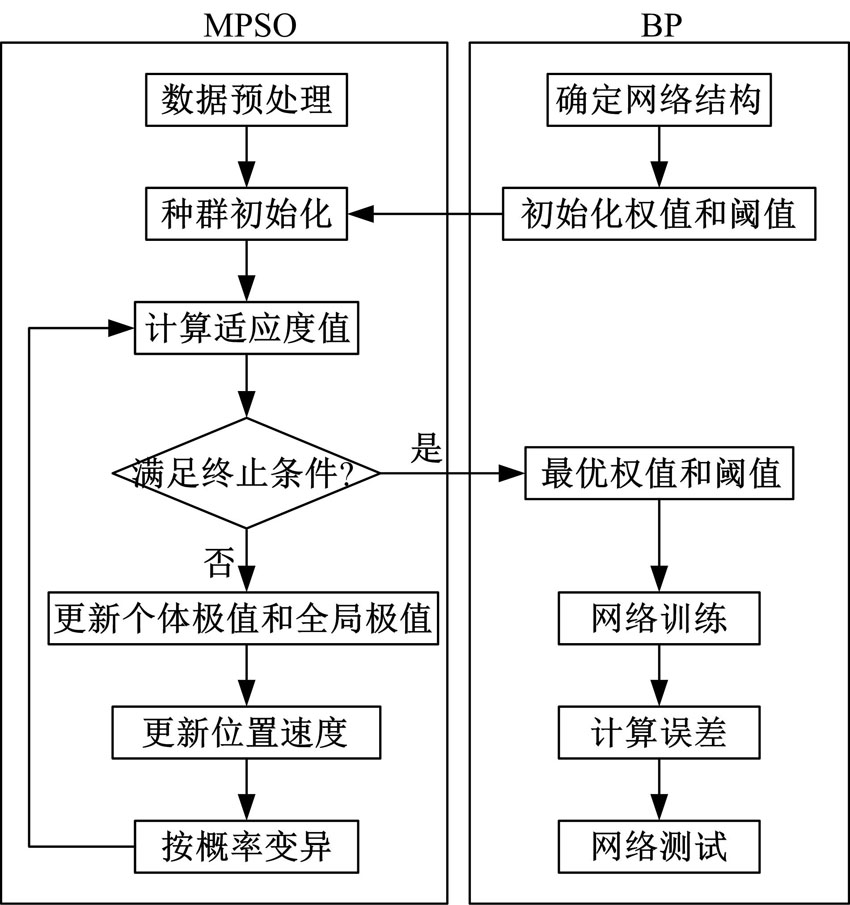 | 图1 MPSO-BP算法流程图Fig.1 Flowchart of MPSO-BP algorithm |
该算法可以分为两部分, 一是图中左侧的MPSO优化部分; 二是图中右侧的网络训练部分。运用左侧MPSO的粒子代表右侧所确定网络的权值和阈值, 以右侧网络所求得的预测误差作为此粒子的适应度, 以适应度值为基础按照MPSO方法对粒子进行寻优, 通过迭代更新找到最优的个体粒子, 以此作为网络的初始权值和阈值。
(1)初始化
包括网络结构的确定、种群的编码以及各个参数的选取。其中, 采用三层网络结构, 每个个体需包含全部的权值和阈值, 即输出层(Output layer)与隐层(Hidden layer)、隐层与输入层(Input layer)的连接权值以及输出层和隐层的阈值。因此, 粒子的维度S应为:
式中:Sin、Sh、Sout分别为输入层、隐层和输出层的结点数。
对于目标威胁估计问题, 6个典型指标对应6个输入层, 网络输出为威胁估计值, 因此输出层结点数为1, 隐层有11个结点。维度S=89, 包含77个权值和12个阈值。
(2)适应度函数选取
将误差作为MPSO的适应度, 即:
式中:
(3)迭代更新
在MPSO优化阶段, 利用式(7)计算每个粒子的Fi, 以此确定每次的Pi和Pg; 利用式(1)(2)对位置xi和速度vi进行更新, 每次更新时, 利用式(3)确定各个参数的取值; 在每次更新后, 按照式(5)确定的概率重新对xi初始化(见式(4))。
更新后, 重新计算适应度Fi, 并根据Fi更新Pi和Pg的取值。重复迭代操作, 直至满足k=K, 从而获得最优解。
运用Matlab R2009a, 编程实现MPSO-BP目标威胁估计算法。从目标威胁数据库中按均匀分布随机抽取300组原始数据作为训练集, 按照目标类型分类, 大型目标、小型目标、直升机各100组数据。再用同样的分类方式抽取60组数据组成测试集。部分的原始数据如表1所示。原始数据需在归一化后再注入到MPSO-BP算法中。
对于MPSO部分, 设置种群规模n=30; 最大迭代次数K=300; 粒子位置区间为[-5, 5], 粒子速度取值区间为[-1, 1]; 其他变化的参数为:c10=2.5、c11=1.25、c20=0.5、c21=2.5、P0=0.05、P1=0.35、ω 0=1以及ω 1=0.1。网络部分, 设置学习率为0.1, 训练目标为1.0× 10-5。
