




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多级图像序列和卷积神经网络的人体行为识别
[马淼 , 李贻斌]
, 李贻斌]
, 李贻斌]
|
|


作者简介:马淼(1989-),女,博士研究生.研究方向:机器视觉,智能机器人,模式识别与智能系统.E-mail:mamiaosdu@hotmail.com
首先,构造出能获得更丰富人体行为信息的四级图像序列结构,并分别用卷积神经网络进行处理,从而得到包含表观、运动、前景和背景信息的特征。然后,提出了一种对视频中行为进行分解的方法,将完整行为分解为由粗略到细致的子行为,从而得到更细致的人体行为描述,获取到更具代表性的行为特征。最后,通过两个行为数据集上的验证及对比实验证明了该方法可有效提高行为识别的准确度。
A multi-level image sequences and convolutional neural networks human action recognition method is proposed. First, a four-level image sequence structure is constructed, which is able to obtain richer information of human actions. Then the four-level image sequences are processed by convolutional neural networks. This structure is able to use appearance, motion, foreground and background information more sufficiently. Besides, a decomposition method of video sequence is proposed, which is able to acquire more detailed human activity information. This method decomposes each level sequence into sub-sequences, and represents actions from coarse to fine, thus, achieving more representative human activity features. The efficiency of the proposed method is verified by two challenging human action databases. The experiment results show that the proposed method improves the action recognition accuracy efficiently.
