




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多层次特征表示的场景图像分类算法
[范敏1  , 韩琪
, 韩琪1 , 王芬1 , 宿晓岚2 , 徐浩2 , 吴松麟2 ]
, 韩琪|
|


作者简介:范敏(1975-),女,副教授,博士.研究方向:计算机视觉、智能控制与智能管理.E-mail:fanmin@cqu.edu.cn
针对场景图像种类增多、场景复杂度增加和场景内容增大的趋势,本文提出了一种基于多层次特征表示的场景图像分类算法。首先采用Object Bank目标属性的高层特征表示方法,经分类器预测出该图像所属的场景主题;然后在同一场景主题内,采用基于底层特征的局部约束低秩编码方法提取图像特征;在低秩编码方法中加入局部约束正则化并采用F-范数替代核范数的优化方法,减少计算复杂度,实现对场景图像较为细致的理解。这种由高层特征和底层特征相结合的多层次特征表示方法,从对象特征的粗理解到底层细节特征的详细解析,充分利用了不同特征间层层递进和互补的关系,实验结果证明了本文算法的有效性。
With the increases in categories, complexity and content of scene images, a categorization algorithm based on multi-level features representation was proposed. First, object attributes based on high-level feature representation were available. Using simple classifiers, the topics of scene images were exported. Then in the same topic, the low-level feature in the image was extracted by the way of fast locality-constrained low rank coding. Meanwhile, in order to reduce the computational complexity, the method of adding local constraint regularization and replacing kernel norm with F-norm in the processing of low rank coding was adopted to achieve detailed understanding of scene images. Achieving scene classification from coarse understanding of object characteristics to detailed analysis of low-level feature, the method can make full use of the progressive and complementary relationship between different features. The experiment results show that better classification effect is obtained.
