
{kind=link}
{kind=link}
基于稀疏矩阵的谱聚类图像分割算法
[刘仲民1  , 李战明
, 李战明1 , 李博皓1 , 胡文瑾2 ]
, 李战明, 李博皓|
|


作者简介:刘仲民(1978-),男,副教授,博士研究生.研究方向:机器视觉,智能信息处理与模式识别.E-mail:liuzhmx@163.com
在图像分割中谱聚类算法需要计算像素之间的相似度矩阵,构造数据量大,并且要对拉普拉斯矩阵进行特征分解,计算比较耗时。针对这一问题,提出了一种基于稀疏矩阵的谱聚类图像分割算法。算法结合图像特征信息在不同尺度上对谱聚类进行误差分析,设计了一种新的样本信息选取方案,并利用选取的图像信息直接创建稀疏相似度矩阵。理论分析以及图像分割实验结果表明,该算法能够有效降低谱聚类的计算复杂度,同时,提高了分割的准确性和鲁棒性。
Spectral clustering based on the similarity while the structure of similarity matrix is complex in image segmentation. The calculation of spectral clustering can be very time-consuming, especially in the process of Eigen-decomposition for Laplacian matrix. Sparse matrix could obtain the approximate solution of the similarity matrix by sing a small amount of sample information, thus, reducing the computational complexity effectively. An image segmentation algorithm based on the sparse matrix is proposed. First, error analysis of the spectral clustering is carried out in different scales. Then, a novel sampling method is presented. The sample information is used to create a sparse matrix, which can be used to substitute the similarity matrix. Typical experiment results and theoretical analysis show that the proposed algorithm can effectively reduce the complexity in calculating spectral clustering and improve the accuracy and robustness of the segmentation.
谱聚类是一种新型的聚类分析方法, 具有能够处理任意形状的数据集、易于执行等优点[1]。近年来谱聚类算法开始应用于图像分割及其相关领域并取得了迅速发展[2, 3]。该方法通过计算像素之间的相似度矩阵和拉普拉斯矩阵并对拉普拉斯矩阵进行特征分解, 通过对特征向量进行聚类完成对图像的划分。该算法基于相似度矩阵将图像划分为多个区域, 使得同一区域内部像素点相似度高, 不同区域之间相似度低, 从而可以获得较理想的分割效果。然而, 该算法在计算过程中产生的相似度矩阵规模过大, 特征值与特征向量的计算、存储使得算法计算复杂度过高。
