
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于ECPMR的编译器测试方法
[刘磊1, 2  , 刘利娟
, 刘利娟2 , 吴新维1 , 张鹏1 ]
, 刘利娟]
|
|


作者简介:刘磊(1960-),男,教授,博士生导师.研究方向:程序分析技术.E-mail:liulei@jlu.edu.cn
提出了一种通过验证程序切片是否满足ECPMR的方式来验证编译器的方法。首先,选取一些满足特定蜕变关系的正确程序作为待测编译器的输入。然后,使用这些被选程序来生成程序切片。最后,检查程序切片的输出是否满足ECPMR从而发现编译器中的错误。在SNL编译器上进行了本文方法的验证实验,结果表明该方法可有效地探测到SNL编译器中的错误。
The aim of this paper is to propose a method based ECP Metamorphic Relation (ECPMR) to test compilers. First, we select some correct programs with specific metamorphic relations as inputs of the under-test compiler. Then, we use these selected programs to generate program slices. Finally, we check whether the outputs of these program slices satisfy the ECPMR to find bugs in the compiler. Our proposed method is verified through experimental study on SNL compiler and the results show that this method is effective to detect bugs in SNL compiler.
编译器在软件开发过程中担任着一项重要的角色, 它为高级程序语言编写的源程序生成可执行文件。因此, 编译器本身所存在的缺陷或故障将会直接威胁到使用其编译开发的软件的可靠性。与很多软件一样, 保证其质量、探测其错误或故障的重要途径之一就是测试, 编译器测试因而显得不可或缺[1]。在进行编译器测试时, 通常需要验证源代码所表达的语义和其生成的可执行程序所实现的功能是否相同[2]。但是这样的测试用例很难建立, 这就是软件测试[3]中经常遇到的Oracle问题[4]。为了解决Oracle问题, Chen等提出蜕变测试方法[5]。该方法通过比较分析程序多次执行的输出结果是否满足一定的关系来进行软件测试, 不需要构建测试预言, 从而有效地解决Oracle问题[6, 7, 8]。
为了对没有测试预言的编译器进行测试, 本文提出了一种通过验证程序切片[9]是否满足ECPMR的方式来验证编译器的方法。在本文方法中, 首先构建一组拥有特定蜕变关系[8]的正确程序作为待测编译器的输入, 然后依次运行由这组程序产生的程序切片。最后, 通过检查程序切片的输出是否满足ECPMR来探测编译器中的错误。如果不满足, 则检测到一个错误。本文引入了基于路径分析的等价类划分方法, 通过动态符号执行技术[10]获取等价类划分基本信息。为验证该方法的有效性, 本文将该方法应用于SNL编译器的测试中, 实验结果表明该方法可以发现编译器中的一些错误。