场景图像分类作为计算机视觉最常见的图像识别任务之一[1], 旨在通过提取并分析图像特征, 将内容相似的图像归为同一类别。常见的场景类别大致可以归纳为4类[2]:自然场景、城市场景、室内场景和事件场景。常用在场景分类任务中的特征大体上可以分为底层特征和高层特征两类[3]。
在场景图像分类识别研究中, 大多数采用SIFT[4]、GIST[5]、HOG[6]等底层特征构建特征描述符[7], 对特征采用量化、编码等方法进一步挖掘底层特征在结构、空间上的相似度或关联关系, 如ScSPM[8]、LLC[9]和LrrSPM[10]等特征编码方法。然而计算机处理的离散“ 数字存储相似性” 和人理解的“ 概念和内容相似性” 之间存在语义鸿沟[11]。尽管这些方法在一定程度上弥补了特征表示与场景语义间的鸿沟问题[12], 但由于计算机视觉任务越来越具有挑战性, 这种基于底层特征的分类方法表现出了越来越多的局限性。而将图像中目标属性作为初始信息的高层特征表示方法如OB[13, 14]、BOP[15]、LPR[16]等, 能够补充图像特征表示在鸿沟问题上的语义信息, 取得了不错的分类效果。不同的特征所描述的侧重点不同, 如SIFT特征对于图像平移、旋转、缩放、光照甚至是遮挡等能够保持不错的鲁棒性, HOG特征能够捕获对象属性并且能对目标的边缘形状和轮廓进行描述。文献[17, 18]将多种特征相结合, 利用特征间互补关系, 在场景分类中取得了较好的分类效果。
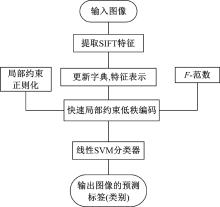
本文在文献[19]的基础上, 关注场景图像的多层特征, 包括底层的像素特征、中层的量化编码特征、高层语义的目标属性特征, 提出了一种基于多层次特征表示的场景图像分类算法。先提取各场景主题对应的OB特征描述符, 进行场景的粗理解, 即得到场景主题类别; 然后分别对场景主题内的子类图像提取SIFT特征, 并采用快速局部约束低秩编码方法得到特征矩阵, 区分同类场景主题内子类场景之间的差异, 并给出图像的具体场景类别。
本文采用Object Bank(OB)方法从目标初始信息出发, 利用OB描述符表示图像中包含的目标信息, 获得语义信息和空间结构关系, 从而形成更加丰富的图像表示。这种基于目标属性的高层特征表示方法, 类似于人类认知世界的过程。例如当人类想象航行场景时, 头脑中会出现上部有蓝天, 下部有海洋和在海洋中漂浮帆船的情景。
OB描述符基于局部可变模型(Deformable parts model, DPM)[20, 21]方法, 通过对底层HOG[6]特征进行建模, 获取中间层特征表示, 其核心是目标滤波器(Object filter), 包括描述区域整体相似度的粗糙根滤波器和若干描述局部小块与目标关键位置相似程度的高分辨率的部件滤波器。通过DPM方法表示多个尺度上一组目标滤波器的目标响应值后, 再经LSVM方法(Latent support vector machine)[22]进行参数学习, 确定目标的具体位置并且得到多个尺度上的目标响应值, 然后求取各层空间金字塔网格上的响应值, 最后使用池化(pooling)方法求取每个网格内各个目标的最大响应值, 将所有网格上的最大响应值连接成一个向量, 构成所包含目标信息的OB描述符。以UIUC 8-Sport运动场景的bocce类中目标“ 人” 为例, 如图1(a)所示, 由于拍摄角度不同可能呈现截然不同的姿态, DPM训练多个视角下不同的滤波器。如图1(b)(c)所示, 从正面、侧面两个视角采用5个部件滤波器和1个根滤波器有效地消除视角干扰。