视频中人体行为的认知和理解是人工智能的一项重要任务, 并有广泛的应用, 例如人机交互、智能空间、虚拟现实、机器人社会等。近年来视频中人体行为识别得到了广泛的关注, 构造行为识别特征的方法也层出不穷, 现有的行为识别方法大致可划分为三种。第一种是基于图像局部特征检测的方法。例如有些学者使用方向梯度直方图(HOG)或尺度不变(SIFT)检测子来提取视频中的形状信息[1, 2], 并用光流直方图(HOF)或运动边界直方图(MBH)特征提取视频中的运动信息[3, 4], 然后用词包的形式进行编码[5], 并训练分类器识别人体行为[6]。然而这种获取行为识别特征的方法是将视频图像中提取的局部特征通过手工制造得到高维的特征, 因此针对性较强, 通用性较差。另外, 有一些学者通过构建多级体系结构分级进行行为识别[7, 8], 例如有些算法采用第一级结构对视频进行多种时空分割并得到所有可能的包含人体区域的分割结果, 再在第二级中利用时空信息对分割结果进行推理, 从而获得有效的人体行为特征[9]。虽然这种分层级的方法能够更好地融合时间与空间信息, 但在每个层级中的处理仍然依赖于手工制造的特征。此外, 近年来还有一些学者提出使用深度神经网络进行行为识别, 例如有学者提出使用卷积神经网络[10](Convolutional neural network, CNN)获取视频的表观特征与运动特征[11, 12], 并将得到的特征进行分析与融合, 从而获得有效的行为识别特征[13]。这种方法的性能与通用性超越了手工制造特征的方法, 但由于卷积神经网络以静态图像块作为输入, 因此如何构造出有效融合时空信息的行为识别特征仍有待探索。
针对上述方法中存在的问题, 本文提出了一种生成含有不同时空信息的四级图像序列, 并分级使用卷积神经网络构造行为识别特征的新方法。首先, 利用原视频序列计算对应的光流图序列, 并用人体检测方法得到原视频序列中每帧图像的人体区域位置, 从而得到原视频序列、人体区域视频序列、光流序列以及人体区域光流序列这四级并行的图像序列。然后, 对每级图像序列中的每幅图像计算出CNN特征。再对原视频序列中的图像进行处理得到关键帧的索引号, 从而通过构造二叉树将每级图像序列分解为视频子段。在每级序列中对图像序列及其子序列进行计算, 得到代表每级图像序列的CNN特征。之后, 将四级图像序列的CNN特征连接得到视频的人体行为特征。最后, 训练分类器对特征进行分类, 确定视频中人的行为。
通常一段视频所包含的信息可以分为空间信息与时间信息。空间信息以视频中每一帧图像的形式表现出来, 如视频中出现的场景物体等; 时间信息则以帧与帧之间运动变化的形式表现出来, 如观测者或相机的运动以及场景中物体的运动。为了更好地获取视频中的空间及时间信息, 除了使用原始视频序列以外, 我们还生成了另外3级图像序列。
为得到更多的运动信息, 用文献[14]中提出的光流图计算方法获取视频图像序列对应的光流图像序列。由于光流图反映两张连续图像之间的运动, 因此光流序列的长度与原图像序列长度不一致(光流图序列比原图像序列短一帧)。为得到长度一致的序列, 本文用式(1)的方法计算光流, 即第一幅光流图
式中:It-1 、It和It+1 分别表示第t-1, t及t+1帧图像; fflow (• )表示用文献[14]方法计算两帧图像之间的光流图。
依据卷积神经网络[14]对输入图像的尺寸及结构的需求, 需要对光流图
然后, 将尺寸为
在视频序列中每幅图像都包含前景与背景, 前景主要包含人体姿态及运动的信息, 而背景中还包含了人与环境进行交互的信息。为了更加突出人体姿态及运动的信息, 用人体区域估计的方法[16]从原始视频序列中提取出连续的人体区域图像序列, 同时从光流序列中提取出对应的人体区域光流序列, 得到四级图像序列。