传统的等价类划分测试是一种典型的黑盒测试方法, 它不关注软件的内部结构而是关注软件需求规格说明书[3]。然而本文中所希望的是每一个等价类可以精准地映射到它自己独有的路径上。也就是说, 本文中所定义的等价类划分是完全基于程序路径分析的。
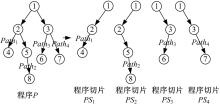
显然, 一个程序在给定输入下具有一条特定的执行路径, 并且一些输入可能恰好对应着同一条执行路径。在本文中, 这些输入被称为一个等价类。通常来说, 一个程序可能有多条执行路径, 正如图1所示的程序P。进而推之, 一个程序也有多个等价类。为了能够描述得更加清晰、直观, 本文给出等价类划分的定义。
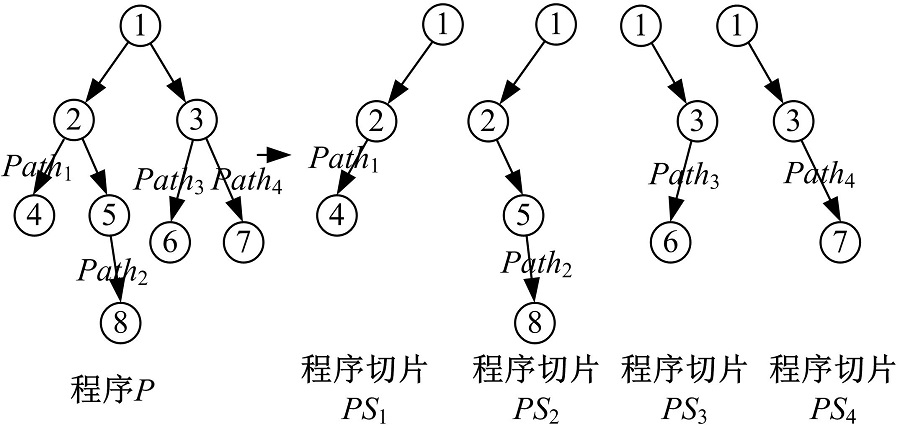 | 图1 程序P的切片结果Fig.1 Slice results of program P |
定义1 等价类划分(Equivalent class partitioning, ECP)假设集合A是程序P的输入集, Path1, …, Pathn是程序P的n条执行路径。如果A可以被划分成n个子集A1, …, Ai, …, An(i=1, 2, …, n, n≥ 2), 同时满足A1∩ …∩ Ai∩ …∩ An=⌀和A1∪ …∪ Ai∪ …∪ An=A, 并且每一个子集Ai都可以映射到独立的路径Pathi, 那么称A1, …, Ai, …, An为等价类划分, 其中Ai为一个等价类。
为了得到基于程序路径分析的等价类划分, 本文不得不寻求其他方法。通过分析很容易发现, 影响执行路径的主要因素就是输入和分支语句。动态符号执行技术提供了这种理想划分的可能性。因为动态符号执行依赖于输入符号约束, 而输入是从执行中的分支语句的谓语中获取的。在动态符号执行算法中[11], 输出结果包含了控制一条路径的路径条件。除此之外, 本文的关注点在于分支语句和循环语句。总而言之, 动态符号的执行解决了关于分支语句的问题。
在同一等价类下, 程序P产生的程序切片的语义应该与程序P的语义一致。因此可以基于执行路径得到这些程序切片, 正如图1所示的PS1、PS2、PS3和PS4。因此如果程序P满足了一条关于一些等价类的蜕变关系, 程序P得到的相应的程序切片也应该满足蜕变关系。
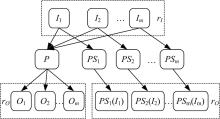
根据等价类划分, 程序P的输入域被划分为n个等价类, 分别为ECID1, ECID2, …, ECIDn, 并且这n个输入域被一一映射到不同的执行路径, 分别为Path1, Path2, …, Pathn。基于路径信息, 可以得到他们相应的程序切片PS1, PS2, …, PSn。I1, I2, …, In作为程序P的输入, 是从它们对应的等价类中随机生成的。O1, O2, …, On是它们相应的输出结果。相似地, PSi(Ii)表示Ii作为PSi输入时的相应输出结果, 其中PSi表示程序P的一条特定执行路径对应的程序切片。
如果程序P满足蜕变关系rI(I1, I2, …, Im)⇒ rO(O1, O2, …, Om) (m≤ n), 我们则认为程序P在这些输入下是没有错误的。显然, 对于这个程序产生的切片程序, 同样的输入理应对应着同样的输出, 也就意味着PSi(Ii)=Oi。基于以上分析, 可以得到如下推论。