过高的计算复杂度严重制约了谱聚类在图像分割领域中的应用。针对这一问题, 国内外学者进行了一系列的研究和改进, 其中有学者提出利用“ 稀疏矩阵” 的方法对其进行改进。稀疏矩阵指的是非零元素占全部元素的百分比很小或者非零元素占全部元素的百分比较大但是分布很有规律的矩阵。利用稀疏矩阵的结构特点可以避免储存零元素或避免对零元素进行运算从而减少内存消耗提高运算效率。代表方法有t-nearest-neighbor方法[4], e-neighborhood方法[5]和“ random” 方法[6]等。其中t-nearest-neighbor方法只保留相似度矩阵中与样本点取值相关的t邻域之内的数, 其余数据都忽略为零。e-neighborhood方法设定阈值e并将相似度矩阵中小于e的值都近似为零。这两种方法虽然能够减小拉普拉斯矩阵特征分解的计算复杂度, 但仍然需要预先算出相似度矩阵中的所有元素, 计算量依旧很大。random方法是随机指定相似度矩阵中一些元素为0, 从而计算量大大减小, 但该方法没有考虑样本之间的关系, 实验结果明显劣于前两种。
针对以上问题, 本文提出了一种新的基于稀疏矩阵的谱聚类图像分割算法。该算法在不同尺度范围内对像素相似度进行误差分析, 通过最小化误差的准则分别提取边缘和区域特征信息, 利用所提取的特征信息创建稀疏矩阵并代替原相似度矩阵进行运算。经理论分析与实验仿真证明, 本文算法不仅能有效降低谱聚类的计算复杂度, 而且能够获得更加令人满意的分割结果。
谱聚类是一种基于图论的聚类算法[7]。图由若干点及连接两点的线构成, 用点代表事物, 线表示对应两个事物间具有的某种关系, 又称为权重。将图划分为若干个子图, 各子图无交集, 划分时子图之间被“ 截断” 的线的权重和称为损失函数。谱聚类通过最小化损失函数来实现图的划分。设G(V, E)表示图, V={v1, v2, …, vn}表示点集, E表示边集。wij 表示vi 与vj 之间权重。假设G(V, E)被划分成G1 、G2 两个子图, 定义q=[q1, q2, …, qn]是一个n维向量, 用来表示划分方案。
损失函数可定义为:
式中:
定义拉普拉斯矩阵L=D-W, 将最小化损失函数的问题转化为最小化qT Lq的问题。
谱聚类图像分割算法将图像中的像素看作图中的点V, 像素之间的相似度关系可看作图中连接各顶点的线E, 构造出基于像素相似度的加权无向图G(V, E), 并以此进行分割, 其具体步骤如下:
Step1将待分割图像映射为加权无向图G(V, E)。
Step2计算相似度矩阵W以及拉普拉斯矩阵L。
Step3对拉普拉斯矩阵
Step4对特征向量进行聚类, 完成图像分割。
利用高斯函数计算图像各像素点之间相似度[8], 如式(5)所示:
式中:F(• )表示灰度值; X(• )表示坐标; σ I 、σ X分别表示灰度差值与坐标距离的尺度参数。
图像分割离不开对图像底层视觉信息的利用, 包括边缘与区域特性。相似度矩阵是决定谱聚类图像分割质量的最重要因素。在创建相似度矩阵时只有有效利用了边缘和区域的特征信息才能获得理想的分割效果。对相似度函数(5)进行分析可知, 随着坐标距离的变大,
由于在较小的距离尺度参数
在邻域r范围内式(5)(6)可以得到相等的ω ij 值, 在r范围外式(5)中相似度取值趋近于0, 与式(6)的取值近似相等。因此用式(6)代替式(5)创建的稀疏矩阵将与原相似度矩阵有较小误差, 不仅减小了计算量, 而且可以获得理想的边缘信息。