这四级图像序列中的每一帧图像将分别作为卷积神经网络的输入, 因此需要将每级图像序列中的每帧图像尺寸进行调整。本文将每级序列中的每帧图像尺寸调整为224× 224。所得的四级图像序列如图1所示。
 | 图1 四级图像序列Fig.1 Four-level image sequences |
本文提出的四级图像序列中既含有RGB图像, 又含有光流图像。在计算每级图像序列的CNN特征时, 考虑到RGB图像及光流图像性质的不同, 采用两个结构相似的CNN来分别提取RGB图像与光流图像的CNN特征。本文使用的两个CNN结构都分别含有5个卷积层和3个降采样层, 如表1所示。
| 表1 卷积神经网络结构 Table 1 Structure of convolutional neural networks |
表1中的C表示卷积层; S表示降采样层; F表示全连接层。对于第1级的原视频图像序列以及第2级的人体区域图像序列, 采用[17]提出的CNN结构, 如表1中第2行所示。表1中卷积层的(n1× k1× k1)表示使用n1个k1× k1的核; 降采样层的(k2× k2)表示使用k2× k2的核。此CNN结构是由ILSVRC-2012训练集[18]训练得到的。对于第3级的光流图像序列以及第四级的人体区域光流序列, 本文采用[15]提出的CNN结构, 如表1中第3行所示。此CNN结构是由UCF101训练集[19]训练得到的。
原视频序列和人体区域视频序列中的每一帧图像被送入第一个CNN作为输入, 并取第2个全连接层(表1中的“ F7” )输出的4096维向量作为其对应的CNN特征, 分别记为
假设一段视频的长度为T, 将四级图像序列中的每帧图像{It |t=1, 2, …, T}通过卷积神经网络得到的向量
人体行为虽然是连续的, 但是连续帧之间的图像变化的程度却不同, 并且每帧图像对行为识别的贡献也不相同。通过观察发现视频中含有冗余的帧, 视频中人体的运动可以由关键帧[20]来表示而不需要使用视频中的所有帧, 通过关键帧图像信息的变化即能识别出运动类型, 如图2所示。针对这个问题, 本文提出了一种获取视频中关键帧的方法。
将原视频图像序列(图1中的第1级序列)中所有帧得到的4096维CNN特征向量排列成T× 4096的矩阵, 剔除其中全为0的列, 将剩余的矩阵记为C, 取出矩阵C中的最大值记为m。然后将矩阵C的每一行Ct中的每个元素转换为log2 m (向上取整)位的二进制序列, 记为
 | 图2 视频序列中的关键帧Fig.2 Extract key frames from a video sequence |
 | 图3 将十进制序列转换为二进制序列Fig.3 Transform decimal sequence into binary sequence |
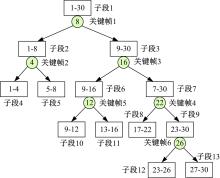
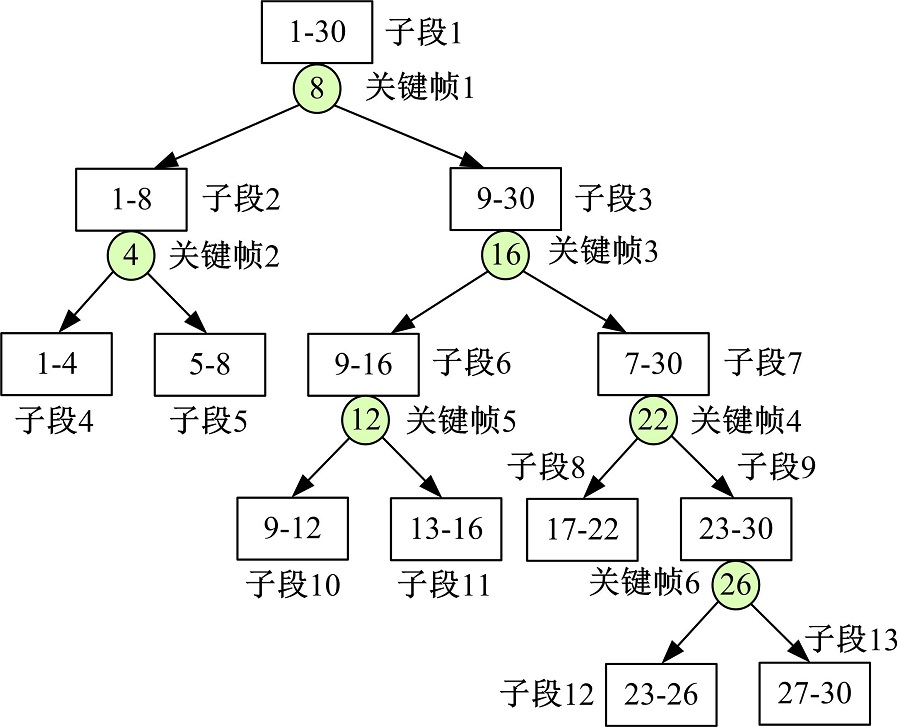 | 图4 视频子段二叉树Fig.4 Binary tree for generating sub-sequences |
按照t=2, 3, …, T的顺序计算