推论1 在待测编译器下, 如果程序P满足rI(I1, I2, …, Im)⇒ rO(O1, O2, …, Om) (m≤ n), 那么对于程序P产生的程序切片, 也应该满足一条蜕变关系rI(I1, I2, …, Im)⇒ rO(PS1(I1), PS2(I2), …, PSm(Im)) (m≤ n)。这条蜕变关系被称之为ECP蜕变关系, 简称为ECPMR。
ECPMR如图2所示。根据推论1, 便可以利用原始程序及其产生的程序切片是否都满足蜕变关系或ECPMR来验证编译器是否有错误。如果原始程序满足蜕变关系并且程序切片不满足ECPMR, 则说明编译器中有错误。这就是基于ECPMR的编译器测试方法。
 | 图2 ECPMRFig.2 Metamorphic relation based on ECP |
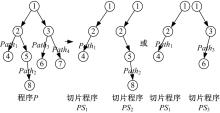
在推论1中, 特意备注了m≤ n。因为在理论上, 程序P有多条执行路径, 理应得到同样数量的等价类, 正如图1所示。而实际上, 由于蜕变关系可能无法覆盖所有的输入域, 在大多数情况下, 这些程序切片并不能覆盖所有的执行路径, 也就是说可能得到如图3所示的一组切片程序。
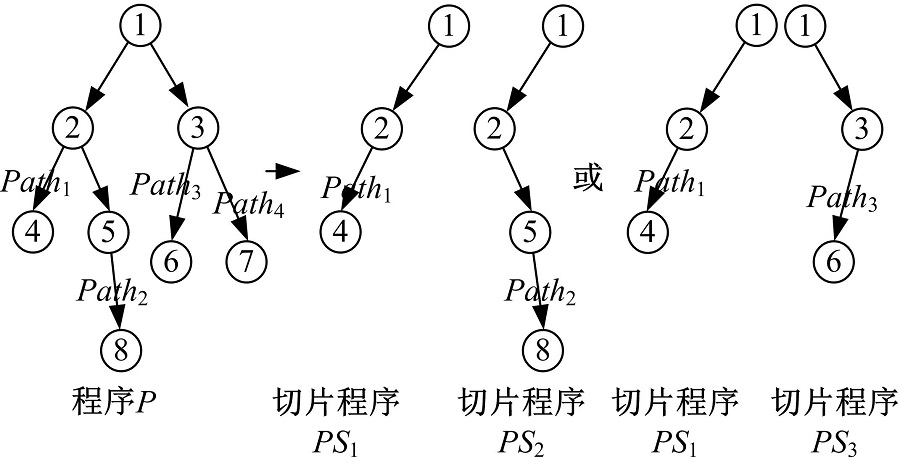 | 图3 程序P的实际切片结果Fig.3 Practical slice results of program P |
为了加深理解, 这里举例说明。董国伟等[5]使用了一个计算三角形面积的程序。这个程序首先将三元组(a, b, c)作为输入, 然后判断(a, b, c)是否可以组成一个三角形, 并且(a, b, c)可以组成什么形状的三角形。如果(a, b, c)可以组成三角形, 那么程序将计算三角形的面积。通过动态符号执行的结果, 可以得出等价类可以被划分为a与b相等的等腰三角形, a与c相等的等腰三角形, b与c相等的等腰三角形, 直角三角形和任意三角形。根据三角形的性质, 可以构造一条蜕变关系:假设(a, b, c)是程序的原始输入, 如果c2≠ a2+b2, 则令衍生输入(a', b', c')=(a, b, sqrt(2a* a+2b* b-c* c)), 那么他们的输出应当在可接受的精度范围内相等。根据定义1, 原始输入和衍生输入应属于不同的等价类, 本文构造一组蜕变测试用例, 如TiangleSquare(4, 5, 5)=TriangleSquare(4, 5, 7.5498)。可以看到这两个输入分别属于a与b相等的等腰三角形和任意三角形不同的等价类, 但是只涵盖了两个等价类。
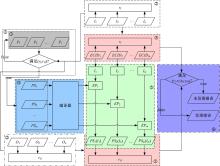
基于上文提出的ECPMR, 设计了编译器测试方法的框架。首先, 确认程序P是否满足蜕变关系。如果满足, 那么确认程序切片是否满足ECPMR。如果不满足, 则判定编译器有错误。其具体由6个阶段组成, 分别为初始化阶段、分析与验证阶段、再分析阶段、程序切片收集阶段、执行阶段和验证阶段。
(1)初始化阶段
在本阶段, 本文创建了一个程序集, 大小为z。被选取的程序应当尽可能地正确, 以减少人工对其修改。如图4中序号①部分所示。