 | 图1 DPM检测的“ 人” 对象模型(bocce类)Fig.1 The “ person” detection model of the DPM(bocce) |
这种包含高层语义信息的场景主题分类方法可以粗略地区分类间差异性较大的场景类, 将对象分布相似、语义相近的图像分到同一场景主题内, 实现对象特征的粗理解。
根据人类视觉原理[23], 同时受Xiao等[2]的启发, 利用Object Bank的目标属性特征, 通过已有的177个目标滤波器检测图像中所包含的物体, 计算得到相关物体响应值的高低分布。就室内场景而言, 一般图像中包括了沙发、桌椅、柜、灯具等标志性的物体, 所获得的这些物体的响应值就相对较高, 就可将这类图像归为室内场景。进而构成OB描述符并将其作为分类器SVM的输入, 学习得到分类模型; 当有新的图像输入时, 提取特征形成OB描述符, 再由已训练好的分类模型得到图像所属的场景主题标签。以数据库Scene-13为例, 本文依据其所包含相同对象和相近的语义信息将其分为3个主题场景:室内场景Indoor scene(bedroom、kitchen、livingroom、PARoffice)、自然场景Natural scene(MITcoast、MITforest、MITmountain、MITopencountry)、城市场景City scene(CALsuburb、MITstreet、MITtallbuilding、MITinsidecity)。各场景主题的样本图像如图2所示。其中在室内场景中通常就包含沙发、桌、椅、柜、窗户、灯具等主要对象; 在自然场景中通常包含树木、天空、海洋等主要对象; 在城市场景中通常包含高楼、房屋、街道等主要目标。
 | 图2 Scene-13中不同场景主题中图像示例Fig.2 Example images of different scene topics in Scene-13 |
在对海量图像进行分类处理时, 通过对图像所属场景主题类别进行初步分类, 可以避免图像特征提取及分类模型训练的盲目性, 减小类间差异性较大的场景图像的干扰。依据高层特征目标属性的特点, 有针对性地将包含具有代表性的相似目标对象的图像归为一类主题, 为后续的细分类任务做好准备工作。这样可以缩小分类器训练学习的场景图像范围, 以聚类的形式归纳场景图像, 所得到的分类精度就相对高些。例如, 在数据库Scene-13下的3类主题场景进行测试时, 其精度可达到98%左右。
采用OB特征表示得到场景主题后, 若在不同场景主题对应的底层特征表示空间内学习统一的分类器, 无法充分利用高层特征的目标对象特征且分类效果主要依赖于底层特征, 存在类内差异大的图像误分成两类或类间相似大的图像误分成同一类的情况。所以本文在得到图像的场景主题后, 采用基于底层特征的快速局部约束低秩编码方法来描述图像特征, 训练对应场景主题下的多个子分类器并输出图像最终所属的具体场景类别。考虑到图像的全局结构一致性和局部空间相似性, 本文在传统的低秩编码方法中加入局部约束正则化并采用
低秩编码方法采取一种在数据分布下的联合编码方式, 捕捉特征描述子间的整体结构特征。这种图像数据子流形的低维表示方法能得到图像的共性特征, 即使图像受到光照、遮挡等噪声改变时也有很强的鲁棒性。
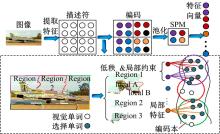