假设原视频帧索引序列为{1, 2, …, T}, 用有顺序的k个关键帧的索引号依次对视频段进行切割, 每次切割时将关键帧索引号归于前一个子段, 从而得到2k+1个视频子段。用图4中的例子详细说明得到视频子段的过程。图4中假设视频中含有T=30帧图像, 得到的k=6个有顺序的关键帧的索引号为[8, 4, 16, 22, 12, 26], 用第1个关键帧
将得到的视频子段对应的帧索引记为{sj|j=1, 2, 3, …, 2k+1}, 其中j表示由二叉树得到的第j个视频子段。对图1中的每级图像序列{i|i∈ [1, 2, 3, 4]}, 用每个子段的最后一帧对应的CNN特征减去本子段第一帧对应的CNN特征, 从而得到一个差值向量, 然后分别计算所有视频子段得到的差值向量中每一维的最大值与最小值, 将得到的向量分别记为
式中: {d|d∈ [1, 2, …, 4096]}表示向量的第
另外, 对每级图像序列
基于上述计算, 本文构造出了视频的行为识别特征向量:

此特征向量的维数为64K维, 其中前16K维包含视频图像中前景与背景的表观信息; 紧接着的16K维包含视频图像中前景与背景的运动信息; 接下来的16K维包含视频图像前景的表观信息; 最后16K维包含视频图像前景的运动信息。也就是说, 我们得到的行为识别特征向量
使用两个人体行为数据集来验证本文提出的人体行为识别方法, 这两个数据集分别是中佛罗里达大学计算机视觉研究中心提出的UCF Sports人体行为数据集[24]和马克斯普朗克研究所智能系统研究中心提出的sub-JHMDB人体行为数据集[25]。
UCF Sports数据集[24]中有包含10种行为的150段视频, 这十种行为分别是:跳水、打高尔夫、踢腿、举重、骑马、跑步、滑板、在跳马上旋转、在单杠上旋转和漫步。其中有103段视频用于训练, 其余47段视频用于测试。
sub-JHMDB数据集[25]中有包含12种行为的316段视频, 12种行为分别是:接住、爬楼梯、打高尔夫、跳跃、踢球、拾起、引体向上、推、跑、投球、打棒球和漫步。数据集中给出了3种训练/测试集的分离方式, 本文采用其中的第3种进行实验, 其中有224段视频用于训练, 其余92段视频用于测试。
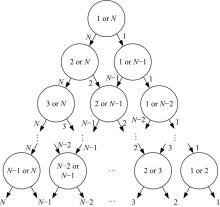
本文采用线性多类分类器实现人体行为的分类。线性分类器的个数
以sub-JHMDB数据集为例, 由于数据集中含有12种人体行为, 因此需要训练66个线性分类器, 分类器结构如图5所示, 其中每个圆形代表一个两类线性分类器, N表示第N类行为。类似地, UCF Sports数据集中含有10种人体行为, 因此需要训练45个线性分类器。
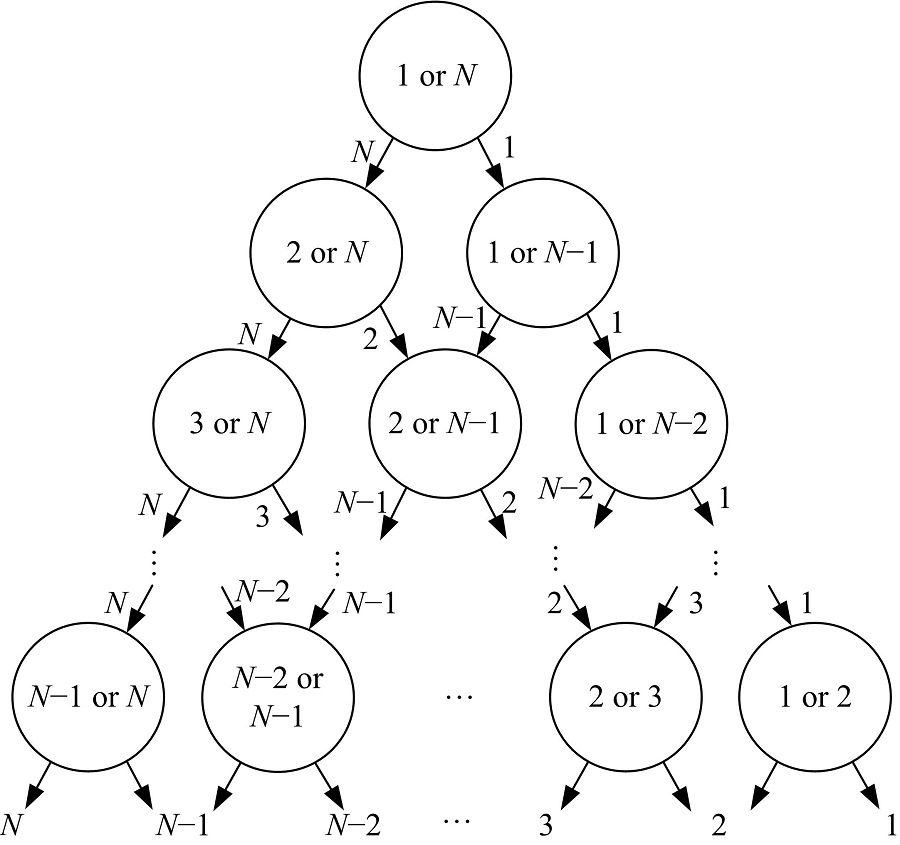 | 图5 针对sub-JHMDB数据集训练行为识别分类器Fig.5 Train the SVMs for the sub-JHMDB dataset |
对UCF Sports数据集构造式(5)所示的人体行为识别特征向量, 并用训练集中的样本训练如图5所示的线性多类分类器, 对测试集中的行为样本进行分类, 得到的人体行为识别结果如图6所示。对sub-JHMDB数据集, 本文用类似的方法获得行为识别特征向量并训练线性多类分类器, 然后对测试集中的行为样本进行分类, 得到的人体行为识别结果如图7所示。