| 表1 部分原始数据 Table 1 Part of original data |
为了验证MPSO-BP目标威胁估计算法的有效性, 本文采用BP网络和PSO-BP网络解决目标威胁估计问题。对于前者, 其参数设置与本文方法的BP部分相同; 对于后者, 则不引入变异过程且设置c1=1.4、c2=1.6、ω =1, 其余部分与本文方法相同。
采用经过全部训练集数据训练后的3种方法对全部威胁估计测试数据进行预测。获得各方法的预测结果及误差如图2所示。
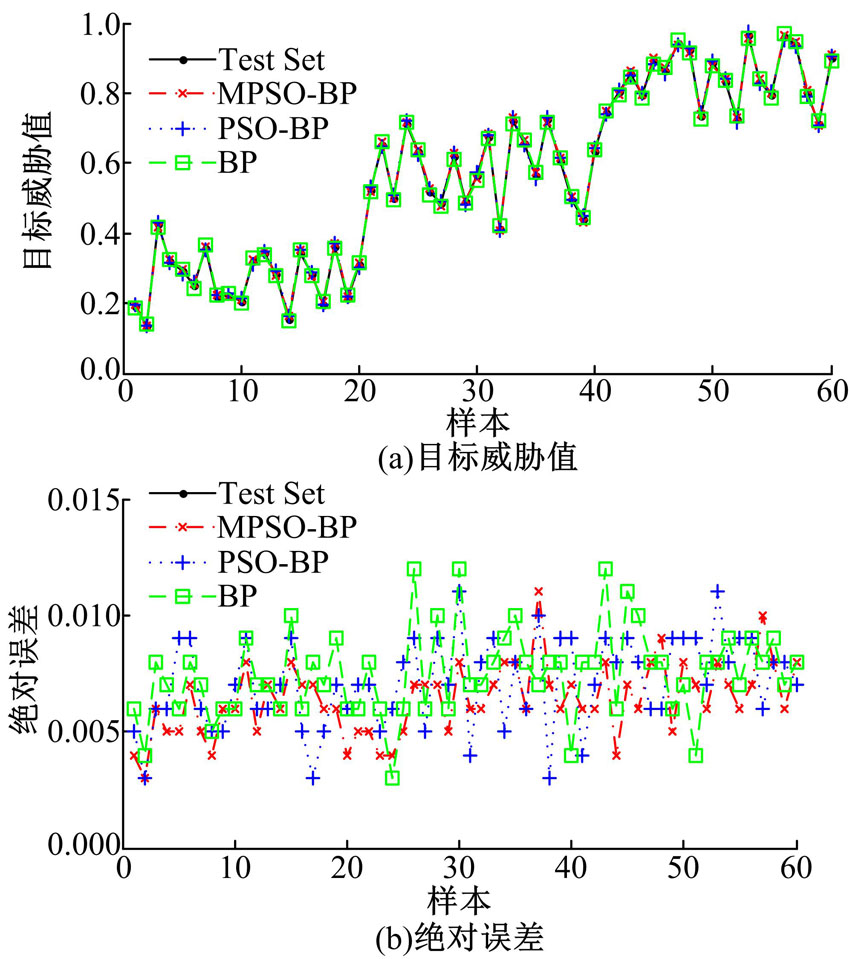 | 图2 训练集样本为300时的预测结果及误差Fig.2 Predictive results and errors with 300 training samples |
从图2中可以看出, 3种算法都可以较好地对60组测试集数据完成目标威胁估计, 绝对误差均不大于0.012, 大都在0.01以内。在其中的41个样本点处(约占总样本量的2/3), MPSO-BP网络的预测误差要小于另外两种算法, MPSO-BP的绝对误差平均值也是三者中最小的。
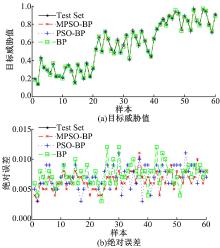
从300组训练集数据中按照目标类别1∶ 1∶ 1的比例随机抽取150组, 同样再对3种网络进行训练, 采用训练好的3种网络对同样的测试集进行目标威胁估计, 预测结果及误差如图3所示。
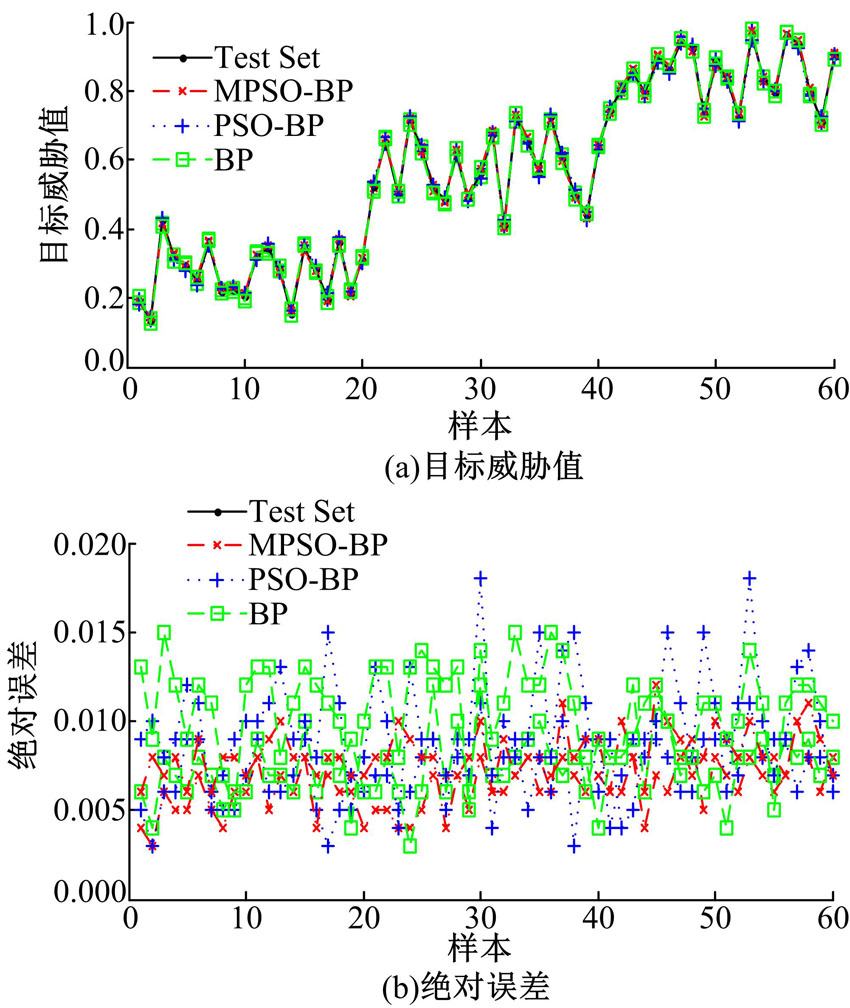 | 图3 训练集样本为150时的预测结果及误差Fig.3 Predictive results and errors with 150 training samples |
从图3可以看出, 当训练样本数量减少为150时, 3种算法的预测误差均有所增加, PSO-BP和BP网络的平均误差增加约40%。而本文网络的预测误差基本都小于0.01, 展现出较好的预测能力。
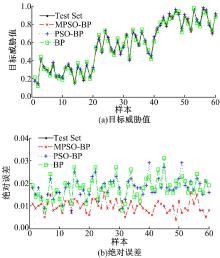