基于快速局部约束低秩编码(Fast locality-constrained low rank coding, FLCLRC)的图像分类方法首先对图像提取SIFT特征, 经过K-means聚类得到字典; 然后采用局部约束的低秩编码方法, 求得SIFT特征在字典下的特征编码表示。编码中加入局部约束正则化并采用
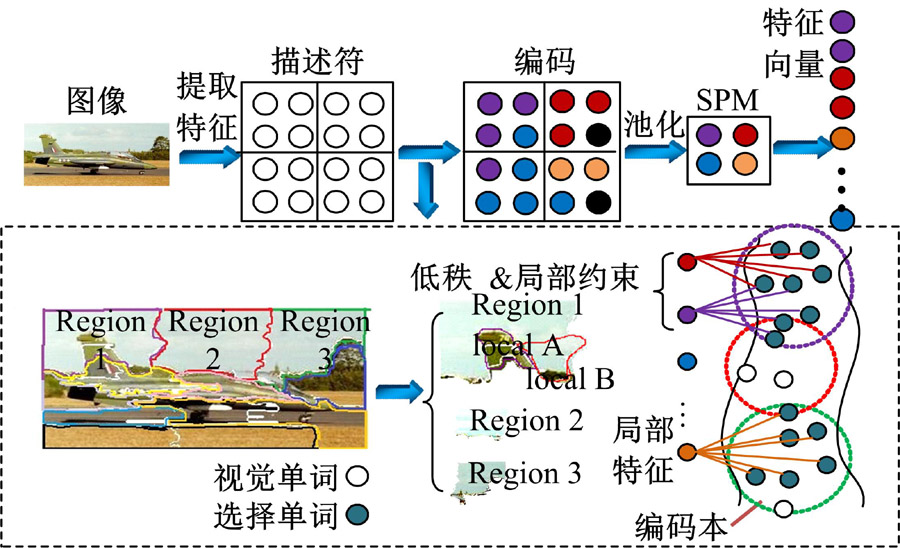 | 图3 快速局部约束低秩编码示意图Fig.3 Illustrations of FLCLRC |
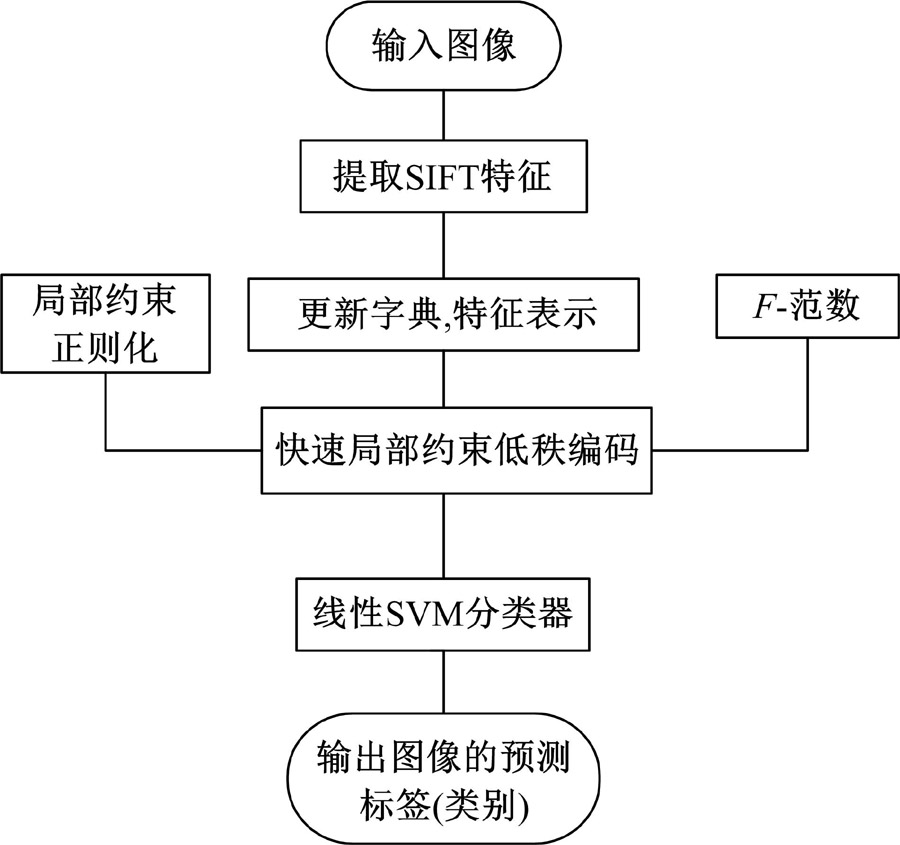 | 图4 快速局部约束低秩编码分类流程示意图Fig.4 Flow chart of FLCLRC Classification |
现有低秩表示的编码方法是在允许的误差范围内寻找特征矩阵的低秩表示:
式中:rank是矩阵的秩;
由于rank是非凸的, 公式(1)是一个NP-hard问题。Candes等[25]人证明在一定条件下, 矩阵的秩可以松弛为矩阵的核范数, 同时考虑到字典
式中:
对于核范数的优化问题通常采用增广拉格朗日乘子法(ALM)[26]方法求解, 优化过程复杂, 计算复杂度为
对低秩编码的优化问题, 本文从以下两个方面做出改进:
(1)Zhang等[27]证明:数据在一定误差条件下, 可用
式中:
(2)现有的低秩约束只考虑了图像特征全局结构的一致性, 却忽略了特征的局部空间相似性, 并且局部性能够产生稀疏效果, 反之则不会[28, 29, 30]。受启发于LLC[8], 本文在低秩编码中加入局部约束正则化项, 弥补特征的局部空间相似性。同时可进行图像局部光滑, 使得相似的图像块有相似的编码向量, 编码也具有更好的重建性能。
因此, 在图像特征全局结构一致性的基础上, 加入局部约束项λ 2/2
式中:
对式(4)进行求导, 最后计算得到特征表示矩阵为:
式中:
可得到图像的编码时间复杂度为
在引入局部约束正则化和用
| 表1 各算法在UIUC 8-Sport数据库上的效果对比 Table 1 Comparison of the effect of each algorithm on UIUC 8-Sport database |
在OB描述符表示的场景主题粗理解基础上, 采用快速局部低秩编码的表示方法描述同一主题内场景类别的细节特征, 分别对不同的场景主题学习不同的子分类器(Sub-support vector machine, S-SVM), 由此构成组分类器(Group-support vector machine, G-SVM)。整个分类过程如图5所示。首先对新输入的图像利用目标滤波器获取响应值, 经LSVM和Max Pooling作用得到OB描述符, 输入已训练得到的场景主题SVM模型中, 得到该类图像所属的主题标签; 再对该图像提取SIFT特征
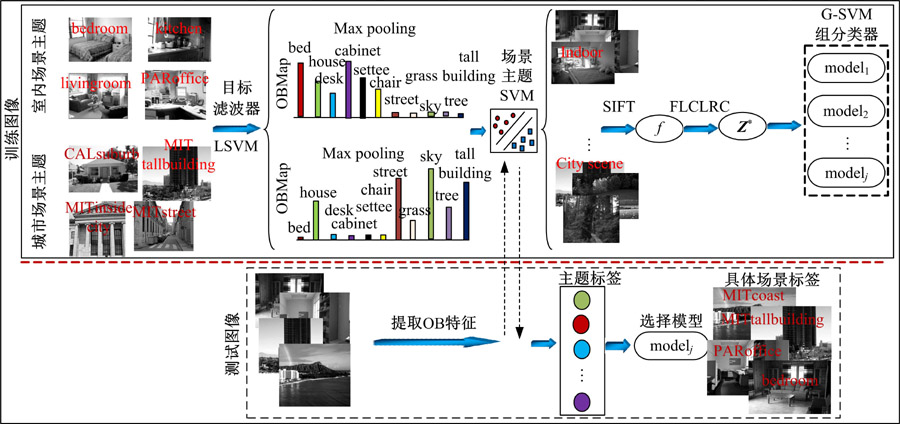 | 图5 多层次特征表示的场景图像分类算法示意图Fig.5 Flow chart of scene imagecategorization based on multi-level features representation |
为验证本文算法的分类效果, 在计算机上使用Matlab软件进行实验。从经典的图像数据库UIUC 8-Sport[31], Scene-13[32]中选取图像进行实验验证。