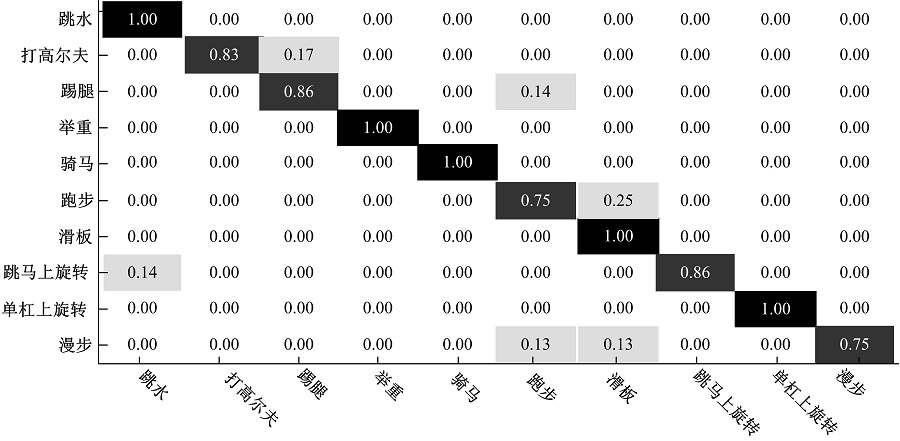 | 图6 UCF Sports数据集分类结果Fig.6 Action recognition results of UCF Sports dataset |
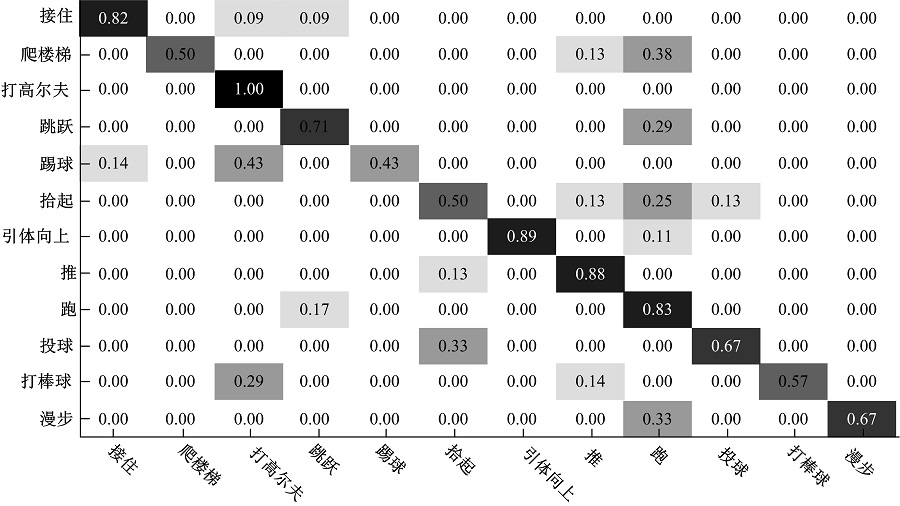 | 图7 sub-JHMDB数据集分类结果Fig.7 Action recognition results of sub-JHMDB dataset |
从图6的混淆矩阵中可以看出, 本文方法能够准确识别UCF Sports数据集中的跳水、举重、骑马、滑板和单杠上旋转行为, 对打高尔夫、踢腿、跑步、跳马上旋转和漫步行为的正确识别率分别为83%、86%、75%、86%以及75%。本文方法对UCF Sports数据集中10种行为的平均识别率为90.5%。
表2中列出的不同行为识别方法的行为识别率对比表明, 本文方法比Souly与Shah提出基于视觉角点的识别方法[7]的平均行为识别率提高了5.2%; 比Le等[8]提出的利用独立子空间分析及层级不变性的时空特征的人体行为识别方法的平均行为识别率提高了3.8%; 比Wang等[4]提出的基于密度轨迹的行为识别方法的平均行为识别率提高了1.2%。
| 表2 对比实验结果 Table 2 Comparison experiment results |
从图7的混淆矩阵中可以看出, 本文方法能较准确地识别sub-JHMDB数据集中的打高尔夫、接住、引体向上、推、跑以及跳跃, 对应的行为识别率分别为100%、82%、89%、88%、83%、71%, 对爬楼梯、踢球、拾起、投球、打棒球、漫步的行为识别率分别为50%、43%、50%、67%、57%、67%。由于sub-JHMDB数据集中的行为比UCF Sports数据集中的更具挑战性, 因此行为识别的成功率较低。以文献[4]方法为例, 其对sub-JHMDB数据集的行为识别率(56.6%)比对UCF Sports数据集的行为识别率(89.1%)降低了32.5%。但从表2的对比实验结果中可以看出, 本文方法依然能够较好地识别出数据集中的行为。本文方法对sub-JHMDB数据集中的12种行为的平均识别率为70.6%, 比Wang等[4]提出的基于密度轨迹的行为识别方法的平均行为识别率提高了14%; 比Gkioxari和Malik[15]提出的使用多级表观及运动模型构建行为管道的行为识别方法的平均行为识别率提高了8.1%; 比Peng等[6]提出的利用堆叠的Fisher向量进行行为识别的方法的平均行为识别率提高了1.3%。
本文提出的基于多级图像序列与卷积神经网络的人体行为识别方法中的关键算法有:①用原视频序列生成四级图像序列并分别用卷积神经网络提取特征, 这四级图像序列分别为原视频图像序列、人体区域图像序列、光流图像序列和人体区域光流序列; ②提取视频中的关键帧并将原视频划分为视频子段, 从而得到视频中人体行为由粗略到细致的划分, 然后将子段得到的特征(式(3))与整段得到的特征(式(4))组合得到人体行为识别特征(式(5))。
为验证本文提出的四级图像序列结构的有效性而采用的对比方法有:①仅使用原视频序列, 即只用第一级卷积神经网络; ②仅使用原视频图像序列与人体区域图像序列, 即使用本文提出的多级图像序列中的第一级与第二级; ③仅使用原视频图像序列与光流图像序列, 即使用本文提出的多级图像序列中的第一级与第三级。