在较大的距离尺度参数
2.2.1 区域最小误差分析
对图像进行特征提取并创建稀疏矩阵, 要保证创建的稀疏矩阵S与原相似度矩阵W之间的误差最小化。对于一幅确定的图像, 相似度矩阵的‖ W‖ F 为一大于0的常数。稀疏矩阵S由W中提取的少量元素与零组成, 因此‖ S‖ F≤ ‖ W‖ F 。最小化误差就要保证最大化稀疏矩阵的‖ S‖ F 。设X={x1…xj…xn}为所有像素的集合, Z={z1…zi…vm}为所有特征中心的集合。
式中:k(zi, xj)表示像素xj 与特征中心zi 之间的相似度, 本文所取相似度矩阵函数k(zi, xj)为高斯核函数, k(zi, xj)取值与xj 、zi 之间的距离d(zi, xj)负相关。即最大化‖ S‖ F 等价于最小化D。
从而可以通过
2.2.2 区域特征信息提取方法
通过区域误差分析, 可以利用K均值聚类算法寻找区域特征中心。然而灰度图像拥有个特征值, 分别为x坐标、y坐标灰度值I(x, y)。由于无法准确预估坐标与灰度值之间的权重关系, 因此无法直接利用K均值进行计算。K均值聚类满足迭代误差ε 最小化, 本文利用该特性寻找区域特征中心。具体步骤如下:
输入:给定图像I, 像素个数n, 特征中心个数m, 终止迭代参数σ 。
输出:特征中心
Step1 按照设定的特征中心个数m, 在图像I上进行均匀采样, 并将像素分配到与之最近的采样点。
Step2 计算采样点3× 3邻域内像素点的灰度梯度值, 选取梯度值最小的点作为新的采样点。
Step3 设置步长s=(n∕ m)1⁄2, 在2s× 2s邻域内按照距离(式(9))为每一个采样点分配像素。
式中:dx, y为坐标的欧氏距离, dI(x, y)为灰度差的绝对值。
Step4 求取采样点所属像素的平均值作为新的采样点
式中:ε x, y为坐标误差; ε I(x, y)为灰度值误差。如果ε < σ 转Step5; 否则转Step3。
Step5 输出
该算法在分配数据时充分利用像素点与采样中心之间的距离关系, 使得误差最小化。根据
稀疏矩阵的创建过程是稀疏矩阵谱聚类图像分割的重要步骤。为了避免对图像中所有像素进行计算, 本文对图像中所有像素进行编码, 并将提取的特征信息映射到相似度矩阵中。
创建稀疏矩阵的具体过程分为两部分。第一部分提取创建稀疏矩阵所需特征信息(Step1~Step5); 第二部分将特征信息映射到稀疏矩阵(Step6~Step10)。以边缘信息特征提取为例, 对于一幅
Step1 计算每个像素与邻域像素的灰度差值, 得到灰度差值矩阵Q1, Q2, …, QN, 根据灰度差值矩阵计算灰度相似度矩阵W1, W2, …, WN:
Step2 将每个灰度相似度矩阵转化为一维列矩阵
合并得到灰度特征信息矩阵
Step3 计算每个像素与邻域像素坐标的欧氏距离, 得到坐标差值矩阵R1, R2, …, RN, 根据坐标差值矩阵计算坐标相似度矩阵T1, T2, …, TN:
Step4 将每个坐标相似度矩阵转化为一维列矩阵
合并得到距离特征信息矩阵Y=[Y1, Y2, …, YN]
Step5 距离特征信息矩阵与灰度特征信息矩阵对应位置相乘得到边缘特征信息矩阵
Step6 按照坐标对像素编码, 得到像素编码矩阵
计算邻域像素编码矩阵
Step7 邻域像素编码矩阵化为一维列矩阵
合并形成稀疏横坐标矩阵
Step8 生成一维列向量
复制
其中:
Step9