根据本文所提出的“ 由粗到细” 分类方法, 在“ 粗分类” 部分将这两类数据库按照图像中包含的某些相似目标或者具有相似语义的图像归为同一主题下; 在“ 细分类” 部分按照数据库原来的类别划分进行实验。
(1)场景主题模型:将Scene-13数据库分为3个主题场景:室内场景Indoor scene(bedroom、kitchen、livingroom、PARoffice)、自然场景Natural scene(MITcoast、MITforest、MITmountain、MITopencountry)、城市场景City scene(CALsuburb、MITstreet、MITtallbuilding、MITinsidecity), 每个主题下分别包含4个子类场景。在OB部分训练模型参数时, 每个大主题下随机选取100× 4张图像用于训练, 剩余图像用于测试; 同样地, 将UIUC 8-Sport数据库分为2个主题场景:球类运动Ball sports(badminton、bocce、croquet、polo)、室外运动Outside sports(RockClimbing、snowboarding、rowing、sailing), 每个主题下又分别包含4个子类场景。在获取OB部分训练模型参数时, 每个大主题下随机选取70* 2张图像用于训练, 从剩下的图像中随机选取60* 2张用于测试。
(2)主题下的子类模型:在Scene-13数据库中, 对每个主题所包含的4个子类场景图像每类随机选取100张图像用于训练, 剩余的用于测试; 同样地, 在UIUC 8-Sport数据库中对每个主题下的4个子类场景图像每类随机选取70张用于训练, 从剩余图像中随机选取60张用于测试。
在Scene-13数据库、UIUC 8-Sport数据库中的测试结果如表2所示。本文整体算法与OB-177[13]、FLCLRC[19]算法在数据库上的效果对比如表3所示。
| 表2 本文方法在数据库Scene-13, UIUC 8-Sport测试结果 Table 2 Testing results of our method on UIUC 8-Sport and Scene-13 database |
| 表3 整体算法在数据库Scene-13, UIUC 8-Sport分类效果 Table 3 Overall classification accuracy on UIUC 8-Sport, Scene-13 database |
可以看出本文算法在两类标准数据库下场景主题和对应场景主题的子类场景取得了较好的分类效果, 分类精度也有所提高, 其中在13类场景中的分类效果相对明显。而在8类运动场景中, 本文算法的效果稍有逊色。这是因为在场景主题分类时, 8类运动场景所包含的对象相对复杂, 类内间的背景复杂度和差异性较大。背景的变化对前景目标的检测造成干扰使得主题分类效果受到影响, 所以会对后面的细分类造成影响进而影响了整体的分类效果。
4.3.1 主题场景实验分析
以场景主题为标签进行分类, 图6为Scene-13数据库下不同主题分类效果。采用OB特征表示方法检测到不同尺度及视角变化的对象。图中, 相同颜色的矩形框表示同一物体, 例如椅(绿色)、桌(蓝色)、灯(橙色)等。可以看到同一物体在拍摄角度和外观上差异很大, 但是OB基本上都能成功检测。例如livingroom中种类多样的沙发、窗户、椅等物体。并且对于每一类图像都有着其标志性的对象, 如livingroom中的沙发,