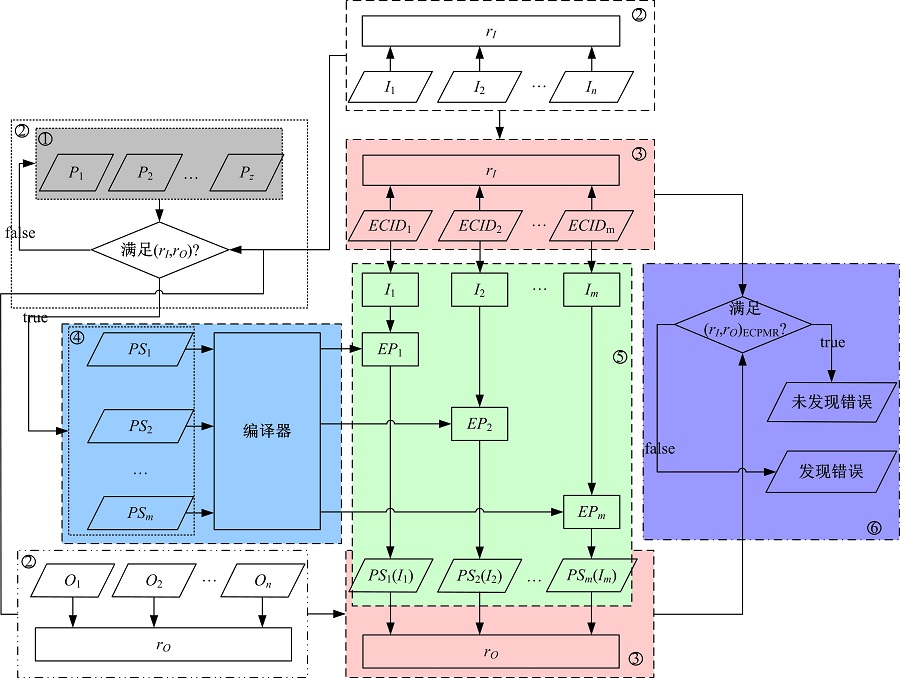 | 图4 测试框架Fig.4 The framework of testing |
(2)分析和验证阶段
在本阶段, 本文从程序集中选取一个程序来分析并推断其蜕变关系(rI, rO)。由于几乎所有蜕变关系都与程序的性质相关, 这一步在测试过程中也变得极其重要和困难。当然, 还是有一些蜕变关系可以被分析并构造出来。然后, 验证源程序是否满足(rI, rO)。如果不满足, 则放弃这个程序并选取下一个程序继续分析和验证, 直到选取的程序满足被构造的蜕变关系。如图4中序号②部分所示。
(3)再分析阶段
基于动态符号执行技术的结果, 输入域可以被划分为这些等价类ECID1, ECID2, …, ECIDm。分析这些等价类是否可以映射到(rI, rO)ECPMR中, 如果不能则放弃这个程序, 从第(2)阶段重新开始。否则, 进行下一步。如图4中序号③部分所示。
(4)程序切片收集阶段
根据程序执行信息, 得到与各个等价类相对应的程序切片PS1, PS2, …, PSm, 如图4中序号④部分所示。
(5)执行阶段
程序切片PS1, PS2, …, PSm作为待测编译器的输入, 并且得到相应的可执行程序EP1, EP2, …, EPm。根据等价类ECID1, ECID2, …, ECIDm, 可以构造一组输入I1, I2, …, Im作为可执行程序的输入, 最后得到输出PS1(I1), PS2(I2), …, PSm(Im)。如图4中序号⑤部分所示。
(6)验证阶段
验证I1, I2, …, Im和PS1(I1), PS2(I2), …, PSm(Im)是否满足(rI, rO)ECPMR。如果不满足, 则编译器中有错误, 否则, 继续第(2)阶段, 如图4中序号⑥部分所示。
因为程序切片可能改变它们的结构, 编译器对它们的优化处理可能会与源程序不同。而这些代码依然可以在编译后执行, 并且语义也与源程序等价, 换句话说, 这些程序切片和源程序在相同的输入下应该得到相同的结果。同时源程序输入与输出之间所满足的蜕变关系能够帮助笔者比较并分析程序切片的结果以发现编译器中的错误。
为了验证本文方法的有效性, 设计了一些实验。使用了SNL编译器作为实验对象, 实验环境为Windows 7系统。SNL编译器是由吉林大学课程组为编译原理课程设计的[12]。可以从代码开源库GitHub网站上下载源码(https://github.com/hikean/SNL-Compiler)。
实验中使用的测试用例一部分来自于SNL编译器开发者根据SNL语言语法规则编写的21个实例。由于一些实例程序主要流程是相同的, 本文只选取其中一个用于实验, 例如C6、C7和C8几乎相同。除此之外, 一些实例并没有分支语句, 也不得不放弃。最后本文得到了11个适用于实验的实例程序。然后对实例程序分析并抽象出ECPMR。已经在SNL编译器中发现了2个错误, 这两个错误分别由实例程序C1和C6探测到。接下来, 将介绍这两个实例程序。
实例程序C6接收一个整数值作为输入, 并且输出一个等于输入值或等于输入值减10的整数值。假设ts、tf、os、of分别表示原始测试输入、原始测试输出、衍生测试输入、衍生测试输出。通过分析程序的性质, 得到以下两条蜕变关系。
ECPMR1:如果ts≠ 10, 令tf=20-ts, 那么of=20-os。