利用该方法创建稀疏矩阵可以避免对原相似度矩阵中所有元素进行计算, 计算复杂度由O(n2m2)降为O(Nnm), 需要运算及存储的数据量大大减少。例如邻域像素范围为5, 则N=25, 涉及相似度的计算量由m2n2 减少为25× mn。
改进的谱聚类算法步骤如下:
Step1 按照本文算法分别提取边缘特征信息与区域特征信息, 并建立边缘稀疏矩阵S1, 区域稀疏矩阵S2, 最终得到相似度稀疏矩阵W=S1+S2 。
Step2 计算拉普拉斯矩阵并进行特征分解, 将特征值由大到小排序后, 选择前
Step3 将矩阵
Step4 矩阵
Step5 确定原像素点类别, 完成图像分割。
本文实验环境为Windows10操作系统、Intel i3处理器、4 GB内存, 实验平台为MatlabR2012a。实验图像均来自Berkeley大学的BSD300图像数据库中的训练集和测试集, 在其中选取了大量不同类型的图像进行分割, 并选取标准手工分割、FCM、Nyströ m、Ncut等分割结果与本文算法进行对比。
本文选取幅图像进行分割实验, 其视觉分割效果如图1所示。
 | 图1 图像分割实验结果Fig.1 Experimental results of image segmentation |
从4幅图像分割的视觉效果来看, 本文算法有着明显的优势。为验证上述结论的可靠性, 本文将经典的性能评价指标查全率Recall和查准率Precision[11]引入到图像分割效果的性能评价过程中。
式中: TP表示检索出的相关信息量; FN表示未检索出的相关信息量; FP表示检索出的无关信息量。查准率说明算法排除干扰, 减少噪声的能力, 查全率说明算法避免遗漏的能力。查准率、查全率越大说明分割效果越好, 但是一般情况下查全率高, 查准率就低, 查全率低, 查准率高。在两者都要求高的情况下, 可以用F-score来衡量。
本文图像分割结果的3项分割指标如表1所示。
| 表1 分割评价指标 Table 1 Evaluation parameter |
通过表1的计算结果以及图像分割视觉效果可以直观地看出, 本文算法要明显优于其余几种方法, 本文方法对测试库中的图像是准确可靠的。
图像质量对图像分割效果具有重要的影响, 当图像存在一定程度的噪声或模糊干扰时, 将严重降低图像的分辨质量[12], 从而影响到算法对最终分割结果的计算, 因此有必要对该算法在不同程度噪声下的鲁棒性进行分析和讨论。
在对图1松树图像的分割当中4种算法都能获得较好的分割效果。为了对4种算法的鲁棒性进行验证, 在实验中对图像增加不同含量的椒盐噪声, 图像分割的F-score指标变化曲线如图2所示。
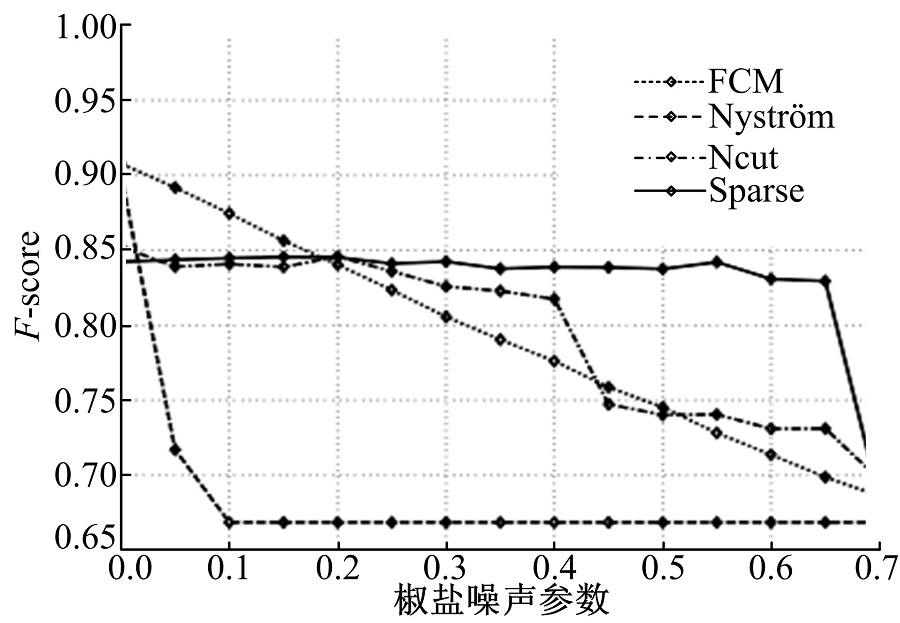 | 图2 F-score指标变化曲线Fig.2 F-score change curve |
从图2可以看出, 在对图像施加噪声时其余3种算法的分割质量迅速变差, 而本文算法不仅有较好的分割结果, 稳定性也更强。
较高的计算复杂度严重限制了谱聚类算法在图像分割中的应用。为此, 提出了一种基于稀疏矩阵的谱聚类图像分割算法。该算法利用像素在不同尺度上的相似度关系, 通过最小化相似度矩阵与稀疏矩阵在边缘和区域上的误差提取特征信息创建稀疏相似度矩阵。经理论分析与实验仿真可证明:该算法不仅有效降低了谱聚类图像分割的计算量与计算复杂度, 节省了内存空间, 而且提高了图像分割质量, 提高了算法对噪声的抗干扰能力, 有更强的鲁棒性。
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|