从300组训练集数据中按照目标类别1∶ 1∶ 1的比例随机抽取75组, 同样对3种网络进行训练, 并对同样的测试集进行目标威胁估计, 结果及误差如图4所示。
 | 图4 训练集样本为75时的预测结果及误差Fig.4 Predictive results and errors with 75 training samples |
从图4可以看出, 当训练样本数量减少为最初的1/4时, PSO-BP和BP网络的误差急剧增加, 后者的最大误差达到了0.031, 而前者的平均误差甚至要大于后者, 没有展现出算法应有的优化效果。而本文方法的预测误差集中在0.01附近, 并且平均值小于0.01, 展现出较好的预测能力。
表2给出了在经过不同样本数量的训练集数据训练后, MPSO-BP网络、PSO-BP网络和BP网络对于60组目标威胁估计测试集数据的绝对预测误差的平均值。
从图2~图4和表2误差的变化可以看出, 当所采用的训练集中样本数量较大时, 3种网络的精度相当, 都能较好地解决目标威胁估计问题, MPSO-BP的预测误差略小于另外两种网络。而当所采用的训练集中样本数量较小时, PSO-BP方法容易产生局部极值, 其预测误差反而大于未经优化的原始网络。而对于MPSO-BP算法, 由于加入了变异过程, 可以有效地避免粒子种群快速趋同效应, 其预测结果最接近真实值, 预测误差为三者中最小, MPSO-BP算法通过较小的训练代价即可获得较高的预测精度。
| 表2 三种网络在不同样本数下的绝对误差平均值 Table 2 Average of absolute predictive error of three networks with different quantities of training set |
根据目标威胁估计的特点, 综合考虑各种影响因素, 提出了基于MPSO-BP的目标威胁估计方法。选取6个典型指标, 在训练集样本数量不同的情况下分别对BP网络、PSO-BP网络和MPSO-BP网络进行仿真实验比较。结果表明:在训练集较少的情况下, 本文方法能够克服快速趋同效应的影响, 降低陷入局部极值的可能, 其预测误差小于另外两种网络。因此, 基于改进粒子群算法优化的BP神经网络具有良好的预测能力, 可以有效地完成对作战目标威胁的估计。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|