ECPMR2:如果tf=ts+10并且ts≥ 10, 则of=os+10; 如果tf=ts+20并且-10≤ ts< 10, 则of=os+20; 如果tf=ts-20并且-10≤ ts< 10, 则of=os-20; 如果tf=ts+10并且ts< -10, 则of=os-10。
为了方便理解测试过程, 本文给出了程序的流程图, 如图5所示, 其中虚线表示调用函数过程, 箭头所指方向为其调用的函数过程。根据动态符号执行的结果, 可以分析得到等价类为s1< 10和s1≥ 10。其中蜕变关系恰好可以映射到这两个等价类。在图5中, 衍生程序1是由等价类s1< 10对应的执行路径得到的, 衍生程序2是由等价类s1≥ 10对应的执行路径得到的。
根据上文所示蜕变关系, 可以构造如表1所示的蜕变测试用例。用表1所示的测试用例运行相应的切片程序, 最终得到的统计结果见2。
 | 图5 测试实例程序C6及其切片的流程图Fig.5 The flow chart of C6 and its slices |
| 表1 实例程序C6的测试用例组 Table 1 The test case suite of program C6 |
在表2中, 序号为10的测试用例组违反了ECPMR, 也就是说它探测到了一个错误。通过对程序及结果的验证和分析, 发现SNL编译器在处理形如x< 5这样的布尔表达式时, 通过直接判断x-5是否小于0来处理, 这样就导致一些原本并不会溢出的输入在判断时溢出, 从而导致使用SNL编译器编译得到的可执行程序的功能与源程序想要表达的语义不同。
| 表2 实例程序C6实验结果 Table 2 The results of program C6 |
因为实例程序C1没有输入, 本文不得不对其分析并修改以便用于本文的实验。修改后的程序接收一个正整数作为输入, 这个正整数控制程序中的一条循环语句的循环次数。程序的输出是一个数组的一部分或全部的值。这个循环次数直接影响程序输出的数组的元素个数。修改后的程序具备一条性质:当循环次数小于等于5时, 如果c1< c2, 那么O1⊂O2, 其中c1和c2是两个输入, O1、O2分别表示c1和c2作为程序输入时的输出结果集。当循环次数大于5时, 两次输出结果的大小应该一致。从这些分析中, 可以得到如下蜕变关系。
ECPMR:
Of⊂Os, 如果tf=ts-1并且0< tf, ts≤ 5; Of和Os的大小均为5, 如果tf=ts+1, ts≥ 5。
我们为其产生了一些测试输入来测试, 得到的结果并不满足ECPMR, 当ts≥ 5时, Of和Os存在数组越界读取, 其集合大小不等于5。通过分析发现编译器在读取数组时有错误, 这极有可能是由于SNL编译器内部实现读取数组之前并没有对数组大小进行验证, 从而导致了数组越界读取错误。
本文提出了一种通过验证程序切片之间是否满足ECPMR的方法来测试没有测试语言的编译器。该方法通过检验满足特定蜕变关系的正确程序产生的切片程序的在其同一类输入下对应的输出是否满足蜕变关系来探测编译器中的错误。该方法应用于测试SNL编译器, 实验表明本文方法可以发现一些编译器中的错误。然而, 本文方法也有一些缺点。首先, 并不是所有的程序都可以找到蜕变关系并且接收输入。其次, 部分操作依赖于人工, 其效率并无保障。在未来的工作中, 将尽可能地完善方法以提高测试效率, 并且应用于更多的编译器中。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|