由表3中序号1、2、3、6的实验结果可以看到, 使用视频图像序列与人体区域图像序列比仅使用原视频序列的行为识别精度提高了12.3%, 这是由于原视频序列中仅包含图像帧的空间信息, 而使用视频图像序列与人体区域图像序列能够附加人体行为的前景信息, 有助于剔除无效信息保留有效信息。使用原视频图像序列与光流图像序列比仅使用原视频序列的行为识别精度提高了3.4%, 这是由于有效利用了帧与帧之间的运动信息。而使用四级图像序列比仅使用原视频序列的人体行为识别精度提高了24.6%, 这是由于四级图像结构比原视频序列中附加了视频中的运动信息与前景信息, 因此能够得到更多有效行为信息。实验结果证明, 本文提出的构造四级图像序列并分别用卷积神经网络进行处理的方法有效地提高了人体行为识别的准确度。
| 表3 关键算法的有效性验证 Table 3 Efficiency of the key points in the proposed method |
为验证本文提出的用完整视频段与视频子段共同构造的人体行为识别特征的有效性, 本文采用的对比方法有:①仅使用完整视频段信息构造人体行为识别特征; ②仅使用视频子段信息构造行为识别特征。
表3中序号为4、5、6的实验数据表明, 仅使用完整视频段的特征进行行为识别的精度为55.5%, 而使用视频子段特征进行行为识别的精度为61.5%, 提高了6%, 这是由于视频子段是通过将完整视频段中的人体行为进行由粗略到细致的划分得到的, 能够体现人体行为的细节信息, 而完整视频段的特征更侧重于视频中行为的整体信息。另外, 从表3可以看出, 同时使用完整视频段信息与视频子段信息得到的行为识别精度为70.6%, 比仅使用完整视频段构造的行为识别特征的行为识别准确率提高了15.1%, 比仅使用视频子段构造的行为识别特征的行为识别准确率提高了9.1%, 这是由于使用由完整视频段信息与视频子段信息相结合构造的人体行为识别特征中既包含了全局信息又包含了细节信息, 因此所含的人体行为的有效信息量更大。实验结果表明, 本文提出的将完整视频段信息与视频子段信息结合构造人体行为识别特征的方法有助于提高人体行为识别的准确度。
本文提出了一种基于多级图像序列和卷积神经网络的人体行为识别方法。首先, 用原始视频图像序列衍生出另外三级图像序列, 它们分别为人体区域图像序列、光流图像序列和人体区域光流序列。然后, 用不同的卷积神经网络分别对四级图像序列进行处理, 得到四级卷积神经网络特征。这样的多级结构中包含了图像的表观特征、前景的表观特征、图像的运动特征以及前景的运动特征, 因此能够提取出更丰富的人体行为特征信息。另外, 本文提出了将人体行为分解为由粗略到细致的子行为的方法, 即从原视频序列中提取关键帧的索引号, 并利用二叉树将四级图像序列分别分解为子序列, 从每个子序列中提取特征向量并融合, 从而得到更具有代表性的人体行为特征。
本文用两个挑战性的人体行为数据集对所提出的算法进行验证, 同时与几种前沿算法进行对比, 并针对所提出的多级结构和视频子序列分解的关键算法分别进行了验证实验。对比实验和验证实验结果表明, 本文方法能够有效识别视频中的人体行为。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|