 | 图6 Scene-13数据库中不同主题下检测到的物体示例Fig.6 Example of object detections of different classes |
bedroom中的床, kitchen中的碗柜, PARoffice中的电脑等。而这些图像又可归纳于同一主题当中, 如本文所分类的室内场景主题Indoor。因此, 可依据这些标志性的物体特征将图像进行主题分类。虽然根据人的主观的主题划分会对实验效果有所影响, 但从本文算法的实验结果来看效果还是不错的。
结合表2和表3可以看出, OB特征表示方法在以主题为标签, 通过检测属于同一主题内具有的相似对象进行分类预测时, 其分类精度高于将具体场景类别作为标签进行分类。原因在于以主题为标签时, 所需要检测的具有标志性的目标明确、数量少且响应值较为突出, 这样对于分类器模型的约束条件就相对较少, 所以最后得到的分类精度相对高。同时也可看出在数据库Scene-13上的测试精度高于UIUC 8-Sport。在Scene-13数据库中, 除了室内场景Indoor主题下包含的目标对象多而复杂, 另外的两个主题场景自然场景和城市场景目标对象较为明确且具有很强的代表性, 对于目标滤波器所得的响应值就较为突出。这也可以说明OB描述方法较为适用于一些具有明显标志性目标的自然场景, 或者一些具有多个目标但背景相对简单的室内场景。
4.3.2 子类场景分析
在对场景主题下的子类场景分类时, 表4和表5展示了UIUC 8-Sport下2类主题场景的分类效果。
| 表4 室外运动场景主题下的分类效果 Table 4 Classification accuracy of outside sport topic |
| 表5 球类运动场景主题下的分类结果 Table 5 Classification accuracy of ball sport topic |
对比表4、表5, 可以看出室外运动主题下的4类子场景相对于球类运动场景主题下的子场景分类效果好些。这是因为户外场景主题下的4类场景包含明显的前景目标和局部结构相似的背景, 并且其局部特征的相似度很高。如图7所示, sailing中包含帆船、海洋、天空, 其中整个帆船和海洋的纹理结构和颜色分布都极其相似; 同snowboarding的雪地的局部特征非常相似, 验证了局部约束能有效地捕捉局部特征描述子的间的相似性和共性特征。表5对应于在球类运动场景主题下的4个子类场景, 这4类场景类别的类内差异性较大, 稀疏编码能够保持对象的个性特征, 其分类精度就比低秩编码要高。如bocce类包含外观各异的场地如草坪, 沙滩, 水泥地; 数量不等的人; 复杂多变的背景房屋或户外森林、海滩; 甚至球的大小和尺度都不同。各类算法在8类运动场景的整体效果对比如表1所示。可以看出本文在场景细分类时所采用的优化方法所取得的分类效果还是不错的。
 | 图7 UIUC 8-Sport数据库样图示例Fig.7 Example images in UIUC 8-Sport |
本文提出了一种基于多层次特征表示的场景图像分类算法。在主题分类中, 充分利用高层特征的目标属性这一特点进行初步分类。在相应主题下的子类场景细分类时, 考虑到本文提取了高层和底层两种特征, 所需要的计算时间相对于一般算法要稍多些, 因此在底层特征编码中加入局部正则化并采用
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|